基于降噪自动编码器的推荐算法
2018-03-29武玲梅陆建波刘春霞
武玲梅,陆建波,刘春霞
(广西师范学院计算机与信息工程学院,广西 南宁 530023)
0 引 言
如今互联网信息急剧增加,为用户提供了很多选择,但过多的信息会出现信息过载的问题。为用户提供合适的商品,可以有效地提高用户的满意度。随着快速增长的社会数据,支持高效和有效的方法从大数据中提取有效特征越来越重要。推荐系统可以利用用户历史数据挖掘一些潜在的需求,进而为用户提供可能感兴趣的商品。
近年来随着网上商品的选择越来越多,推荐系统变得必不可少,为改善用户体验,很多公司和网站使用推荐系统来为用户推荐商品。虽然之前已提出很多算法,但仍有一些众所周知的问题有待解决,如数据稀疏性和冷启动,对于这些问题,许多研究者建议利用附加信息帮助建模,如内容[1-2]、标签[3-4]、社会信息[5-6]或用户多次反馈[7]。由于许多在线服务的选择丰富,推荐则扮演着越来越重要的角色[8]。对于个人,使用推荐系统可以让人们更有效地利用信息。例如,淘宝等网站根据用户的浏览痕迹给用户推荐相关商品。现有的推荐算法大致分为3类[9-10]:基于内容的推荐算法、协同过滤算法和混合推荐算法。基于内容的推荐方法是根据用户的爱好或商品的属性来推荐。协同过滤算法是根据用户过去的喜好或活动,如用户对商品的评分等信息,从而做出推荐。混合推荐算法通过组合基于内容和协同过滤这2种方法来获得最佳效果。
目前许多推荐系统使用的是协同过滤(Collaborative Filtering,CF)推荐算法,CF的基本原理是根据用户过去的偏好以及与其兴趣相似的用户的选择为用户推荐物品。协同过滤算法的简单有效性、准确性促使其得到了广泛的研究[11]。协同过滤可以分为基于记忆的推荐算法和基于模型的推荐算法[12]。基于记忆的推荐算法是根据项目评分矩阵计算用户或物品之间的相似度,根据得到的相似度为用户推荐,该算法优点是算法简单、可操作性强、通用性好。缺点是易受冷启动问题限制。而基于模型的推荐算法尝试预测用户对之前未遇到的物品的兴趣度,针对某一用户,使用机器学习算法训练物品的向量,建立模型后预测用户对新物品的评分,进而完成推荐,进一步填充了用户项目评分矩阵,但算法相对复杂且操作繁琐。而且在实际应用中,评分矩阵比较稀疏,使得基于协同过滤的推荐算法的推荐效果比较低。针对传统推荐算法存在的不足,本文提出基于降噪自动编码器的推荐系统,使用自动编码器去学习输入信号,通过建立模型并进行实验,实验结果表明比传统算法在处理数据集和效率上有明显的提高。
1 相关工作
最近深度学习被广泛应用于许多应用中,从计算机视觉到语音识别和机器翻译。它可以将低层特征进行组合,形成比较抽象的高层表示,其强大的数据处理和自动特征提取等优势,在图像、视频等领域取得了巨大成功。深度学习中常见的模型有深度玻尔兹曼机(Deep Boltzmann Machines,DBM)、深度信念网络(Deep Neural Network,DBN)、卷积神经网络(Convolutional Neural Networks,CNN)、栈式降噪自动编码器(Stacked Denoising Autoencoders,SDAE)等[13]。将深度学习应用于推荐系统越来越受关注,人们提出了很多方法来解决这个问题,大致分为2类:基于评分和基于辅助信息。基于评分的方法侧重于利用深度学习模型根据评分进行推荐[14-15],这些方法使用降噪自动编码器(Denoising Autoencoder,DAE)通过评分矩阵来学习用户或项目的压缩表示,进而做出推荐,结果表明与以前的线性模型(如矩阵分解)相比有很大的改进。基于辅助数据的方法从辅助数据如内容、标签或图像中学习压缩表示,然后结合传统矩阵分解法进行推荐[16-18],在深度模型中使用辅助信息可以使推荐达到更好的性能。
Salakhutdinov等人[19]首次将深度学习应用于协同过滤算法中,提出了一个两层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)模型,可见层为用户对电影的评分信息,隐层为用户信息,对其运用概率模型预测分数。但RBM只是针对评分预测,而不能很好地实现top-K的推荐。Truyen等人[20]提出了用于协同过滤的序号玻尔兹曼机,他们研究了评分顺序的参数,并提出了整合多个玻尔兹曼机用于基于用户和基于项目的过程。Wang等人[21]使用深度信念网(DBN)进行音乐推荐,将音乐的特征提取和推荐的歌曲统一在一框架内。Oord等人[22]使用卷积神经网络(CNN)解决了音乐推荐问题,采用深度卷积神经网络提取歌曲音频中的特征作为歌曲的特征,然后采用加权矩阵分解进行评分预测,结果表明通过增加音频信号,改善了推荐效果。这些方法均是修改深度学习算法并应用于协同过滤中,但这些方法很多并没有对数据进行预处理,直接将稀疏的评分矩阵输入神经网络,仍存在数据稀疏问题。
本文的模型将考虑用户和项目的相关属性特征,这样可以根据新用户或新项目的特征来为用户进行推荐,某种程度上解决了冷启动问题。实验中使用2个降噪自动编码器来训练评分矩阵,其中一个自动编码器训练用户潜在因子矩阵,另外一个训练项目潜在因子矩阵,训练结束后,得到的隐含特征向量输入一神经网络,通过神经网络来预测评分,通过新的评分矩阵计算项目的相似度,根据相似度结果完成推荐。
2 基于自动编码器的推荐系统研究
2.1 自动编码器
自动编码器(AutoEncoder,AE)[23]是一种尽可能使输出信号复现输入信号的神经网络,由输入层、隐藏层和输出层组成,每层包含许多神经元,其中输出层神经元数量等于输入层神经元数量,中间层的神经元数量小于输入层和输出层。输出的结果是数据的压缩表示,即数据的隐含特征,该特征可以代替原数据。自动编码器主要用来特征的提取和数据的降维,不需要对训练数据进行标记,是一种无监督学习算法。该算法特征的准确率一般比其他训练得到的结果要好,通常使用随机梯度下降法(Stochastic Gradient Descent,SGD)更新参数。
自动编码器的工作原理大致如下:
假设输入样本的一个向量表示为x∈RN,将其映射到隐藏层z∈RK的映射关系表示为:
z=h(x)=σ(Wx+b)
(1)
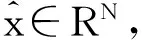
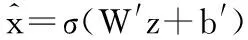
(2)
其中,W′∈RN×K是隐藏层与输出层之间的权值矩阵,b′∈RK为偏置向量,W′是W的转置即W′=WT。自动编码器的训练过程就是调整权值矩阵W,W′与偏置向量b,b′使得平均重构误差最小,其中损失函数如公式(3)所示:
(3)
最小重构误差函数如公式(4)所示:
(4)
2.2 降噪自动编码器
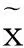
(5)
为使损坏输入公平,未损坏的值以原始值输入到公式(5)中:
θ=1/(1-q)
3 本文算法
实验目的是预测用户对未评分过的产品的评分,进而发现用户潜在的还未发现的感兴趣的产品,为用户做出推荐,使构建的模型在使用阶段快速有效,处理新数据时迅速有效,不需要为每个新评分、新用户或新项目重建模型。针对传统算法存在的扩展性、冷启动和数据稀疏等问题,实验中将考虑用户和项目的隐含因子进行推荐,通过2个自动编码器分别来训练用户和项目评分矩阵,得到输入数据的压缩表示后,将其输入神经网络来预测评分,并根据项目的相似性为用户进行推荐。
图1 用户-项目评分矩阵
记用户集合为U,项目集合为I,给定M个用户和N个项目,形成M×N用户-项目评分矩阵R,Ri,j表示用户i对项目j的评分值,评分值为0~5之间的整数。如果用户u对项目j未评分,则Ri,j=0,评分值越高表示用户对该项目认可度越高,如图1所示。
1)数据预处理。
在训练之前对MovieLens 1M数据集进行预处理,对用户数据加入地区信息,对电影数据加入电影年份信息。并将有关用户、产品和评分的数据信息转换为向量。将原始的评分数据进行处理,若性别为女性则数值等于0.5,若性别为男性则数值等于-0.5。电影年份设置为[-0.5,0.5],具体设置如公式(6)~公式(9):
d=yearmax-yearmin
(6)
(7)

(8)
(9)
其中,yearmax,yearmin分别代表数据集中最大和最小的电影年份,year为实验使用的数据。
2)训练自动编码器。
实验使用了2个自动编码器,对于第一个自动编码器中的每个用户输入R里的每一行、项目ID和项目特征向量,R里的每一行即每个用户对各个项目的打分作为其向量描述,输入层神经元个数等于项目数目I。对于第二个自动编码器每个项目输入R里的每一列和用户特征向量,R里的每一列即每个项目用各个用户对它的打分作为其向量描述,输入层神经元个数等于用户数目U。
每个用户u∈U={1,…,m}对项目的评分矩阵可以用R(u)=(Ru1,…,Run)∈Rn来表示,同理,对于每个项目i∈I={1,…,n}的评分矩阵可以用R(i)=(R1i,…,Rmi)∈Rm来表示。2个自动编码器,分别输入R(u)和R(i),通过自动编码器来获得用户和项目的隐含特征向量。下面主要描述输入R里的每一行数据的自动编码器训练过程,另一自动编码器训练过程与其同理。
对于R(u)加噪后的数据为:
训练用户评分矩阵的自动编码器的输出公式为:
其中,W,W′分别是训练用户评分矩阵的自动编码器中输入层到隐藏层、隐藏层到输出层的权重矩阵,b,b′分别是偏置向量。如图2所示。
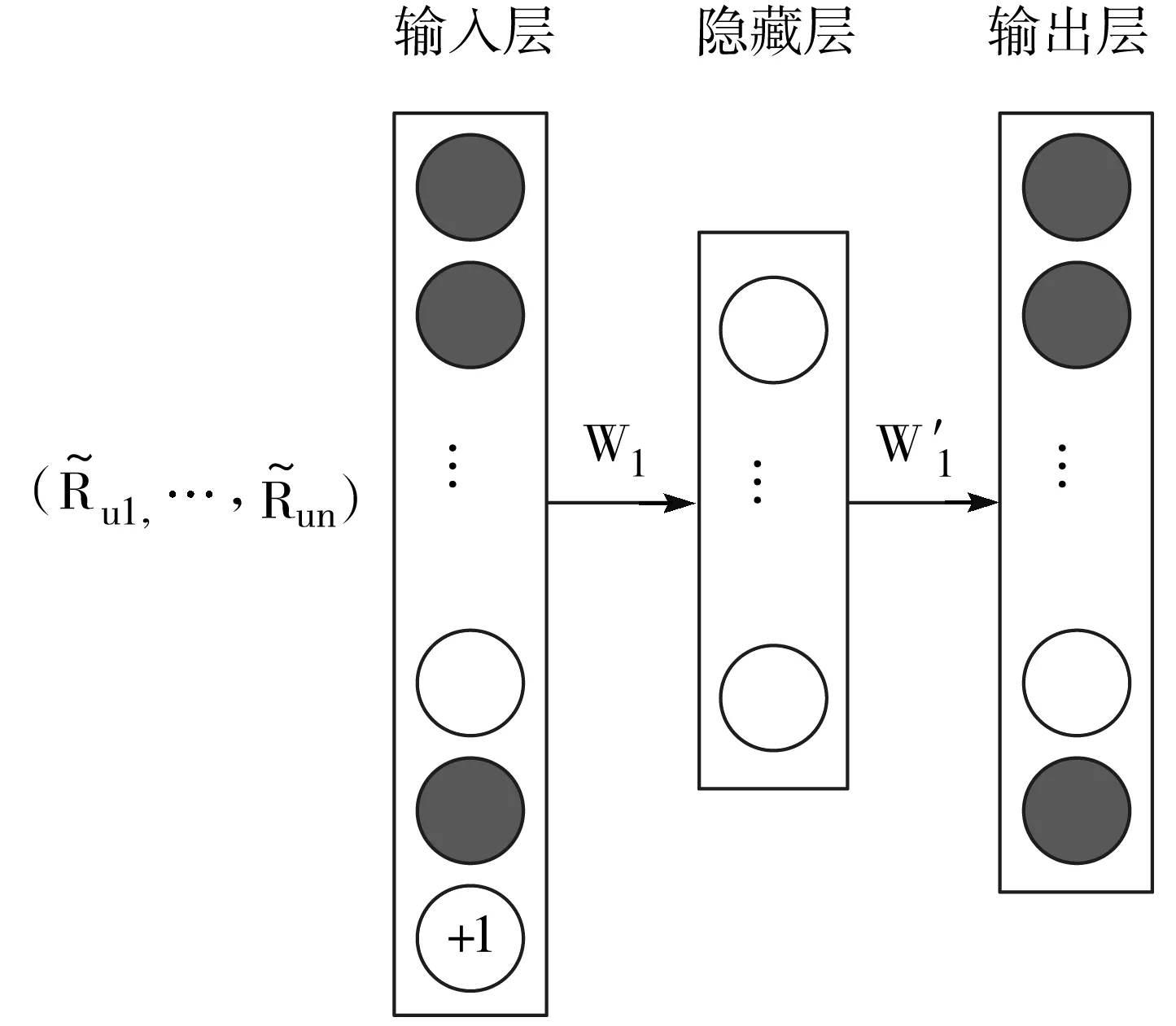
图2 训练用户评分矩阵
对于训练用户评分矩阵的自动编码器的最小损失函数为:
(11)
3)微调。
在训练过程中确定激活函数和梯度下降的学习率,用梯度下降法训练整个网络,并用训练好的参数测试整个网络,用反向传播算法(Back Propagation,BP)调整误差函数。
4)评分预测。
将自动编码器的输出结果输入神经网络,训练神经网络确定参数,使新的评分矩阵拟合原始评分矩阵。
5)生成推荐列表。
经过重复多次的训练后得到新的评分矩阵,根据重构后的评分矩阵,用欧氏距离来计算项目的相似性,利用相似度为用户进行top-K推荐。
欧氏距离公式:
(12)
欧氏距离值越小,说明相似性越大。算法流程如图3所示。
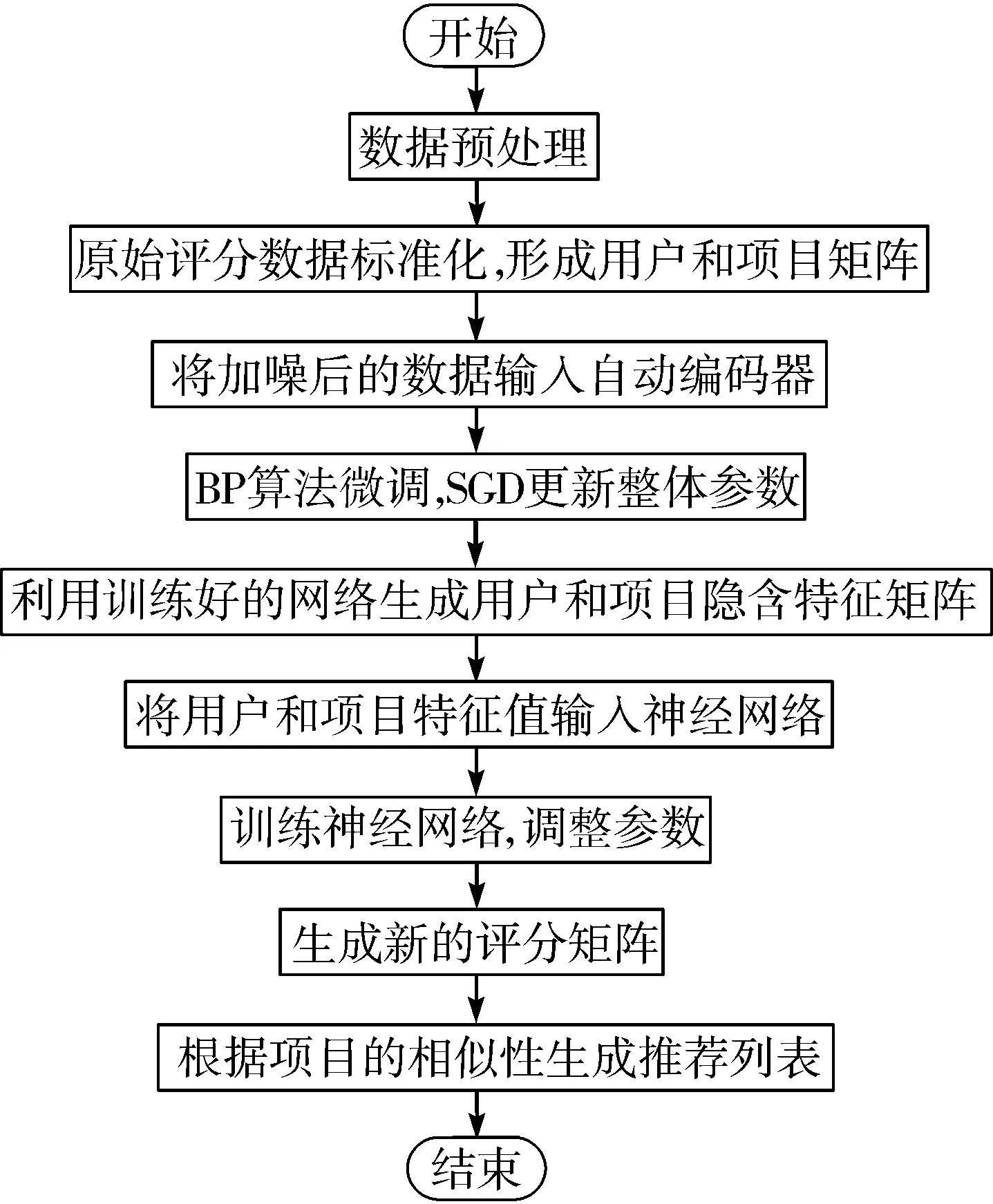
图3 本文算法流程图
4 实验结果与分析
4.1 实验数据集及评价指标
本文采用电影评分数据集Movielens 1M进行实验。MovieLens 1M数据集包含6040名用户对3952部电影的100万条评分数据。它包括3种数据信息:评分、用户信息和电影信息。评分值为1~5之间的整数。实验过程中采用数据集中的70%作为训练样本,剩余的30%作为测试样本。
采用均方根误差RMSE来作为评分预测的评价指标。通过计算预测评分与实际评分之间的偏差度量预测的准确性,差值越小则预测的质量越高,如图
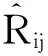
(13)
另外使用召回率(recall)来评价为用户作出推荐结果的质量,召回率公式:
(14)
其中,Su为测试集中用户评过分的集合,Tu为算法计算出的为用户推荐的集合。召回率表示算法推荐的K个项目中用户真正评过分的项目占用户评价过的所有项目的比例,计算结果越大,推荐的效果越好,如图5所示。
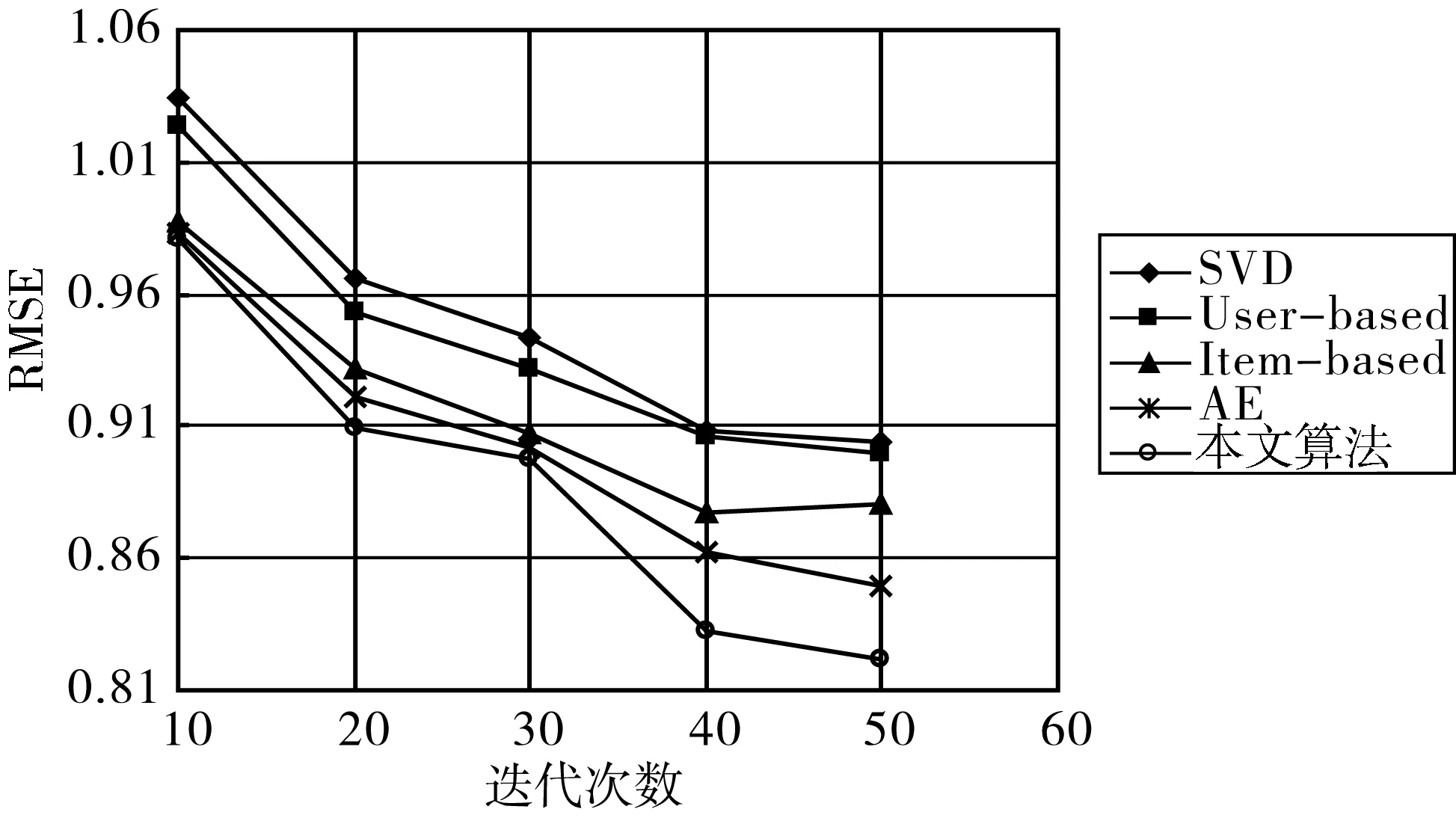
图4 各个算法的均方根误差曲线

图5 各个算法的召回率曲线
4.2 实验结果分析
为了验证本算法的有效性,将本文算法与基于用户的协同过滤算法(User-based))、基于项目的协同过滤算法(Item-based)、奇异值矩阵分解(SVD)、传统自编码(AE)在共同数据集MoiveLens 1M下进行对比验证。实验中,将评分数据分为训练集和测试集,对训练样本不断微调、更新参数,亦使重构误差最小,迭代次数分别为10~50次,从图4中可以看出在同样的参数设置下本文算法的预测性能最优。
当推荐列表个数K值为50,100,150,200,250,300时,各个算法的召回率情况如图5所示,根据实验结果可知,在推荐长度相同时,本文算法推荐的效果更好,说明基于降噪自动编码器学习的用户和项目特征能更好地代替原数据,将其应用于推荐,效果有所提升。
5 结束语
本文提出了一种基于降噪自动编码器的模型,实验结果表明,相比传统方法,本文算法的准确性高,对输入数据加入噪声使得重构误差减小。通过2个自动编码器训练用户和项目的潜在因子矩阵,使输入神经网络的数据没有原始评分矩阵稀疏,本文算法考虑了用户和项目的隐含特征向量,所以可以根据新用户或新项目的特征给予推荐,一定程度上同时解决了矩阵稀疏和新项目冷启动问题。从实验结果可以看出,将深度模型应用于推荐系统是一个很好的研究方向。本文在预处理数据和训练模型时花费了较长的时间,最优效果有待改进,今后的工作还可以考虑用其他深度学习模型来做推荐。
[1] Wang Hao, Li Wujun. Relational collaborative topic regression for recommender systems[J]. IEEE Transactions on Knowledge and Data Engineering, 2015,27(5):1343-1355.
[2] Zheng Xiaolin, Ding Weifeng, Lin Zhen, et al. Topic tensor factorization for recommender system[J]. Information Sciences, 2016,372(C):276-293.
[3] Wang Hao, Shi Xingjian, Yeung D Y. Relational stacked denoising autoencoder for tag recommendation[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. 2015:3052-3058.
[4] Ma Huifang, Jia Meihuizi, Zhang Di, et al. Combining tag correlation and user social relation for microblog recommendation[J]. Information Sciences, 2017,385(C):325-337.
[5] Guo Guibing, Zhang Jie, Yorke-Smith N. TrustSVD: Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. 2015:123-129.
[6] Park C, Kim D, Oh J, et al. Improving top-K recommendation with truster and trustee relationship in user trust network[J]. Information Sciences, 2016,374(C):100-114.
[7] Pan Weike, Xia Shanchuan, Liu Zhuode, et al. Mixed factorization for collaborative recommendation with heterogeneous explicit feedbacks[J]. Information Sciences, 2016,332(C)84-93.
[8] Zhang Wancai, Sun Hailong, Liu Xudong, et al. Temporal qos-aware Web service recommendation via non-negative tensor factorization[C]// Proceedings of the 23rd International Conference on World Wide Web. 2014:585-596.
[9] Bobadilla J, Ortega F, Hernando A, et al. Recommender systems survey[J]. Knowledge Based Systems, 2013,46:109-132.
[10] 黄震华,张佳雯,田春岐,等. 基于排序学习的推荐算法研究综述[J]. 软件学报, 2016,27(3):691-713.
[11] 冷亚军,陆青,梁昌勇. 协同过滤推荐技术综述[J]. 模式识别与人工智能, 2014,27(8):720-734.
[12] 丁少衡,姬东鸿,王路路. 基于用户属性和评分的协同过滤推荐算法[J]. 计算机与工程设计, 2015(2):487-491.
[13] 孙志军,薛磊,许阳明,等. 深度学习研究综述[J]. 计算机应研究, 2012,29(8):2806-2810.
[14] Li Sheng, Kawale J, Fu Yun. Deep collaborative filtering via marginalized denoising auto-encoder[C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. 2015:811-820.
[15] Wu Yao, DuBois C, Zheng A X, et al. Collaborative denoising auto-encoders for top-N recommender systems[C]// Proceedings of the 9th ACM International Conference on Web Search and Data Mining. 2016:153-162.
[16] He Ruining, McAuley J. VBPR: Visual Bayesian personalized ranking from implicit feedback[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. 2016:144-150.
[17] Wang Hao, Wang Naiyan, Yeung D Y. Collaborative deep learning for recommender systems[C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2015:1235-1244.
[18] Lei Chenyi, Liu Dong, Li Weiping, et al. Comparative deep learning of Hybrid representations for image recommendations[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. 2016:2545-2553.
[19] Salakhutdinov R, Mnih A, Hinton G. Restricted Boltzmann machines for collaborative filtering[C]// Proceedings of the 24th International Conference on Machine Learning. 2007:791-798.
[20] Truyen T T, Phung D Q, Venkatesh S. Ordinal Boltzmann machines for collaborative filtering[C]// Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. 2009:548-556.
[21] Wang Xinxi, Wang Ye. Improving content-based and hybrid music recommendation using deep learning[C]// Proceedings of the 22nd ACM International Conference on Multimedia. 2014:627-636.
[22] Oord A V D, Dieleman S, Schrauwen B. Deep content-based music recommendation[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. 2013:2643-2651.
[23] Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[C]// Advances in Neural Information Processing Systems. 2006:153-160.
[24] Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]// Proceedings of the 25th International Conference on Machine Learning. 2008:1096-1103.
