基于色彩空间的最大稳定极值区域的自然场景文本检测
2018-03-20范一华邓德祥
范一华,邓德祥,颜 佳
(武汉大学 电子信息学院,武汉 430072)(*通信作者电子邮箱ddx_dsp@163.com)
0 引言
近几年来,文本检测已经成为计算机视觉研究的热点。作为人类想法和表达方式的承载体,自然场景中的文本例如广告牌、路标等包含丰富的有价值的信息,这些信息极大地方便了大家的生活,并且为商业带来巨大的利益。文本检测被广泛地应用在图像检索和人机交互等领域,因此,自然场景中的文本检测的研究不可避免地成为研究的趋势,如何设计一个健壮的文本检测算法是一个亟待解决的问题。
文本检测最常用的两个方法是基于滑动窗口[1-2]的方法和基于连通域分析[3-6]的方法。基于滑动窗口的方法可以实现很高的召回率,但是需要多种尺寸的窗口在整幅图像移动,穷举的搜索增加了计算复杂度,并且会产生大量的错误候选区域,此方法的检测率和实时性都不能满足目前的需求。基于连通域分析的方法是通过连通域分析提取字符候选区域,然后采用分类器筛选非字符区域,最后将字符整合成文本行。笔画宽度变换(Stroke Width Transform, SWT)[7]和最大稳定极值区域(Maximally Stable Extremal Region, MSER)[6]是最常用的连通域分析的方法。最近几年,MSER由于尺度旋转不变性、仿射不变性的优势被广泛地应用于文本检测,成为文本检测的主流方法;但是,目前基于MSER的自然场景文本区域检测的方法仍然存在无法提取低对比度图像文本区域的缺陷,主要原因有以下两个方面。
首先,自然场景的图像容易受到光照、外部环境和噪声的影响,MSER抗污迹和抗噪声的能力较弱,从而导致检测出的文本区域出现粘连现象。为了解决这个问题,Chen等[3]移除边界外的像素,结合MSER与Canny边缘检测提取小区域,此方法可以有效地提高图像的边缘对比度;但是噪声的边缘也被增强,加大了筛选正确的字符候选区域的难度。Yin等[8-9]提出修剪MSER造成的重复的区域,使其能够检测任意方向的文本,这增强了文本检测的鲁棒性,但是并没有解决低对比度图像不能被提取文本区域的问题。Forssen等[10]结合MSER与尺度不变特征变换(Scale Invariant Feature Transform, SIFT)来增强MSER对复杂图像的鲁棒性,但是算法复杂度较高,不利于系统的实时性。为了有效地增强文本区域与背景的对比度而同时不增大噪声的对比度,本文充分利用方向梯度直方图(Histogram of Oriented Gradients, HOG)增强图像的边缘信息,以此提高MSER的鲁棒性。
其次,大多数的MSER方法都是在灰度通道进行处理,而忽略了颜色信息。彩色图像转换成灰度图像时,丢失了颜色和纹理信息,极大地影响系统的性能。最近的一些研究也逐渐地把目光转移到色彩空间,Neumann等[11]使用RGB和HSI(Hue-Saturation-Intensity)空间提取文本候选区域,这个系统对噪声稳定并在一定的程度上解决了低分辨率的字符不能被提取的问题,但是此方法采取6个颜色通道提取文本区域,导致检测出的文本区域重复,并且耗时较多,降低了算法的实时性。唐有宝等[12]在RGB、HSI色彩空间进行多阈值MSER区域检测,此方法取得了较好的结果,但是在6个颜色通道利用两个阈值提取MSER,时间复杂度过高,不利于系统的实时性。HSI空间是更符合人类视觉的颜色空间,色域较广,并且颜色和亮度相互独立,因此本文选择在HSI空间利用改进的MSER方法提取文本候选区域。
随着神经网络在计算机视觉中的成功应用,大多数学者将MSER与神经网络结合,并取得了较好的效果。唐有宝等[12]利用MSER提取文本候选区域,通过神经网络进行分类,使F指标在ICDAR (International Conference on Document Analysis and Recognition) 2011等数据集上达到了79%。李鉴鸿[13]利用Canny算子增强边缘信息提取MSER,并将预处理得到的MSER区域作为卷积神经网络的输入,最终在ICDAR 2011数据集实现了字符定位正确率为81%;但李鉴鸿[13]没有将字符整合成文本行,无法验证文本检测的召回率。神经网络的应用极大地提高了自然场景的文本检测率;但是它的算法复杂度过高,不利于系统的实时性。而本文提出的贝叶斯模型算法复杂度低,三个特征具有平移旋转不变性,训练得到的模型对字符分类的稳定性较高。MSER与贝叶斯模型的结合在提高系统性能的同时也提高了系统的实时性,因此本文提出的算法对未来文本检测的研究有一定的借鉴意义。
综上所述,本文在颜色空间充分利用HOG算子改进MSER,并使用贝叶斯分类器进行字符的筛选,最终能够很好地解决低对比度、背景复杂的图像不能被检测出文本的问题,从而提高系统的检测率和实时性。整个系统在两个公共数据集ICDAR 2003[14]和ICDAR 2013[15]进行测试,实验结果表明,召回率和检测率相对于传统的MSER方法都有所提升,因此本文提出的基于色彩空间的边缘增强的MSER文本检测方法对于自然场景的文本检测具有一定的有效性。
1 自然场景文本检测流程
本文提出的基于色彩空间的MSER的文本检测的方法主要分为以下三个步骤:提取字符候选区域,筛选非字符,整合成文本行。算法的整体流程如图1所示。首先,利用HOG算子增强图像边缘信息,并在H、S、I三个颜色通道提取文本候选区域;其次,将笔画宽度[7]、边缘梯度方向[15]、拐角点[11]这三个特征送入贝叶斯系统中筛选出非字符区域;最后,将滤波后的字符区域整合成文本行。

图1 算法整体流程
2 提取字符候选区域
2.1 基于边缘增强的最大稳定极值区域
MSER首次被Matas等[6]提出,MSER的数学表达式如下:
qi=|Qi+Δ-Qi-Δ|/|Qi|
(1)
其中:Qi代表阈值为i时所求的极值区域;Δ是灰度阈值的变化量,通过对训练集进行不同阈值变化量的MSER候选区域检测,发现Δ太小会出现大量的极值区域,Δ太大会导致小区域无法被检测出来,本文将Δ设置为10能够获得较好的文本候选区域;qi代表阈值为i时,极值区域的变化率,当qi达到最小值时,则Qi为最大极值区域。
MSER对于抗污迹和抗噪声的能力较弱,这个弱势使MSER无法成功地从低对比度图像中检测出文本,如图2所示,原始的MSER方法检测出的文本区域可能会出现粘连现象。考虑用增强边缘信息的方法来增大图像的对比度。最简单的方法就是利用Canny算子提取图像的边缘信息,然后将这些边缘点所对应的像素值相应地增大或者减小。虽然此方法在一定的程度上提高了边缘对比度;但是处理时忽略了边缘的梯度信息,不重要的边缘(比如噪声)也被增强,导致图像有较小的失真(如图3所示),影响MSER的性能。从视觉角度上分析,由于颜色和对比度信息,一般自然场景图像的文本区域是最引人注目的,因此文本边缘区域的梯度值较大,这一特性使本文方法可以有效地增强文本区域的对比度而减少噪声的影响,从而提高文本检测的准确率。为了更好地利用原图像的信息,采用HOG算子提取图像的梯度信息,利用梯度值重新构建图像,计算式如下:
I原图像=I原图像±λ▽I原图像
(2)
其中:I原图像代表将要处理的图像;▽I原图像代表I原图像的梯度;λ是调节像素大小的参数;±分别代表亮背景暗区域和暗背景亮区域。

图2 原始的MSER与改进后的MSER比较

图3 利用Canny算子和本文算法的边缘增强效果对比
2.2 色彩空间的最大稳定极值区域
颜色和对比度在视觉感知中占据着举足轻重的地位,自然场景中的文本往往都是通过颜色和对比度信息被人们捕捉到。目前大多数的图像处理集中在灰度通道实现相关的算法,而忽略了包含大量有价值信息的颜色通道。对于背景复杂的图像,灰度通道上的文本区域与背景之间的对比度不够明显,导致无法利用MSER正确地提取文本候选区域,而观察颜色通道上的图像,可能会有清晰的对比度,能够帮助正确地提取文本区域,因此本文充分利用色彩空间加强文本候选区域的提取。
颜色空间的选择对字符候选区域的提取也有着显著的影响。一些常用的颜色空间包含RGB、HSI和Lab色彩空间。颜色和亮度在RGB颜色空间相互关联;但在HSI和Lab颜色空间相互独立,从理论上分析,RGB颜色空间的文本检测结果不如HSI和Lab色彩空间。HSI色彩空间更符合人类的视觉效果,它在业界是更常用的一种色彩空间,并且色域足够广,因此选择在H、S、I三个通道分别提取最大稳定极值区域来获得文本候选区域。图4展示了本文在HSI空间提取文本候选区域的结果。其中:MSER+代表深色背景浅色区域的图像检测结果;MSER-代表浅色背景深色区域的图像检测结果。通过MSER+和MSER-可以更多地提取图像的最大稳定极值区域。
从图4中可以看出,对于背景复杂的图像,在H、S、I三个通道共同采用本文改进的MSER方法,能够很好地提取文本候选区域,从而可以实现较高的召回率,提高系统的性能。
此外本文对原始的MSER方法、基于Canny算子增强MSER的方法和本文提出的基于HOG算子增强MSER的方法分别在灰度通道和色彩通道作文本检测的实验,所用的数据集是ICDAR 2013。实验结果如表1所示,从表1得到,本文提出的方法优于原始的MSER方法和基于Canny增强的MSER方法,能够有效地提高文本检测的召回率和检测率(f-measure),而对HSI颜色空间的利用可以获得更好的文本检测率。
3 筛选非字符区域
从视觉角度上看,在一幅图像上,文本区域更具有显著性,它们具有自己单独的特征。本文结合笔画宽度、边缘梯度方向和拐角点这三个特征从候选区域中筛选出正确的字符。与其他分类器不同的是,本文采用贝叶斯模型进行分类。
3.1 笔画宽度
笔画宽度(Stroke Width, SW)是文字的一个标志性特征,被广泛地应用于文本检测。首次被Epshtein等[7]提出,笔画边缘上总有两点的梯度方向相反,这两点之间的距离就是这两点的笔画宽度值。如图5所示,字符的笔画宽度一般来说都是比较稳定均匀的,而非字符的笔画宽度变化是不均匀的。将SW的贝叶斯模型定义为下边的形式:
(3)
其中:E(r)和var(r)分别区域r的笔画宽度的均值和方差。与非字符区域相比,字符区域的SW(r)值相对较小。
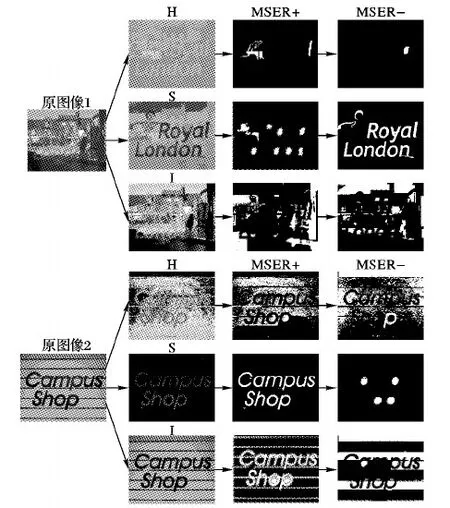
图4 HSI色彩空间的MSER结果

Tab. 1 Detection results comparison of three methods on different channels (ICDAR 2013 dataset)

图5 字符与非字符的笔画宽度对比
3.2 边缘梯度方向
方向梯度直方图特征(HOG)[16]对图像几何和光学的形变都能保持不变性。图6展示了字符的梯度方向分布图,把边缘点的梯度方向定义成四个区间[17]。
区间1 0<θ≤π/4或者7π/4<θ≤2π。
区间2 π/4<θ≤3π/4。
区间3 3π/4<θ≤5π/4。
区间4 5π/4<θ≤7π/4。
其中:1、2、3、4分别代表对应的四个区间,对于字符来说,位于区间1和区间3的边缘点数基本相同,区间2和区间4也如此,因此定义HOG的贝叶斯模型如下:
HOG(r)=(|num1(r)-num3(r)|+
(4)
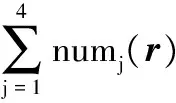
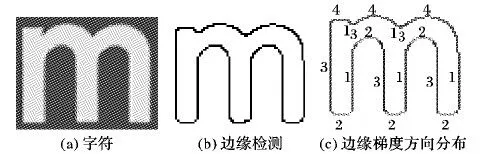
图6 字符的边缘梯度方向分布
3.3 字符的拐角点
一个字符通常只有有限个拐角点,而非字符可能有非常多的拐角点。拐角点特征具有旋转、平移、尺度不变性。在本文,将这个特征的贝叶斯模型定义为以下形式:
(5)
其中:cornernum(r)代表在区域r内拐角点的个数;edgenum(r)表示在区域r内边缘的点数。Corner(r)越小,这个区域是字符的可能性越大。
3.4 贝叶斯多个模型的融合
假设SW、HOG、字符边界拐角点这三个特征之间是相互独立的,根据贝叶斯理论,知道一个区域是字符的后验概率[17]可以由以下计算式进行计算:
(6)
其中:Ω={SW,HOG,拐角点};p(c)和p(b)分别表示字符和非字符的先验概率。通过正样本和负样本来定义似然函数p(cue/c)和p(cue/b),其中正样本和负样本来自ICDAR 2013自然场景文本分割的训练集。这个训练集拥有像素级的人为标注,包含229张可供训练的自然场景的图像,在本文的实验中,选择159张作为训练,剩余的70张作为测试集用来评估模型。
3.5 贝叶斯分类与SVM分类
为了证明本文提出的贝叶斯模型的有效性和稳定性,分别做10组实验比较贝叶斯分类与支持向量机(Support Vector Machine, SVM)分类的性能。其中第一组随机选取129张作为训练,剩下的100张作为测试;第二组随机选取169张作为训练,剩下的60张作为测试;剩下的8组分别随机选取159张作为训练,剩余的70张作为测试。10组训练数据保证每组与每组的样本不完全重合,贝叶斯模型利用上述的三个特征模型计算候选区域属于字符的概率。SVM分类首先要对候选区域进行预处理,归一化为32×32大小,然后提取HOG特征。最终的分类结果如图7所示。在10组实验中,本文提出的贝叶斯模型筛选字符的召回率基本保持稳定,并且相比SVM分类有较高的召回率,能够更好地筛选出字符区域。这是因为自然场景中的字符是各式各样的,贝叶斯模型采用的这三个特征具有平移旋转不变形,对字符的形状、拉伸、大小均无严格要求,无需对候选区域进行预处理,从而提高了系统分类的鲁棒性,而SVM分类对训练集要求较为严格,在样本量较少的情况下,训练集很难包含所有的字符形状,从而出现误判的问题。

图7 贝叶斯与SVM对候选字符区域分类结果
4 整合字符成文本行
本章的目的是将滤波后的字符区域整合成文本行。利用字符的几何特性宽、高、面积、字符之间的距离来判断字符是否在同一行。定义区域R={R1,R2,…,Rp,…,RQ},Q=charnum;charnum为最终留下来的字符个数,其中Rp,Rq∈R;p,q∈charnum。
1)区域Rp和Rq的宽和高大小相似。
(7)
2)区域Rp和Rq的中心点水平距离小于Rp和Rq的宽度的平均值的3倍;中心点的垂直距离小于Rp和Rq的高度的平均值的1/2。
多个检测结果的融合如下。
本文在HSI空间利用改进后的MSER来提取文本候选区域,最终的文本定位分别由H、S、I三个通道的MSER+和MSER-检测结果共同组成,多个检测结果会出现重复的文本框,简单地将这些结果叠加会降低文本的检测率。Rp={leftp,upp,rightp,downp},定义文本框与文本框之间的关系有3种:相交、包含、独立。当两个区域呈相交的关系时,本文合并这两个区域,分别取两个区域的左边的最小值、右边的最大值为新区域的左边值和右边值,即leftnew=min(leftp,leftq),rightnew=max(rightp,rightq);对上边值和下边值做相同的处理同样的处理。当两个区域呈包含关系时,如果两个区域的宽(高)之差小于最大宽(高)的1/5,剔除掉小区域;当两个区域呈完全独立的关系时,认为这两个区域是检测的不同的文本区域。
5 实验结果与分析
本文的实验环境是Windows 7、64位系统、Intel i5处理器、Matlab R2016a平台。为了评价算法的性能,系统在最常用的两个公共数据集ICDAR 2003和ICDAR 2013进行测试。其中ICDAR 2003包含258张图像用于训练,251张图像供测试;ICDAR 2013包含229张图像用于训练,233张图像用于测试。ICDAR 2013有专门的网上评价性能系统,将每幅图像的检测结果按照左、上、右、下的顺序以txt的格式存储文本区域的坐标,最终将233张图像的txt压缩上传至评估平台,即可得到精确率和召回率。
ICDAR 2003没有网上评估系统,通过匹配所检测区域的文本框与标准框之间的最大相似度获得召回率和精确率。首先定义:
m(t;T)=max{mp(t:t1)/t1∈T}
其中:m(t;T)代表矩形框t与标准框T的最大相似度。
召回率和精确率定义如下:
(8)
(9)

(10)
其中:G代表的是标准框的集合;E是本系统文本检测的结果;f-measure用来综合评价召回率和精确率;β代表召回率和精确率所占的权重。
5.1 实验结果比较与分析
本文方法对ICDAR 2013和ICDAR 2003两个数据集的测试结果如表2所示。针对最近几年基于MSER的文本检测方法进行效果比较。从表2中可以看到,唐有宝等[12]检测率、精确率、召回率是最好的,采用在RGB、HSI色彩空间进行多阈值MSER区域检测,在RGB、HSI、Lab九个色彩空间提取颜色特征并送入神经网络进行分类,虽然实现了较高的检测率;但是算法复杂度过高,耗费时间较长,在提升文本检测率的同时降低了系统的实时性。Turki[4]采用索贝尔算子(Sobel operator, Sobel)进行边缘增强,并在Y颜色通道提取MSER,此方法虽然也利用颜色空间和增强对比度提升MSER的性能,但是如前边2.1节所述,单纯地利用边缘检测增强边缘信息会导致不感兴趣的区域对比度也增加,从而影响文本检测的精确率。Ren等[18]采用神经网络的方法进行文本检测,Neumann等[11]同样在RGB、HSI空间利用MSER提取候选区域,但是效果都差于本文效果。对ICDAR 2013数据库,本文方法在HSI空间的召回率达到71%,低于唐有宝等[12]算法结果4个百分点,但是本文算法不涉及复杂的卷积操作,系统实时性优于唐有宝等[12]算法。通过实验结果可以获得,本文提出的算法优于其他类似基于色彩空间和MSER提取文本区域的方法。
表2中,在ICDAR 2003数据集的结果对比中:张国和等[19]将MSER与SWT相结合提取文本区域;杨磊[20]采用在色彩空间基于均值漂移的图像分割的方法,选取HOG和局部二值模式特征(Local Binary Pattern, LBP)送入AdaBoost分类器筛选字符区域;Neumann等[21]采用MSER获取文本候选区域;Chen等[3]结合MSER与Canny边缘检测提取文本候选区域。可以很清晰地看到本文算法优于其他竞争算法,实现了最高的召回率,f-measure也达到了最高。
综合上述的主观分析和客观实验结果可知,本文的召回率的提升正是由于利用文本区域的梯度值高于其他区域这一特性来改进MSER,将改进后的MSER应用到色彩空间,可充分利用颜色和梯度信息来解决背景复杂、低对比度的图像无法提取文本候选区域的问题。贝叶斯分类方法保证了字符分类的精确率,从而提升f-measure。与此同时,本文方法的精确率略低于其他竞争的算法,精确率较低的原因是本文将多个通道的文本检测结果进行融合,这些检测结果会产生多个重复的文本框,虽然字符分类的召回率较高,但是最终形成的重复的文本行降低了文本检测的精确率。图8展示了本文系统对数据集ICDAR 2013和ICDAR 2003进行文本检测的一部分结果。

表2 本文算法与其他竞争算法在不同数据库的检测结果对比

图8 本文方法对不同数据库中的部分检测结果
5.2 算法复杂度分析
本文的算法复杂度主要涉及提取最大稳定极值区域和筛选候选区域两大部分。其中,筛选文本候选区域采用的是贝叶斯模型,无需进行卷积操作,主要是对候选区域提取3个特征,求取笔画宽度、边缘梯度方向、拐角点只需要对区域内每个像素进行操作,因此时间复杂度为O(n),其中n为候选区域所包含的像素总数。最大稳定极值区域的复杂度为O(Nlog logN),MSER是对按照阈值从小到大和从大到小检测极值区域,因此每个通道提取最大稳定极值区域的算法复杂度为O(2Nlog logN),其中N为原图像的像素总数。
为了直观地证明系统既可以实现较高的检测率,又可以实现较好的实时性,在RGB、HSI空间分别做实验观察运行一幅图像消耗的时间。如表3所示,系统在RGB通道上的检测结果差于HSI通道的检测结果,这与本文所分析的一致,RGB通道的亮度和颜色相关,不能使系统达到较好的效果。系统在RGB和HSI六个通道上的文本检测实现了最高的检测率,处理一幅图像的平均时间是25 ms,在HSI空间上召回率达到了71%,低于最好结果2个百分点,但是处理一幅图像的时间减少了一半,因此在HSI空间提取文本候选区域可以同时兼顾系统的检测率和实时性。
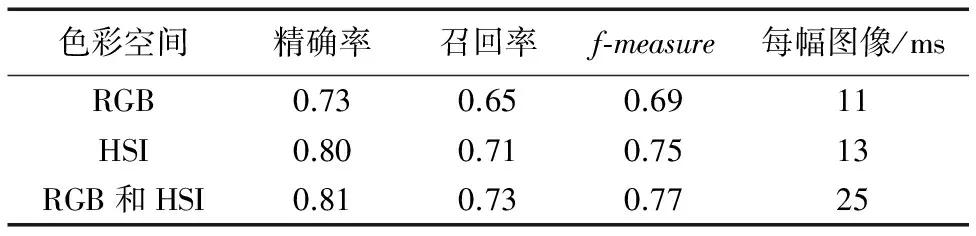
表3 本文算法在RGB、HSI空间的检测结果(数据集ICDAR 2013)
6 结语
本文针对MSER不能检测低对比度、背景复杂的图像文本区域的问题,提出了一种基于色彩空间的边缘增强的MSER自然场景文本检测算法。大多数的边缘增强的方法会同时增加文本区域与噪声的对比度,本文从全新的角度思考利用方向梯度值来减小噪声的影响,再利用色彩空间提取出更多感兴趣的候选区域;本文提出的三个特征具有平移旋转不变性,贝叶斯分类算法简单并对字符分类有一定的精确性和鲁棒性。实验结果表明,本文所提出的方法既实现了较高的检测率又有一定的实用性;但本文算法也存在一定的缺陷,如:对于一些在颜色空间对比度不明显的图像,即使利用HOG算子增强对比度,也不能获得理想的结果;将字符组合成文本行的方法过于简单,容易形成重复的文本行,导致在字符分类精确率很高的情况下得到很低的文本检测精确率。随着神经网络的发展,将传统方法与神经网络结合是一个发展方向,后期,我们将集中研究如何将本文提出的边缘增强的MSER和三个特征的贝叶斯模型与神经网络相结合,在保证系统实时性的同时实现更好的文本检测率。
References)
[1] CHEN X, YUILLE A L. Detecting and reading text in natural scenes [C]// CVPR 2004: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: 366-373.
[2] NEUMANN L, MATAS J. Scene text localization and recognition with oriented stroke detection [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2013: 97-104.
[3] CHEN H Z, TSAI S S, SCHROTH G, et al. Robust text detection in natural images with edge-enhanced maximally stable extremal regions [C]// ICIP 2011: Proceedings of the 2011 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2011: 2609-2612.
[4] TURKI R, HALIMA M B, ALIMI A M. Scene text detection images with pyramid image and MSER enhanced [C]// ISDA 2015: Proceedings of the 2015 International Conference on Intelligent Systems Design and Applications. Piscataway, NJ: IEEE, 2015: 301-306.
[5] AO C, BAI X, LIU W, et al. Detecting texts of arbitrary orientations in natural images [C]// CVPR 2012: Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 1083-1090.
[6] MATAS J, CHUM O, URBAN M, et al. Robust wide baseline stereo from maximally stable extremal regions [J]. Image and Vision Computing, 2004, 22(10): 761-767.
[7] EPSHTEIN B, OFEK E, WEXLER Y. Detecting text in natural scenes with stroke width transform [C]// CVPR 2010: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 2963-2970.
[8] YIN X C, YIN X, HUANG K, et al. Robust text detection in natural scene images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5): 970-983.
[9] YIN X, PEI W, ZHANG J, et al. Multi-orientation scene text detection with adaptive clustering [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1930-1937.
[10] FORSSEN P E, LOWE D G. Shape descriptors for maximally stable extremal regions [C]// ICCV 2007: Proceedings of the 2007 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2007: 1-8.
[11] NEUMANN L, MATAS J. Real-time scene text localization and recognition [C]// CVPR 2012: Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 3538-3545.
[12] 唐有宝,卜巍,邬向前.多层次MSER自然场景文本检测[J].浙江大学学报(工学版),2016,50(6):1134-1140.(TANG Y B, BU W, WU X Q. Natural scene text detection based on multi-level MSER [J]. Journal of Zhejiang University (Engineering Science), 2016, 50(6): 1134-1140.)
[13] 李鉴鸿.基于MSER的图像文本定位的应用研究[D].广州:华南理工大学,2015:30-41.(LI J H. Application research on text location in image based on maximally stable extremal regions [D]. Guangzhou: South China University of Technology, 2015: 30-41.)
[14] LUCAS S M, PANARETOS A, SOSA L, et al. ICDAR 2003 robust reading competitions [C]// ICDAR 2003: Proceedings of the 2003 International Conference on Document Analysis and Recognition. Berlin: Springer, 2003: 682-687.
[15] KARATZAS D, SHAFAIT F, UCHIDA S, et al. ICDAR 2013 robust reading competition [C]// ICDAR 2013: Proceedings of the 2013 International Conference on Document Analysis and Recognition. Piscataway, NJ: IEEE, 2013: 1484-1493.
[16] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// CVPR 2005: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2005: 886-893.
[17] LI Y, JIA W, SHEN C, et al. Characterness: an indicator of text in the wild [J]. IEEE Transactions on Image Processing, 2014, 23(4): 1666-1677.
[18] REN X H, ZHOU Y, HE J H, et al. A convolutional neural network-based Chinese text detection algorithm via text structure modeling [J]. IEEE Transactions on Multimedia, 2017, 19(3): 506-519.
[19] 张国和,黄凯,张斌,等.最大稳定极值区域与笔画宽度变换的自然场景文本提取方法[J].西安交通大学学报,2017,51(1):135-140.(ZHANG G H, HUANG K, ZHANG B, et al. A natural scene text extraction method based on the maximum stable extremal region and stroke width transform [J]. Journal of Xi’an Jiaotong University, 2017, 51(1): 135-140.)
[20] 杨磊.复杂背景图像中文本检测与定位研究[D].广州:华南理工大学,2013:57-61.(YANG L. Research on text detection and location in complex background images [D]. Guangzhou: South China University of Technology, 2013: 57-61.)
[21] NEUMANN L, MATAS J. A method for text localization and recognition in real-world images [C]// ACCV 2010: Proceedings of the 2010 IEEE Computer Asian Conference on Computer Vision. Piscataway, NJ: IEEE, 2010: 770-783.
FANYihua, born in 1993, M.S. candidate. Her research interests include natural language processing of image, character recognition.
DENGDexiang, born in 1961, M.S., professor. His research interests include computer vision, target tracking.
YANJia, born in 1983, Ph. D., lecturer. His research interests include target tracking, image quality assessment.
