基于像素自适应背景建模的运动目标分割
2018-03-19李宗民张洲凯刘玉杰
李宗民,张洲凯,刘玉杰
(中国石油大学 计算机与通信工程学院,山东 青岛 266580)
0 引 言
视频目标分割技术[1]近几十年经历了很大的发展。最早的方法有背景减除法和帧差法,后来相继提出了基于卡尔曼滤波、基于光流的方法、基于高斯混合模型的方法、基于背景建模的方法等。总体上经历了从基于空域、基于时域到基于时空联合特征的流程。虽然取得了一定的效果,但是仍然有很多问题没有得到完美地解决,如阴影、鬼影、遮挡和动态背景等。大多数方法分割精度并不是很高或者难以满足实时性。基于像素背景建模的方法具有模型简单,更新分割快和分割精度高的特点,具有更好的实用意义。此类方法一般以颜色值和梯度信息作为像素的特征,缺少空间信息,不能表达出像素之间的时空连续性,因此只能在后续步骤中对像素进行邻域内的信息整合处理,使分割得到的区域尽可能保持一致。基于像素背景建模的方法主要有:ViBe、SACON、PBAS[2]。其中PBAS借鉴了之前工作的优点,不但实现了背景模型更新,还可以动态调整分割的阈值和模型的更新速率,取得了很好的分割效果,但是对于背景变化较快,存在光照或者阴影的情况,PBAS的分割效果也不够理想,而且难以消除鬼影区域。
本文主要针对PBAS方法存在的缺陷进一步改进。首先,针对模型更新机制进行了改进,使更新的响应更加灵活和可靠;其次,根据像素判定为前景点次数去除鬼影点,将边界前景像素和邻域背景模型作二次比较,确定是否为鬼影;通过阴影检测去除阴影。在CDnet 2014[3]数据集上进行实验和PBAS进行对比,验证改进后的效果。
1 相关工作
大多数视频序列运动目标分割方法的主要依据是:在摄像机固定的情况下,当前帧和参考背景的差异可以反映出运动目标。这样处理的优点是无需先验知识。和基于目标检测的方法不同,这类方法可以得到运动目标的精确边缘,而非仅仅是一个约束框。然而,由于在真实条件下,由于视频背景的动态变化特性,一般需要建立视频背景模型。
最早的背景建模雏形是背景减除法,这种方法比较简单,效果也很差。为了增强算法对环境的适应能力,部分学者提出了自适应背景建模的方法。最早的自适应方法使用像素均值和卡尔曼滤波的方法创造参数化背景模型,用于背景的比较。这类方法对于噪声较为鲁棒,可以缓慢地适应全局光照变化,但是对于阴影和多模态背景处理效果不佳。为了解决多模态的问题,高斯混合模型GMM (Gaussian mixture models)被应用于动态背景建模,并得到广泛的应用。文献[4]提出的方法依赖一个混合多层系统:融合了基于通量张量的运动检测和分割高斯混合模型的分类结果,通过目标层的处理区分固定前景目标和鬼影区域,并且取得了不错的效果,但是方法较为耗时。基于核密度估计的方法采用了非参数模型,直接由像素的颜色值估计背景概率密度函数。然而大多数的基于核密度估计的方法由于获得的观测值有限,制约了模型的精度。文献[5]中提出了一种随机采样方法,并在文献[6]中得到了改进,此类方法通过将模型用观测得到的值随机替换的方法解决了上述的方法存在的问题。此外还有基于码本的方法,将观测值聚类得到码字保存到局部字典内,这样就可以把长期的观测结果保存在背景模型之中。文献[7]中引入了人工神经网络,并且在多个场景下实现了不错的效果。然而,此类方法需要预训练过程,这无疑增加了算法的复杂性和难度。针对这一问题,文献[8]中采用了基于二元节点的无权神经网络进行在线学习。除此之外,其它的方法则通过基于连接元的高级正则化技术,超像素和马尔可夫随机场[9],静态目标检测[10]来改进分割的区连续性。一些方法采用区域层[11],帧层级或者两者融合[12]的对比,利用邻域像素进行背景的建模。文献[13]中首先进行超像素预分割,通过超像素确立运动区域,结合高斯混合模型的精细分割和局部图割获得目标的精确结果,相比基于光流的方法更加高效。文献[14]中同时考虑将分割和光流估计相结合,通过分割的结果对光流估计的结果进行纠正,从而使分割的精度得到提高。文献[15]提出一种基于参数化曲线模型对目标边界进行表达,通过对边界的稳定性进行观测,确定前景目标。文献[16]采用非监督的迭代方法生成目标的区域,在生成约束框的基础上,不断精炼结果,获取像素级的分割结果。文献[17]中首先生成推荐目标,通过在构建的有向帯权图上求取最大路径,获取最可能为前景目标的区域,最后通过基于图割的方法得到精确的分割结果,计算的复杂度较大。文献[18]受深度学习在追踪中应用的影响,将深度学习的方法应用于视频目标分割。利用静态图像训练的卷积网络检测目标的区域,指导分割的进行;利用在线和离线学习的方法,可以在对目标进行估计的同时,获取特定目标的外观特征。
上述的方法总体来说取得了很大的进步,但是计算的模型和求解步骤非常复杂。视频目标分割作为视频处理的基础对实时性要求很高,上述的大多数方法在实际应用中很难得到推广。
基于单像素进行背景建模的方法把历史背景像素存储在模型内,通过随机替换的方法更新背景模型,动态地调整更新速率。其中,PBAS[2]方法分割速度较快,更能满足实时处理的实际需求,但是,对于难以解决鬼影、阴影和动态背景等问题,分割效果还有待进一步提高。
2 PBAS算法
PBAS运动目标分割是一个基于像素进行背景建模的方法,通过保存每个像素的历史像素值作为背景的模型,将当前帧的每个像素和背景模型进行比较来判定前景背景,为了保证算法的鲁棒性,还对模型进行连续地更新,使之适应背景的变化,并且不断更新决策阈值和模型的学习率。算法的整体流程如图1所示。
2.1 背景模型与决策
PBAS对视频帧中的每个像素建立一个长度为N的背景模型,保存的是N个历史背景像素值,因此每个像素的背景模型中都包含了该像素可能出现的像素值特征,模型如下
B(xi)={B1(xi),…,Bk(xi),…,BN(xi)}
(1)
如果输入帧Ii中像素xi的值和背景模型中的N个历史像素值中至少有#min个相近,则判定为背景点,否则为前景点,像素值和历史像素值的比较通过决策阈值R(xi)确定,定义如下
(2)
式中:F=1表示判定为前景点,R(xi)是每个像素自己的决策阈值,#min是像素和背景模型中元素至少相同的个数。
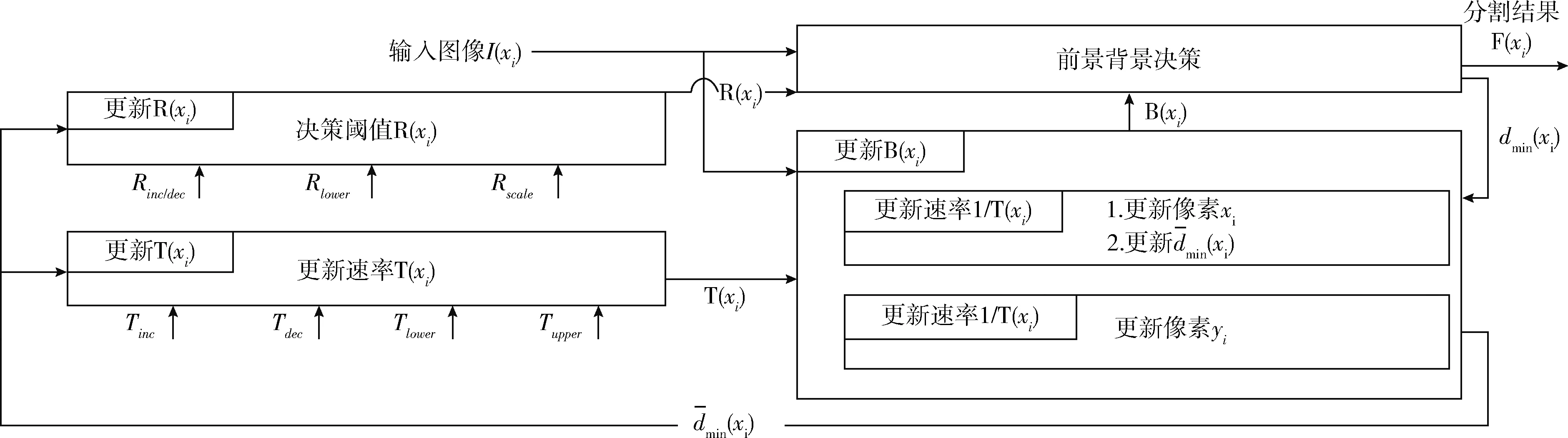
图1 PBAS流程
2.2 背景模型的更新
传统的方法不对背景模型进行更新,因此模型中包含的像素值是不变的,这就使得在环境发生变化的时候,如光照变化,背景的实际值发生了变化,从而导致决策结果出错。为了提高算法的鲁棒性,PBAS在决策过后都会对背景模型更新。如果当前像素判定为背景点,则随机地选择其背景模型中N个值中的一个,用当前像素值替换更新,同时,在邻域中随机选择一个像素的背景模型用当前值进行更新。背景模型的更新速率为p=1/T(xi), 参数T(xi)决定了背景模型的更新概率。因此,模型是否更新是个随机选择的过程,T(xi)越大则更新概率越小,更新的速度也就会越慢。
2.3 决策阈值的更新
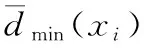
(3)
式中:Rinc/dec,Rscale——固定参数,用于调节R(xi)。
2.4 学习率的更新
像素的背景模型只保存背景像素,所以只有判定为背景模型才对背景模型进行更新,同时对邻域中的一个随机挑选的像素的背景模型进行更新。这样更新的结果就是前景目标的边缘像素会不断地融入到背景中,更新速率决定了融入的速度。学习率T(xi)的更新方式如下
(4)
其中,Tinc,Tdec为固定参数。学习率的上下界为(Tlower,Tupper)。
3 本文方法
3.1 更新方式改进
视频的背景由于环境突变(如:风吹动树叶,车辆增多)产生误检时,很容易向背景模型里引入错误的像素值,影响后续的分割结果,因此必须迅速地降低背景的更新速度;而当背景环境趋于稳定的时候应该缓慢的提高背景模型更新的速率,这样可以尽最大限度的保证背景模型的及时更新。而PBAS中采用的阈值决策方式并不能及时进行响应,因此本文提出对于阈值和环境复杂度应采用下式关系进行阈值调节判定,提高响应速度
(5)
(6)
3.2 鬼影处理
如果初始帧中存在前景目标,初期的背景模型会包含前景像素的信息,导致后续帧中不断将背景错分为前景,产生难以消除的“前景”区域,这称为“鬼影”。通过分析发现,鬼影通常在一个区域长时间停留,鬼影的像素和周围的背景往往是相似的,因此基于这两点分析,本文提出了对于鬼影的处理方法。
首先对前景建立前景统计图,统计每个像素判定为前景的时间长度,当时间超过一定的长度则判定为鬼影,并归为背景,同时更新背景模型。
其次对于判定为非背景的像素,如果邻域的像素yi为背景,则与邻域像素yi背景模型B(yi)进行二次对比判断是否为背景,进一步降低鬼影点数目,提高结果的可靠性
(7)
图2为blizzard中的片段示例,4幅图依次是:输入图像、groundtruth、PBAS结果和加入鬼影检测的结果。视频开始存在前景目标,造成了后续帧中存在鬼影。通过加入鬼影检测,鬼影得到了更快地消除。

图2 鬼影去除效果
3.3 阴影检测
为了进一步消除阴影带来的影响,本文采用文献[1]中的基于颜色不变量的移动阴影检测算法进行阴影的检测与消除。像素的颜色不变特征计算如下所示
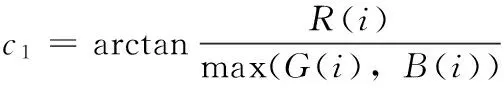
(8)
式(8)中的R(i)、G(i)、B(i)代表像素的RGB值,通过将像素和对应背景模型比较可得D(i)
(9)
对D(i)的值和RGB值分析进行背景判别,判别准则见表1。

表1 判别准则约定
表1中,α是允许方差波动范围的阈值参数,fbackground、fforeground和fshadow是前景、背景和阴影的决策阈值。
图3为cubicle中的片段示例,视频中由于光照影响,存在大量阴影。通过加入阴影检测,算法能够更好地识别和消除了人脚下的阴影区域,前景分割结果更加理想。

图3 阴影检测效果对比
4 实验结果及分析
实验环境为Intel i3 2100,处理器主频为3.1GHz,系统内存为8G,软件环境为VS2013,OpenCV2.4.8。
4.1 定性分析
首先对算法进行定性分析。为了验证算法的有效性,我们在CDnet2014数据集上将改进后的方法和PBAS进行了对比。CDnet2014数据集包含11个视频类,每个类对应不同的视频类型,用于测试方法在不同情况下地分割方法,每个类中包含若干个视频。
图4到图9分别显示了部分实验结果的对比情况。第一列图像是数据集中的原始图像;第二列图像表示groundtruth;第三列是用PBAS的分割结果;第四列图像为用本文改进后PBAS方法的分割结果。

图4 baseline
图4中是baseline中的highway的对比结果,路旁的树木阴影会随着枝叶的摇摆而运动,造成前景和背景的快速变化,这对于模型是一个很大的挑战,图中的车顶部分的分割结果有部分残缺。相比之下,经过改进以后,方法更加可靠,车顶部分的分割结果也十分的完整。视频上方驶来的车辆和摄像机距离较远,因此较为模糊,这就造成了分割的结果有大量的残缺,但是改进后的方法也可以很好地分割出来,可见对于阴影和远距离目标,本文的方法都可以更好地解决。
图5是office的对比结果,主要挑战来自于光照的影响产生的阴影和反光,并且视频中的人会有移动中的短暂静止,这就容易产生鬼影现象。而且目标移速较慢,很容易造成前景消失,所以PBAS分割结果并不完整。由于算法采用了更为鲁棒的模型更新方式,所以更快地进行模型更新,提高了前景判断精度,能够更好地分割出前景目标效果更加理想。

图5 office
图6是PETS2006视频序列的对比结果,该视频的主要问题是存在反光,由于距离影响,远处目标不够清晰,而且目标存在间歇性的运动,通过对比可以看出本文的方法在有反光的影响下也能更好地分割前景目标。可见对于模糊目标和间歇性运动目标,本文的方法效果更佳。

图6 PETS2006
图7是dynamicBackground中canoe的对比结果,在该实例中,水面的波动会产生闪动的亮点,使分割结果内存在大量的噪声和孤点,由于船上的人物不断运动,颜色和背景相近且较为模糊,所以分割难度很大。原方法在分割船体的时候不够完整,人物肢体则无法分割,而改进后的方法不但能够很好的分割船体,而且还能够把人物很好的分割出来。

图7 canoe
图8是shadow中的cubicle视频序列的对比结果。在该视频序列中主要问题是阴影和反光。 PBAS方法部分肢体分割不完整,而本文的方法却可以获得更加完整的肢体部分,并且远处的目标分割效果也更好。

图8 cubicle
图9中是blizzard视频序列的对比结果。blizzard中,场景较为模糊,而且车辆目标和背景的颜色部分相似,很容易造成前景误分为背景,在目标较远是尤其明显。如图所示,PBAS将车窗和左侧的部分误分为背景部分,而本文的方法得到了更加精确的结果。

图9 blizzard
实验结果表明,该方法对于场景中存在的干扰更加鲁棒,对于接近背景的前景部分判断能力更强,受到反光和阴影更小,对于细小目标也能够实现更为精确的分割,模型的更新效率更高,能够提取出比较完整而准确的前景对象,其性能要优于PBAS方法,能够达到更好的效果。
4.2 定量分析
较早的基于像素建模的方法相比PBAS效果差距较大,因此我们只对PBAS和本文中提出的方法进行了定量分析评估,共采用了5个标准:Recall,Specificity,FPR,FNR,F-measure,各个指标的含义在式(10)中做了详细说明。
TP:正确前景
FP:错误前景
FN:错误背景
TN:正确背景
Re(Recall):TP/(TP+FN)
Sp(Specficity):TN/(TN+FP)
FPR(FalsePositiveRate):FP/(FP+TN)
FNR(FalseNegativeRate):FN/(TP+FN)
F-measure:
(2*Precision*Recall)/(Precision+Recall)
(10)
实验的结果在表2中列出,bw、bl、io、sd和tm分别表示CDnet2014数据集中的几个视频类的名称缩写:BadWeather、baseline、Intermittent ObjectMotion、shadow和thermal,oa表示总体平均水平。粗体数据是改进后算法对应的每个视频类结果。本文中的方法得到的实验结果的Recall均高于PBAS得到的结果,平均高出0.1172;Specificity和PBAS得到的值相近;FPR略高于PBAS,但是FNR明显优于PBAS的实验值,平均低。由此可见,通过改进阈值更新机制,引入鬼影检测和阴影检测,本文中的方法对目标的分割效果相比PBAS方法,得到了进一步提高。
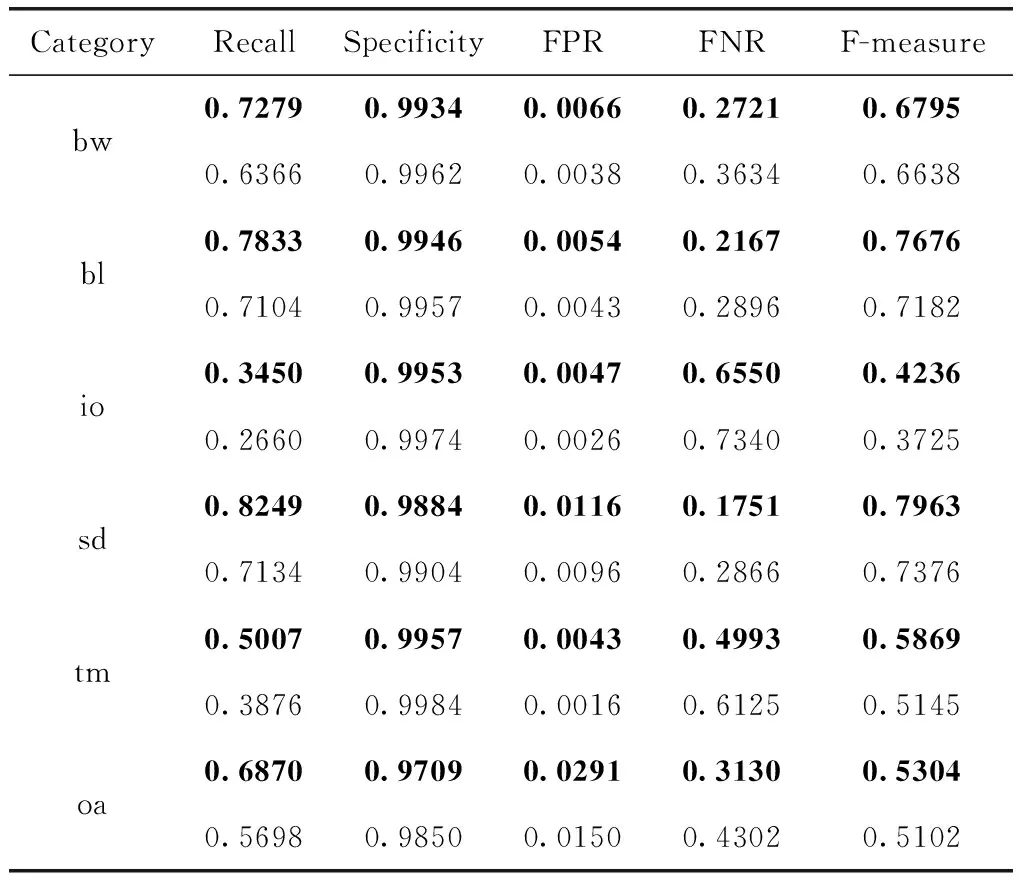
表2 CDnet2014部分实验结果
5 结束语
本文中通过对PBAS的背景更新机制进行改进,使阈值的调整更加的鲁棒,获取的阈值相比之前也更为精确,因此明显减少了前景背景的误分,提高了精度;对前景进行二次检测和判定为前景次数进行控制,减少鬼影对于分割结果造成的影响;用基于颜色不变量的移动阴影检测识别阴影区域,提高对前景的分割精度。实验结果中的定性和定量分析表明,本文的方法相比之前的方法精度有了明显的提高,鲁棒性更好。
[1]LI Zongmin,GONG Xuchao,LIU Yujie.Research on video object segmentation based on multi-feature jointed modeling[J].Journal of Computer,2013,36(11):2356-2363(in Chinese).[李宗民,公绪超,刘玉杰.多特征联合建模的视频对象分割技术研究[J].计算机学报,2013,36(11):2356-2363.]
[2]Hofmann M,Tiefenbacher P,Rigoll G.Background segmentation with feedback:The pixel-based adaptive segmenter[C]//Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE,2012:38-43.
[3]Wang Y,Jodoin P M,Porikli F,et al.CDnet 2014:An expanded change detection benchmark dataset[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Columbus:IEEE,2014:387-394.
[4]Wang R,Bunyak F,Seetharaman G,et al.Static and moving object detection using flux tensor with split Gaussian models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Columbus:IEEE,2014:414-418.
[5]Van Droogenbroeck M,Paquot O.Background subtraction:Experiments and improvements for ViBe[C]//IEEE Compu-ter Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE,2012:32-37.
[6]St-Charles P L,Bilodeau G A,Bergevin R.Flexible background subtraction with self-balanced local sensitivity[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Columbus:IEEE,2014:408-413.
[7]Maddalena L,Petrosino A.The SOBS algorithm:What are the limits?[C]//Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE,2012:21-26.
[8]De Gregorio M,Giordano M.Change detection with weightless neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Columbus:IEEE,2014:403-407.
[9]Schick A,Bäuml M,Stiefelhagen R.Improving foreground segmentations with probabilistic superpixel Markov random fields[C]//Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence,Rhode Island:IEEE,2012:27-31.
[10]Morde A,Ma X,Guler S.Learning a background model for change detection[C]//Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE,2012:15-20.
[11]Jodoin J P,Bilodeau G A,Saunier N.Background subtraction based on local shape[EB/OL].[2017-03-10].https://arxiv.org/pdf/1204.6326.pdf.
[12]Nonaka Y,Shimada A,Nagahara H,et al.Evaluation report of integrated background modeling based on spatio-temporal features[C]//Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE,2012:9-14.
[13]Giordano D,Murabito F,Palazzo S,et al.Superpixel-based video object segmentation using perceptual organization and location prior[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Boston:IEEE,2015:4814-4822.
[14]Tsai Y H,Yang M H,Black M J.Video segmentation via object flow[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:3899-3908.
[15]Lu Y,Bai X,Shapiro L,et al.Coherent parametric contours for interactive video object segmentation[C]//Procee-dings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:642-650.
[16]Xiao F,Jae Lee Y.Track and segment:An iterative unsupervised approach for video object proposals[C]//Procee-dings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:933-942.
[17]Zhang D,Javed O,Shah M.Video object segmentation through spatially accurate and temporally dense extraction of primary object regions[C]//Proceedings of the IEEE Confe-rence on Computer Vision and Pattern Recognition.Portland:IEEE,2013:628-635.
[18]Khoreva A,Perazzi F,Benenson R,et al.Learning video object segmentation from static images[EB/OL].[2017-03-10].https://arxiv.org/pdf/1612.02646.pdf.
