餐饮连锁店员工离职倾向预测研究
2018-03-17徐昆赵东亮
徐昆+赵东亮
[提要] 频繁的员工流动不仅增加企业的培训成本,还会降低企业的运营能力。本文利用R语言,建立随机森林模型处理已离职人员数据,从中分析员工离职影响因素,对于企业而言,能够依据离职概率大小及离职影响因素采取针对性的挽留措施,并能够分辨员工的真正离职动机,从而可以发现更深层的企业运营体系的问题,可以为企业提供借鉴,便于提前采取措施,避免造成更多的损失。
关键词:R语言;随机森林模型;预测;满意度;离职倾向
中图分类号:F24 文献标识码:A
收录日期:2018年1月24日
一、引言
离职倾向是员工个体经历了不满意之后,想要离开组织的态度和意向,它被认为是预测离职行为最佳变量。综合国内外已有文献,离职倾向概念提出时间较早,但是其影响因素的探索一直没有停滞,由于社会文化变迁,劳动力结构的变化,离职倾向的动因也在发生着变化。员工离职意向形成基本源于两个方面因素:一是员工自身的人格特质因素,如突出个性、价值观多元化等;二是其他外部因素,比如工作设置、组织支持等。国外学者提出的离职倾向动因模型为本研究开展提供了重要的理论依据。近几年,国内对新生代知识型员工关注越来越多,其离职倾向的探索也形成了一定程度积累,但仍存在一些不足:第一,已有文献仅涉及了处于发展成熟期的民营企业和国企,缺乏以高员工流动率公司为对象展开的研究;第二,研究框架受国外模型限制较大,系统地探索离职倾向的實证研究少。
另外,随着大数据时代的到来,运用数据挖掘方法分析已离职人员数据,挖掘员工离职影响因素,对在职员工进行离职倾向预测,依据离职概率大小及离职影响因素采取针对性的挽留措施,将更有效可行。eBay,包括沃尔玛、瑞士信贷集团和Box等都正在通过大数据“算”出最有可能跳槽的员工。这些公司的HR部门会收集员工的工作任期、员工调查、沟通模式甚至性格测试等一系列数据,这些数据往往能够揭示员工去留的动机,从而分析判断员工的离职倾向性。没有一种单一的数据可以预测员工去留。离职背后的动机通常很复杂,收入多寡、同事关系、公司前景、职业规划等等,在不同公司,这些变量的影响力又有很大的差异。对于企业而言,通过数据算法分析的目的并不在于驱赶有离心的员工,而在于挽留人才以及搞清楚背后的动机,解决公司弊病。正如沃尔玛负责人员分析的全球副总裁Elpida Ormanidou所述:“如果我们能够提前三个月,我们就能够尽快地组织招聘和培训,没有人希望职位一直空缺着。”从数据中能够看到更深的层次,挖掘出企业运营体系的内在问题,从而提前采取措施,可以避免造成更多的损失。综上所述,本文以连锁餐饮业作为研究焦点,参照已有研究思路,根据大样本统计研究,借助R语言随机森林模型,对员工的离职概率进行预测,并辨识哪些因素影响该群体离职意向及不同因素的影响强度。
二、员工入职前期离职倾向预测
(一)预测模型——随机森林模型。随机森林算法的实质是基于决策树的分类器集成算法,其中每一棵树都依赖于一个随机向量,随机森林的所有向量都是独立同分布的。随机森林就是对数据集的列变量和行观测进行随机化,生成多个分类树,最终将分类树结果进行汇总。随机森林相比于神经网络,降低了运算量的同时也提高了预测精度,而且该算法对多元共线性不敏感以及对缺失数据和非平衡数据比较稳健,可以很好地适应多达几千个解释变量数据集。
随机森林的组成——随机森林是由多个CART分类决策树构成,在构建决策树过程中,不进行任何剪枝动作,通过随机挑选观测(行)和变量(列)形成每一棵树。对于分类模型,随机森林将根据投票法为待分类样本进行分类;对于预测模型,随机森林将使用单棵树的简单平均值来预测样本的Y值。
随机森林的估计过程:(1)指定m值,即随机产生m个变量用于节点上的二叉树,二叉树变量的选择仍然满足节点不纯度最小原则;(2)应用Bootstrap自助法在原数据集中有放回地随机抽取k个样本集,组成k棵决策树,而对于未被抽取的样本用于单棵决策树的预测;(3)根据k个决策树组成的随机森林对待分类样本进行分类或预测,分类的原则是投票法,预测的原则是简单平均。
随机森林性能因素:(1)每棵树生长越茂盛,组成森林的分类性能越好;(2)每棵树之间的相关性越差,或树之间是独立的,则森林的分类性能越好。
(二)指标体系的确定。为了实现预测,首先我们需要收集一些历史数据。针对S公司的实际情况,该公司当前的数据库中相关数据与我们期望相比存在一些不完善,我们决定确定一个新的指标重新建立数据库。首先我们采用文献法和开放式问卷收集相关指标条目,通过几轮删除,最终确定指标。相关指标可以分为三类:(1)个人信息。包括“姓名、性别、年龄、政治面貌、学历、职业资格”;(2)综合测评。综合测评是招聘员工时对员工的综合能力进行问卷测评,测评指标包括“言语理解、逻辑、常识、成就导向、抗压能力、社交能力、外向性、心里感受性、情绪稳定性、敬业”;(3)在职情况。在职情况是指员工在一段时间内是否离职,我们用数字表示,“0”代表在职,“1”代表已经离职。
(三)样本数据的收集。为了获得更加科学的数据并且检验预测模型的实用性,我们联系了S公司,让该公司对最近入职的一批员工共170人进行了相关指标数据的收集。首先在招聘员工入职前,通过问卷和测评,获得每位员工的个人信息和综合测评成绩,并且在之后的3个月时间里对这一批员工进行在职情况的跟踪。得到数据如表1所示。(表1)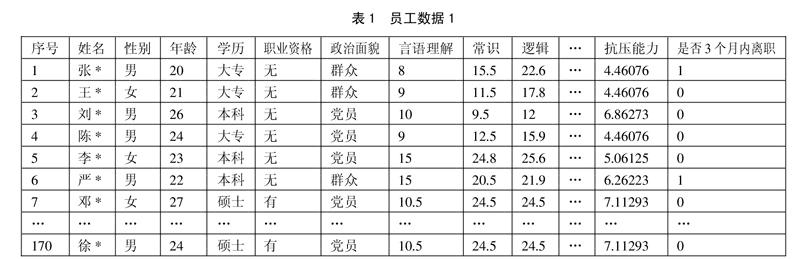
(四)预测。当我们完成了历史数据的收集之后,便可以对新一批员工进行离职概率预测了。为了便于将数据导入模型,我们可以直接在170位员工的历史数据后面添加新一批员工的数据。我们以新一批员工其中一位员工为例,他在表中的数据为第171条,需要预测的数据为“是否3个月内离职”,暂时用“NA”表示数据空缺。(表2)

第一步,需要我们打开R语言程序,下载随机森林数据包;
第二步,我们将历史数据(训练样本)和需要预测数据(预测样本)导入模型;
第三步,将历史数据(训练样本)单独提取出来供模型学习,训练模型;
第四步,对预测数据(预测样本)进行预测:
library(randomForest)#下载随机森林数据包#
d1<-read.csv(“~/Desktop/员工数据2.csv”)#读取训练样本和预测样本#
d2<-d1[1:170,3:16]#提取训练样本#
d3<-d1[171,3:16]#提取测试样本#
d2[,“是否3个月内离职”]<-factor(d2[,“是否3个月内离职”])
levels(d2[,“是否3个月内离职”])<-list(在职=0,离职=1)
set.seed(101010)
m1<-randomForest(是否3个月内离职~.,data=d2,proximity=TRUE,
importance=TRUE,na.rm=TRUE)#训练模型#
p1<-predict(m1,d3,type="prob")#预测#
p1#预测结果#
在职 离职
0.666 0.334
attr(,“class”)
[1]“matrix”“votes”
(五)结果解释及预测效果检验。根据预测结果的显示,该名员工在接下来3个月内离职的概率为33.4%,在职的概率为66.6%。
同時,我们可以增加一个对模型预测效果检验的步骤。以历史数据作为检验标准,将历史数据导入模型进行模拟“预测”,再将“预测”的结果与实际情况进行对比,检验过程如下:
p1<-predict(m1,d2)#用原始数据进行预测显示结果#
table(d2$是否3个月内离职,p1)(表3)
从表3中可以看出,预测结果与实际情况完全一致,误判率为0,模型的预测效果非常好。
三、员工入职中期工作满意度分析
当员工入职一段时间后,虽然他们暂时没有离职,但是他们都有潜在的离职倾向。根据现有的研究成果我们可以知道,离职倾向与工作满意度成负相关,也就是说,工作满意度越高,离职倾向越小;工作满意度越低,离职倾向越大。
于是我们便设计了“员工入职中期工作满意度测评”问卷,同样采用文献法和开放式问卷收集相关指标条目,通过几轮删除,最终确定指标为:“劳动强度、工作压力、与同事的关系、岗位性质、职业地位、企业体制、企业类型、组织文化、管理水平、薪酬水平、发展机会、请假调休、职业兴趣、职业意向、自尊、情感稳定性、工作技能、工作安全感、工作卷入、组织承诺”。对应不同指标,我们设计了相关问题。例如,与“薪酬水平”对应的问题为“您对目前的薪酬待遇是否意?”;与“工作安全感”对应的问题为“现在的工作是否让您感受到安全感?”。受试者在每个问题后进行打分,分数区间为“0~10”分,分数越高表示满意度越高。在问卷最后,设置了一项总体满意度评价——“您对当前工作总体是否满意?”,“0”表示满意,“1”表示不满意。最终得到132位受试者的评价数据如表4所示。(表4)
同样的,我们可以随机森林模型对员工满意度数据进行分析,并且对各自变量重要性进行排序:
d4<-read.csv(“~/Desktop/员工满意度分析.csv”)
d4[,“对当前工作总体是否满意”]<-factor(d2[,“对当前工作总体是否满意”])
levels(d2[,“对当前工作总体是否满意”])<-list(满意=0,不满意=1)
set.seed(101010)
m1<-randomForest(对当前工作总体是否满意~.,data=d4,proximity=TRUE,
importance=TRUE,na.rm=TRUE)
Importance<-importance(x=m1)
Importance
varImpPlot(m1)#重要度排序#
对员工工作整体满意度影响的各因素重要性分析如图1所示。左边图形是根据Mean Decrease Accuracy来判断自变量的重要程度。Mean Decrease Accuracy是衡量指标,衡量把一个指标的取值变为随机数,随机森林模型预测准确性降低的程度。数字越大表示该指标的重要性越大。根据这个指标,薪酬水平、工作压力、职业兴趣、发展机会4个变量是影响员工工作整体满意度的主要因素。右边图形是根据Mean Decrease Gini来判断自变量的重要程度。Mean Decrease Gini指数是计算出每个变量对分类树每个节点观测值异质性的影响程度,从而反映变量的重要性。该值越大表示该变量的重要性越大。根据这个指标,薪酬水平、发展机会、职业兴趣、与同事的关系4个变量是影响员工工作整体满意度的主要因素。(图1)
四、结论及建议
(一)结论
1、对S餐饮连锁公司来说,在员工入职前期,我们可以对员工在入职后一段时间内的离职概率进行预测,预测要建立在模型对历史数据的学习之上。对于如何建立相应的历史数据库,我们提出了3类数据指标,即个人信息、综合测评、在职情况并且详细分为17个子指标,该指标构建合理、主题明确、层次清楚、操作性强,可以方便和准确地进行统计。
2、从对S餐饮连锁公司员工入职中期的工作满意度分析可以看出,影响员工工作整体满意度的因素主要是薪酬水平、职业兴趣、发展机会、工作压力、与同事的管理系这几项。根据分析结果,公司可以有针对性地去改善,提高员工在这几个方面的满意度,从而快速提升员工工作的整体满意度,减小离职倾向。
(二)建议
1、针对不同行业和企业,要建立起合理、合适的指标体系。不同行业和企业员工的工作岗位和工作性质存在差异,可以根据员工的工作特点对数据指标体系进行更改和替换。
2、为了保证预测的精度,历史数据要尽可能越多越好。预测模型通过对大样本的学习,会进一步提高预测的准确性。
3、虽然预测模型有很高的准确性,但仍然是建立在统计学的基础之上,因此仍然存在误判率。在实际的运用过程中,可以将预测结果作为一项参考因素,而不应完全依赖预测结果,作为绝对的标准。
主要参考文献:
[1]王雪莉,马琳,张勉.基于独生子女的调节作用的个人-工作匹配、工作满意度与员工离职倾向研究[J].管理学报,2014.11.5.
[2]柯江林,孙健敏.心理资本对工作满意度、组织承诺与离职倾向的影响[J].经济与管理研究,2014.1.
[3]李洁,吕康银,熊顺朝.职业成长、工作满意度和离职倾向关系的实证研究[J].理论经济学,2012.1.
[4]刘顺祥.基于R语言的随机森林算法运用[EB/OL].http://www.docin.com,2015.11.
[5]蔡治.大数据时代的人力资源管理[M].北京:清华大学出版社,2016.
