基于相似性摘要算法的应用与研究
2018-04-02肖锦琦
肖锦琦
(四川大学计算机学院,成都 610065)
0 引言
传统的数据摘要算法如MD5、SHA-1等目前被广泛应用于数据完整性校验、数据加密等领域,其特点是摘要生成过程不可逆,且对原始数据十分敏感,一个字节的变化就会导致生成完全不同的摘要。但在电子数据取证以及恶意软件检测领域,存在各式各样的具有一定相似性的数据需要被挖掘出来,例如识别恶意软件变种、补丁升级的软件、被修改过的文本、或者是计算内存与硬盘中数据信息的相似程度等,而这些算法难以应对这类问题。相似性摘要算法便是用来解决这些最邻近搜索问题的一种有效手段,它将每个文件生成较短的指纹,不逐一比较文件本身,而是比较指纹。这样来降低比较量,提高效率。目前较为常见的有SSDEEP[1]、SDHASH[2,3]、NILSIMSA[4]、TLSH[5]等算法,其共同特点就是目标信息的改变程度会反应在生成的摘要信息上。按照实现方法可以将其分为基于内容分割的分片哈希算法、特征提取算法以及局部敏感哈希算法等三个类别,本文阐述了几种算法的核心思想,并对几种算法进行对比,讨论了其适用范围以及发展趋势。
1 基于局部敏感哈希的相似性摘要算法
局部敏感哈希算法的基本思想是将两个点冲突的可能性与其距离紧密相连,即两个点的距离越近它们冲突可能性越高,距离越远则冲突的可能性则越低。目前基于局部敏感哈希实现的相似性摘要算法有NILSIMSA和TLSH两种。
1.1 NILSIMSA
NILSIMSA最早被应用于垃圾邮件过滤中,通过步长为1,大小为5个字节的滑动窗口遍历目标数据,再将每个窗口中生成的3字节组(trigram)通过哈希函数h()进行映射,即令 i=h(trigram),其中 i的取值范围在0~255,用来统计每个trigram出现的次数,进计算所有trigram次数的平均值,若第i个trigram的次数大于平均值则输出1,否则输出0。由此可产生一个大小为32字节的摘要信息。
相似度则是通过按位统计两个摘要信息之间相同的总数减去128得出,也就是相似度的取值范围在-128~128之间,原文作者指出在相似度超过54时,可以认为两个文本的匹配度较高。
1.2 TLSH
TLSH算法是由趋势科技公司提出的一种相似性摘要算法,其借鉴了NILSIMSA的一些基本思想,工作原理如下:
(1)用大小为5个字节的滑动窗口处理目标数据,一次向前滑动一个字节,设一个滑动窗口的内容为:ABCDE;则采用 Pearson Hash[]映射得到 ABC、ABD、ABE、ACD、ACE、ADE这6个trigram的索引,进而统计每个trigram出现的次数;
(2)定义 q1、q2、q3为:75%的 trigram 的个数≥q1,50%的trigram的个数≥q2,25%的trigram的个数≥q3;
(3)构造TLSH哈希的头部,共三个字节:第一个字节是数据的校验和;第二个字节为目标文件长度大小;第三个字节由步骤(2)计算出的四分位点构成;
(4)构造TLSH哈希的主体部分:并按如下公式生成相应的二进制位,由此得到大小为32字节的主体部分摘要信息。
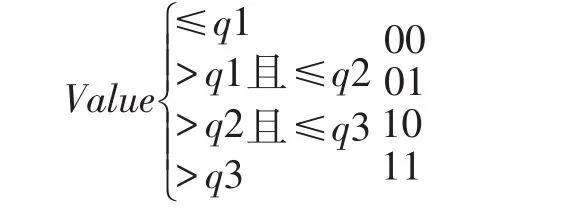
(5)将步骤(3)、(4)所求得的哈希头部与主体连接起来,得到最终的TLSH摘要信息。
TLSH通过距离值表示两个信息之间的匹配度,首先定义mod_diff(a,b,R)为一个在大小为R的循环队列中a到b的最小距离,即:
mod_diff(a,b,R)=Min((a-b)modR,(b-a)modR)
通过mod_diff()计算前三个头字节的距离并累加起来,而主体部分的距离计算方式与汉明距离较为相似。头部距离与主体距离之和为最终的距离值,其范围可以达到1000以上,与NILSIMSA相比具有更好的区分度。
2 基于内容分割的分片哈希的SSDEEP算法
基于内容分割的分片哈希算法(Context Triggered Piecewise Hashing,CTPH)又被称为模糊哈希算法(Fuzzy hash),2006年 Jesse Kornblum 提出 CTPH,并实现了一个名为spam sum的算法实例。随后,Jason Sherman开发了SSDEEP工具以实现这一算法。该算法最初用于取证,后来被用于恶意代码检测,最近又有用于开源软件漏洞挖掘等。目前SSDEEP已经成为恶意软件分析领域的一个标准算法,被NIST以及Virus Total作为相似性摘要算法所支持,其工作原理如下:
(1)首先将数据进行分片,读取前n个字节使用Alder-32算法作为滚动哈希算法得到哈希值h,若h除以n的余数恰好等于n-1时就在当前位置分片,否则,不分片,并向前移动一个字节,重复上述步骤。其中n的初值近似于文件的长度除以64的值,为2的整数倍,并根据分得的片数调整n的大小,如果当前片数较低,则将n减小一半,若较多则将n乘以2。最终使得分得的片数维持在32~64之间。
(2)使用Fowler-Noll-Vo hash[7]哈希算法计算每个分片的哈希值,并取哈希值的后六位以ASCII码表示出来作为摘要信息的最终结果。
(3)采用加权编辑距离(weighted edit distance)作为评价其相似性的依据,然后将这个值除以两个数据的长度之和,再将其映射到0~100的整数值上,100代表完全一致,0表示完全不同。
3 基于特征提取的SDHASH算法
SDHASH由Roussev在2010年提出,采用了类似于机器学习的方法去提取数据特征,具体方法如下:
(1)令熵值为Hnorm、优先级Rprec以及权重Rpop的初值为0。将数据划分为64字节大小的块,计算每个块的信息熵H。
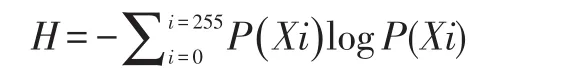
其中,P(Xi)表示字节值i在该块中出现的概率,然后计算得到Hnorm。
Hnorm=1000×H/log2B(B=64)
其中Hnorm向下取整,而Rprec由Hnorm映射得到。(2)计算出所有块的Rprec后,用大小为8,步长为1的滑动窗口依次遍历所有的Rprec值,并将窗口中值最小且位于最左端的Rprec值对应的Rpop值加一,选出所有Rpop≥t的块作为特征,这里t为4。
(3)每个被选出的特征转换为SHA-1,并将得到的哈希值分成5份放入Bloom过滤器[7]中,当过滤器存满时,则再创建一个新的过滤器进行填充,直到处理完所有特征。
(4)处理完所有特征后,Bloom过滤器中存储的数据即为最终的摘要信息,其距离计算公式SD(F,G)如下:
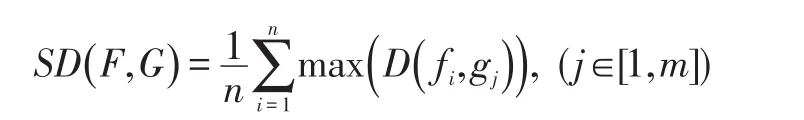
其中,信息摘要 F=f1f2…fn,G=g1g1…gn,(f和 g代表Bloom过滤器)。
4 算法对比及应用
目前已有一些工作对几种相似性摘要算法做了安全性的分析[8-9],其中Breitinger对SSDEEP做了分析认为该算法并没有使用基于密码学的哈希函数,构成并不严谨,因此存在漏洞可以被利用。而文献[10]对相似性摘要算法的健壮性以及对网页、图片等格式的区分度做了详细的对比实验,结果认为TLSH应对随机性变化的能力要好于SDHASH与SSDEEP。其特点对比如表1:
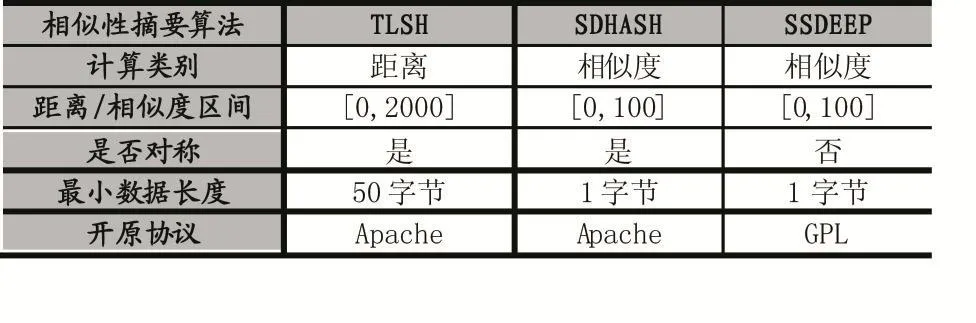
表1 相似性摘要算法对比
除了在电子取证方面有着广泛的应用,近年来也有人通过相似性摘要算法在安全领域进行试验,如文献[11,12,13]对其在恶意软件二进制变种识别上做了研究,并取得了较好的结果。
5 结语
本文对相似性摘要算法做了全面的介绍,同时针对其在安全领域方面的应用做了分析,该算法由于极强的区分能力以及抗随机干扰能力,在恶意软件家族分类,软件漏洞分析等领域也有极大的优势,但目前相似性摘要算法只支持字面上的区分,无法做到语义上的区分,因此针对特定的领域还需进一步的提取其深层次的特征。
参考文献:
[1]Kornblum J.Identifying Almost Identical Files Using Context Triggered Piecewise Hashing[J].Digital Investigation,2006,3(3):91-97.
[2]Roussev,V.:An Evaluation of Forensics Similarity Hashes.In:Proceedings of the 11th Annual DFRWS,pp.S34.S41.Elsevier,(2011)
[3]Roussev V.Data Fingerprinting with Similarity Digests[C].Advances in Digital Forensics VI-Sixth IFIP WG 11.9 International Conference on Digital Forensics,Hong Kong,China,January 4-6,2010,Revised Selected Papers.DBLP,2010:207-226.
[4]Damiani E,Vimercati S D C D,Paraboschi S,et al.An Open Digest-based Technique for Spam Detection[C].ISCA,International Conference on Parallel and Distributed Computing Systems,September 15-17,2004,the Canterbury Hotel,San Francisco,California,Usa.DBLP,2004:559-564.
[5]Oliver J,Cheng C,Chen Y.TLSH--A Locality Sensitive Hash[C].Fourth Cybercrime and Trustworthy Computing Workshop.IEEE Computer Society,2013:7-13.
[6]Eastlake D,Fowler G,Vo K P,et al.The FNV Non-Cryptographic Hash Algorithm[J].2014.
[7]B.Bloom,Space/Time Trade-Offs in Hash Coding with Allowable Errors,Communications of the ACM,vol.13(7),pp.422-426,1970.
[8]Breitinger,F.:Sicherheitsaspekte Von Fuzzy-Hashing.Master's Thesis,Hochschule Darmstadt,2011
[9]Breitinger,F.,Baier,H.,Beckingham,J.:Security and Implementation Analysis of the Similarity Digest sdhash,1st International Baltic Conference on Network Security&Forensics(NeSeFo),Tartu(Estland)(2012).
[10]Oliver J,Forman S,Cheng C.Using Randomization to Attack Similarity Digests[M].Applications and Techniques in Information Security.Springer Berlin Heidelberg,2014.
[11]Daniel Raygoza.Automated Malware Similarity Analysis.Black Hat 2009
[12]Madison J,Techreport I,Smith M.Identifying Malware with Byte Frequency Distribution and Context Triggered Piecewise Hashing[J].2007.
[13]Azab A,Layton R,Alazab M,et al.Mining Malware to Detect Variants[C]//Cybercrime and Trustworthy Computing Conference.IEEE,2015:44-53.
