基于OPTICS聚类的差分隐私保护算法的改进
2018-03-20葛丽娜王苏青王丽颖张翼鹏梁竣程
王 红,葛丽娜,王苏青,王丽颖,张翼鹏,梁竣程
(1.广西民族大学 信息科学与工程学院,南宁 530006; 2.广西民族大学 东盟研究中心(广西科学实验中心),南宁 530006; 3.深圳市亿威尔信息技术股份有限公司,广东 深圳 518000; 4.广西广播电视信息网络股份有限公司,南宁 530006)(*通信作者电子邮箱66436539@qq.com)
0 引言
随着网络技术的发展,信息量呈现爆炸式的增长,如何收集、管理、分析和发布数据成为信息技术研究的重点。目前,以机器学习和数据挖掘为基础的高级数据分析处理技术,使得在分析、使用数据上更加方便,但对于数据发布者来说,不经过任何处理随意将有关用户的敏感信息进行发布,将给用户带来不可预测的后果。近年来的信息安全事件频繁发生,从QQ号码被盗取、手机下载带有病毒性的APP到电子银行钱财的丢失,不少不法分子利用安全漏洞以及用户敏感信息的泄露,给用户造成了很大的困扰和损失,这就要求信息安全领域加强隐私信息保护的力度,给公众用户一个安全的网络平台。而最早的匿名隐私保护技术需要特殊的背景攻击假设,一旦攻击者掌握足够相关信息,便容易出现链接攻击和背景攻击。Dwork[1]定义了及其严格的ε-差分隐私保护模型:即使攻击者已经知道除一条记录外的所有记录的敏感属性,仍然无法推断出有关这条记录的任何敏感属性,通过添加随机噪声便能够对用户的敏感信息进行保护,同时保持添加过噪声后的数据的统计性和属性不变。目前,差分隐私保护在人口统计、推荐系统、网络数据分析、搜索日志等方面有着重要应用。
对吴伟民等[2]提出的DP-DBSCAN(Differential Privacy-Density-Based Spatial Clustering of Applications with Noise)差分隐私保护算法分析,针对DBSCAN(Density-Based Spatial Clustering of Applications with Noise)[3]算法对参数输入敏感性的问题,本文将DBSCAN算法的改进算法——OPTICS(Ordering Points To Identify Clustering Structure)[4]算法应用于差分隐私保护中,进而提出改进算法——DP-OPTICS(Differential Privacy-Ordering Points To Identify Clustering Structure)差分隐私保护算法。
1 差分隐私研究现状
2006年Dwork首次提出了ε-差分隐私保护模型,主要是针对个人敏感信息泄露进行隐私保护的一项技术,根据添加噪声顺序不同分为两种方式:1)对原始数据直接添加噪声机制,然后发布数据。这种方法的隐私保护性比较高,但是数据可用性较低。2)先对原始数据进行转换、压缩、随机扰动等技术预处理,再对数据添加随机噪声,最后发布数据。这种方法信息有所缺损,但在减少发布误差和提高数据可用性上有很大帮助。按照处理方式的不同主要有聚类变换、分类变换、层次树变换、傅里叶变换等技术,其中聚类技术在这几项预处理技术中关于数据发布的精度和时间复杂度整体对比上是比较优良的。
Blum等[5]中首次将基于SuLQ框架的k-means算法应用在差分隐私中;针对Blum所提方法应用存在聚类结果可用性低的问题,Nissim等[6]提出抽样—聚合框架随机对抽样数据进行聚类,但是这种聚类方式只能在局部取得较好效果;Dwork等[7]进而从预算分配的角度对基于k-means的差分隐私保护算法进行了完善,但是仍然存在差分隐私保护k-means聚类结果可用性差的问题;李杨等[8]提出了IDPk-means聚类方法,使得聚类的可用性有较大提高。在满足ε-差分隐私保护条件下,吴伟民等首次将基于密度的DBSCAN聚类算法用于差分隐私保护中,但是由于DBSCAN算法自身存在对参数输入敏感的问题,进而影响聚类效果以及噪声添加,最终将会影响数据发布的可用性。OPTICS算法是在DBSCAN算法的基础上进行改进的算法,解决了DBSCAN算法对参数输入敏感的问题,本文将OPTICS算法应用于差分隐私保护中,并提出相关的改进算法——DP-OPTICS算法。
2 差分隐私保护相关知识
1)ε-差分隐私保护的定义。
定义1ε-差分隐私[1]。对于数据集D1和D2,至多存在一条不同的记录(称D1和D2为兄弟数据集),Range(K)为随机算法K的取值范围,如果算法K在数据集D1和D2上的任意输出为M∈Range(K),能够满足:
Pr[K(D1)∈M]≤eε×Pr[K(D2)∈M]
(1)
则称为算法K满足ε-差分隐私。其中,Pr[K(D1)∈M]、Pr[K(D2)∈M]分别为输出K(D1)和K(D2)为M的概率,ε是差分隐私参数,用来表示隐私保护程度,ε越小表示隐私保护程度越高、隐私泄露风险越低;反之,隐私泄露风险越高。
2)敏感度。
定义2 敏感度。差分隐私保护模型中敏感度是决定加入噪声大小的关键参数,它指删除数据集中任何一条记录对查询结果造成的最大影响。一般可以把敏感度分为全局敏感度[1]和局部敏感度[5]。给定一个函数集F、数据集为D、结果集为R,函数集中的任一函数f存在f(D)∈R,则F的全局敏感度为:

(2)
文中所提到的敏感度均为全局敏感度,D1和D2为兄弟数据集。
3)噪声机制。
差分隐私保护算法的实现,主要是对敏感数据集中的数据信息添加噪声,主要采用Laplace机制[9]和指数机制[10]。Laplace机制仅使用于数值型查询结果,指数机制可以适用于实体对象、事务型等的查询结果。本文主要采用Laplace机制。
定义3 Laplace机制。对于任意一个函数f:D→Rd,如果随机算法K满足ε-差分隐私,则向查询结果中f(D)添加噪声lap(Δf/ε),响应值为:
K(D)=f(D)+lap(Δf/ε)
(3)

4)添加噪声的方式。
定义4 同/异方差加噪方式[11-12]。在不考虑用户查询兴趣点分布不均匀的情况下,认为随机查询的每个数据属性概率相同。若任意一条记录i1和i2被查询的概率相同,有隐私预算参数εi1=εi2则称为同方差加噪方式;如果考虑记录i1和i2被查询的概率不相同,则隐私预算参数εi1≠εi2,则称为异方差加噪方式。
5)差分隐私的组合性质[13]。
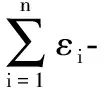
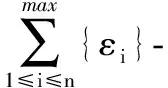
6)隐私参数ε的选取。
隐私参数ε越小,所得到的数据隐私保护性越高,攻击者能够获取具体的数据信息记录就越困难,但是足够小的隐私参数导致数据的可用性降低。如何选取隐私参数ε,一直是差分隐私保护的重要话题。何贤芒等[14]在Lee等[15]的基础给出定理1以及定理2,具体内容如下。
定理1 采用Laplace机制分布给函数f(D)添加lap(Δf/ε)噪声,则结果集f(D)+lap(Δf/ε)落在(-∞,f(D)+μ+L)概率为:
(4)
其中:μ为概率密度中心位置参数,L为改变位置参数的变量值,可以给定具体数值。
定理2 设位置参数μ=0,L=0.5的情况下,攻击者对于结果数据集查询成功的概率是:
(5)
只要攻击者所查询的成功概率ρ≤δ,就能有效保证数据的隐私安全性,则隐私参数ε的选取上界满足以下条件即可:
ε≤[ln 2(1-ρ)Δf]/L
(6)
可以看出隐私参数ε的选取与数据集大小无关,仅仅与查询函数(Δf,L)和攻击者的成功概率ρ有关。
7)差分隐私保护算法的度量。
a)算法性能。通常考虑时间复杂度和渐进噪声误差边界作为性能的评价标准。
b)算法误差。通常采用欧氏距离[16]、相对误差[17]、绝对误差[18]、误差的误差[19]等来度量误差。
c)隐私预算参数ε的分配。常用的分配策略[20],比如线性分配、均匀分配、指数分配、自适用性分配以及混合策略分配等。
3 基于OPTICS聚类的差分隐私保护改进算法
3.1 基于OPTICS聚类的差分隐私保护
OPTICS算法和DBSCAN算法是基于密度的聚类算法,主要优点是能够根据数据集的稠密度发现任意形状的聚类,且对噪声数据不敏感,这些特点能够较好地符合用户查询数据的概率大小以及差分隐私保护算法预处理数据的特点。OPTICS算法是在DBSCAN算法的基础上引入了核心距离和可达距离[21]两个概念。具体定义如下。
定义5 对象的E邻域。给定对象半径E内的邻域为该对象的E邻域。
定义6 核心对象。如果对象E邻域内至少包含最小数目MinPts个对象,则称该对象为核心对象。
定义7 直接密度可达。给定一个对象集合D,如果p和q的E邻域内,而q是一个核心对象,则我们说对象p从对象q出发是直接密度可达的。
定义8 基于密度的簇。基于密度可达性的最大的密度相连对象的集合。不属于任何聚类中的数据或离散点被认为是低频对象。
定义9 核心距离(core-distance, cd)。对象p的核心距离是使{p}成为核心对象的最小E′。如果p不是核心对象,则p的核心距离没有定义。
定义10 可达距离(reachability-distance, rd)。对象q关于另一个对象p的可达距离是p的核心距离和p与q之间的欧几里得距离之间的较大值。如果p不是核心对象,p和q之间的可达距离没有定义。
基于OPTICS聚类的差分隐私保护算法如算法1所示。
算法1 基于OPTICS聚类的差分隐私保护算法。
步骤1 创建队列L1,L2,L,有序队列L1用来存储核心对象及核心对象的直接密度可达对象,并按可达距离的升序排序;结果队列L2用来存储样本点的输出次序;输出队列L用来存储聚类结果中添加Laplace噪声后的数据。
步骤2 如果样本集D中所有点都已处理完,则算法结束;否则选择一个未处理(不在L2队列中)且为核心对象的样本点,找到其所有直接密度可达样本点,如果该样本点不存在于结果队列中,则将其放入有序队列中,并按可达距离排序。
步骤3 如果L1为空,则跳转到步骤2;否则,从有序队列中取出第一个样本点(即可达距离最小的样本点)进行拓展,并将取出的样本点保存至L2中,如果它不存在L2当中的话:
a)判断该拓展点是否为核心点,如果不是,则删除该拓展点;否则找到该拓展点所有的直接密度可达点。
b)判断该直接密度可达样本点是否已经存在L2中,是则不处理;否则下一步。
c)如果有序队列中已经存在该直接密度可达点,如果此时新的可达距离小于旧的可达距离,则用新可达距离取代旧可达距离,有序队列重新排序。
d)如果L1中不存在该直接密度可达样本点,则插入该点,并对L1重新排序。
步骤4 将Laplace噪声添加到聚类簇中,输出添加噪声后的结果集存储在L中。
3.2 DP-OPTICS差分隐私保护算法
基于OPTICS聚类的差分隐私保护算法能解决输入敏感性问题,但是在时间消耗上,却是大于DP-DBSCAN算法的时间消耗,而且,处理稀疏型数据效果不好,因此本文利用基于密度聚类的OPTICS算法对参数输入不敏感的特性、能够发现任意形状簇的特点及对离散点数据不敏感,适合差分隐私保护算法对大数据预处理的优点,克服了OPTICS算法将离散点排在队列末尾的缺点,采用邻接表的形式存储聚类簇,对离散点采用压缩处理技术,考虑用户查询的概率、攻击者攻击成功的概率及高频点和离散点的比例添加异方差噪声确定隐私参数ε的比例,提出改进的基于聚类的差分隐私保护算法DP-OPTICS。
基于密度聚类的算法来说,两个数据点的距离越近,则属于同一簇的概率也就越大。DP-OPTICS差分隐私保护算法将以此作为假设背景,在基于OPTICS聚类的差分隐私保护算法的基础上,为每个对象增加邻接表refresh存储最近的相邻数据点,并利用邻接表中的指针域将低频点放入到与之相邻的高频区域所在的簇中,如果该对象附近没有相邻的高频区域,则将该对象聚集在相邻的低频数据点附近。DP-OPTICS差分隐私保护算法的主要思想是:为每一个核心对象创建邻接表,引入一个非排序的种子队列存储待扩张的点和一个r指针,r指针用来指向种子队列中可达距离最小的点。当种子队列中的点为核心对象时,将其邻域点直接更新到种子队列中;所有点更新完之后,搜索一次种子队列,将r指针指向种子队列中可达距离最小的点。当处理种子队列中下一个点时,只需取出r指针所指向的点即可。这种方法处理完种子队列中的每一个点后,都会遍历一次种子队列,找到可达距离最小的点,搜索一次种子队列的时间复杂度为O(n),在整体上时间复杂度有所降低。对于低频数据采用压缩的形式存储,具体的压缩方式采取在相同的邻域半径内,不是核心对象的点,如果满足[50%MinPts]个,则认为是一个簇或者认为该点为次核心点,否则就认为是离散点,添加较大噪声。
DP-OPTICS算法具体的流程如下。
算法2 DP-OPTICS差分隐私保护算法。
输入:数据集D、邻域半径E、给定点数MinPts,噪声lap(Δf/εi)和lap(Δf/εj)。
输出:具有添加Laplace噪声的可达距离信息的数据集。
步骤1 根据给定的数据集D、邻域半径E、邻域半径E内核心对象最少点的个数MinPts,创建种子队列L1、结果队列L2、邻接表refresh,指针r。遍历数据集,搜索每一个对象的E邻域,确定对象是否为核心对象,并为该对象创建邻接表存储邻域点,初始化L1、L2为空队列,指针r为空,标记数据对象为unprocessed。
步骤2 如果数据集D中所有点都已处理完,转至步骤5;否则选择一个未处理对象加入到L1队列中,将r指针指向该对象。
步骤3 若队列L1为空,则跳转到步骤2;否则,从L1中取出第一个样本点p(即可达距离最小的样本点)进行扩张。如果p不是核心点,设置其可达距离为Undefined,转至步骤4;否则,对p的邻接表内任一未处理的邻近点q作处理:
a)若q已经在队列L1中,q的可达距离小于旧值,则更新q的可达距离;
b)如果q不在L1队列中,则把p直接加入到L1队列的尾部,并转至步骤4。
步骤4 从L1队列中删除p,并将p及其可达距离写入结果队列中。遍历L1队列,制定r指针指向可达距离最小的对象并返回步骤3。
步骤5 在结果队列L2总按照陡峭下降和陡峭上升的区域来提取数据集簇,添加lap(Δf/εi)到高频数据簇中,添加lap(Δf/εj)到低频聚类簇中。
3.3 实验结果分析
3.3.1 实验环境
操作系统为Window 7;系统类型为64位操作系统;处理器为AMD Athlon II X4 640 Processor 3.00 GHz;安装内存(RAM)为4.00 GB;集成开发环境为Matlab R2012(a)、Weka3.6版本、Eclipse3.7.0;所采用的数据集来自Weka3.6版本中data文件夹下credit-g.arff数据集,Relation为german_credit;Instances为1 000;Attributes为21。
3.3.2 实验结果及分析
credit-g.arff数据集主要是关于德国信贷信息的统计,其中一共有1 000条记录,21个数据属性。数据各项属性具体如表1所示。
从统计出来的数据集来看,其中有关信用卡(credit)属性,信用历史(credit_history)、信用额度(credit_amount)、居住地(resident_since)、财产大小(property_magnitude)、现有信用卡(existing_credits)、工作(job)、个人电话(own_telephone)等都属于敏感信息,是需要保护的,因为可以根据信用历史、工作和财产大小、信用额等相关信息推测出个人的信用等级。虽然信用等级对于银行、政府数据库来说是属于公共隐私,但是对于个人来说还是属于个人隐私信息。
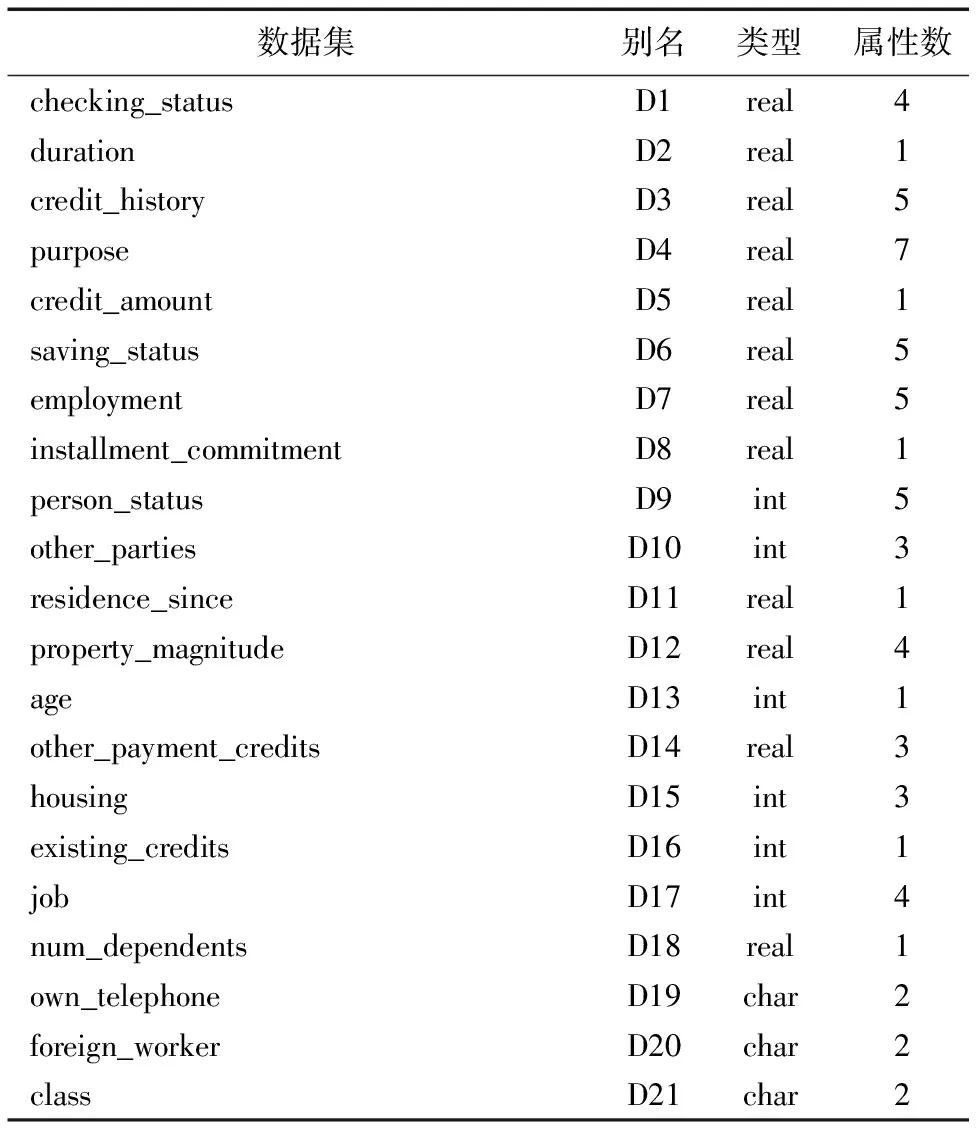
表1 credit.arff数据集属性
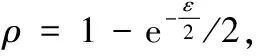
采用DP-DBSCAN算法、DP-OPTICS差分隐私保护算法和基于OPTICS差分隐私保护算法对credit-g.arff数据集1 000条记录进行多次实验,在邻域半径E和邻域半径内取得最少点数MinPts分别取值为{(0.1,5),(1,10),(5,10),(10,50),(0.5,8),(2,10),(10,20),(20,50)},取经过150次实验的平均值。对比分析如图1,DP-OPTICS在E和MinPts取得相对较小值的时候,局部聚类紧密性较好,整体上要比基于OPTICS聚类的差分隐私保护、DP-DBSCAN算法好。
在(E,Minpts,ε)分别取得{(0.1,5,0.1),(1,10,0.3),(2,15,0.5),(4,18,1.0),(6,20,1.2),(10,20,1.3),(15,25,1.5),(20,25,20)}的情况下,对高频数据和低频数据分别添加同方差Laplace噪声和异方差Laplace噪声(高频数据与低频数据仍然按照1∶20的比例添加噪声)后的相对误差,如图2。很明显图2表示了采用同方差方式添加噪声,聚类高频数据越多,其相对误差越大;而采用异方差方式添加噪声,因为平衡了总体上的噪声分配,所以整体上的误差相对较小,因此添加异方差噪声方式要比同方差噪声方式在处理数据上更优。
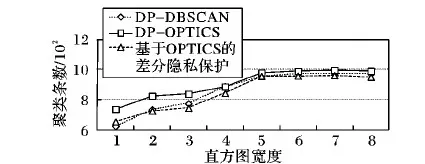
图1 相同E、MinPts、ε下的3种算法聚类结果对比
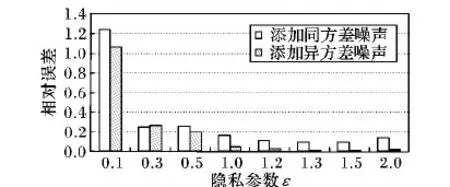
图2 添加两种噪声的DP-OPTICS相对误差对比
在ε取值相同,(E,MinPts)分别取值为{(0.1,5),(1,10),(3,13),(5,15),(10,15),(15,20),(20,25)}的情况下,采用DP-OPTICS算法、DP-DBSCAN算法和基于OPTICS聚类的差分隐私保护算法,经过多次实验取得150次实验平均值,三者的时间对比如图3。从图3可以看出,相比DP-DBSCAN算法和基于OPTICS差分隐私保护算法,DP-OPTICS采用邻接表形式,在空间复杂度比两者的空间复杂度都小,但是运行时间耗费介于DP-DBSCAN算法和基于OPTICS算法之间,因此从整体上来说DP-OPTICS算法还是可行的。
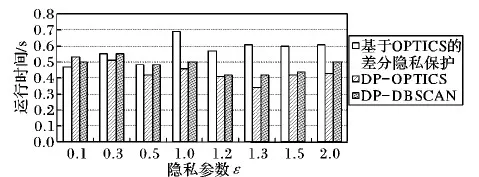
图3 3种算法的时间消耗对比
选择credit-g.arff数据集中credit_history、employment、personal_status等敏感属性信息用DP-OPTICS算法进行处理,同时选择与未经处理的原始数据作对比分析,在隐私参数ε=0.42的情况下添加异方差噪声,再转化为直方图进行隐私敏感信息保护,最后发布数据。具体如图4:横坐标是按照等宽直方图的方式划分距离,Raw data代表原始数据集,Privatized代表DP-OPTICS算法处理后的隐私数据。从图4中可以看出添加随机噪声后的数据始终在原始数据集的周围上下浮动,但仍然保持着原始数据集的整体分布属性。在ε=0.42的基础上,如果增大隐私参数ε的取值则隐私泄露的风险将增加;如果降低ε的取值则数据可用性将会降低,因此,对本文credit-g.arff数据集来说,ε=0.42有效地平衡了数据可用性和隐私保护性之间的分配,总体上效果较好。
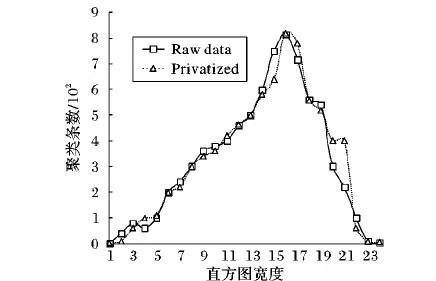
图4 原始数据与经过DP-OPTICS算法处理后的隐私保护数据对比
4 结语
本文在DP-DBSCAN差分隐私保护算法、基于OPTICS聚类的差分隐私保护算法基础上,解决了基于OPTICS聚类的差分隐私保护存在的时间复杂度大和数据可用性低的问题,平衡了隐私保护和数据可用性之间的分配。提出的DP-OPTICS差分隐私保护算法,较好地提高了数据可用性。DP-OPTICS算法相对于DP-DBSCAN算法和基于OPTICS聚类的差分隐私保护算法来说,对数据集的聚类效果较好,时间消耗介于两者之间。DP-OPTICS算法对于稀疏型的数据集采用压缩方式和尽可能地归于高频数据范围内,考虑到用户查询数据的概率以及攻击者能够成功攻击数据集记录的概率,确定最大隐私参数,对高频数据和低频数据以异方差形式添加随机噪声,提高了数据的可用性,有效平衡了隐私参数的分配,整体上是较有优势的,但是在确定异方差噪声隐私参数比例的时候,需要对用户的查询概率有较为准确的估计及在假设最大背景下用户成功攻击的概率范围,这也将会影响隐私参数最大值的确定。DP-OPTICS算法的时间耗费也需要进一步的降低以提高整体效率。
目前,差分隐私保护的应用主要有PINQ框架[22]、Airavat框架[23]、Rappor框架[24],而具体的应用较少,重点在推荐系统[25]和社交网络[26]上,下一步将所改进的DP-OPTICS算法应用于推荐系统中,进一步完善应用。
References)
[1] DWORK C. Differential privacy [C]// ICALP 2006: Proceedings of the 2006 International Colloquium on Automata, Languages, and Programming. Berlin: Springer, 2006: 1-12.
[2] 吴伟民,黄焕坤.基于差分隐私保护的DP-DBScan聚类算法研究[J].计算机工程与科学,2015,37(4):830-834.(WU W M, HUANG H K. Study on DP-DBSCAN clustering algorithm based on differential privacy protection [J]. Computer Engineering and Science, 2015, 37 (4): 830-834.)
[3] NG R T, HAN J. Efficient and effective clustering methods for spatial data mining [C]// Proceedings of the 1994 International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann, 1994: 144-155.
[4] ANKERST M, BREUNIG M M, KRIEGEL H P, et al. OPTICS: ordering points to identify the clustering structure [J]. ACM SIGMOD Record, 1999, 28(2): 49-60.
[5] BLUM A, DWORK C, MCSHERRY F, et al. Practical privacy: the SuLQ framework [C]// Proceedings of the Twenty-Fourth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems. New York: ACM, 2005: 128-138.
[6] NISSIM K, RASKHODNIKOVA S, SMITH A. Smooth sensitivity and sampling in private data analysis [C]// Proceedings of the Thirty-Ninth Annual ACM Symposium on Theory of Computing. New York: ACM, 2007: 75-84.
[7] DWORK C. A firm foundation for private data analysis [J]. Communications of the ACM, 2011, 54(1): 86-95.
[8] 李杨,郝志峰,温雯,等.差分隐私保护k-means聚类方法研究[J].计算机科学,2013,40(3):287-290.(LI Y, HAO Z F, WEN W, et al. Study on clustering method of differential privacy protectionk-means [J]. Computer Science, 2013, 40 (3): 287-290.)
[9] DWORK C, MCSHERRY F, NISSIM K. Calibrating noise to sensitivity in private data analysis [J]. Proceedings of the VLDB Endowment, 2012, 7(8): 637-648.
[10] MCSHERRY F, TALWAR K. Mechanism design via differential privacy [C]// FOCS ’07: Proceedings of the 2007 IEEE Symposium on Foundations of Computer Science. Piscataway, NJ: IEEE, 2007: 94-103.
[11] HAY M, RASTOGI V, MIKLAU G, et al. Boosting the accuracy of differentially private histograms through consistency [J]. Proceedings of the 36th VLDB Endowment, 2010, 3(1/2): 1021-1032.
[12] PENG S, YANG Y, ZHANG Z, et al. DP-tree: indexing multi-dimensional data under differential privacy (abstract only) [C]// SIGMOD ’12: Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2012: 864.
[13] MCSHERRY F D. Privacy integrated queries: an extensible platform for privacy-preserving data analysis [J]. Communications of the ACM, 2010, 53(9): 89-97.
[14] 何贤芒,王晓阳,陈华辉,等.差分隐私保护参数ε的选取研究[J].通信学报,2015,36(12):124-130.(HE X M, WANG X Y, CHEN H H, et al. Study on the selection of differential privacy parametersε[J]. Journal on Communications, 2015, 36(12): 124-130.)
[15] LEE J, CLIFTON C. How much is enough? choosingεfor differential privacy [C]// ISC 2011: Proceedings of the 2011 International Conference on Information Security. Berlin: Springer, 2011: 325-340.
[16] HARDT M, TALWAR K. On the geometry of differential privacy [C]// Proceedings of the 2010 ACM Symposium on Theory of Computing. New York: ACM, 2010: 705-714.
[17] XIAO X, BENDER G, HAY M, et al. iReduct: differential privacy with reduced relative errors [C]// SIGMOD 2011: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2011: 229-240.
[18] LI Y, ZHANG Z, WINSLETT M, et al. Compressive mechanism: utilizing sparse representation in differential privacy [C]// Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society. New York: ACM, 2011: 177-182.
[19] XIAO X, WANG G, GEHRKE J. Differential privacy via wavelet transforms [C]// Proceedings of the 2010 IEEE 26th International Conference on Data Engineering. Piscataway, NJ: IEEE, 2010: 225-236.
[20] CHEN R, ACS G, CASTELLUCCIA C. Differentially private sequential data publication via variable-lengthn-grams [C]// Proceedings of the 2012 ACM Conference on Computer and Communications Security. New York: ACM, 2012: 638-649.
[21] 曾依灵,许洪波,白硕.改进的OPTICS算法及其在文本聚类中的应用[J].中文信息学报,2008,22(1):51-55.(ZENG Y L, XU H B, BAI S. Improved OPTICS algorithm and its application in text clustering [J]. Journal of Chinese Information Processing, 2008, 22(1): 51-55.)
[22] MCSHERRY F D. Privacy integrated queries: an extensible platform for privacy-preserving data analysis [J]. Communications of the ACM, 2010, 53(9): 89-97.
[23] ROY I, SETTY S T V, KILZER A, et al. Airavat: security and privacy for MapReduce [C]// NSDI 2010: Proceedings of the 2010 USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2010: 297-312.
[24] ERLINGSSON U, PIHUR V, KOROLOVA A. RAPPOR: randomized aggregatable privacy-preserving ordinal response [C]// Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2014: 1054-1067.
[25] 程呈.基于差分隐私的兴趣点推荐系统的设计与分析[D].成都:电子科技大学,2015.(CHENG C. Design and analysis of point of interest recommendation system based on differential privacy [D]. Chengdu: University of Electronic Science and Technology of China, 2015.)
[26] 王越.基于差分隐私的社交网络隐私保护方法研究[D]. 哈尔滨:哈尔滨工业大学,2016.(WANG Y. Study on privacy protection method of social network based on differential privacy [D]. Harbin: Harbin Institute of Technology, 2016.)
This work is partially supported by the National Natural Science Foundation of China (61462009), the Scientific Research Foundation of Guangxi University for Nationalities (2014MDYB029), the China-ASEAN Research Center of Guangxi University for Nationalities (Guangxi Science Experimental Center) 2014 Open Project (TD201404), the Graduate Research and Innovation Project of Guangxi University for Nationalities (gxun-chxps201671).
WANGHong, born in 1990, M. S. Her research interests include information security.
GELina, born in 1969, Ph. D., professor. Her research interests include information security.
WANGSuqing, born in 1980. Her research interests include network security.
WANGLiying, born in 1991, M. S. Her research interests include information security.
ZHANGYipeng, born in 1991, M. S. His research interests include information security.
LIANGJuncheng, born in 1982. His research interests include information security.
