基于多敏感属性分级的(αij,k,m)-匿名隐私保护方法
2018-03-20王秋月葛丽娜王利娟
王秋月,葛丽娜,耿 博,王利娟
(广西民族大学 信息科学与工程学院,南宁 530006)(*通信作者电子邮箱66436539@qq.com)
0 引言
随着信息技术的不断发展,越来越多的个人隐私信息不断泄露。在大数据信息的统计中,所要发布的数据往往具有多个敏感属性,如何对这些具有多个敏感属性的数据进行信息保护,成为目前匿名隐私保护的重要课题。目前,针对数据发布[1-2]方面,单敏感属性的匿名模型研究较为成熟。
Jiang等[3]提出了k-匿名模型[4];Machanavajjhala等[5]提出了L-多样性模型[6];文献[7-8]中提出了(α,k)-匿名模型,该模型要求等价类中每个敏感值出现概率不超过阈值α;金华等[9]针对语义相近问题提出了(αi,k)匿名模型,另外还有p-敏感性k-匿名模型[10]、t-closeness框架[11]等。这些均是对单敏感属性的数据进行保护,并没有考虑到对多敏感属性数据的信息保护。对于多敏感属性方面的研究,罗方炜等[12]提出了(l,m)-多样性模型,该模型要求当同一敏感值的元组从等价类中删除时,等价类剩余的元组仍满足独立敏感属性(l-1)多样性,能够有效抵制关联攻击,但是仍存在敏感值语义相近问题;刘志军等[13]针对敏感值语义相近问题提出了(l,α,m)-多样性模型,但是该模型信息损失度比较大。
本文针对多敏感属性语义相近问题提出了基于多敏感属性分级的(αij,k,m)-匿名模型,在满足(αi,k)-匿名模型的基础上,对多个敏感属性的属性值进行分级,引入了分级表的概念,每个敏感属性均设置一个分级表,并且为每个级别设置一个频率约束αij,同时还引入了一种基于贪心算法的匿名化方法。
1 相关工作
1.1 信息损失度量方式
数据匿名化的过程会对数据造成一定的信息损失,降低数据的可用性。本文采用了泛化树的构造方法和基于权重的加权层次距离[14],下面给出相关的定义。
定义1 加权层次距离(Weighted Hierarchical Distance, WHD)。设h为泛化树高度,从最高层(最泛化的形式)到最底层(最具体的形式)各层的层次为1,2,…,h-1,h,当某个属性值从p层泛化到q层(p>q),加权层次距离定义为式(1):

(1)
其中,wj, j-1=1/(j-1)(2≤j≤h)。例如Ex_Pid的一种泛化层为:{12010,1201*,120**,12***,1****,*},把1201*泛化到1****的距离:WHD={1/4+1/3+1/2}/{1/5+1/4+1/3+1/2+1}=0.47。
定义2 元组泛化的信息损失。设t为数据表的元组,b为准标识符属性个数,t={ZB1,ZB2,…,ZBb}经过泛化得到t={ZB1′,ZB2′,…,ZBb′}同时设level(ZBj)在泛化树中的层次,那么t泛化为t′的元组泛化信息损失为式(2):
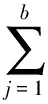
(2)
定义3 数据表泛化的信息损失。设n为数据集DT的元组个数,DT′为DT的匿名表。DT中元组ti对应泛化成DT′中元组ti′,则DT泛化为DT′的数据表泛化信息损失为式(3):
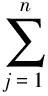
(3)
1.2 数据隐私保护度量方式
定义4 敏感性距离[15]。假设D(B)是敏感属性B的级别域,Li,Lj为该域中的2个级别,那么两级别间的敏感性距离为:
D(Li,Lj)=|Li-Lj|
(4)
定义5 等价类敏感性距离度量。假设E为等价类,并且有u条记录,D(B)为属性B的级别域;wk为第i条记录和第j条记录之间级别距离的权重,那么等价类的度量定义为:

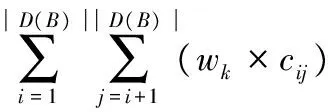
(5)
其中Cij=D(Li,Lj)。对于表1,可以设置Wk={0.85,0.9,0.95,1},即表示:级别5到级别4、3、2、1的权重都为1;级别4到级别3、2、1的权重都为0.95;级别3到级别2、1的权重都为0.9;级别2到级别1的权重为0.85;因此第1个等价类E1(2,1,4,5)的Ds(E1)=1.133 3,较好地反映了等价类的敏感性差异。
1.3 单敏感属性(αi,k)-匿名存在的问题
定义6 等价类。假设数据表DT的准标识符(Quasi Identifier, QI)为QI,在数据表DT上具有相同QI的元组的集合称为一个等价类,记作E。
定义7 (αi,k)-匿名。数据集DT,其敏感属性为PD。根据单敏感属性值|PD|语义敏感性由高到低分为L1,L2,…,Lc级,并且为每个级别设置了一个相应的αi约束频率,要求每个等价类中的敏感值都满足其所属敏感级的频率约束。在完成(αi,k)-匿名分组的时候,防止了具有相同级别敏感值的记录存在于同一组内,则称该匿名为(αi,k)-匿名。
表1是将原始数据进行泛化,得到泛化后的数据表,然后将泛化后的数据根据(αi,k)-匿名要求进行分类,得到了表1;表1中含有两个敏感属性Physician、Disease,其余的为准标识符,后面的级别是根据敏感属性值严重程度,将其划分为多个等级,划分等级的内容在后边将提到。
(αi,k)-匿名虽然解决了敏感值语义相近的问题,但是仍然存在着隐私泄露的风险。例如,设级别L1的约束频率α1=0.35,L2的约束频率α2=0.4,L3的约束频率α3=0.45,k=3,那么表1就是满足其要求的匿名表,但是攻击者仍然能够根据背景知识确定John不是Candy的Physician值,因此Candy的Disease属性值为Heart Disease。为了抵制多敏感属性的关联攻击,提出了(αij,k,m)-匿名模型。
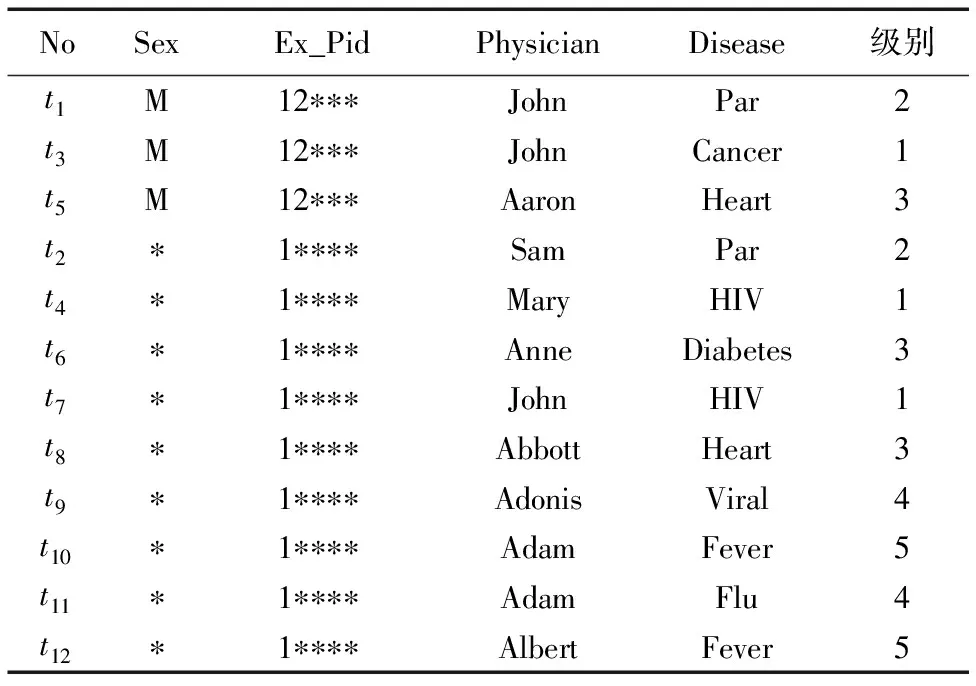
表1 单敏感属性(αi,k)-匿名表
2 改进的(αij,k,m)-匿名模型
保护个人隐私信息主要是保护有关个人身份或者标识的敏感信息,对数据进行匿名化操作时,可以把数据属性分为3类:1)显示标识符(Explicit Identifier, EI),能够唯一识别单个个体的属性。2)准标识符(Quasi Identifier, QI),主要存在于匿名表与外表中,通过连接查找能唯一识别单个个体的一组属性。3)敏感属性(Sensitive Attribute, SA),指个体隐私信息中属于敏感信息的属性。例如,对于一个患病者来说,唯一标识个人身份信息的身份证号是显示标识符,性别为准标识符,患病情况为敏感属性等信息都是需要保护的。
2.1 (αij,k,m)-匿名模型的定义
在(αi,k)-匿名模型的基础上,本文定义了(αij,k,m)-匿名模型。
定义8 (αij,k,m)-匿名。含有m个敏感属性的某一等价类在满足单敏感属性(αi,k)-匿名的基础上,对其他的m-1个敏感属性的敏感值均根据语义设置对应的级别,即DT数据集中的敏感属性为PDi(1≤i≤m),根据敏感属性值|PDi|敏感性由高到低分为Li1,Li2,…,Lij,…,Lmc(1≤j≤c)并为每个级别设置一个相应的αij约束频率,要求等价类中的m个敏感属性的属性值都满足其所属级别的频率约束,在完成(αij,k,m)-匿名分组的时候,防止具有相同级别的敏感值的记录存在于同一组内,则称该数据集满足(αij,k,m)-匿名。
下面是对(αi,k)-匿名模型所进行的改进设计。
2.2 模型设计
设DT表示数据集,QI表示准标识符,PD表示敏感属性。数据集DT上有多种属性{ZB1,ZB2,…,ZBb,PD1,PD2,…,PDm},其中ZBi(1≤i≤b)为准标识符,PDj(1≤j≤m)为敏感属性。DT上有n个元组ti(1≤i≤n)。
因为同一个等价类中不能出现语义相近的内容,所以就更不能出现相同的名字,故为Physician和Disease的不同属性值都设置一个对应的级别,如表2~3所示。
表2是对敏感属性Disease的属性值进行分级,1为级别最高的,5为级别最低的。表2中是根据Disease敏感属性值的语义,将其语义相近的划分为一组。
表3是对敏感属性Physician的属性值进行分级,1为最高级别,9为最低级别。表3中是根据Physician敏感属性值的语义,将其语义相近的划分为一组。

表2 Disease属性分级表
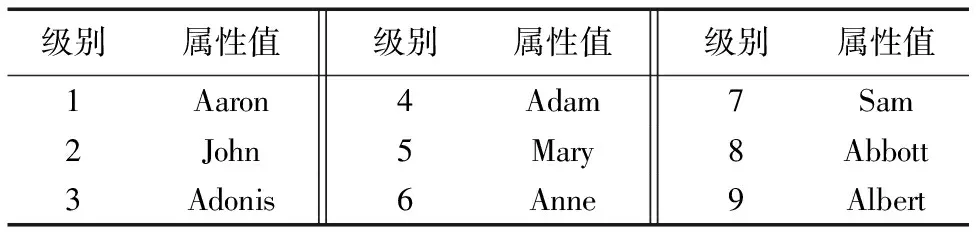
表3 Physician属性分级表
例如,设Physician为敏感属性PD1,Disease为敏感属性PD2,则L11的频率约束α11=0.25,依次设置L12的为α12=0.3,L13的为α13=0.35,L14的为α14=0.4;L21的频率约束α21=0.25,依次设置L22的为α22=0.3,L23的为α23=0.35,L24的为α24=0.4;k=4,表4是满足其要求的匿名表。因此,在表4中,即使攻击者了解到某个病人属于第1个等价类,并且Physician的属性值不是John,那么在Disease属性上,该病人可能是Viral Infection,也可能是Fever,攻击者不能精确地了解到该病人有什么病情,降低了泄露风险。

表4 多敏感属性(αij,k,m)-匿名表
在表4中,两个敏感属性的属性值都有其划分的级别,在列举表格时,将其对应的级别也对应地列举出来,可以看到表4中的级别PD1中没有级别相同的记录,PD2中也没有级别相同的记录出现,因此表4呈现的是满足多敏感属性(αij,k,m)-匿名模型的匿名表,表中是将k设为4,划分成了两个等价类,并且对Physician和Disease的每个敏感属性值都设置了级别和阈值,同时满足了同一等价类中不出现相同级别的记录的要求。
3 改进的(αij,k,m)-匿名模型算法设计
针对改进的(αij,k,m)-匿名模型,提出了基于贪心策略的实现算法,在基于多敏感属性数据分级的基础上(如图1),采用贪心算法,使得插入等价类中的级别高低之分更加明确,区别危险等级的难度增加,提高了隐私数据的保护程度。该算法通过分组,为每个敏感属性PDi的语义相近的敏感值分为一组FZs,将每个组划分对应的级别Lij,并为每个级别设置对应的阈值αij,共有c个级别(s≤c),使得每一个级别内的敏感属性值的现实语义含义尽可能地相近。
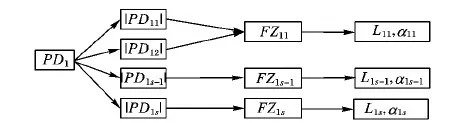
图1 敏感属性值划分组和对应级别
当i=1时,按照贪心算法,选择局部最优的一条级别最高的记录插入,然后再选择局部最低的一条记录插入,直到满足k-匿名,用数组Di[x]存储插入记录PDi的级别Lij(如图2~3所示)。

图2 由空的等价类E转变成满足k-匿名条件的等价类E

图3 由数组Di[x]存储PDi的级别Lij
当i=2时,查询Di[x]中有没有相同的值,如果有,说明存在相同等级的记录,因此把其中一条满足条件的记录删除,为了满足k-匿名要求,在找到一条满足条件的记录插入,一直循环,直到不能满足构造等价类的要求为止。将剩下的元组插入到满足条件的等价类中,直到不能插入为止。另外将剩下的不能构造等价类的元组进行隐匿,并且对构造好的等价类中的记录进行泛化,最后输出匿名表。具体算法过程如下。
3.1 算法设计
该算法涉及到下面的几个标记。
1)临时表DT′。包括QI属性、PDi(1≤i≤m)敏感属性。
2)等价类E。
3)基于敏感性分级的敏感值分组FZs(FZ1,FZ2,…,FZq),q为不同敏感属性值的个数,FZs是所有敏感属性值语义相近的记录的分组,并标记该分组所属的敏感级别PDi和αij(1≤i≤m,1≤j≤c,s≤c)。
4)分组的优先级,敏感级别高的优先级高,级别相同的敏感值,No小的优先级别高。
5)Ci[u]存储所有敏感属性为i的级别划分(1≤i≤m,1≤u≤c)。
6)Di[x]存储插入记录的PDi的敏感级别(1≤i≤m,1≤x≤c)。
算法1 基于贪心策略的匿名算法。
输入:原始数据表DT,准标识符个数b;敏感属性个数m,匿名约束k,敏感值分级(L11,L12,…,Lij,…,Lmc)(1≤i≤m,1≤j≤c)及其所属级别的频率约束(α11,α12,…,αij,…,αmc)(1≤i≤m,1≤j≤c)。
输出:满足(αij,k,m)-匿名模型的数据表DT′。
1)
初始化E=∅;
2)
While 可以构造等价类
3)
Whilei=1 andE不满足k-匿名模型时
4)
If 存在优先级非空分组,等价类E中的记录数小于k
5)
采用贪心策略,从优先级别高的分组中提取一条记录ts添加到E中,同级别中选No小的分组,每取出一条记录,即从该分组中删除ts;并且从优先级别低的分组中提取一条记录ts添加到E中,同级别中选No小的分组,每取出一条记录,即从该分组中删除ts;
6)
如果等价类中的记录数s小于k,则重复第5)步,直到等价类E满足k-匿名;将等价类E添加到DT′中;
7)
End if
8)
End while
9)
当2≤i≤m时
10)
WhileE不满足(αij,k,m)-匿名模型
11)
如果Di[x]的值都不相同的,则跳到下一个敏感属性继续循环;
12)
如果Di[x]的值有相同的,则将相同值中优先级别较高的记录从等价类E中删除,并且从剩余的记录中找到满足条件的记录插入到等价类E中,使其满足(αij,k,m)-匿名要求;
13)
End while
14)
End While
15)
For each 剩余的记录ss
16)
如果存在等价类E,添加ss后仍然满足(αij,k,m)-匿名模型,则添加ss到该等价类,优先考虑不含相同级别的、与最高级别距离较大的等价类;
17)
End for
18)
隐匿所有无法添加到等价类的记录,将等价类进行泛化;将所得的匿名表DT′输出;
19)
算法结束
本文为了进一步提高改进的(αij,k,m)-匿名模型的隐私保护程度,采用了贪心算法;在算法执行过程中,为了形成等价类,优先选择局部优先级别最高的记录插入,然后再选择局部优先级别最低的记录插入,依次循环,最后形成满足条件的等价类;在同一个等价类中,两个级别的敏感性距离越大,说明隐私保护程度越高,这样优先选择最高和最低的级别插入,就把局部敏感性距离最大的两个级别插入,提高了改进的(αij,k,m)-匿名模型的隐私保护程度。具体算法流程如图4所示。
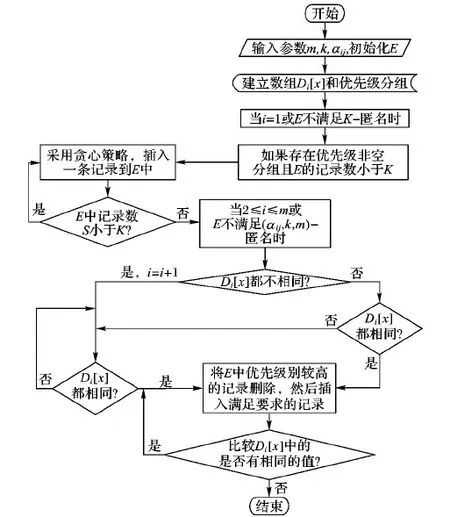
图4 基于贪心策略的(αij,k,m)-匿名模型隐私保护流程
3.2 算法的实例分析
以原始数据表1为例来说明算法的执行过程。按照表2和表3的敏感性分级,并定义敏感级的αij。
Disease为第1个敏感属性,所以可以定义:α11=0.3,α12=0.35,α13=0.4,α14=0.45,α15=0.5。Physician为第2个敏感属性,所以可以定义α21~α29为{0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65},k=4,过程如下。
1)当i=1,敏感属性为Disease时,基于敏感性分级的敏感值分组按优先级由高到低的分组。第1级别分组有:HIV={t4,t7},Cancer={t3};第2级别分组有:Parkinson={t1,t2};第3级别分组有:HeartDisease={t5,t8};Diabetes={t6};第4级别分组有:Flu={t11};ViralInfection={t9};第5级别有:Fever={t10,t12}。
2)当i=2时,敏感属性为Physician,按优先级分组。第1级别组:Aaron={t5};第2级别有:John={t1,t3,t7};第3级别有:Adonis={t9};第4级别有:Adam={t10,t11};第5级别有:Mary={t4};第6级别有:Anne={t6};第7级别:Sam={t2};第8级别有:Abbott={t8};第9级别有:Albert={t12}。
3)在满足k=4匿名的基础上进行等价类分类,当i=1时(也就是敏感属性为Disease时),按照贪心策略,优先从最高的组中取出一条记录t3,再按级别从最低级别的分组中取出一条记录t10,按照上述过程,再取一条高级别记录t1,一条低级别记录t9,此时第1个等价类为表5所示。
表5展现的是只根据PD1形成的等价类,虽然在PD1中,级别只有2,1,4,5,没有级别相同的记录出现,但是在PD2中出现的级别是2,2,3,4,因此,在PD2中出现了具有相同级别的记录,所以当i=2(即敏感属性为Physician时),有相同级别的数据出现,将相同级别的数据保留下一条记录,其余记录删除(将Disease划分的级别较高的记录删除),因此把t3删除,为了满足4-匿名,从剩下的记录中找到一条满足条件的记录插到第1个等价类中,找到记录t4(条件要满足敏感属性为Disease时,从级别高的分组查找首先是t3,但是t3的Physician属性与等价类中的级别相同,因此t3不满足条件;找到t4,t4的Physician属性与等价类中的级别都不同,满足条件,插入),因此可以得出满足条件的第1个等价类为{t10,t1,t9,t4}以此类推出现满足条件的(αij,k,m)-匿名模型的表4,隐藏剩余的不满足条件的记录。
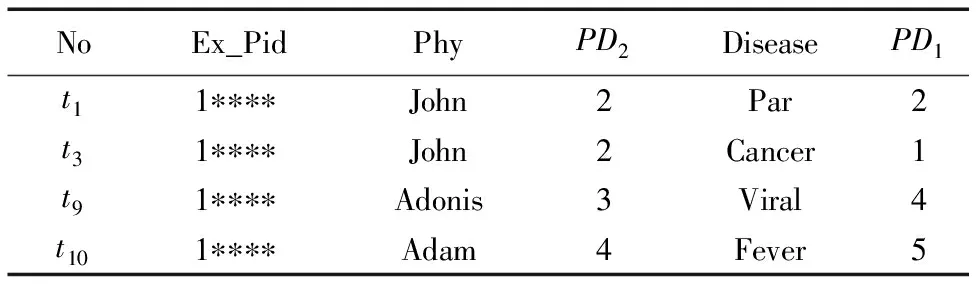
表5 满足条件的第1个等价类
这个实例分析说明了改进的(αij,k,m)-匿名模型能够保护多敏感属性数据,有效地抵制关联属性间的关联攻击,提高了对多敏感数据的隐私保护程度。
4 算法性能分析
4.1 实验环境
实验数据采用来自UCI Machine Learning Repository 中的Adult标准数据集共22 723条记录,该数据广泛用于数据匿名保护研究中。本机运行环境为Windows 7操作系统,采用C++编程。数据的具体描述如表6。
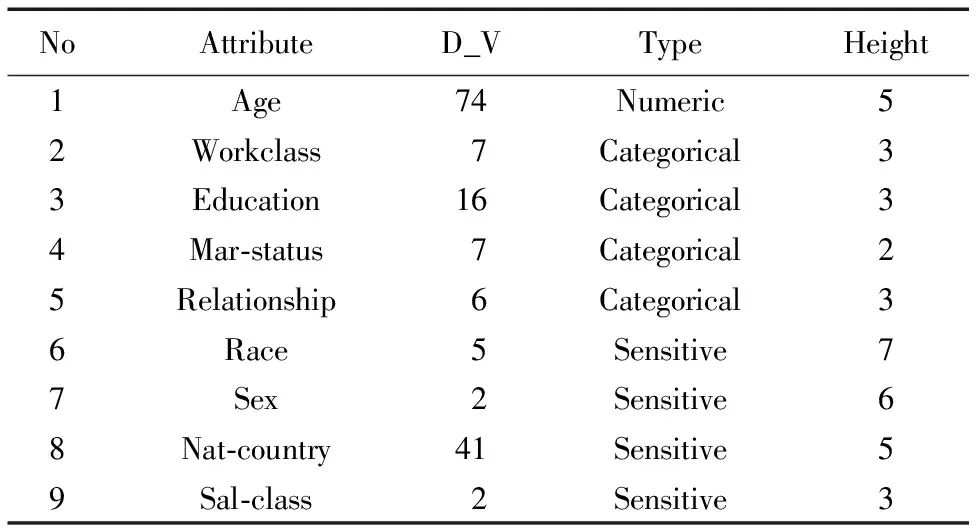
表6 Adult实验数据集
4.2 实验结果分析
基于贪心算法的(αij,k,m)-匿名模型主要针对多敏感属性信息进行保护,为每个敏感属性的敏感值进行分级设置,并为每个级别设置一个特定的αij,贪心算法将分级的记录选择一高一低的插入到等价类中,使得该算法在分级的基础上进一步提高了数据隐私的保护程度。实验结果证明,该模型信息损失量小,能够抵制关联攻击,保护多敏感属性数据,进一步提高了数据隐私的保护程度,是一种有效的隐私保护方法。表4就是本文算法发布的数据结果,表2~3就是对应的分级表。
算法采用信息损失度、执行时间和隐私保护程度为衡量数据质量的标准。与(αi,k)-匿名模型[9]相比,本文算法实现的(αij,k,m)-匿名模型能够保护多敏感属性数据;与(l,m)-多样性模型[12]相比,(αij,k,m)-匿名模型能够解决敏感属性值语义相近问题;与(l,α,m)-多样性模型[13]相比,(αij,k,m)-匿名模型信息损失量较小,保护程度更高,并且能够更好地抵制关联攻击。
4.2.1 数据隐私保护度量分析
在同一个等价类中,敏感值的多样性可以避免同质性攻击,更进一步说,敏感值之间的差异性越大,越难以判断该敏感值所属的范围,因此,数据的隐私保护程度就越高。本文中,在敏感属性值分级的基础上,采用贪心算法,找到局部级别最高的记录以及局部级别最低的记录,依次插入到等价类中,形成满足改进的(αij,k,m)-匿名模型的等价类,增大了等价类敏感性距离,提高了等价类中记录级别的差异性。由于数据的隐私保护程度可以用平均等价类敏感性距离来度量,敏感性距离越大,说明数据之间的差异性越大,因此,本文算法可以降低隐私泄露程度,加强对多敏感属性数据的保护。本文随机取一个k值4,比较了在k=4的情况下,各个模型随着m的增长所呈现的变化趋势。如图5,就是m变化时平均等价类敏感性距离度量的比较。
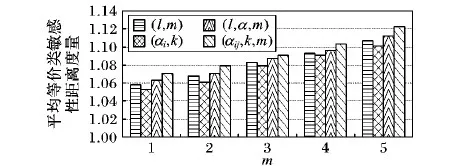
图5 m变化时的平均等价类敏感性距离度量比较(k=4)
从整体上来看,当k=4,随着m的不断增大,各个模型的平均等价类敏感性距离度量不断增大;因为含有越来越多的敏感属性,将其敏感属性值插入到等价类中时,会不断地循环执行,为了满足同一等价类中不出现相同的级别要求,那么随着记录的不断插入,平均等价类敏感属性距离就会不断增大,就会出现如图中的结果。从信息保护程度来说,(l,m)-多样性模型虽然能够保护多敏感属性数据,但是并没有解决敏感值语义相近问题;隐私保护程度相对较低;(αi,k)-匿名模型只能保护单敏感属性数据,对多敏感属性数据的保护程度最低;(l,α,m)-多样性模型解决了语义相近问题和关联攻击问题,而改进的(αij,k,m)-匿名模型在解决了保护多敏感属性问题和关联攻击问题后,还采用了基于贪心策略的实现算法,采用一条高级别,一条低级别的记录插入方式形成等价类,在敏感属性值分级的基础上,进一步阻止了级别相近的记录出现在同一等价类中,因此,与(αi,k)-匿名模型和(l,α,m)-多样性模型相比,改进的(αij,k,m)-匿名模型在信息保护程度上有更好的效果。本文采用等价类敏感性距离度量来量化数据的隐私保护程度,等价类间的级别相差越大,级别距离就越大,数据的隐私保护程度就越好,从图5中可以看出,改进的(αij,k,m)-匿名模型的平均等价类敏感性距离度量最高,因此,该模型的隐私保护程度最高。
4.2.2 信息损失和时间效率的分析
由图6和图7可以看出,从整体上来看,当k=4时,随着m的不断增大,各个模型的信息损失量增大,执行时间也在变长;因为当数据信息含有越来越多的敏感属性时,程序执行的循环次数就会增多,那么执行时间就会相应地增大;由于含有多个敏感属性,在进行等价类分类时,为了满足各个敏感属性的属性值在插入到等价类中的要求,那么相对的信息的损失量就会增加。在执行时间相差不大的基础上,与(l,m)-多样性模型相比,在m=1时,改进的(αij,k,m)-匿名模型能够很好地解决敏感值语义相近问题,提高对数据信息的隐私保护程度;(l,α,m)-多样性模型相比,改进的(αij,k,m)-匿名模型能够更好地降低信息损失量,在算法执行的结尾,可以对不能够构造等价类的元组,找到满足条件的等价类,再次并将其插入,减少信息损失;与(αi,k)-匿名模型相比,当m=1时,两者的信息损失量是相同的,随着m的增大,改进的(αij,k,m)-匿名模型的信息损失度也会增大,但是该模型能够对多敏感属性数据进行保护,抵制关联属性之间的关联攻击。

图6 m变化时信息损失量的比较(k=4)

图7 m变化时执行时间的比较(k=4)
4.3 信息损失量与隐私保护分析
从整个算法的执行过程看:首先,以m个敏感属性为基准,不断抽取语义相近的敏感值记录构建分组;根据敏感值的敏感性,为每个分组设置对应的级别Lij,并且设置对应的阈值αij;按照贪心策略,选择级别一高一低的顺序插入,构造不会出现相同级别记录的等价类,实现了m个敏感属性的多样性。通过研究改进的(αij,k,m)-匿名隐私保护模型和基于贪心策略的匿名化隐私保护算法,从技术执行的各个关键步骤找到了该模型在m的不同取值下与其他模型信息损失度和时间效率的对比图。综合考虑,改进的(αij,k,m)-匿名隐私保护模型能够满足对多敏感属性数据的隐私保护需求,积累相关数据集、实现代码及为改进的(αij,k,m)-匿名隐私保护模型和基于贪心策略的匿名化隐私保护算法研究提供实际的支持。将(αij,k,m)-匿名隐私保护模型和匿名化隐私保护算法结合,解决了不同多敏感属性数据的匿名化问题和关联攻击问题,并且提高了隐私数据的保护程度。形式化地定义信息损失度和时间效率,可以更加客观地分析、比较不同匿名化隐私保护技术的性能。
5 结语
本文提出了抵制多敏感属性关联攻击的(αij,k,m)-匿名模型。该模型信息损失量小,可以对多敏感属性的数据进行更好的保护。针对此模型本文提出了基于贪心策略的实现算法,实验证明所提出的算法能实现面向多敏感属性的(αij,k,m)-匿名模型,有效地保护了含有多敏感属性数据的个人隐私,提高了数据隐私的保护程度。
本文所提出的算法在执行时间上还有待改进,而且本文针对不同算法进行了对比,接下来将针对这两方面进行研究,如何在不影响算法匿名保护的基础上提升算法执行时的效率是一项很有意义的工作。
References)
[1] ABAD B, KINARIWALA S A. A novel approach for privacy preserving in medical data mining using sensitivity based anonymity [J]. International Journal of Computer Applications, 2013, 42(4): 13-16.
[2] PURUSHOTHAMA B R, AMBERKER B B. Duplication with trapdoor sensitive attribute values: a new approach for privacy preserving data publishing [J]. Procedia Technology, 2012, 6(4): 970-977.
[3] JIANG W, CLIFTON C. Privacy-preserving distributedk-anonymity [C]// DBSec’05: Proceedings of the 19th Annual IFIP WG 11.3 Working Conference on Data and Applications Security. Berlin: Springer, 2005: 166-177.
[4] SORIA-COMAS J. DOMINGO-FERRER J. Probabilistick-anonymity through micro aggregation and data swapping [C]// Proceedings of the 2012 IEEE International Conference on Fuzzy Systems. Piscataway, NJ: IEEE, 2012: 1-8.
[5] MACHANAVAJJHALA A, GEHRKE J, KIFER D, et al.L-diversity: privacy beyondk-anonymity [C]// Proceedings of the 22nd International Conference on Data Engineering. Piscataway, NJ: IEEE, 2006: 24-35.
[6] BHATTACHARYYA D K. Decomposition+: improvingl-diversity for multiple sensitive attributes [C]// CCSIT 2012: Proceedings of the 2012 International Conference on Computer Science and Information Technology. Berlin: Springer, 2012: 403-412.
[7] WONG R C, LI J, FU A W, et al. (α,k)-anonymity: an enhancedk-anonymity model for privacy preserving data publishing [C]// KDD ’06: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2006: 745-759.
[8] 刘丽杰,李盼池,李守威.粒化(α,k)-匿名方法研究[J].计算机工程与应用,2014,50(2):75-80. (LIU L J, LI P C, LI S W. Research of granulating (α,k)-anonymity method [J]. Computer Engineering and Applications, 2014, 50(2): 75-80.)
[9] 金华,张志祥,李善成,等. 基于敏感性分级的(αi,k)-匿名隐私保护[J].计算机工程,2011,37(14):12-17.(JIN H, ZHANG Z X, LI S C, et al. (αi,k)-anonymity privacy preservation based on sensitivity classification [J]. Computer Engineering, 2011, 37(14): 12-17.)
[10] TRUTA T M, VINAY B. Privacy protection:p-sensitivek-ano-nymity property [C]// ICDEW 2006: Proceedings of the 22nd International Conference on Data Engineering Workshops. Washington, DC: IEEE Computer Society, 2006:94-94.
[11] LI N, LI T, VENKATASUBRAMANIAN S.t-closeness: privacy beyondk-anonymity andl-diversity [C]// ICDE 2007: Proceedings of the 23rd International Conference on Data Engineering. Piscataway, NJ: IEEE, 2007: 106-115.
[12] 罗方炜,韩建民,鲁剑峰,等.抵制多敏感属性关联攻击的(l,m)-多样性模型[J].小型微型计算机系统,2013,34(6):1387-1391.(LUO F W, HAN J M, LU J F, et al. A (l,m)-diversity model of resisting the associated attack based on multi-sensitive attributes [J]. Journal of Chinese Computer Systems, 2013, 34(6): 1387-1391.)
[13] 刘志军,张艳丽,闫晶晶,等.面向多敏感属性的个性化分级(l,α,m)-多样性匿名方法[J].科技通报,2016,32(1):123-127.(LIU Z J, ZHANG Y L, YAN J J, et al. An personalized classification (l,α,m)-diversity anonymous approach based on multi-sensitive attributes [J]. Bulletin of Science and Technology, 2016, 32(1): 123-127.)
[14] LI J, WONG C W, FU W C, et al. Achievingk-anonymity by clustering in attribute hierarchical structures [C]// DaWaK 2006: Proceedings of the 2006 International Conference on Data Warehousing and Knowledge Discovery. Berlin: Springer, 2006: 405-416.
[15] HAN J, YU H, YU J. An improvedl-diversity model for numerical sensitive attributes [C]// Proceedings of the 3rd International Conference on Communications and Networking in China. Piscataway, NJ: IEEE, 2008: 938-943.
This work is partially supported by the National Natural Science Foundation of China (61462009), the Scientific Research Foundation of Guangxi University for Nationalities (2014MDYB029), the China-ASEAN Research Center of Guangxi University for Nationalities (Guangxi Science Experimental Center) 2014 Open Project (TD201404).
WANGQiuyue, born in 1991, M. S. candidate. Her research interests include information security.
GELina, born in 1969, Ph. D., professor. Her research interests include information security.
GENGBo, born in 1990, M. S. candidate. His research interests include information security.
WANGLijuan, born in 1992, M. S. candidate. Her research interests include information security.
