基于卷积神经网络的违章停车事件检测
2018-04-02吴玉枝熊运余吴洋
吴玉枝,熊运余,吴洋
(1.四川大学计算机学院,成都 610064;2.四川大学视觉合成图形图像技术国防重点学科实验室,成都 610064;3.武警警官学院信息工程系,成都 610213)
0 引言
随着城市规模的扩大和道路车辆增多,智能交通系统(ITS,Intelligent Transportation System)逐渐成为图像视觉领域的一个研究热点。与此同时,摄像机技术的飞速发展使得低成本高质量的摄像机被广泛应用于道路监控,为ITS的实现提供了丰富的原材料。传统的ITS着重于检测和识别道路车辆,通过图像特征检测视频帧或者视频流中车辆的有无以及车辆的位置,有效规避车辆碰撞等交通事故。道路是城市重要的公共资源,路边停车、人行道停车等非法占道事件不仅妨碍其他车辆和行人通行,更有可能酿成车祸惨剧,是一种较为常见的非法行为。事实上交警显然无法及时发现所有违章停车行为——利用已有的监控摄像头智能检测违章停车事件可以极大地减少警力投入,更快更精确地帮助交警的维持交通秩序。
在ITS中最关键的是图像处理技术,而检测算法又是图像处理的关键。车辆检测分为基于视频的车辆检测和基于图像的车辆检测。基于视频的车辆检测方法主要采用帧差算法、边缘检测算法和背景差算法[1],通过采样、开窗、虚拟传感器等方法实现对车辆数量、类型、车流量、车流密度,平均车速以及交通事故检测等的检测[2]。其中背景差算法使用最多,常用的背景建模的法有均值法、高斯平均法、中值法、卡尔曼滤波模型法及混合高斯模型(GMM,Gaussian Mixture Model)法[3]。
传统的基于图像特征的车辆检测采用了车辆显著的视觉特征、统计特征、变换系数特征和代数特征[4],近年来,深度卷积神经网络被应用于计算机视觉各个领域,在诸如图像分类[5-6]、人脸识别[7]、行人检测[8]和车辆分类[9]等多个方面取得了极大的成功,本文就是应用卷积神经网络进行车辆检测。
在目标检测方面,以R-CNN(Regions with CNN features)[10]为代表大部分的卷积神经网络[11]应用方法包含三个步骤:生成推荐区域(region proposal)、提取区域特征(feature extract)、对特征进行分类,其中区域推荐算法是关键,计算量和参数量都很庞大。本文使用一种单步式神经网络 SSD(Single Shot MultiBox Detector)[12],利用该神经网络直接预测出车辆的位置和分类,与包含区域推荐算法的神经网络相比,既保证了检测精确度,又极大地提高了检测速度,减少了内存损耗。在检测到视频帧中禁停区域的目标车辆后,利用颜色特征和位置特征对目标车辆进行短时跟踪,当目标车辆在禁停区域停留时间超过指定阈值后发出预警,并且只预警一次。
1 违章停车预警
当车辆在道路禁停区域(如人行横道、路肩等)停留时间超过一个阈值(如15分钟)就判为违章停车,需要发出一次针对该车的违章预警。获取道路监控摄像头的视频帧,检测该视频帧中的车辆目标并对禁停区域的车辆目标进行短时跟踪,若禁停区域内车辆在一超过阈值的时间内仍泊在禁停区域内,则发出预警。处理每一张视频帧的概要流程如图1所示。

图1 违章停车算法流程图
1.1 多车型标签车辆数据集
传统图片数据库中的车辆图片与真实的道路摄像头采集到的车辆图片有很大的区别。前者车辆目标只有小车和公交,车辆目标往往较大较少,多是平视的视角,背景各异,包含车辆的正面、侧面和背面;而后者车辆目标有小车、公交、三轮车和货车四种车型,受高摄像头和密集车流影响,图片中车辆目标更多,多为俯视视角,背景是树荫和道路,除了包含传统的车辆正面、侧面和背面外,还包含车顶图片,使用球机摄像头时目标可能还有轻微变型。本文用到的数据集大部分采自于真实道路摄像头,筛选了不同摄像头下1100+张图片,以确保角度和场景的多样性,另外采集了500+张网络车辆图片,以增加模型自适应性。在筛选出来的图片中标注货车、三轮车、小车和公交车四个车型的真实包围框,制作样本标签集。

表1 四种车型目标数量分布
1.2 区域检测
将禁停区域设为一个矩形,那么固定摄像头下的禁停区域也是固定的。为了方便描述,我们将每一个固定摄像头记为一个点位,并记录登记相关信息。已知各点位禁停区域的个数及对应禁停区域位置(左上角坐标和右下角坐标),根据禁停区域的位置信息截取视频帧对应部分作为输入图片。为每一个新出现的点位创建一个对象,包含到目前位置停泊在该点位禁停区域内所有车辆对象。利用SSD算法检测输入图片中的车辆目标,获得禁停区域车辆对象的具体信息,包括bounding box、灰度直方图、出现时间、停泊时间、预警信息等。
SSD[13]是一种利用单个卷积神经网络进行多类检测的方法,它由MulltiBox[13]和YOLO[14]启发产生的。SSD[13]与MultiBox[15]相比省去了后期分类步骤,减少了消耗,速度更快。与YOLO[14]采用整个特征图不同,SSD使用多层特征图,增加了模型输出层的平移不变性,减少了过拟合,改善了检测性能。同时,SSD还借鉴了Faster R-CNN[13]中锚(anchor)的概念,在训练之前首先定义了一系列不同长宽比和尺寸的先验包围框,在训练中由卷积神经网络筛选合适的包围框并对其大小和位置进行调整,得到最后的预测包围框,但是又比Faster R-CNN[13]更为简单,因为SSD不需要结合RPN和Fast R-CNN[12]。SSD[13]是首个将不同分辨率的特征图与先验包围框结合的网络,达到了计算量小、适应性强、检测精度高的效果。
(1)训练方法
将检测图片划分为s×s个格子,每个格子负责预测其对应区域的车辆目标。假设有总共n个先验,我们用bi(i∈ 2[0;n))表示,每一个先验对应一个包围框和若干分类置信度,这些置信度标志着该先验位置的目标是属于某个特定类的概率。表示第i个先验属于第p类的置信度,li∈R4表示第i个先验包围框的坐标,∈R4表示图片中第p类目标的第j个真实包围框。值得注意的是,预测包围框是通过先验包围框加上相应的网络输出偏移量得到的,另外,先验框和真实框都采用基于整张图的单元坐标系。坐标系归一化使得整张图片都可以在一个坐标单元内取得,这样我们就不必关心输入图片的大小,可以随意地对比坐标。
我们在文中将先验包围框称为源框,真实包围框简称为真实框。在训练过程中需要确定正负样本,能够与真实框匹配的源框是正样本,其余的源框是负样本。本文采用全预测匹配算法,首先执行双向匹配,保证每个真实框同一个源框匹配,然后在剩下的源框中选择与真实框相似度超过特定阈值(例如0.5)的几个源框,这几个源框也同真实框相匹配。全预测匹配可以为每个真实框匹配好几个正样本源框——使用全预测匹配算法能够为多个交叉的先验框预测出高置信度,而不会像双相匹配一样非要选出一个最好的匹配先验框。
为了检测多个类(几百甚至上千),我们需要为每个先验框预测出一个针对所有目标类别的包围框偏移量,也就是说,在匹配阶段不考虑源框的从属类别,先用算法将源框和真实框匹配起来。源框对应的真实框目标属于哪一个类在计算置信度损失函数时会用到。
(2)多层特征图预测
SSD的关键之一是设计源框(先验包围框),这需要为特征图中的每个位置设置一些先验,然后在算法中使用全卷积先验。这种做法不仅可以提高计算效率,还可以削减参数数量,减少过拟合的风险。
大多数的卷积网络的高层特征图会越来越小,以减少计算量和内存消耗,增加算法的平移不变性和尺度不变性。本文使用的卷积网络结合单个网络中多层卷积特征图达到了同样的效果。众所周知,卷积网络低层相较于高层获取了更多输入目标的细节,能够改善语义分割的质量;而高层特征图中池化得到的全局特征有助于平滑语义分割结果。SSD同时采用高层和低层卷积特征图来进行预测。一个网络中不同层的特征图通常感受野也不同。如果网络中的卷积先验需要同使用的每一层感受野相关联,计算量将非常惊人!为了解决以上难题,我们通过一定的调整使得特征图的某个位置通过学习负责预测图片特定区域和特定大小的检测目标。
(3)SSD提取特征
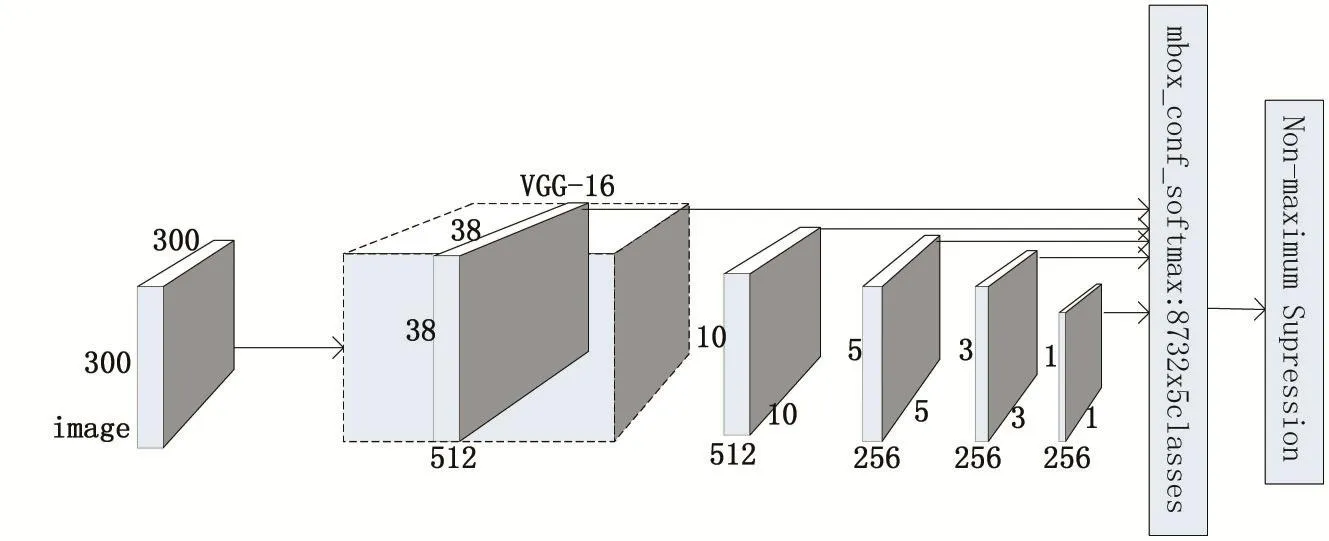
图2 SSD网络结构
通过CNN卷积学习到的特征具有一定的辨别性,针对目标提取的特征识别度较高,背景识别度较低,具有一定程度的位移、尺度、形变不变性。图3为网络中某些层特征可视化结果,其中第一张是是网络中的第一个卷积层,提取的特征较为具象化,图3.b第一张图片能够看到车辆目标的轮廓。算法中用作预测的六层特征图如图3中后六张图片所示,可以看到越低层的特征越具象化,提取的多是颜色、轮廓等基本特征;越顶层的特征越抽象化,越具有辨别性。多层特征的结合,可以兼顾到细节和全局两方面的特征信息,使得预测结果更为准确可靠。
(4)难例最小化
在匹配步骤之后,大部分的源框都会被标记为负样本,这样一来在训练过程中正样本和负样本之间就存在巨大的不平衡。我们将负样本中的源框按照所有类的置信度由高到低进行排序,选择置信度最高的几个负样本,丢弃其余的的负样本,使得负样本和正样本的比例总是接近3:1,使得网络优化更迅捷,训练过程也更稳定。
2.2 弱特征跟踪
利用弱特征对禁停区域停泊车辆进行短时跟踪。对比每一帧检测到的车辆目标和该点位已存在的车辆对象,若位置和灰度直方图匹配则根据新检测到的目标更新该对象信息,包括停泊时间,bounding box位置和大小等。
已知两个车辆对象A和B,利用其bounding box BA和BB的交叉比IoU(Intersection over Union)进行位置匹配,若两者IoU超过阈值i=0.5则认为A和B匹配。A和B的IoU计算公式如下:

其中SA和SB是两个车辆对象bounding box的面积。
采用基于区间统计的灰度直方图匹配算法。将输入图片处理为灰度图,然后将像素值0-255分为16个区间(即0-15,16-31,32-17……240-255),分别统计灰度图中各区间的像素点个数。将区间取值x映射到1-16(1,2,3…16),归一化得到图片在各区间的概率分布F(x)。假设灰度图分辨率为 h×w,落在第 i(i∈{1,2,3……16})个灰度区间的像素点个数为ci,则有,对应地:

对两个车辆对象A和B的bounding box区域图像进行灰度化处理后,分别获得其对应灰度区间概率分布F(xA)和F(xB),计算A和B每个离散函数值之差:

统计函中函数值超过指定阈值d的x个数,若超过s个则认为不匹配。经交叉验证,取d=0.01,s=2时较为合适,但由于不同点位背景和摄像头角度的影响,s和d的最佳取值可能有所差异。

图4 禁停区域灰度直方图
当已存在车辆对象A和新检测的到车辆对象B IoU和灰度直方图均匹配时,判它们是同一个车辆对象,根据B更新A的信息。不论已存在车辆对象A是否更新信息,均需判断其停泊时间是否超过指定阈值,若超过指定阈值且该对象尚未预警,则发出预警并更新其预警信息为已预警。同一个点位已存在对象连续n帧未能检测到则视为已驶出,删除该对象。经过试验验证将n设为3较为合适。
3 实验结果及分析
采集车辆数据制作标签,以PASCAL VOC数据集下训练好的SSD模型作为预训练模型,利用训练得到适用的网络模型用于车辆检测。训练采用的硬件配置如下:CPU,Intel Core i7-6800k@3.40GHz×12;GPU,Ge-Force GTX 1080/PCle/SSE2。该算法对于指定的禁停区域内车辆检测准确率达89.46%,帧率达46.57fp。道路摄像头采集的真实视频帧中驶经车辆很多,许多车辆只能抓取到部分车身图像,该算法对于占整体比例低于25%的部分车辆图像,尤其是只有车尾或者车身的上下部分时检测效果不甚理想。但违章停车预警主要是针对在禁停区域停泊一定时间的车辆目标,此类车辆往往可以拍到整个车身,因此并不影响最终结果。
依据目标对象的弱特征IoU和灰度直方图对车辆目标进行短时跟踪,跟踪准确率达91.63%。采用10个摄像头一组轮询的形式传送视频帧,平均每分钟每个点位传输2张视频帧,作为输入图片投入违章车辆预警系统。随机挑选3组含禁停区域的点位进行预警测试,违章停车预警率达93.92%。以下为部分点位预警后保存的对应图片示例,其中最外的蓝框是禁停区域框,禁停区域内车辆目标用黄框标出,最粗的红框为检测到禁停区域内停泊超过预设时间的车辆目标。

图5 违章停车检测效果
该方法在晴天、树荫遮挡、强光等复杂环境下均能有效发出预警,适应性强。由于不同点位的摄像头和背景差异较大,不同的点位点检测和跟踪时最佳阈值有一定差异。需将各点位的禁停区域和阈值等基本信息实现存储在XML文件中,读入该点位视频帧时再载入相应信息进行处理。
4 结语
采用改进的卷积神经网络用于车辆检测,利用IoU和灰度直方图对检测目标进行弱特征跟踪,将检测与跟踪结合起来有效地检测真实道路场景下违章停车事件。经实验,该方法违章停车检测准确率达93.92%,平均每秒处理约20张图片,能够准确有效地实现实时道路违章停车预警。该方法分钟的检测算法对视频帧中较小的车辆目标检测效果不甚理想,另外跟踪阶段的匹配方法对于光线较差的场景如夜晚匹配准确率大大降低。笔者将针对以上问题进行更为深入的研究。
参考文献:
[1]董春利,董育宁.基于视频的车辆检测与跟踪算法综述[J].南京邮电大学学报(自然科学版),2009(02):88-94.
[2]马卫强.基于交通视频的运动车辆检测方法[J].吉林大学学报(信息科学版),2014(03):321-327.
[3]甘新胜,赵书斌.基于背景差法的运动目标检测方法比较分析[J].指挥控制与仿真,2008,30(3):45-50.
[4]邱凌赟,韩军,顾明.车道模型的高速公路车辆异常行为检测方法[J].计算机应用,2014,34(5):1378-1382.
[5]Krizhevsky A,Sutskever I,Hinton G E.Imagenet Classification with Deep Convolutional Neural Networks[C].Advances in Neural Information Processing Systems.2012:1097-1105.
[6]A.Krizhevsky,I.Sutskever and G.E.Hinton,ImageNetClassification with Deep Convolutional Neural Networks,Advances in Neural Information Processing Systems,vol.25,no.2,2012.
[7]Y.Taigman,M.Yang,M.Ranzato,et al.DeepFace:Closing the Gap to Human-Level Performance in Face Verification,CVPR14.
[8]D.Tome,F.Monti,L.Baroffio,L.Bondi,M.Tagliasacchi,S.Tubaro,Deep Convolutional Neural Networks for Pedestrian Detection.http://arxiv.org/abs/1510.03608.
[9]Z.Dong,Y.Wu,M.Pei,and Y.Jia,Vehicle Type Classification Using a Semi-Supervised Convolutional Neural Network,IEEE Trans.Intelligent Transportation Systems,16(4):1-10 · August 2015
[10]Girshick R,Donahue J,Darrell T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.
[11]Ren S,He K,Girshick R,et al.Faster r-cnn:Towards Real-Time Object Detection with Region Proposal Networks[C].Advances in Neural Information Processing Systems,2015:91-99.
[12]Liu W,Anguelov D,Erhan D,et al.SSD:Single Shot Multibox Detector[C].European Conference on Computer Vision.Springer International Publishing,2016:21-37.
[13]C.Szegedy,S.Reed,D.Erhan,D.Anguelov.Scalable,High-Quality Object Detection.arXiv preprintarXiv:1412.1441 v3,2015.2,3,5.
[14]J.Redmon,S.Divvala,R.Girshick,A.Farhadi.You Only Look Once:Unified,Real-Time Object Detection.arXiv Preprint arXiv:1506.02640 v4,2015.1,2,3,6.
