透明进程间通信协议在集群系统中的应用
2018-03-19张淑萍
赵 晨,张淑萍
(中国航天科工集团第二研究院706所,北京 100854)
0 引 言
为解决单核计算机运算能力有限,无法适应现今信息膨胀、运算需求急剧增长的环境,多核/众核计算模式、集群系统等新型计算体系应运而生,针对集群系统所设计开发的标准接口与通信协议也层出不穷,如基于共享存储的OpenMP、Pthread和基于消息传递的MPI、PVM等。本文研究的MPICH2是一种基于集群并行计算通信标准接口MPI(message passing interface)的具体实现。第二代消息传递接口实现(MPICH2)默认采用TCP/IP协议进行节点间通信,集群间通过消息传递进行数据互通且信息传递模式适用于多重设定,独立于网络速度和内存架构中,具有高度的可移植性,逐渐成为广泛使用的集群并行运算接口[1]。
现今出现的若干网络通信协议及硬件通信平台,针对集群间通信频繁的特点做出相应优化,对于连接建立/拆除、数据流阻塞/非阻塞等具体问题提供更为实用的方式,极大降低了网络的通信延迟,提升网络通信性能,这些提升单单通过传统的TCP/IP协议显然不足。现今一些人已针对如何提升MPICH2集群通信性能进行相关研究,Ren′e Grabner等[2]提出使用InfiniBand高速互联网络构建MPICH2的数据分发接送这样一种研究思路;Cray公司的Howard Pritchard等[3]提出基于MPICH2底层Nemesis通道进行拓展,加入一种用户层通用网络接口用于支持其公司自有的CrayXE超级计算机;金亨科等[4]使用RapidIO替代传统的设备层,采用RapidIO底层硬件以及接口,为脱离采用以太网模拟器使用RapidIO这一劣势,借鉴SCTP协议开发出SRI接口实现MPI上下层之间的通信并实验验证。然而这些研究建立在特定的硬件实现平台上,移植性有限,少有建立MPI上层应用与底层设备实现之间的统一接口,为不同硬件通讯平台的相互移植带来困难。
为实现节点间通信效率的提升以及构建更加开放的平台环境,本文采用一种透明进程间通信协议TIPC(transparent inter-process communication),代替MPICH2默认采用的TCP/IP协议进行节点间通信。本文通过实验对比TCP/IP协议与TIPC协议在连接频繁建立/拆除过程中的性能差异,随后分析MPICH2源码架构,借鉴TCP/IP在MPICH2中的实现方式及分段传输的设计思路,利用TIPC网络拓扑追踪及传输流控特点,设计出基于MPICH2的CH3通道下适合于TIPC协议的通信通道,完成向CH3通道下植入TIPC协议的过程,最后通过运行实际的测试程序,验证拓展后的MPICH2在节点间通信上具有更小的延迟和更高的传输带宽。
1 TIPC简介及其与TCP/IP性能比较
1.1 TIPC结构及特点简介
TIPC由爱立信公司Maloy J等开发,目前由风河公司维护[5]。Linux 2.6.30及以上版本中已将TIPC内核模块作为可加载项植入内核中。其实现结构如图1所示。

图1 TIPC结构框架
TIPC最上层实现了与用户间建立连接交互的各项接口,包括通用的socket接口、TIPC自定义的Port接口以及用户自行编写的其它接口;中间层为TIPC的内核组态,包含与通信接口建立连接的各项通信端口,以及地址服务、名称管理服务等核心的实现;最下层包含通信的物理层和链路层,对于TIPC基础包而言支持以太网、共享内存以及分布式共享内存3种链路形式,后续开发人员针对底层通信拓展了TIPC的传输模式,包括RapidIO、PCIe等,从理论上将,TIPC支持几乎所有底层通讯设备[6]。TIPC专门针对机群通信开发,具有通过功能性地址完全透明、快速可靠的进程间通信及动态感知节点增加/删除三大特征。
1.2 TIPC与TCP/IP对比验证
TCP/IP协议有其强大的普适性和众多优点,被绝大多数程序员和用户所熟知,但功能性地址不透明、建立/拆除连接过程繁琐的客观问题的存在使其在集群通信的条件下表现不佳,而TIPC协议在集群通信频繁的条件下则更具优势。Stylianos Bounanos等[7]与冀映辉等[8]分别在其文章中阐述了两者的对比实验,均验证这一结论。
笔者在两台装有千兆网卡的主机上进行乒乓传输收发测试,实验TCP/IP协议与TIPC协议传输时间上的差异。通信时间按照客户端首次发起连接请求开始到最后一次接收到回复数据后断开连接为止。套接字缓冲区按照协议默认值设置,连续通信次数总计为100 000次。得到的测试结果如图2所示。

图2 ping-pong实验结果
在传输数据大小相同的情况下,TIPC传输的时间要小于TCP/IP协议,平均减小了约20%,网络吞吐量高于TCP协议,提升了约25%左右,验证了TIPC在建立/拆除连接过程中的优势,值得一提的是,随着发送数据量的增加,TIPC协议会比TCP协议更快的达到网络吞吐量的峰值。由于系统网络端口recv()每次最多接收4244 Byte数据,且多于4 k数据在机群通信中少有一次性发送,故仅测试4 k及以下数据。由于TIPC允许一次最多发送的缓冲区大小不大于66 000字节,TCP/IP为65 536字节,所以以上数据发送均在一次数据拷贝中由应用拷贝到内核态然后进行发送,所以产生的发送延时主要取决于连接建立和拆除中造成的时延[9]。
2 基于TIPC协议的MPICH2通道层的实现
2.1 MPICH2结构分析
MPICH2是一款高性能,广泛实现MPI-1与MPI-2所定义的标准接口的应用实现,其支持多平台的最主要原因就在于源码的层次性鲜明,可在不修改上层源码的基础上,重新编写底层设备支持,完成应用实现的移植。MPICH2具有典型的3层结构[10],最上层MPICH2实现了用户编程应用使用的全部接口,包括MPI的初始化、主/从机之间的消息发送与接收等,绝大多数接口都包含在mpi.h头文件中,方便使用者直接调用而无须关注其下层的具体实现;ADI层(abstract device interface)是整个体系架构中最核心的部分,抽象了下层设备提供的具体接口,所有的MPI实现都建立在ADI层与其上下层协调配合中;ADI层往下为CH3层(channel interface),各种通信传输协议与实现就位于该底层结构中。CH3层作为最底层通道,包含多种底层设备的实现与抽象,可以便捷地进行平台的移植。CH3层提供多种传输通道,包括Nemesis、SCTP等,默认通过Nemesis通道进行网络通信,而我们所关注的TCP协议就位于Nemesis通道下。作为一款并行处理接口的应用实现,MPICH2具有相应的管理与监测工具如MPD和MPE,在此不一一赘述。
2.2 利用TIPC改进MPICH2具体实现
2.2.1 整体思路
在MPICH2-1.0.5p4版本源码中,CH3层共提供5种底层通道进行数据传输,分别为TCP传输协议sock、sctp、nemesis、shm、以及ssm。在MPI执行初始化进程过程,调用MPI_Init()函数时,依照当前默认配置的网络模式配置传输模式,调用相应的CH3底层代码。5种传输通道最上层源码提供相同的接口供ADI层配置调用,针对不同配置调用不同封装包内的函数。我们在CH3通道下修改sock通道模式,在此处添加TIPC连接的相关库文件与源码文件,同时需要重写MPICH2下TCP协议进行数据收发操作的相关函数,如有request对象需求的MPIDI_CH3_iSend(发送数据包头)和MPIDI_CH3_iSendv(数据包头+数据消息体),及无request对象需求的MPIDI_CH3_iStartMsg(发送数据包头)和MPIDI_CH3_iStartMsgv(数据包头+数据消息体)等。
由于TIPC协议规定的连接地址与传统TCP协议有所区别,我们规定在CH3接口建立连接的过程中,首先进行连接地址转换操作,将MPI定义的进程号转化为TIPC协议传输需求的端口名称。随后,调用ch3_init.c下的MPIDI_CH3_Init()函数,初始化通信端口,向进程组注册连接信息以及初始化套接字等操作,建立与目的地址端口的相互连接。在进行一次数据收发的过程中,上层函数将发送函数提供的发送缓冲区以及目的地址进行初步处理,将相关信息传递到CH3接口中,依照发送目的地址以及数据长度分配不同的发送函数。对于消息缓冲区的处理,将发送队列数据头指针*buf和数据长度data_sz存放于数据聚散发送I/O结构iovec中向下传递,等待底层TIPC调用tipc_send()等API定义函数发送到指定端口名称处,完成一次数据发送。数据接收队列不做特殊处理,与MPICH2所定义接收方式相同。
2.2.2 连接地址转换
为使集群系统运行像一台主机般运行,在通信过程中隐藏各节点的物理地址,采用功能性地址通信是目前通用的通信策略。MPICH2在上层通过进程号指明通信语句的交互对象,例如API中描述:
int MPI_Send(void *buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)。dest表明目的进程所在的节点,ADI层将该进程号存入虚链接VC(virtual connection),在虚链接中建立进程号与通信地址的key-value 键值对,同时将要传递的buffer写入到IOV中,这样,在CH3层进行sock通信的过程中,通过查找对应的key-value键值对,即可准确定位接收端,完成消息传递。
TIPC采用端口名称服务进行无连接或面向连接的数据传输,每个节点的通信单元都有一个独特的端口名称,通信单元将套接字绑定到端口名称上,在与其它设备建立连接的过程中,TIPC底层将端口名称进行翻译,与下层物理地址建立对应,保证数据正确的传输到对应的套接字节点上。端口名称结构tipc_name包含两个32位信息,如下所示:
struct tipc_name {
__u32 type;
__u32 instance;
};
type表示端口的服务类型,instance表示服务类型的具体实例,两者结合成为一个端口对外沟通的唯一渠道。tipc_name结构存储于sockaddr_tipc套接字地址结构中。为将TIPC植入MPICH2中作为通信通道,有必要在CH3层建立连接地址的转换,将进程号转变为tipc_name。为此,在mpidpre.h头文件下建立MPIDI_VC_TIPC结构如下:
typedef struct MPIDI_VC_TIPC
{
int handle;
volatile int ref_count; /* 使用同连接的通信子个数 */
MPIDI_VC_State_t state; /* VC当前通信状态*/
MPIDI_PG_t * pg; /* VC所属进程组 */
int pg_rank; /* 进程组对应的标识 */
int lpid; /* Local process ID */
struct sockaddr_tipc sockaddrtipc; /* TIPC端口名称域 */
# if defined(MPIDI_CH3_VC_DECL)
MPIDI_CH3_VC_DECL /* VC当前状态及Socket */
# endif
};
在CH3层对VC进行处理时,提取VC结构包含的进程号rank赋予到变量NODE_INST中。点对点通信中,默认TYPE变量为固定值18888,定义函数MPID_Comm_TIPC_get_name(),将NODE_INST中保存的进程号赋予VC结构sockaddrtipc.addr.name.name.instance中,等待CH3层调用相关通信函数时使用。
2.2.3 连接建立拆除方式
机群服务器将计算量分配到不同的机群节点中实现并行计算,再将最终结果汇总到服务器端完成一次机群计算调度,在运算时间上远远小于单核计算机运算时长。在这个过程中,根据计算任务本身以及服务器任务调度的不同,机群各节点间可能存在频繁的通信和数据交换需求,而这一部分时间在整体任务完成时长中所占的比重无法忽视。设机群系统完成一次计算任务,即整个应用程序的运行时间为Ttotal,理想状态下,程序运行时间包括计算时长Tcpt与通信时长Tcmn两部分组成,并且彼此之间没有重叠。则存在Ttotal=Tcpt+Tcmn。其中,Tcpt依据具体计算任务的不同需具体分析,假设机群节点间一次建立、拆除的时间为Tb&d,每次消息传递的长度固定为Lm且与传递时长Tsd成正比k(k为常数),消息共发送N次,则有Ttotal=Tcpt+N×(Tb&d+kLm) 由此看出,理想情况下,通信时长主要取决于通信连接的建立、发送/接受的时长这两方面因素。在MPICH2默认的SOCK通信模式下,使用PF_INET协议族绑定流套接字SOCK_STREAM,执行标准TCP握手流程,该模式面向连接,提供可靠传输,而其缺陷也在于此。过于冗杂的连接开销巨大,致使完成一次通信所需时长较长,不利于并行计算效率进一步提升。为优化该传输过程,现使用TIPC流式传输模式作为CH3层通信通道传输方式,简化通信连接建立/拆除步骤。
如图3所示,连接建立过程中,Client端引用create()函数创建一个通信端口cport并向服务器端发送一份携带NAMED_MSG信息的有效数据载荷(4),Server端初始端口suport接收该有效数据,阅读其中内容以识别发起请求的cport端口。随后,Server端创建一个新端口sport(5)并发起到Client端的连接请求lconnect()(6),此时,lconnect()调用是一个本地操作,直到Server端满足连接请求并向Client端回复一份携带CONN_MSG信息的数据载荷(7),在接收到响应消息后,客户端读取服务器端口信息并对其执行lconnect()(8),双方的连接正式建立。通过这种方式,双方在无需发送协议标志位信息的情况下即可建立相互连接。
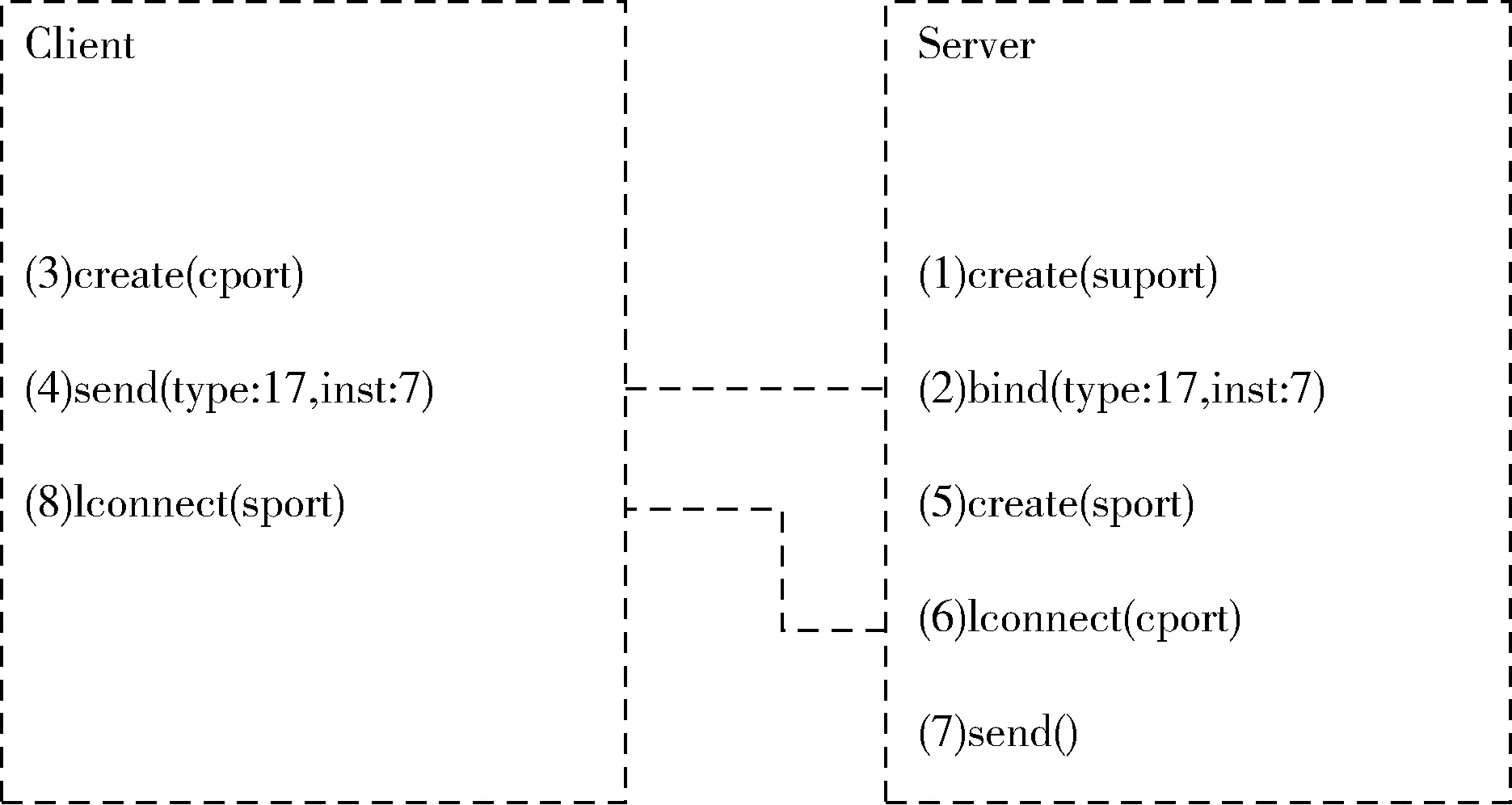
图3 TIPC连接建立
连接拆除的过程相较建立情况更为简单,如图4所示,Client端调用close()(1)功能,同时删除Client端端口信息。删除连接的端口具有以下效果:具有错误代码NO_REMOTE_PORT的DATA_NON_REJECTABLE/CONN_MSG(在TCP术语中为“FIN”)被发送到另一端。接收到这样的消息意味着接收侧的TIPC必须关闭连接,并且这必须在通知Server端之前完成。然后Server端必须调用close()(2),不要关闭连接,而是要删除端口。由于Client端口已经关闭通信端口,TIPC本次不发送任何“FIN”。完成此项操作后,双方连接拆除,表明一次通信完成。

图4 TIPC连接拆除
2.2.4 传输过程设计及流量控制
TIPC支持采取流式传输进行数据传递,对此可设定MPICH2节点间基于流式传输的分段思想。虽然这种方式仍属于面向连接类型但不同于传统TCP/IP面向连接的流式传输。以双节点Client端与Server端建立通信传输为例,双方定义传输类型为AF_TIPC协议族中SOCK_STREAM套接字类型并将其绑定到对应套接字结构sockaddr_tipc中,客户端进行完绑定套接字地址等一系列操作后,依照所要发送数据大小进行分段打包处理,设定一次包传输大小上限MSG _SIZE,超出此段上限的数据控制在下一数据包中。每段数据包头部加入4字节该段长度描述rec_size保证数据传输完整性。分段打包完成后数据结构如图5所示。
打包完成后,将数据包依次存入预先设定的iovec结构,同时,从虚连接结构VC中提取发送目的进程端口dest_port相关数据,通过tipc_send()函数将发送数据拷贝到发送缓冲区等待协议发送,每次发送数据上限为常量MSG_SIZE(最后一次发送数据大小为tot_size-sent_size)。部分实现代码如下:
…
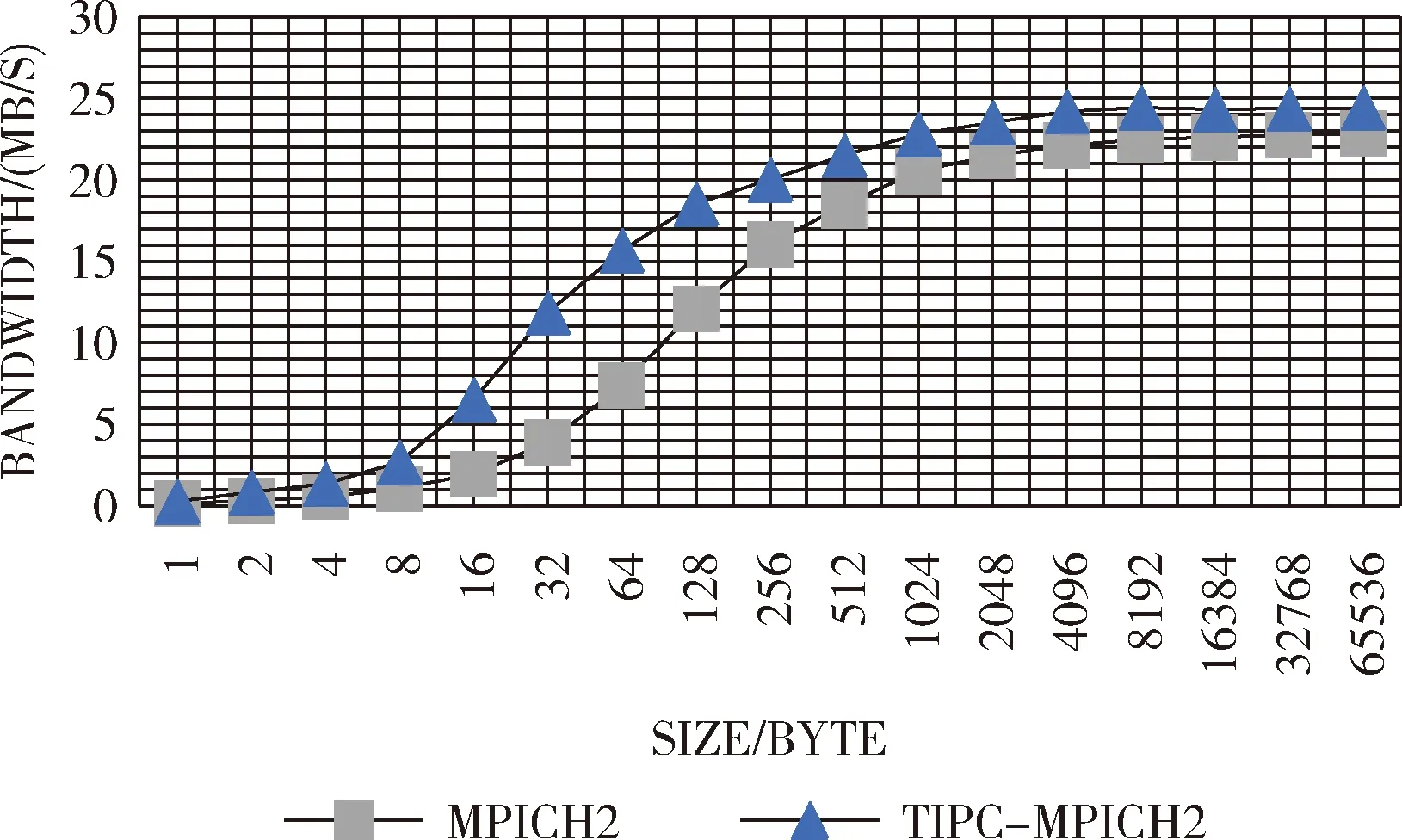
sent_size=0;
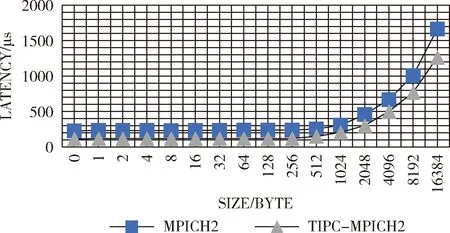
while (sent_size if ((sent_size + MSG_SIZE) <= tot_size) msg_size = MSG_SIZE; else msg_size = (tot_size-sent_size); my_iov.iov_base =&(sendbuf+sent_size);/* 存储发送缓冲区指针到iovec */ my_iov.iov_len =msg_size + 1;/* 存储发送数据大小到iovec */ if (0 > tipc_send(dest_port,1,&my_iov)) { perror("Client:failed to send"); exit(1); } sent_size += msg_size;/* 使用同连接的通信子个数 */ } … 接收端在接收到数据包后,依照数据包头指定的数据大小进行解包操作,将数据还原。值得一提的是,TIPC在下层源码中实现数据校验及确认/重传机制,编程者在上层应用中无需考虑。 图5 数据分片发送 本实验建立在两台装有千兆网卡网络互联的节点主机进行数据收发测试,测试环境为主机节点CPU:i5-460M-2.54GHz,内存4G;从机节点:CPU:i7-6700HQ-2.6GHz,内存8G。程序运行在Linux 4.4.0-2-deepin-amd64内核版本下,使用俄亥俄州立大学(OSU)公布的MPI基准测试程序进行相关测试,两个节点在一次通信中,分别向对方发送一份固定消息窗大小的消息,然后同时等待接收方回复确认信息,实际操作中,通过定义两类不同的发送进程号标志位tag对应通信通道,避免造成数据混乱或链路死锁等问题。发送接收函数采用无阻塞发送接收方式MPI_ISend与MPI_IRecv。多次重复该项进程后通过传输流程时间总长(从发送方第一次发送数据到发送方最后一次接收确认信息为止)以及消息传输总字节数来计算带宽。测定所得单双边通信带宽结果如图6、图7所示。 图6 单边通信带宽 图7 双边通信带宽 基于TIPC协议的MPICH2并行程序接口在传输带宽上表现出良好的上升特性,整体带宽提升效率在10%~20%左右。相比之下,传统MPICH2通信带宽上升迟缓。由于TIPC协议在小数据量情况下,无需单次发送确认重传等相关信息位数据,在底层尽量减少除发送数据外的其余操作,故通信带宽上升较快,大约在1 k左右到达传输峰值的90%。为得益于TIPC协议下层本身针对快速频繁的数据通信采取的流式传输方式以及简洁的流量控制处理,TIPC协议在整体传输带宽上优于传统TCP协议,在大数据量情况下,由于采用分片发送机制,仍可以保持较高的通信带宽。测试结果与预计理论值有一定差距,主要原因在于两台节点处于网络直连状态进行点对点传输,传输瓶颈除默认预配置网络连接速度外,还受限与两台节点各自硬盘拷贝速率和处理能力等因素。 同样采用OSU标准测试程序测定单双边集群通信延迟。类似乒乓传输机制,发送方向接收方发送一份确定消息长度的数据同时等待接收方反馈一份接收确认,接收方在接受到消息后向发送方回复相同长度大小的数据并等待发送方回复接收确认连续不断重复过程并求取单边延迟平均值。该程序采用阻塞发送函数MPI_Send与MPI_Recv进行数据传输。测试结果如图8、图9所示。 图8 单边通信延迟 图9 双边通信延迟 可以看出,经由TIPC协议进行传输的MPICH2通信函数在数据发送接收时间延迟上与原MPICH2函数相比,在小数据量情况下下降约50%,在1 k数据点以后通信延迟下降整体维持在20%左右。符合TIPC针对集群通信小数据量特点制定的传输优化策略。在小数据量传输时,TIPC面向连接传输在下层实现传输的完整性验证,乒乓实验中针对发送的数据量采用批量验证模式,极大减小了传统TCP协议每次调用发送接收函数后均需进行的数据确认验证(SYN+ACK),故在小数据量发送接收阶段通信延迟急剧下降。在数据量逐渐增大阶段,由于网络带宽以及由硬盘拷贝速度带来的传输瓶颈,通信延迟下降程度与小数据量阶段相比有所下降,符合传输特性。 本文将针对集群通信所设计的透明进程间通信协议TIPC运用到并行计算实现接口MPICH2中,替代MPICH2默认采用的TCP传输协议,利用TIPC面向连接的流式传输模式进行数据传输过程,简化数据传输过程。该技术目前可应用与基于以太网连接的Linux集群系统做并行计算处理。由于TIPC协议在理论上支持绝大多数底层连接方式,例如共享内存、RapidIO、PCIe等,未来可在CH3的TIPC通道下添加下层对于各种底层设备的描述,即可实现相应的集群通信,以及TIPC支持的多路冗余可靠性传输以及传输优先级判别等功能。 [1]LU Yun’e,HUANG Zongyu,LI Chaoyang,et al.The MPI parallel computing based on the microcomputer cluster[J].Electronic Design Engineering,2011,19(5):78-81(in Chinese).[卢云娥,黄宗宇,李超阳,等.基于微机集群系统的MPI并行计算[J].电子设计工程,2011,19(5):78-81.] [2]Grabner R,Mietke F,Rehm W.An MPICH2 channel device implementation over VAPI on infiniBand[J].Proceedings-International Parallel and Distributed Processing Symposium,2004,18:2581-2588. [3]Pritchard H,Gorodetsky I.A uGNI-Based MPICH2 nemesis network module for Cray XE computer systems[G].LNCS 6960:Computer Science,2011:110-119. [4]JIN Hengke,LEI Yongmei,LIANG Ji.Middleware for MPI based on RapidIO[J].Computer Engineering and Design,2008,29(21):5464-5467(in Chinese).[金亨科,雷咏梅,梁基.基于RapidIO的MPI设备层的设计与实现[J].计算机工程与设计,2008,29(21):5464-5467.] [5]Maloy J P.TIPC:Providing communication for Linux clusters[C]//Proceedings of the Ottawa Linux Symposium,2004. [6]Maloy J.Linux TIPC 1.7 programmers_guide_1.7.6.[EB/OL].http://tipc.sourceforge.net/doc/tipc_1.7_programmers_guide.pdf, 2008. [7]Mandvekar L,Qiao C,Husain M I.Enabling wide area single system image experimentation on the GENI platform[C]//Second Geni Research and Educational Experiment Workshop.IEEE Computer Society,2013:97-101. [8]JI Yinghui,CAI Wei,CAI Huizhi.Research and analysis of transparent inter process communication protocol[J].Computer Systems Applications,2010,19(3):76-79(in Chinese).[冀映辉,蔡炜,蔡惠智.TIPC透明进程间通信协议研究和应用[J].计算机系统应用,2010,19(3):76-79.] [9]SUN Zhongyi,JIN Tongbiao,YIN Jinyong.Performance measurement and analysis of communication protocols[J].Computer Systems Applications,2012,21(9):224-227(in Chinese).[孙忠义,金同标,殷进勇.通信协议性能测量与分析[J].计算机系统应用,2012,21(9):224-227.] [10]Goglin B,Moreaud S,Phanie.KNEM:A generic and scalable kernel-assisted intra-node MPI communication framework[J].Journal of Parallel & Distributed Computing,2013,73(2):176-188. [11]Andersson P,Maloy J,Krishnan S.A system and method for generating functional addresses:WO,EP2191634[P].2014. [12]Mehta K,Gabriel E.Multi-threaded parallel I/O for OpenMP applications[J].International Journal of Parallel Programming,2015,43(2):286-309. [13]WANG Yunsheng,WANG Jian,ZHOU Hong.TIPC communication architecture based on RapidIO[J].Telecommuni-cation Engineering,2012(12):1980-1983(in Chinese).[王运盛,王坚,周红.基于RapidIO的TIPC通信软件设计[J].电讯技术,2012(12):1980-1983.] [14]Goglin B,Moreaud S,Phanie.KNEM:A generic and scalable kernel-assisted intra-node MPI communication framework[J].Journal of Parallel & Distributed Computing,2013,73(2):176-188. [15]WANG Rui.Optimization of MPI communication library on KD60 platform[D].Hefei:University of Science and Technology of China,2011(in Chinese).[汪睿.KD60平台MPI通信库优化设计[D].合肥:中国科学技术大学,2011.]
3 实验结果及分析


4 结束语
