笔迹独体字搭配特征出现率的统计分析
2018-03-18王帅帅
王帅帅
(中国刑警学院,辽宁 沈阳 110035)
传统笔迹检验主要依靠专家经验来完成,在证明力方面收到一定质疑,如何提高笔迹检验鉴定的客观性和科学性也是笔迹检验领域现阶段亟需解决的难题。目前,DNA 鉴定技术已经可以较好地使用概率表达其检验鉴定的可信度,在笔迹量化检验鉴定中,笔迹特征出现率的量化一直以来都是人们的关注重点。本文借助计算机软件和数理统计学相关方法,通过小样本实验,在客观精确测量独体字笔画搭配特征数据的基础上对相关数据进行统计分析,制定出对应的出现率量化方法。
1 独体字的搭配特征
独体字是以笔画为直接单位构成的汉字。独体字的搭配位置关系主要是笔画交接部位和相邻笔画间的高低、远近关系。根据汉字中笔画之间的位置关系,将独体字的搭配位置关系分为以下三种:离散关系,交叉关系,连接关系。
2 数据统计分析方法
2.1 正态性检验
正态性检验是对判断一个总体是否符合正态分布进行假设检验,是一类特殊的拟合优度假设检验。进行正态假设检的方法很多,一般根据检验总体的分布特性和数据量来选择最佳的检验方法,本实验研究最佳的正态性检验方法k-s检验,可借助SPSS软件进行检验。当检验结果的显著性值大于0.05时,即符合正态分布。
2.2 百分位法
如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。处于p%位置的值称为第p百分位数。在对数据进行处理时,先进行正态性检验,如果符合正态分布,则使用置信区间的方式获得特征出现率分布;若不符合正态分布,则使用百分位法,获得特征出现率分布区间。
3 实验研究
3.1 设计并收集实验样本
以常用汉字为研究对象,为保证实验样本的真实性,设计50个常用汉字为实验样本。组织90人为样本收集对象在标准A4打印纸上书写实验样本,样本的书写一律使用中性笔坐姿书写,并以纸张为衬垫物,正常速度书写。
3.2 笔迹特征数据的提取
3.2.1 实验对象的选择
根据独体字的搭配特征类型,在样本常用汉字中对每个搭配类型选取具有代表性的单字作为实验数据提取和出现率统计分析的对象。离散关系选择“二”和“三”为实验对象,交叉关系选择”十“字为实验对象,连接关系中“T”形关系以“下”为研究对象,“┣”形关系以“正”为研究对象,折线连接以“厂”为研究对象。
3.2.2 具体特征数据的提取
3.2.2.1 离散关系搭配特征数据的提取
离散关系的搭配特征主要表现在笔画之间空间距离的远近。本实验研究中选择“二”和“三”作为研究对象,“二”字需测量两横之间距离,如图1所示;“三”字需分别测量相邻两横笔之间的距离,如图2所示。
3.2.2.2 交叉关系搭配特征数据的提取
交叉关系搭配特征,需要对笔画中交叉点搭配位置进行研究,测量交叉点两侧笔画的长度,以其比值为数据。本实验以“十”字为研究对象,如图3所示。
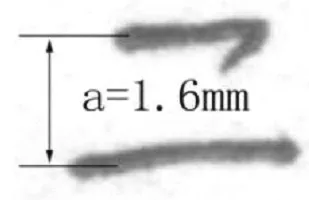
图1 “二”字搭配特征

图2 “二”字搭配特征

图3 “十”字搭配特征
3.2.2.3 连接关系搭配特征数据的提取
连接关系搭配特征有“T”形连接、“┣”形连接和折线连接三种,“T”形连接和"┣"形连接特征数据的提取方式和交叉关系相似。由于折线连接在书写时常被写成“T”形连接或“┣”形连接,或者离散关系搭配的情况,需要对三种情况分别进行统计分析。如图4和图5所示。

图4 “厂”字搭配特征

图5 “厂”字折线连接笔画的离散特征
3.3 独体字搭配特征出现率量化实验结果
使用SPSS软件对获取的实验数据进行正态性检验,对符合正态分布的特征通过计算置信区间来获得出现率,本实验分别计算95%和80%置信区间;对于不符合正态分布的特征使用百分位法计算概率分布区间,本文计算80%的概率分布区间。
3.3.1 离散关系搭配特征实验结果
对于“二”字,以两横之间距离为统计量进行分析;对于“三”字以第一、二横笔间距与第二、三横笔间距的比值为统计量。正态性检验结果如表1和图6、图7。

表1 离散关系特征单样本k-s检验结果


图7 “三”字搭配特征
通过实验结果可以看出,"二"字离散关系搭配特征检验结果显著性水平P=0.2>0.05,样本总体符合均值为1.79,标准差为0.46的正态分布,两横间距离的95%置信区间为(0.89,2.69),80%置信区间为(1.20,2.38);“三”字离散关系搭配特征检验结果显著性水平P=0.2>0.05,样本总体符合均值为0.89,标准差为0.22的正态分布,第一、二横距离与第二、三横距离比值的95%置信区间为(0.46,1.32),80%置信区间为(0.61,1.17)。
3.3.2 交叉关系搭配特征实验结果
“十”字交叉点在横笔和竖笔上的位置形成不同的搭配关系。对横笔来说,以交叉点左部与右部比值为统计量更具规律性;对竖笔来说以下部与上部比值为统计量更具规律性。分别以此为统计量。具体实验见表3和图8、图9。
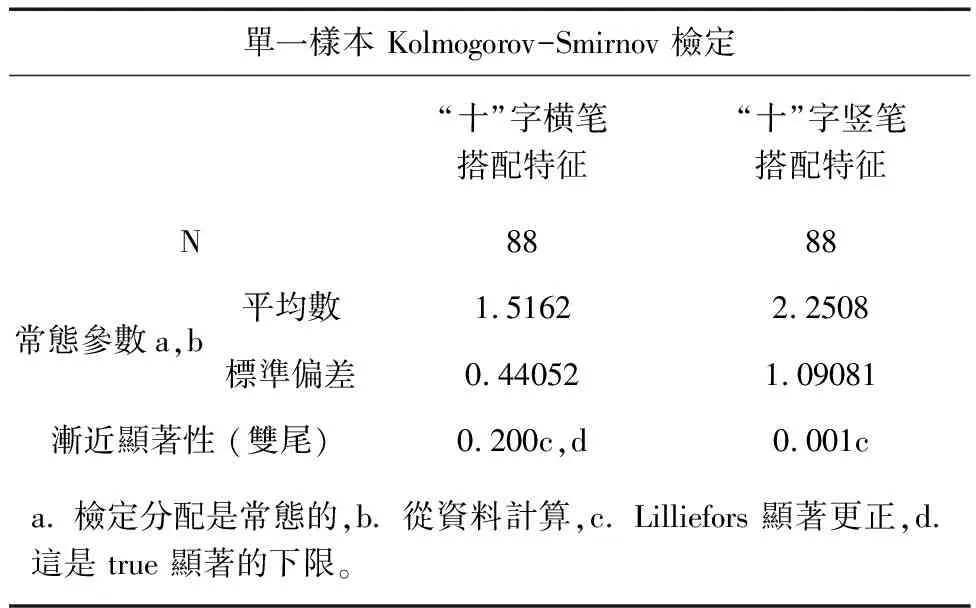
表2 交叉关系特征单样本k-s检验结果


图9 “十”字竖笔搭配特征
通过实验结果可以看出,“十”字交叉关系搭配特征显著性水平P=0.200>0.05,总体数据分布符合均值为1.52,标准差为0.44的正态分布,搭配特征的95%置信区间为(0.66,2.38),80%置信区间为(0.96,2.08);“十”字交叉关系搭配特征显著性水平P=0.001<0.05,样本总体不符合正态分布,根据SPSS输出百分位结果看出,第10百分位点为1.21,第90百分位数为3.96,80%概率区间为(1.21,3.96)。
3.3.3 连接关系搭配特征实验结果
连接关系有三种,“T”形连接以“下”字为研究对象,存在交叉点左部与右部比值以及右部与左部比值两种统计量;“┣”形连接以“正”字为研究对象,具体内容为“正”字第二笔与第三笔的搭配特征,存在上部与下部比值以及下部与上部比值两种统计量;折线连接首先分别统计离散形式、规范折线连接和“T”形连接或“┣”形连接的比例,再对“T”形连接或“┣”形连接的情况进行正态检验。以“厂”字为研究对象则先分别统计离散形式、规范折线连接和“T”形连接的出现率,再单独对“T”形连接情况进行正态假设检验。经实验对比发现,“T”形连接以左部和右部比值为统计量更具有规律性;“┣”形连接以上部和下部比值为统计量更具规律性;折线连接关系中的“T”形连接形式的右部和左部比值更具有规律性。具体实验结果见表3和图10、图11、图12。

表3 连接关系特征单样本k-s检验结果
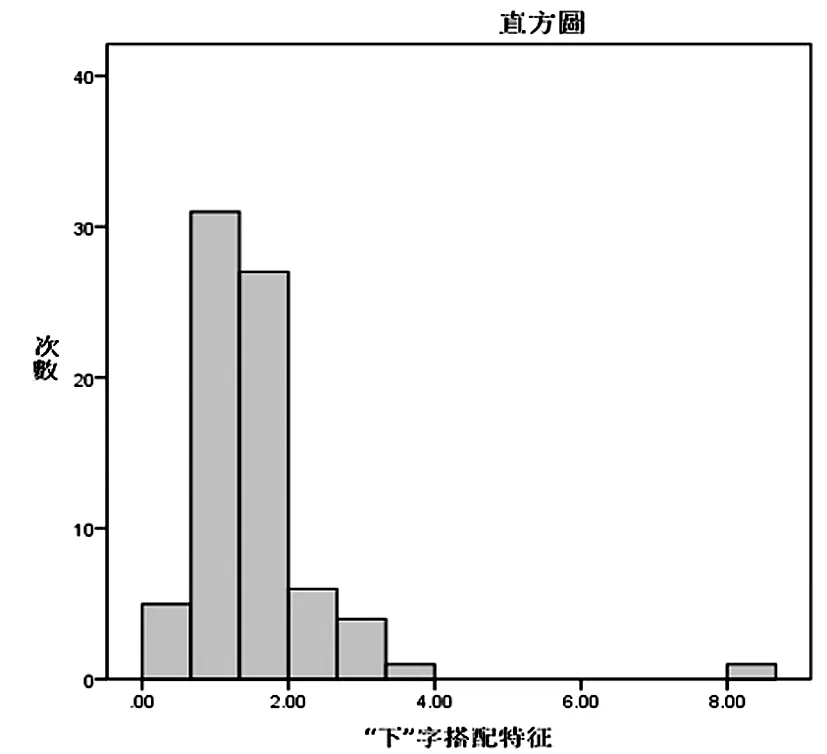
图10 “下”字搭配特征
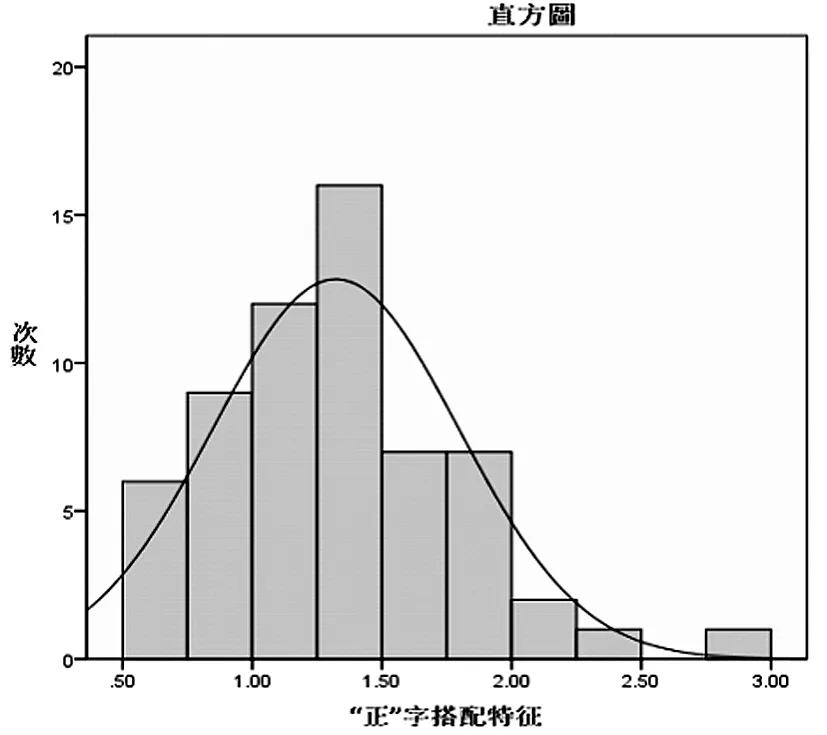
图11 “正”字搭配特征
通过实验结果可以看出,"下"字搭配特征显著性水平P=0.000<0.05,样本总体不符合正态分布,根据SPSS输出百分位结果看出,第10百分位点为1.21,第90百分位数为3.96,80%概率区间为(0.42,2.71);“正”字搭配特征显著性水平P=0.2>0.05,样本总体符合均值为1.32,标准差为0.47的正态分布,搭配特征的95%置信区间为(0.39,2.23),80%置信区间为(0.71,1.91)。

图12 “厂”字搭配特征
“厂”字统计结果显示:在88份总样本中,规范连接的出现24次,出现率为27.7%;离散连接的出现20次,出现率为22.3%;“T”形连接的出现44次,出现率为50.00%;还出现了1次及特殊的“十”字交叉连接,出现率为1.14%。对“T”形连接搭配方式中,显著性水平P=0.200P>0.05,样本总体符合均值为2.26,标准差为1.08的正态分布,搭配特征的95%置信区间为(0.14,4.38),80%置信区间为(0.88,3.64)。
4 总结
本实验研究中统计的独体字三种搭配类型中,共产生7组数据,其中5组数据正态性检验结果符合正态分布。另外两组数据虽然正态性检验不符合正态分布,但从数据分布直方图可以看出,数据分布都集中在较小的区间内,使用百分位法可以划分出具有一定特殊性的搭配类型。本文在客观测量独体字搭配特征数据的基础上,对独体字各种类型的搭配形式实现了特征出现率的量化,区分出了每种特征类型中出现率较低的特征形式,在笔迹检验中对特征价值的认识具有很高的参考意义,也为笔迹量化检验鉴定的发展起到了推动作用。
