深度神经网络在目标跟踪算法中的应用与最新研究进展
2018-03-27欧阳谷钟必能杜吉祥
欧阳谷,钟必能,白 冰,柳 欣,王 靖,杜吉祥
1(华侨大学 计算机科学与技术学院,福建 厦门 361021) 2(华侨大学 计算机视觉与模式识别重点实验室,福建 厦门 361021)
1 引 言
视频目标跟踪技术已经广泛用于智能交通、人机交互、车辆导航、军事目标定位等领域,具有很强的实用价值,是计算机视觉领域中的一个热点研究课题,它具有多学科交叉性、重要的理论性、广泛的实用性等特点.虽然近些年目标跟踪研究取得了很大进展,但是在现实的跟踪场景中,由于目标的不定向运动和摄像机成像条件的复杂多样性等因素导致的目标自身的变化(非刚性物体形变、尺度变化、姿态变化等)和外部环境因素(遮挡、光照变化、背景混杂等)的干扰,使得构建一个鲁棒的目标跟踪系统有效地处理上述各种复杂变化,依旧是个巨大的挑战.
目标跟踪可以简单定义为:给定视频帧中第一帧的目标状态(位置,方向等),来对随后帧的目标状态进行估计[1,2].一般来说,目标跟踪技术的研究主要是为了获得目标的运动轨迹和运动参数,从而对后续的视频内容进行语义上的理解(如:目标识别、行为分析、场景理解等)提供可靠的数据基础.根据不同情况,如跟踪目标数量,摄像机数量,摄像机是否运动等,视频目标跟踪问题可以分为很多类型,典型的有:单目标跟踪与多目标跟踪,单摄像机跟踪与多摄像机跟踪,固定摄像机跟踪与运动摄像机跟踪等[3].本文中我们主要关注于当前主流的单摄像机单目标跟踪算法.
传统的目标跟踪算法通常分为基于生成式模型和基于判别式模型来对目标物体进行表观建模.基于生成式模型的目标跟踪算法是在上一帧目标位置附近,依据某种先验分布检测出候选目标,再对目标区域进行特征描述,再找出重构误差最小的候选区域作为当前帧目标的位置.基于判别式模型的目标跟踪算法伴随着检测一起进行,主要是训练一个二值分类器,从检测到的大量候选样本中区分前景(目标)与背景,将打分最高的候选样本作为目标样本,从而获得目标位置区域.以上两类跟踪方法,都涉及到一个关键问题:目标表观建模.而大部分传统的目标表观建模方法都是在提取目标物体的浅层特征上构建,如HOG特征[4],SIFT特征[5],颜色特征[6],局部二值特征[7]等,这些人工设计的特征只适用于某些特定场景,在复杂场景中表现的并不尽如人意,致使构建的跟踪系统很难应对现实跟踪场景的需求,容易导致跟踪目标漂移,甚至跟踪目标丢失.
在2006年,受到人脑视觉机理的启发,多伦多大学Hinton教授[8]提出了深度学习的概念.深度学习是从机器学习中的人工神经网络发展出来的新领域,其结构图如图1所示,其包含前馈传播和反向传播两个过程,前馈传播进行特征空间的转换,而反向传播算法[9]进行参数更新.相对于支持向量机[10,11]、在线Boosting[12,13]等浅层结构的学习方法而言,深度学习通过堆叠多个网络映射层,可以分别从网络的宽度和深度上来构建深度图模型,它具有模型层次深、特征表达能力强的特点,能自适应地从大规模数据集中学习当前任务所需要的特征表达,而且对于不同层特征具有不同的属性,甚至可以利用这些不同层特征的特定属性来应对不同场景中的跟踪任务.同时,层次化的深度网络具有强大的函数逼近能力和泛化能力,无需先验知识来提取特征.近些年研究发现,相比于传统的手工特征,基于深度学习技术自动学习到的层次化物体特征在很多计算机视觉任务中都表现的更鲁棒.
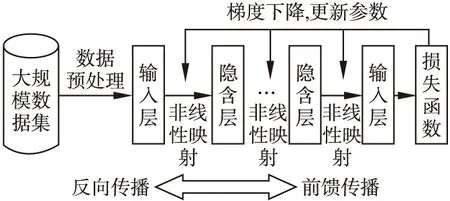
图1 深度学习技术基本框架Fig.1 Framework of the deep learning technology
随着深度学习技术的发展,其借助于海量数据的优势在图像分类[14-16]、目标检测[17-19]等诸多计算机视觉领域中取得了重大突破,同时也为研究人员利用深度学习方法来解决目标跟踪的各种难题提供了全新的视角.2013年以来,深度学习技术应用到目标跟踪研究中同样取得了不错的效果,从最初的使用深度网络来提取自适应特征,然后融合其他跟踪策略来实现目标跟踪,发展到目前已经能够训练出端到端的深度网络模型来直接预测目标位置.研究者们已经不满足于最初的依靠深度学习技术来提取自适应特征应用到跟踪问题上.目前,深度学习技术在目标特征描述、预测目标位置准确率、图像帧处理的速度等性能方面都有明显的提高.越来越多的深度神经网络模型,如自动编码机(ADE)[20]、卷积神经网络(CNN)[21]、循环神经网络(RNN)[22]、孪生(Siamese)网络[23]等都应用到了目标跟踪领域,并取得了不错的效果.
当然,深度学习应用到目标跟踪领域中时间不长,其中还有很多问题没有解决,比如:如果虽然在速度上有提升,但可能还不够实时;深度学习模型需要用大量训练样本来训练模型,而对于跟踪任务只有视频序列的第一帧能够拿来使用,所以存在训练样本的缺乏的问题等;因而还有必要对基于深度学习的目标跟踪算法做进一步的深入研究.
近几年,也有国内外同行总结了目标跟踪领域的相关研究现状,如[1-3,24-29],但随着大数据的时代的到来,深度学习技术发展迅速,并且应用到目标跟踪领域的算法也在快速更新,因此我们在前人的基础上,从不同角度和视野总结了当前基于深度学习技术的目标跟踪算法的最新进展.本文对目标跟踪算法的发展过程,研究现状和未来发展趋势做了一个讨论,将首先回顾目标跟踪系统的关键技术,其次重点阐述了目前最新的深度学习技术在目标跟踪领域中的应用、发展、算法特点等.最后对深度学习在目标跟踪领域未来的发展趋势进行了分析与展望.
2 传统目标跟踪算法的三项关键技术
目标跟踪算法已经发展了很多年,涌现出了大量优秀的跟踪算法.传统的目标跟踪算法的工作流程如图2所示,大致分为三个主要步骤:目标物体表观建模、搜索策略选取、模型更新.为了构建一个稳定的、鲁棒的、实时的目标跟踪系统,国内外学者分别针对这三个关键技术展开了大量研究工作,并取得了众多不俗的成果.

图2 目标跟踪算法工作流程图Fig.2 Workflow of the object tracking algorithm
2.1 目标物体表观建模
目标的表观建模主要包括对目标物体的外观刻画和观测模型两个部分.对目标外观刻画即提取特征描述,观测模型负责计算各候选区域的可信度.目标的表观建模决定了跟踪模型是否能够有效的应对各种复杂的目标表观的变化,是跟踪系统中的核心技术.
在特征描述方面,特征描述能够抽象出目标的外观,经过一个映射过程,将原始图像像素空间映射到一个维度可分的特征空间,鲁棒的特征描述应该具有以下性质:1)较强的泛化能力,能够应对各种遮挡、外观变化等不确定因素;2)较高的区分性,模型能够对背景和非目标物体保持较好的判别性;3)较小的计算量,能够达到跟踪的实时要求.传统跟踪算法提取特征主要是基于人工设计特征如HOG特征[4]、SIFT特征[5]、LBP特征[6]等.这些手工特征属于浅层特征范畴,带有一定的先验知识,特征提取速度快,容易实现,计算量小,对于某些特定场景具有很好的表达能力和区分性.但泛化能力弱,不能从本质上刻画目标物体,设计后不能自适应外观变化来应对的复杂场景中的跟踪任务,特别是在目标物体外观发生剧烈的变化的时候,手工设计的特征已经不能够保证准确的描述,最终导致模型“漂移”.由于实际场景中的目标外观变化具有高度非线性、动态性、任务依赖性等特点,而这些浅层特征提取器在目标表观模型上结构简单,从而提取的特征泛化能力不够,很难满足实际场景应用.
如何从视觉样例中构建一个自适应鲁棒特征表达一直是一个亟待解决的问题.但近期的研究表明,深度学习技术通过模仿人脑视觉皮层的感知系统能够很好的获取目标的外观表达,它通过多层的函数结构,多次非线性函数映射,提取目标特征的工作机制符合人脑的视觉系统所观察事物的原理,使得最后提取出来的特征高度抽象,包含丰富的语义信息,增加了区分度,这种深度特征模型增强了模型的特征表达能力.
一般来说,在提取完目标物体特征之后,目标表观建模可分为生成式模型和判别式模型.
生成式模型主要是借助模型匹配思想,着重于对目标本身的描述,提取目标特征之后通过搜索候选区域最小化重构误差,也就是搜索最接近目标的候选区域作为目标对象.经典的基于生成式模型的目标跟踪算法有:基于子空间模型算法[30,31]、基于混合高斯模型算法[32]、基于低秩和稀疏表示模型算法[33-35]、基于核模型算法[36]等.这类算法很大程度上依赖目标物体历史状态的特征提取,来完善描述当前帧目标物体的能力,但是没有充分利用目标周边的上下文信息,导致判别性不够,在背景干扰、遮挡等复杂场景下是不够鲁棒的.
判别式模型主要是借助分类思想,判别式模型将目标跟踪问题看成一个二分类的问题,通过训练一个在线分类器,从不断变化的局部运动背景中区分出目标(前景)与背景,经典的判别式目标跟踪算法有:基于岭回归跟踪算法[37,38],基于多示例学习跟踪算法[39],基于在线boosting学习跟踪算法[12,13]、基于支持向量机跟踪算法[10,11]等.判别式方式因为能显著区分背景与目标信息,对复杂场景表现更为鲁棒,一直受到研究人员的追捧.但是如果训练出来的分类器判别性不够,模型不稳定,会累积跟踪误差导致发生模型漂移.判别式模型也没有充分利用历史帧目标状态在时间上的关联性,致使跟踪失败后由于跟踪算法随着模型的更新累积分类误差,当目标再次回到视野时跟踪器无法找回目标.
2.2 搜索策略选取
搜索策略也可以称为运动建模和搜索,主要作用是模型在上一帧目标位置附近搜索当前帧的所有可能的目标位置,并从这些候选的位置区域中估计出最优的目标位置.由于目标运动的复杂性和不确定性,对于搜索策略的选取显得尤为重要.一般来说,好的搜索策略能够自适应目标运动规律,搜索出更优更少的候选区域,缩小了搜索范围能够提高算法的效率,同时优质的候选区域间具有较少的重复率和较高的区分性,使得模型更加鲁棒且处理速度更快.根据不同的搜索方式,搜索策略可以分为以下几类:
1)基于滤波理论的搜索策略
基于滤波理论的搜索策略主要是经典贝叶斯滤波框架下的卡尔曼滤波算法[40]以及粒子滤波算法[41],通过散播离散的
粒子集合的思想来近似目标运动的不规律性和不确定性,最后加权粒子样本来估计目标当前分布状态.前者处理线性问题并且假设目标的状态符合高斯分布,应用具有局限性,后者由前者发展而来,粒子滤波通过蒙特卡罗技术能够处理非线性、非高斯问题,会根据粒子的重要度进行重采样,具有更高的广泛性和精确度.
基于滤波理论的搜索策略,能够融合不同种类的特征信息,具有较高的计算效率.但是对于复杂场景下的任务,需要更多的样本来描述后验概率分布,算法的复杂度就越高,对于粒子滤波来说,重采样会导致算法的退化,无法保证重采样后样本的多样性.如何选择合适的提议分布、避免算法的退化和保证样本的多样性是基于滤波理论算法的一个急需解决的问题.
2)基于滑动窗口的搜索策略
基于滑动窗口的搜索策略主要是基于局部穷举思想[1,2,28,29],在感兴趣区域内密集搜索所有可能范围来选取最优的目标状态.这种方法从局部区域考虑目标的可能状态,降低了计算复杂度,搜索比较全面.但是,随着搜索范围的增大,候选区域就变多,计算量就增加,有时候不得不采用简化表观模型和精简分类器的方法来补偿模型搜索匹配消耗的时间,不适用于感兴趣范围较大的搜索任务.
3)基于梯度优化的搜索策略
基于梯度优化的搜索策略典型的算法是均值漂移算法[36,42],均值漂移算法是一种基于梯度分析的非参数优化算法,以其计算量小、无需参数、快速模式匹配的特点受到普遍关注和广泛研究,均值漂移适用于目标形变、旋转变化的跟踪任务.它通过定义目标能量函数,采用梯度下降的策略来最小化能量函数进行目标的匹配和搜索,相对于滑动窗口搜索策略,它明显降低了计算强度,特别适用于对跟踪系统具有实时性要求的场景.但是均值漂移算法容易陷入局部收敛,对于初始搜索位置比较敏感,同时当目标发生严重遮挡或目标运动速度较快时,往往导致收敛于背景而不是目标本身.
2.3 模型的更新
模型更新决定了模型的更新策略和更新频率,由于受目标自身和外部环境变化的影响,目标的外观一直处于动态变化中,是一个非静态信号,目标的表观模型必须通过自动更新来适应目标物体的外观变化,所以说跟踪问题也可以看成是一个边跟踪边学习的过程.
目前大部分模型使用的是在线更新策略,比较常用的方法是用最近新的模型代替旧的模型.但由于跟踪过程中,目标物体很容易发生遮挡、形变等现象[2,29],使得获取到的正负样本经常是不完整、不精确、带有一定噪声污染,并且通常情况下大部分正负样本具有二义性,导致模型在更新过程中逐渐累积误差,使得最新的表观模型与实际目标表观发生很大偏差,从而导致“漂移”现象,这是跟踪领域中一直存在的问题.
目前主要的更新策略常用的有在每一帧中都进行更新、每隔一段时间间隔进行更新、用启发式规则指导更新即误差达到一定阈值进行模型更新等.这些方法虽然能在短时间内和可控场景下能够达到良好的效果,但是针对长时间跟踪、实际动态复杂场景中还是不够鲁棒,模型如何选择最优的在线更新策略还有待深入研究.
3 深度学习在目标跟踪上的应用
深度学习技术这几年来发展迅速且应用广泛,在文本、语音、图像三大领域取得了不俗的成绩.区别于传统跟踪算法设计好的手工特征和浅层分类器结构,深度学习技术通过构建多个非线性映射的隐藏层来模拟人脑视觉系统的分层结构,如图3所示,大脑由瞳孔摄入像素即原始图像信号,经大脑皮层视觉细胞来检测目标边缘和方向,抽象出物体的大致形状,最后进一步抽象并推测物体类别.深度网络经前馈传播过程中将原始信号进行逐层特征变化,即变换特征空间,再经反向传播的梯度下降算法更新网络权重,通过这种自学习方式提取高度抽象的自适应特征,而且构建的网络规模在模型深度上也比传统的浅层分类器要深.

图3 深度网络模拟大脑视觉的分层处理过程Fig.3 Deep learning neural network simulate the brain′s visual hierarchical structure processing
目前来说,深度学习网络模型按照训练方式可分为两类:有监督模型和无监督模型.有监督模型有:多层感知机(MLP)、卷积神经网络(CNN)[21]、循环神经网络(RNN)[22]等.无监督模型有:深信度神经网络(DBN)[43]、自动编码机(ADE)[20]等.随着近些年深度学习技术在目标跟踪领域的发展,越来越多的深度网络模型应用到了跟踪领域并取得了不错的性能,我们依据各算法使用的主要深度神经网络框架和算法的显著特点将目前基于深度学习技术的跟踪算法分为以下4类:1)基于在线迁移和特征属性分析的跟踪模型;2)基于深度集成学习的跟踪模型;3)基于时空域信息的跟踪模型;4)基于相似度对比与回归的跟踪模型.我们总结了每类跟踪模型从深度学习技术开始应用到目标跟踪领域以来的典型算法,如表1所示,下面将对各类跟踪模型进行展开分析.
表1 基于深度学习技术的目标跟踪算法归类
Table 1 Classification of the object visual tracking algorithm based on deep learning

算法类别典型算法基于深度学习技术的目标跟踪算法归类(1)基于在线迁移与特征属性分析的跟踪模型DLT[44]、SO⁃DLT[45]、MDNet[46]、DeepTrack[47]、CNN⁃SVM[48]、HCFT[49]、FCNT[50]、DeepSRDCF[51]等(2)基于深度集成学习的跟踪模型TCNN[52]、SCTC[53]、HDT[54]等(3)基于时空域信息的跟踪模型RATM[55]、DeepTracking[56]、ROLO[57]、RTT[58]、SANet[59]等(4)基于相似度对比与回归的跟踪模型SiameseFC[60]、SINT[61]、YC⁃NN[62]、GOTURN[63]等
3.1 基于迁移学习与特征属性分析的跟踪模型
深度学习强大的自适应特征提取能力主要依靠海量的标注数据集来训练网络,对于目标跟踪任务来说,由于只能使用第一帧的带标签的图像帧,使得缺乏足够的样本来训练深度网络提取特征.近些年来,研究者们发现通过迁移学习的方法,借助其他相近领域(如:目标检测、图像分类、图像识别等)的大型数据集来预训练网络然后迁移到跟踪任务上,能够达到了良好的效果.
2013年,Wang等人[44]第一次将深度学习技术应用到跟踪领域,他提出了一种离线预训练与在线微调的思路,搭建了一个四层的栈式自编码器,在一个大型小尺度数据集(图片大小为32*32)上离线预训练模型,然后借助跟踪数据集的第一帧带标注的样本来进行在线微调,解决了训练样本不足的问题.但是由于训练样本和跟踪序列有明显差距,加上栈式自编码器对重构过程中会引入了大量噪声,网络结构也只有四层且用的全连接层比较多,使其对目标的表外特征刻画能力不足,计算代价大,性能甚至低于一些基于手工特征的跟踪方法.但是,它为深度学习技术解决跟踪问题开辟了一个新的研究思路,后续大量的基于深度学习的跟踪算法基本上都是延续这种迁移学习的思路来进行的.
随着深度学习在计算机视觉领域的快速发展,研究人员发现,有监督方式的卷积神经网络(CNN)[21]结构相对于其他网络结构有更好的图像抽象能力,卷积网络结构图如图4所示,卷积神经网络(CNN)主要包括卷积层、池化层、全连接层三个关键层类型.其中卷积层能够很好的的保留图像像素邻域之间的联系和局部空间结构的特点,保证了图像的旋转不变性和平移不变性.池化层减少了特征图的维度,但保留了重要的特征信息,并扩展了下一层的感受野范围.这些特性使得卷积神经网络在计算机视觉领域引起了广泛关注,一大批优秀的卷积网络模型被提出来,从最初5层的LeNet[21]衍生出了AlexNet[15],GoogleNet[64],VGGNet[16],ResidualNet[14]等具有代表性的深度卷积网络模型,网络结构分别从宽度和深度上进行加深.同时研究人员发现从这些预训练好的深度卷积神经网络的不同卷积层可以学习到不同的特征信息,图5展示了分别从VGG19[16]深度网络中可视化Conv3-4(第8层),Conv4-4(第12层),Conv5-4(第16层)卷积层的特征图,从图中可以看出底层特征保留了丰富的空间结构信息,高层特征则更加抽象,充分使用这些层次特征能够使得模型更加鲁棒,来应对不同的物体外观变化.
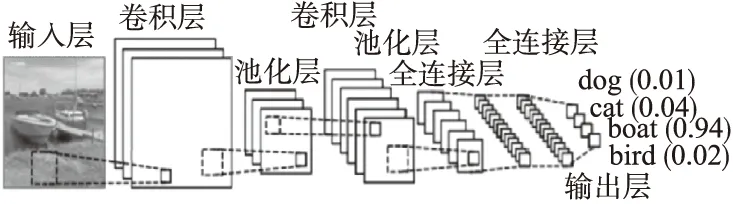
图4 卷积神经网络(CNN)结构图Fig.4 Structure chart of the convolutional neural network(CNN)
近几年来,由于这些深度卷积网络模型在目标检测、图像分类等领域取得了巨大的成功,研究人员开始考虑是否这些不同深度卷积网络模型同样能应用到目标跟踪领域?并且开展了一系列深入的研究.
Wang等人[45]延续了离线训练在线微调的思想,先在大规模图像数据集上离线训练网络模型识别物体与非物体区域,跟踪时用第一帧样本进行在线微调,将不同尺度的候选区域输入网络得到不同的概率图输出,最后经边界框回归确定最优尺度,在模型更新过程中采用了针对处理误判的长时更新和外观变化的短时更新策略,达到了良好性能.

图5 深度卷积网络(VGGNet)获取到的层次特征Fig.5 Hierarchical features get from the deep convolutional neural network(VGGNet)
Danelljan等人[51]同样借助迁移学习的方法学习特征,同时认为跟踪任务不同于检测和分类任务,由于跟踪任务对于位置精确度的要求比较高,底层的卷积特征具有的较高的区分性和丰富的空间结构信息,可能对于跟踪问题来说更为重要,但Danelljan等人只注意到了底层的特征空间结构特性而忽略了高层特征的语义特性.
Ma,Wang等人[49,50]进行了更深入的研究,他们对于从预训练深度卷积网提取出来的分层特征属性进行了细致的分析,他们认为不同层特征具有不同属性,高层特征和底层特征对于目标的表观建模都非常重要,高层特征抽象出图片块的语义信息,可以作为一个类间分类器,做粗略的定位,对于目标发生形变、遮挡等表观变化比较鲁棒.底层特征具有丰富的纹理信息和空间特征,可以用来作为类内分类器,并且底层特征对位置变化比较敏感,可以用来对目标位置微调.他们认为通过有效的方式(如加权融合、阈值选取等)充分利用各个层次特征的优点从而达到可以精确定位效果.
基于在线迁移和特征属性分析的跟踪模型在近几年来用的比较广泛.主要是由于基于迁移学习的思想能够缓解跟踪任务训练样本缺失的问题.同时,用迁移学习的方法训练深度卷积网络,由于卷积网络分层结构的特点,从而我们可以充分利用不同层特征的属性来应用到跟踪过程中的不同场景.但是大部分迁移学习的方法还是从利用非跟踪数据集来训练,这与跟踪任务还是有一定差距,导致对于目标刻画的准确度上还有待进一步改善.另外,我们知道目标周边区域的时空上下文对于跟踪任务时非常重要的,大部分深度网络提取到自适应特征并没有考虑目标附近区域的时空上下文信息,导致学习到的特征判别性不够.而且,对于这些深度网络来说,由于模型层数比较深,导致所要学习的参数空间也较大,处理图像帧的速度就降低,如何优化参数空间,达到跟踪上的实时需求还有待进一步研究.
3.2 基于深度集成学习的跟踪模型
考虑到单个跟踪器跟踪的结果可能不稳定、不可靠,通过结合深度学习和传统的集成学习的方法,以自适应加权组合的方式将多个弱分类器合成一个强分类器来提高模型的判别能力和稳定性也是目前的跟踪领域研究热点.传统的集成学习方法常用的有以下几类:在线Boosting算法[12,13]、在线Adaboost算法[65]、随机森林[66-69]等.基于深度集成学习的基本框架如图6所示,该跟踪模型主要通过传统的集成学习的方法来直接训练深度模型或者结合深度学习技术训练多个弱分类器动态整合成一个强分类器,然后对前景和背景进行分类.这类跟踪模型具有很好的判别能力、稳定性,防止了模型的过拟合.如何自适应选择弱跟踪器的数量和和每个弱跟踪器的最优权重来减少模型的内存消耗从而构建最优的强跟踪器,是一个需要深入研究的问题.
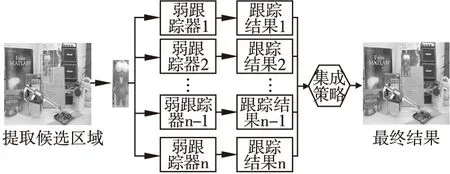
图6 基于集成学习的目标跟踪模型Fig.6 Tracking model based on ensemble learning
Qi等人[54]通过在分层深度卷积特征上学习多个相关滤波器作为专家系统,并借助在线自适应Hedged算法负责计算并更新每个弱跟踪器的权重,然后融合成一个强跟踪器,跟踪的结果由最后的强相关滤波器得到的响应图中估计出来.
Wang等人[53]提出了一种以序贯集成学习的方法来解决训练深度卷积网络中训练样本少的问题,目的是训练一个强的深度网络分类器,他们将每个通道的卷积特征看成一个基本的分类器,通过不同的损失函数独立更新,这样使得在线微调CNN就变成了一个连续的集成学习训练过程.最后将跟踪问题看成一个前景和背景分类的问题.
Nam等人[52]基于决策树思想提出了一种基于树结构的多个卷积神经网络模型集成学习方法来提取目标物体不同状态的外观特征,通过树的多分支结构以加权策略确定目标最优状态,同时选择最优路径进行模型的在线更新,此模型具有分类效果好、稳定性强的特点,但随着分支的增多和树路径的加深,会使跟踪速度下降.
3.3 基于时空域信息的跟踪模型
尽管基于卷积神经网络(CNN)的跟踪模型相对于传统跟踪算法已经取得了很大进步,但是跟踪问题毕竟是一个在时间序列上的问题,而基于卷积神经网络的模型每次只能对当前帧的目标表观进行建模,并没有考虑到当前帧与历史帧之间的关联性.同时提取出来的深度特征往往随着网络层数的加深,特征变得高度抽象,丢失了目标自身的结构信息,并且仅关注于目标本身的局部空间区域,忽视了对目标周边区域的上下文关系进行建模.然而这些内部结构信息和周边区域的上下文信息对于提高模型的判别性具有很大的作用.所以基于深度卷积网络的模型的算法在时间上的连续性和空间信息建模方面还有待改善.针对于这些问题,近年来,循环神经网络(RNN)凭借具有处理历史信息,建模时间、空间上的强关联性能力开始受到研究人员的关注.
循环神经网络(RNN)[22]最初在文本和语音领域取得了很大成功,因其具有历史信息记忆功能,常用来对时间序列进行建模,目前来说随着RNN的深入研究,也用RNN来建模图像空间结构上像素级的依赖性.循环神经网络目前也发展出了很多有代表的网络模型,比较常用的模型有:传统RNN模型,长短时间记忆网(LSTM)[70],双向RNN[71],GRU[72]等,网络结构如图7所示.研究人员也尝试着借助RNN的优势来应用到跟踪任务上,并且做了大量研究.
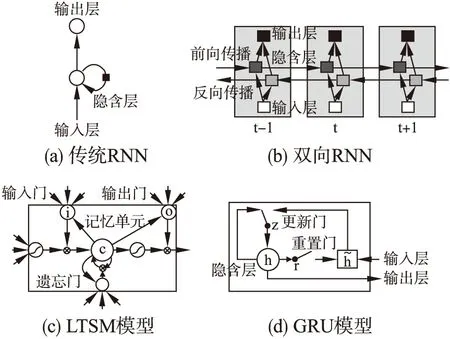
图7 常用的RNN网络结构Fig.7 Common structures of the recurrent neural network
在时间域上,RNN通常用来建模视频序列之间的依赖关系.Kahou等人[55]在跟踪过程中用RNN训练注意力机制来提取当前时刻感兴趣区域,同时用RNN负责保留历史帧中的受关注目标区域块,并预测在下一时刻的位置.Ondruska等人[56]通过人工生成数据训练RNN来预测目标在每一帧的概率分布,并保留历史帧目标位置的概率分布来指导当前帧的预测,从而直接预测边界框的坐标,这也是一种注意力机制.以上两个方法都是使用传统的RNN结构来对图像帧的时间关系进行建模,但只适用于简单的人工生成的序列上,很难应用到实际场景.Ning等人[57]结合tracking-by-detection 的思想设计了一个循环卷积网络模型,用一个最流行的目标检测器YOLO[73]粗略的检测出每一帧的目标区域大致坐标,并收集鲁棒的特征信息,同时输入到堆栈的LSTM中直接回归出当前帧的目标位置,这种模型同时结合了时间域上的关联性和空间域上结构关系使得模型更加有效,能够对于遮挡、短时间目标丢失等场景具有很好的鲁棒性.
在空间域上,由于图像区域中内部结构信息的关联性是普遍存在的,而这种关联性可以转化为像素间的循环依赖关系,所以只需遍历图像上的像素点来形成RNN输入序列.与处理时间序列不同,从整体上看,此时RNN主要建模目标区域内部空间结构与附近区域上下文的依赖性,从像素级看,RNN建模的是大范围像素间的邻域关系.Cui等人[58]利用多方向递归神经网络在二维平面上来预测一个可信区域来缓解遮挡问题和判断模型更新,同时作为一个正则化项引入到相关滤波器中,抑制背景干扰,增强目标区域的可信度,提高了滤波器的判别性,是第一个将RNN来建模跟踪任务中样本空间结构上的依赖关系,但整个框架是基于HOG特征和传统的RNN结构,可能出现目标表观刻画不足和梯度消失等问题.Fan等人[59]认为卷积特征主要适用于类间分类,缺乏对目标自身结构的描述,很难用于区分同类非目标物体,他们提出结合深度卷积网络和多方向RNN,在卷积网络中多个下采样层后利用多方向RNN建模目标物体自身的空间结构,同时利用跳越连接(skip concatenation)策略[74]将卷积特征与RNN提取到的自身结构图进行融合并作为下一层的输入,用多分支域思想训练网络.这种关注于目标内部结构的网络丰富了特征图的结构信息,提高对二义性物体的判别性,提高了模型的准确率.
3.4 基于相似度对比与回归的跟踪模型
目标跟踪问题本质上还是一个检测和验证的问题,一个好的跟踪模型不仅要有着较高的准确率和鲁棒性,同时要满足跟踪的实时性需求.先前的深度模型需要在线更新过程以及较大的参数空间,虽然有着较高的鲁棒性但运行速度缓慢.2016年以来,出现了基于相似度对比的孪生网络(Siamese Network)模型[23]来应用到跟踪任务当中,基于孪生网络的跟踪模型是训练一个完全端到端的模型,没有动态更新过程.该模型算法流程图如图8所示,它的输入是一个样本对,分为示例样本和候选样本,通过离线训练模型来评估两个输入样本的的相似程度,决策层决定采用哪种匹配算法计算相似度,匹配程度最高的候选样本作为目标当前最优区域.
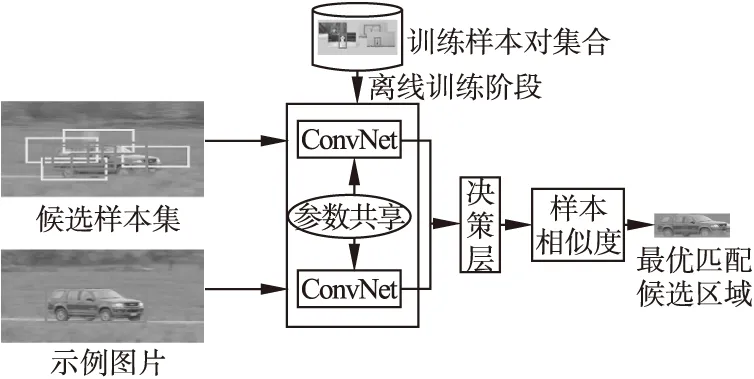
图8 基于孪生(Siamese)网络模型的目标跟踪算法流程图Fig.8 Tracking model based on Siamese neural networok
Tao等人[61]基于在线多示例的思想,提出通过提取大量的外部视频样本数据对来离线训练深度孪生网络学习一个先验的匹配函数,训练好的孪生网络能自动判断输入实例数据对的相似度,找出和第一帧样本最相似的图像候选块作为目标区域,可以应对各种外观变化,但对严重遮挡、剧烈的外观变化以及类内区分鲁棒性较低.
Bertinetto等人[60]注意到了跟踪问题对于特征图的空间结构比较敏感,使用的siamese网络采用了全卷积结构,只在网络浅层用了较少的池化层并摘掉了后面的全连接层.同时通过使用较小的示例图片特征图对较大的候选区域特征图进行卷积运算,计算数据对之间的内相关,本质上也是计算两个样本的相似度,结果输出一张响应图.然后搜索响应值最大的位置作为目标的大致位置.
Chen等人[62]做法与Bertinetto等人类似,同样是输出一张响应图,但他们是通过最后的全连接层直接回归响应图输出,并且在后面的全连接层中融入了前面卷积层的提取的特征,最后输出的响应图是通过随机选取历史帧已确定的响应图与当前帧的输出加权得到,充分考虑了历史状态的影响,训练过程中对于候选样本进行了大量的数据仿射处理(如旋转、光照变化、加入噪声等)来模拟实际场景下目标外观的不断变化,极大的增大了样本空间.
Held等人[63]通过在静态图片和连续的动态视频序列上提取数据对来训练一个更加精简的孪生网络模型,他们通过合理的设计带偏移量标注的样本对和损失函数,使得训练好的模型能够直接回归出目标区域的坐标和尺度的偏移量,速度达到了100fps,但算法对于那些快速运动、偏移量较大的场景还有待提高.
基于相似度对比与回归的跟踪模型主要是借助孪生网络的双通道输入的结构特点,用大量的样本对,学习一个匹配函数.此类模型的关键主要在训练阶段,需要设计合理的带标注的数据对和损失函数,一旦模型训练好了,就是一个完全不需要更新,端到端的运行的模型,此类算法在速度上更有优势,但该类模型需要大量的视频跟踪样本对,对于训练阶段来说,设计合理的损失函数至关重要.同时该模型对于严重遮挡、移动距离过大,非相似目标物体的判别性还不够鲁棒.
4 总结与展望
尽管深度学习近年来在计算机视觉获得了快速发展,并且在目标跟踪问题中也显示出了其深度模型的有效性,其应用过程也并不是一帆风顺,依然面临着严峻的挑战.我们认为深度技术在目标跟踪领域涉及的困难主要集中在以下几个方面:1)深度模型需要估计一个较大的参数空间,因此需要足够的训练样本,然而对于跟踪问题来说,由于只能使用有限的第一帧的标注样本作为正样本来训练网络,导致训练数据的缺失.2)使用迁移学习的方法预训练模型需要大量时间消耗,同时这种离线学习得到广义特征缺乏对所跟踪目标的判别性.3)目标跟踪过程中用在线更新得到的新样本带有大量噪声,用这些带有噪声的样本训练网络,会使模型的稳定性下降,导致模型“漂移”问题.4)深度学习模型在线训练过程需要大量的时空和计算资源.5)目前大部分的深度模型还集中在对样本空间结构上的描述,缺乏对整个跟踪序列时间维度上的建模,很难应对目标物体表观分布的复杂多样性和非静态性.6)跟踪算法在实时性和准确度上达到平衡依旧任重道远.
综上所述,深度学习在目标跟踪领域中还有很大提高的空间,以后的研究方向可以从以下几个方面进行展开:1)首先,在目标的表观建模方面,以深度学习理论为基础,探索如何有效的结合迁移学习、回归方法、集成学习、以及混合深度网络模型来构建鲁棒的基于深度学习的目标表观建模.2)其次,在目标的运动建模和搜索方面,如何采用高效的搜索策略为在线训练深度模型提供量少质高的正负样本集合也是值得深入研究.3)另外,在模型更新方面,自适应学习出的目标部件模型具有良好的灵活性,将其与局部背景结合,对于处理遮挡、非刚性形变等问题具有优势,结合深度学习的方法提取表观特征,能够构建一个鲁棒的跟踪模型.4)最后,在算法的实时性要求方面,如何通过优化算法减少参数空间,同时训练完全端到端的网络模型来对算法进行提速也是很重要的研究方向.
本文通过对传统算法进行回顾,重点对近期基于深度学习的目标跟踪算法进行分析与总结,指出了目标跟踪算法最新的研究状况,为研究人员提供参考.我们相信,随着深度学习的不断发展,更多更优秀的基于深度学习的目标跟踪算法将会呈现出来,并且应用到实际场景当中.
[1] Li X,Hu W,Shen C,et al.A survey of appearance models in visual object tracking[J].ACM Transactions on Intelligent Systems and Technology (TIST),2013,4(4):58.
[2] Wu Y,Lim J,Yang M H.Online object tracking:A benchmark[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2013:2411-2418.
[3] Guan Hao,Xue Xiang-yang,An Zhi-yong.Advances on application of deep learning for video object tracking[J].Acta Automatica Sinica,2016,42(6):834-847.
[4] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C].2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR′05),IEEE,2005,1:886-893.
[5] Lowe D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[6] Van De Weijer J,Schmid C,Verbeek J,et al.Learning color names for real-world applications[J].IEEE Transactions on Image Processing,2009,18(7):1512-1523.
[7] Ahonen T,Hadid A,Pietikäinen M.Face recognition with local binary patterns[C].European Conference on Computer Vision,Springer Berlin Heidelberg,2004:469-481.
[8] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
[9] Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[J].Cognitive Modeling,1988,5(3):1.
[10] Avidan S.Support vector tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(8):1064-1072.
[11] Bai Y,Tang M.Robust tracking via weakly supervised ranking svm[C].Computer Vision and Pattern Recognition (CVPR),2012 IEEE Conference on.IEEE,2012:1854-1861.
[12] Grabner H,Bischof H.On-line boosting and vision[C].2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR′06),IEEE,2006,1:260-267.
[13] Grabner H,Leistner C,Bischof H.Semi-supervised on-line boosting for robust tracking[C].European Conference on Computer Vision,Springer Berlin Heidelberg,2008:234-247.
[14] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C].2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016:770-778.
[15] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C].Advances in Neural Information Processing Systems,2012:1097-1105.
[16] Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[J].Computing Research Repository (CoRR),2014,abs/1409.1556.
[17] Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.
[18] Girshick R.Fast r-cnn[C].Proceedings of the IEEE International Conference on Computer Vision,2015:1440-1448.
[19] Ren S,He K,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[C].Advances in Neural Information Processing Systems,2015:91-99.
[20] Vincent P,Larochelle H,Bengio Y,et al.Extracting and composing robust features with denoising autoencoders[C].Proceedings of the 25th International Conference on Machine Learning,ACM,2008:1096-1103.
[21] LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[22] Zaremba W.An empirical exploration of recurrent network architectures[C].Processding of the 32nd International Conference on Machine Learning (ICML),2015:2342-2350.
[23] Bromley J,Bentz J W,Bottou L,et al.Signature verification using a “Siamese” time delay neural network[J].International Journal of Pattern Recognition and Artificial Intelligence,1993,7(4):669-688.
[24] Yin Hong-peng,Chen Bo,Chai Yi,et al.Vision-based object detection and tracking:a review[J].Acta Automatica Sinica,2016,42(10):1466-1489.
[25] Lu Ze-hua,Liang Hu,Tang He,et al.Survey of visual objects tracking[J].Computer Engineering & Science,2012,34(10):92-97.
[26] Yan Qing-sen,Li Lin-sheng,Xu Xiao-feng,et al.Survey of visual tracking algorithm[J].Computer Science,2013,40(06A):204-209.
[27] Huang Kai-qi,Chen Xiao-tang,Kang Yun-feng,et al.Intelligent visual surveillance:a review[J].Chinese Journal of Computers,2015,38(6):1093-1118.
[28] Smeulders A W M,Chu D M,Cucchiara R,et al.Visual tracking:an experimental survey[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(7):1442-1468.
[29] Wu Y,Lim J,Yang M H.Object tracking benchmark[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1834-1848.
[30] Li X,Hu W,Zhang Z,et al.Robust visual tracking based on incremental tensor subspace learning[C].2007 IEEE 11th International Conference on Computer Vision.IEEE,2007:1-8.
[31] Ross D A,Lim J,Lin R S,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1):125-141.
[32] Wang H,Suter D,Schindler K,et al.Adaptive object tracking based on an effective appearance filter[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2007,29(9):1661-1667.
[33] Bao C,Wu Y,Ling H,et al.Real time robust L1 tracker using accelerated proximal gradient approach[C].Computer Vision and Pattern Recognition,IEEE,2012:1830-1837.
[34] Zhang K,Zhang L,Yang M H.Real-time compressive tracking[C].European Conference on Computer Vision,2012:864-877.
[35] Zhang T,Ghanem B,Liu S,et al.Low-Rank sparse learning for robust visual tracking[C].European Conference on Computer Vision,Springer Berlin Heidelberg,2012:470-484.
[36] Yang C,Duraiswami R,Davis L.Efficient mean-shift tracking via a new similarity measure[C].IEEE Computer Society Conference on Computer Vision and Pattern Recognition.IEEE,2005:176-183.
[37] Henriques J F,Rui C,Martins P,et al.High-speed tracking with kernelized correlation filters[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(3):583-596.
[38] Henriques J F,Rui C,Martins P,et al.Exploiting the circulant structure of tracking-by-detection with kernels[J].Lecture Notes in Computer Science,2012,7575(1):702-715.
[39] Babenko B,Yang M H,Belongie S.Visual tracking with online multiple instance learning[C].Computer Vision and Pattern Recognition(CVPR 2009),IEEE Conference on.IEEE,2009:983-990.
[40] Kalman R E.A New Approach to linear filtering and prediction problems[J].J.basic Eng.trans.asme,1960,82D(1):35-45.
[41] Isard M,Blake A.Condensation-conditional density propagation for visual tracking[J].International Journal of Computer Vision,1998,29(1):5-28.
[42] Comaniciu D,Ramesh V,Meer P.Real-time tracking of non-rigid objects using mean shift[C].Computer Vision and Pattern Recognition,Proceedings.IEEE Conference on.IEEE,2000:2142.
[43] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.[J].Neural Computation,2006,18(7):1527-1554.
[44] Wang N,Yeung D Y.Learning a deep compact image representation for visual tracking[J].Advances in Neural Information Processing Systems,2013:809-817.
[45] Wang N,Li S,Gupta A,et al.Transferring rich feature hierarchies for robust visual tracking[J].arXiv preprint arXiv:1501.04587,2015.
[46] Nam H,Han B.Learning Multi-domain convolutional neural networks for visual tracking[C].2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016:4293-4302.
[47] Li H,Li Y,Porikli F.DeepTrack:learning discriminative feature representations online for robust visual tracking[J].IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,2015,25(4):1834-1848.
[48] Hong S,You T,Kwak S,et al.Online tracking by learning discriminative saliency map with convolutional neural network[C].Proceedings of the 32nd International Conference on Machine Learning(ICML),2015:597-606.
[49] Ma C,Huang J B,Yang X,et al.Hierarchical convolutional features for visual tracking[C].IEEE International Conference on Computer Vision,2015:3074-3082.
[50] Wang L,Ouyang W,Wang X,et al.Visual tracking with fully convolutional networks[C].IEEE International Conference on Computer Vision,2016:3119-3127.
[51] Danelljan M,Höger G,Khan F S,et al.Convolutional features for correlation filter based visual tracking[C].IEEE International Conference on Computer Vision Workshop,2015:621-629.
[52] Nam H,Baek M,Han B.Modeling and propagating CNNs in a tree structure for visual tracking[J].arXiv preprint arXiv:1608.07242,2016.
[53] Wang L,Ouyang W,Wang X,et al.STCT:sequentially training convolutional networks for visual tracking[C].IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society,2016:1373-1381.
[54] Qi Y,Zhang S,Qin L,et al.Hedged deep tracking[C].IEEE Conference on Computer Vision and Pattern Recognition,2016:4303-4311.
[55] Kahou S E,Michalski V,Memisevic R.RATM:recurrent attentive tracking model[J].arXiv preprint arXiv:151008660,2015.
[56] Ondruska P,Posner I.Deep tracking:seeing beyond seeing using recurrent neural networks[C].Proceedings of the 30th AAAI Conference on Artificial Intelligence,2016:3361-3368.
[57] Ning G,Zhang Z,Huang C,et al.Spatially supervised recurrent convolutional neural networks for visual object tracking[J].arXiv preprint arXiv:1607.05781,2016.
[58] Cui Z,Xiao S,Feng J,et al.Recurrently target-attending tracking[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:1449-1458.
[59] Fan H,Ling H.SANet:Structure-aware network for visual tracking[C].IEEE Computer Vision and Pattern Recognition,2016.
[60] Bertinetto L,Valmadre J,Henriques J F,et al.Fully-convolutional siamese networks for object tracking[C].European Conference on Computer Vision.Springer International Publishing,2016:850-865.
[61] Tao R,Gavves E,Smeulders A W M.Siamese instance search for tracking[C].Computer Vision and Pattern Recognition,2016:1420-1429.
[62] Chen K,Tao W.Once for all:a two-flow convolutional neural network for visual tracking[J].arXiv preprint arXiv:1604.07507,2016.
[63] Held D,Thrun S,Savarese S.Learning to track at 100 FPS with deep regression networks[C].European Conference on Computer Vision.Springer International Publishing,2016:749-765.
[64] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[65] Santner J,Leistner C,Saffari A,et al.Prost:parallel robust online simple tracking[C].Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on.IEEE,2010:723-730.
[66] Saffari A,Leistner C,Santner J,et al.On-line random forests[C].Computer Vision Workshops (ICCV Workshops),2009 IEEE 12th International Conference on.IEEE,2009:1393-1400.
[67] Schulter S,Leistner C,Roth P M,et al.On-line hough forests[C].Proceedings of British Machine Vision Conference(BMVC),2011:1-11.
[68] Gall J,Yao A,Razavi N,et al.Hough forests for object detection,tracking,and action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(11):2188-2202.
[69] Godec M,Roth P M,Bischof H.Hough-based tracking of non-rigid objects[J].Computer Vision and Image Understanding,2013,117(10):1245-1256.
[70] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[71] Schuster M,Paliwal K K.Bidirectional recurrent neural networks[J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[72] Cho K,Van Merrienboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[C].Proceedoings of the 2014 Conference on Empirical Methods in Natural Language Processing,2014:1724-1734.
[73] Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C].2016 IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[74] Bell S,Zitnick C L,Bala K,et al.Inside-outside net:detecting objects in context with skip pooling and recurrent neural networks[C].2016 IEEE Conference on Computer Vision and Pattern Recognition,2016:2874-2883.
附中文参考文献:
[3] 管 皓,薛向阳,安志勇.深度学习在视频目标跟踪中的应用进展与展望[J].自动化学报,2016,42(6):834-847.
[24] 尹宏鹏,陈 波,柴 毅,等.基于视觉的目标检测与跟踪综述[J].自动化学报,2016,42(10):1466-1489.
[25] 吕泽华,梁 虎,唐 赫,等.目标跟踪研究综述[J].计算机工程与科学,2012,34(10):92-97.
[26] 闫庆森,李临生,徐晓峰,等.视频跟踪算法研究综述[J].计算机科学,2013,40(06A):204-209.
[27] 黄凯奇,陈晓棠,康运锋,等.智能视频监控技术综述[J].计算机学报,2015,38(6):1093-1118.
