基于信任扩展和列表级排序学习的服务推荐方法
2018-03-14方晨张恒巍张铭王晋东
方晨,张恒巍,张铭,王晋东
基于信任扩展和列表级排序学习的服务推荐方法
方晨1,2,张恒巍1,2,张铭1,2,王晋东1,2
(1. 信息工程大学三院,河南 郑州 450001;2. 数字工程与先进计算国家重点实验室,河南 郑州 450001)
针对传统基于信任网络的服务推荐算法中信任关系稀疏以及通过QoS预测值排序得到的服务推荐列表不一定最符合用户偏好等问题,提出基于信任扩展和列表级排序学习的服务推荐方法(TELSR)。在分析服务排序位置信息的重要性后给出概率型用户相似度计算方法,进一步提高相似度计算的准确性;利用信任扩展模型解决用户信任关系稀疏性问题,并结合用户相似度给出可信邻居集合构建方法;基于可信邻居集合,利用列表级排序学习方法训练出最优排序模型。仿真实验表明,与已有算法相比,TELSR在具有较高推荐精度的同时,还可有效抵抗恶意用户的攻击。
服务推荐;排序学习;概率型用户相似度;信任关系
1 引言
随着互联网的普及和云计算技术的迅猛发展,网络上提供的Web服务呈指数级增长。用户迫切地需要一种有效的服务推荐方法来解决其面临的选择困境。因此,服务推荐技术在服务计算领域获得了广泛的关注。Web服务的服务质量(QoS, quality of service)包括服务失效率、响应时间、成本、吞吐量等[1],是用户进行服务选取时需要考虑的重要属性之一。而由于Web服务广泛地分布在网络中,一些QoS属性如响应时间、吞吐量等经常受到网络环境动态变化的影响,具有很大的不确定性,这就造成了服务推荐可靠性差的问题。
为解决此问题,研究者们考虑将协同过滤算法应用到服务推荐过程中,通过预测QoS值并以此对服务进行排序来实现推荐[2]。为了提高QoS预测的准确性,研究者们对传统协同过滤算法做出了一系列改进,包括引入用户的信任网络[3]、服务调用模式[4]、服务的上下文信息[5]等。主要存在的问题为1) 没有有效利用服务的排序位置信息;2) 引入的信任网络中用户直接信任关系稀疏,难以提供足够的辅助信息。
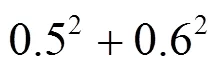
近几年来,有研究者考虑将排序学习技术引入推荐算法中来,通过直接优化最终的排序列表来提高推荐系统的准确性[6]。作为一种强监督性机器学习算法,排序学习能够整合大量复杂特征并自动学习最优参数,降低了考虑单个因素进行排序的风险,且能够通过多种方法来规避过拟合问题,获得了学术界越来越多的关注[7]。然而,目前很少有研究将传统协同过滤算法与排序学习技术结合起来,并应用到服务推荐领域。
针对上述问题,本文提出基于信任扩展和列表级排序学习的服务推荐方法(TELSR, trust expansion and listwise learning-to-rank based service recommendation method)。该方法首先在分析服务排序位置信息重要性的基础上,给出概率型用户相似度计算方法(PUSC, probabilistic user similarity computation method),提高相似度计算准确性;然后,提出信任扩展模型充分挖掘用户信任网络信息,并结合用户相似度构建可信邻居集合;最后,利用可信邻居集合改进列表级排序学习算法,通过训练得到最符合用户偏好的服务推荐列表。本文的主要贡献有以下3点。
1) 给出概率型用户相似度计算方法,有效利用了服务的排序位置信息,提高了相似度计算准确性。
2) 提出信任扩展模型,充分挖掘了用户信任关系,构建出可信邻居集合,能够抵抗恶意用户的攻击。
3) 改进列表级排序学习算法,可输出最符合用户兴趣偏好的服务推荐列表。
2 相关工作
协同过滤最早是由Goldberg等[8]在1992年提出的,后来被广泛应用于电子商务领域,并且取得了极大的成功。其核心思想是:在用户群中寻找与目标用户评分行为相似的邻居用户,然后基于这些邻居用户对服务的评分向目标用户做出推荐[9]。目前,已有很多学者将协同过滤算法应用到服务推荐过程中,并对其做出了一系列的改进。王海艳等[10]引入服务的推荐个性属性特征来改进传统的相似度计算式,并结合用户之间的信任关系对服务的评分值进行预测,进而对用户做出推荐。Liu等[11]利用服务的流行度特征改进相似度计算,并根据用户和服务的地理位置来缩小相似用户的寻找范围,相比传统推荐算法更加高效;Hu等[12]在寻找相似邻居时融入了服务调用的时间信息,并通过线性加权的方式综合了基于相似用户和相似服务的QoS预测结果。文献[10~12]均是通过改进相似度计算来提高算法准确性,属于基于近邻的协同过滤算法。此外,还有部分研究者利用数学模型来预测服务的QoS,并取得了较好的成果。Wei等[13]利用矩阵分解模型将高维的用户—服务矩阵分解为低维的用户矩阵和服务矩阵,并将位置属性融入矩阵分解的正则项中,有效提高了QoS预测精度;胡堰等[14]借助隐含类别表示用户指标偏好、用户及服务情境三者之间的依赖关系,并建立隐语义概率模型用于预测用户在特定服务情境下的个性化指标偏好,然后计算出每个候选服务的效用值进行推荐;Wang等[15]考虑到了QoS值在不同时间段的动态变化特性,对QoS预测值的残差进行零均值拉普拉斯先验分布假设,将QoS预测问题转化为Lasso回归问题进行求解。文献[13~15]有效利用了数学模型的精确性,属于基于模型的协同过滤算法。可见,上述工作的研究重点均集中在提高QoS值预测的准确性方面,而近年来有研究者发现QoS值预测的准确性并不能确保服务推荐的准确性,引言已给出相关示例。
排序学习作为一种强监督性机器学习算法,能够直接针对最终的推荐列表进行优化,这一特性可以避免根据QoS值排序来间接得到推荐列表带来的缺陷。根据优化目标的不同,排序学习主要分为3类:点级(pointwise)、对级(pairwise)、列表级(listwise)[7]。点级排序的处理对象是单独的一个项目,通过预测评分实现推荐,其相当于传统的预测QoS值的服务推荐方法;对级排序是根据评分来定义项目对之间的偏序关系,最终通过整合所有项目对的偏序关系得到整个排序列表,而其时间复杂度高,且在整合推荐列表时会损失一定的准确性;列表级排序的处理对象是所有的项目,直接对整个排序列表进行优化,在运行效率和推荐准确性方面具有更明显的优势,因此,成为被研究最多的方法。
Huang等[6]利用基于排列概率的相似度来寻找更准确的邻居用户,然后通过最小化目标用户和邻居用户在未评分项目集合上的交叉熵损失函数,来得到最优的排序列表。Weimer等[16]提出了一种最大化边界矩阵因式分解算法CoFiRank,通过直接优化排序评价标准NDCG来进行推荐。Shi等[17]提出一种基于上下文感知的推荐方法,利用张量分解优化MAP评测准则,是首个能够挖掘用户隐式反馈和上下文信息,并将列表级排序学习和协同过滤算法相结合的方法。但是列表级排序学习算法依然面临着用户恶意评分、数据稀疏性等传统难题,且目前还缺乏将该算法改进并应用到服务推荐领域的研究。
3 基于信任扩展和列表级排序学习的服务推存方法
本节给出基于信任扩展和列表级排序学习的服务推荐方法,该方法首先将用户表示为已调用服务集合的概率分布,基于Kullback-Leibler(KL)距离进行概率型用户相似度的计算,以此提高用户相似度计算的准确性;然后,利用信任扩展模型充分挖掘用户信任网络中的信任关系,并结合用户相似度构建为目标用户构建可信邻居集合,以此抵抗某些恶意用户的攻击;最后,利用可信邻居集合改进列表级排序学习算法,训练出最优的服务排序列表推荐给用户。其中,概率型用户相似度计算方法、可信邻居集合构建算法(TNSC, trusted neighbor set construction algorithm)以及列表级排序学习预测算法(PABL, prediction algorithm based on listwise learning-to-rank)为TELSR的核心,下面重点对它们进行介绍。
3.1 概率型用户相似度计算方法
协同过滤算法的核心步骤是寻找相似用户,可采用的方法主要有Pearson相关系数、余弦相似性、修正的余弦相似性等[10]。目前大多数服务推荐算法都是基于Pearson相关系数改进得来的,其基本定义如下。
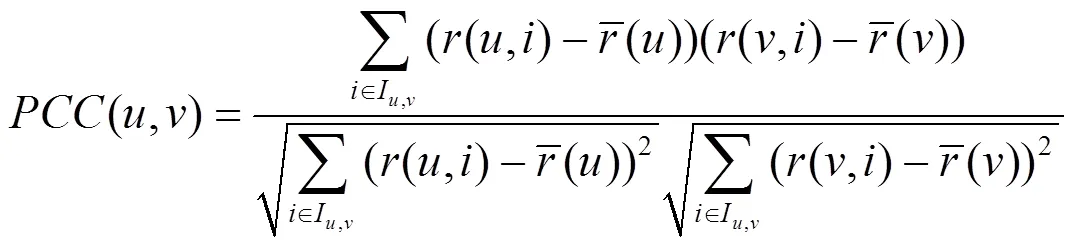
用户调用服务示例如图1所示,假设用户A、B、C共同调用过的服务集合为I={a,b,c,d},这4个服务的QoS(如可用性,用百分制表示)分别为A=(0, 20%, 80%, 100%), B=(10%, 0, 80%, 100%), C=(0, 22%, 100%, 89%),采用Pearson相关系数计算得,即用户B、用户C和用户A是同等相似的。从图1可以看出,如果根据服务可用性大小对服务进行排序,用户B对于服务a、b的排序与用户A是相反的,而用户C对于服务c、d的排序与用户A是相反的。此时,若利用用户B做推荐,则其向用户A推荐的最好服务是d,正好符合用户A的需求;若利用用户C做推荐,则其向用户A推荐的最好服务是c,违背用户A的需求。相比之下,用户B的推荐结果更加可信,所以理论上用户B与用户A的相似度应该更大。原因在于,在实际推荐系统中,用户主要关注排在推荐列表中前面质量较优的服务,对于排在后面质量较差(如可用性低于50%)的服务给予的关注较少。因此,服务的排序位置是除了QoS数据之外另一个能够反映用户兴趣偏好的重要信息。
基于此,本文充分挖掘服务的排序位置信息,借鉴Mollica等[18]提出的Plackett-Luce模型,将每个用户表示为已调用服务集合排列的概率分布,然后进行用户相似度的计算,从而找到更加准确的相似用户。为方便下文讨论,定义如下。
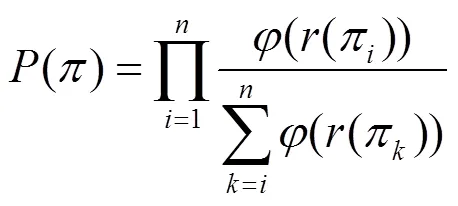

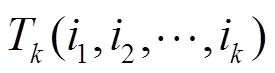
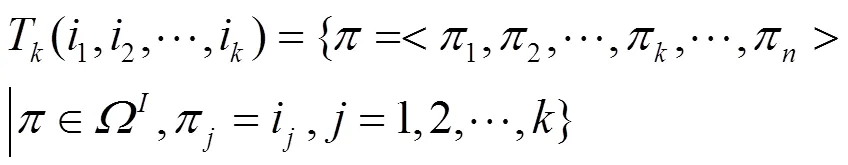
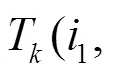
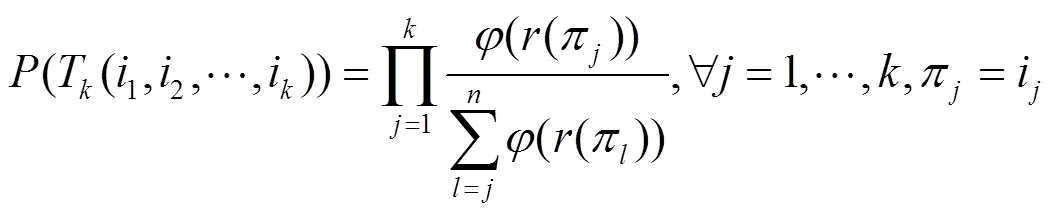
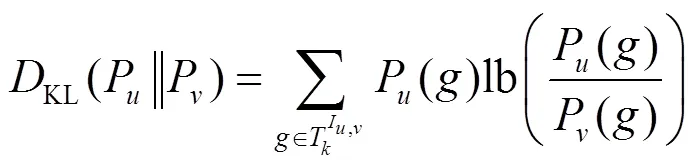
定义7 概率型用户相似度。用户和之间的概率型相似度可定义为
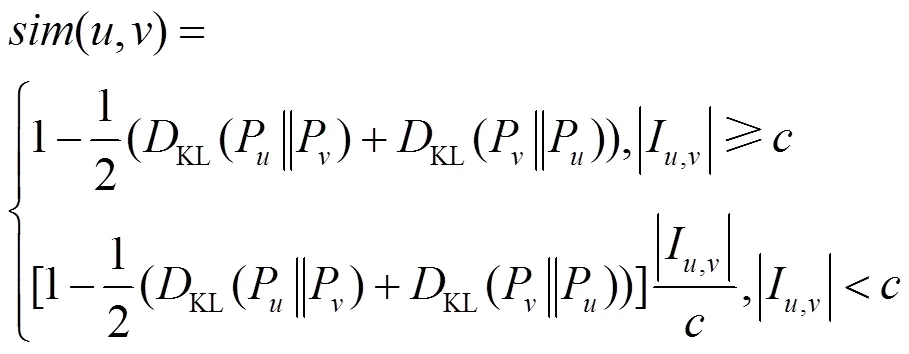
算法1 概率型用户相似度计算
begin
6) end for
end
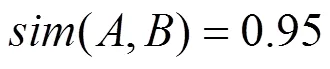
3.2 可信邻居集合构建算法
利用PUSC可计算其他用户与目标用户的相似度,然后选取出相似度较大的用户作为邻居进行推荐。但是当推荐系统中存在恶意用户对服务QoS值进行虚假评价时,此时,若把这类用户当作邻居,会极大影响推荐的精度。基于此,本文利用用户间的信任关系建立可信邻居集合来进行推荐,从而避免恶意用户的攻击。为了解决传统基于信任的服务推荐算法中信任关系稀疏性问题,本文提出信任扩展模型,同时考虑直接信任关系和间接信任关系。
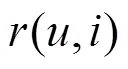
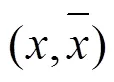
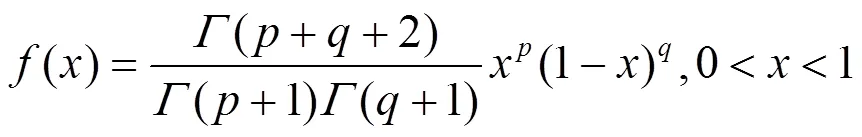
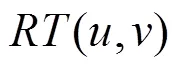
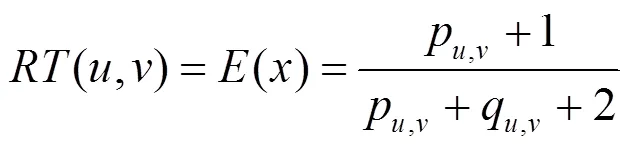
由式(8)可知,用户和之间的直接信任度与有效推荐行为次数成正比,因此,其可以甄别某些用户反常的恶意评价行为。然而,在实际推荐系统中,用户之间的相互交互记录往往较少,导致直接信任关系稀疏性问题。为此,本文利用信任关系的传递特性来扩大用户的信任范围,并给出如下定义。
间接信任传递关系如图2所示。由图2可知,用户和均与用户和之间存在直接信任关系,根据信任关系的传递性,可以通过用户和建立起用户和之间的间接信任关系。

图2 间接信任传递关系
定义11 间接信任度。若用户的直接信任集合为,利用中所有与用户有直接信任关系的用户来进行信任传递,则用户和之间的间接信任度为
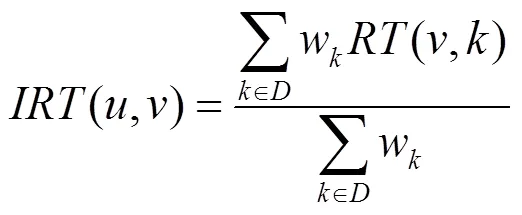
定义12 综合信任度。通过综合直接信任度和间接信任度,得到用户之间的综合信任度为
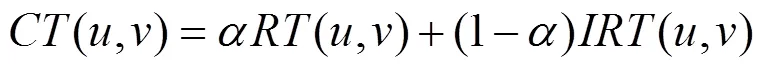
定义13 可信相似度。综合考虑用户和之间的概率相似度和综合信任度,得到用户和的可信相似度为
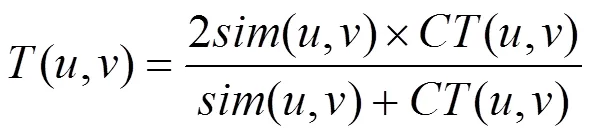
基于可信相似度的定义,本文提出可信邻居构建算法,如算法2所示。
算法2 可信邻居构建
输入 目标用户,其他用户集合,参数
输出 目标用户的可信邻居集合N
begin
7) end for
8)N←按照可信相似度由大到小对用户进行排序,选取前个用户作为目标用户的可信邻居集合
end
3.3 列表级排序学习预测算法
为了利用可信邻居集合来提高服务推荐的准确性,本文首先利用矩阵分解模型来预测服务的QoS值,然后利用列表级排序学习算法训练出最优的服务排序模型。为了方便描述,定义参数如下。
1) 参数定义
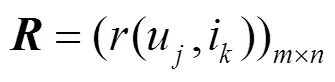
:用户服务评分矩阵,其中,m为用户的个数,n为服务的个数。
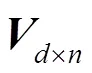
:维的服务隐含特征矩阵。
:隐含特征数。
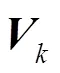
:矩阵V的第k列向量,代表服务的隐含特征向量。
2) 矩阵分解模型
矩阵分解模型是在协同过滤推荐算法中应用最为广泛的模型之一。其主要思想是将用户服务评分矩阵近似分解为低维的用户隐含特征矩阵和服务隐含特征矩阵,计算式为
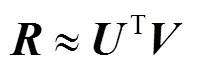
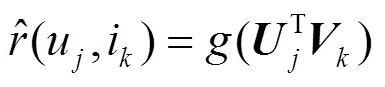
算法通过最小化预测评分矩阵和原评分矩阵的误差来实现QoS值的精确预测[21]。在现实生活中,人们对于一个服务的评价往往会受到所信任好友的影响。因此,为了提高服务推荐的准确性,本文在预测QoS值时加入可信邻居用户的影响,将式(13)改进为
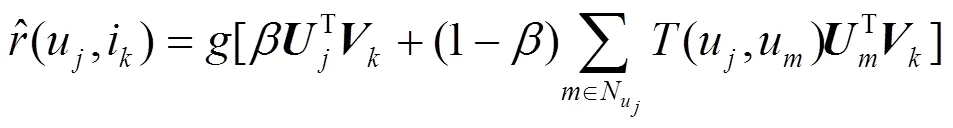
3) 列表级排序学习模型
列表级排序学习直接针对最终的排序列表进行优化,可以避免仅仅根据QoS值排序带来的不准确性。其核心思想是:将预测排序列表和正确排序列表之间的交叉熵作为损失函数,通过训练过程最小化其交叉熵,从而使最终得到的预测排序模型最接近正确排序模型[7]。本文基于top-1概率,将交叉熵损失函数定义如下。
定义14 top-1概率。服务在用户的推荐列表中排在第一位置的概率,定义为
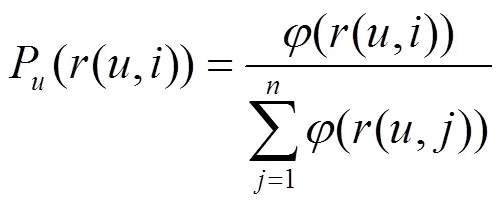
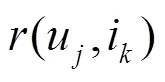
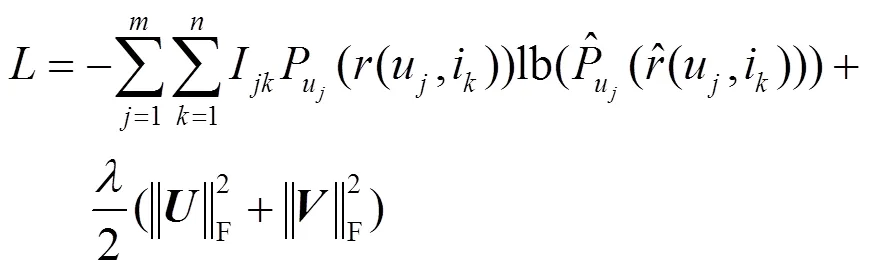
基于交叉熵损失函数的定义,给出列表级排序学习预测算法,具体如算法3所示。
算法3 列表级排序学习预测
输出 每一个用户的最佳服务推荐列表
begin
1) 根据训练数据集,利用式(15)计算得到正确排序列表的概率分布
2) 利用式(14)算出初始所有服务的QoS预测值
3) 利用式(15)算出初始预测排序列表的概率分布
4) 利用式(16)计算初始交叉熵损失函数
6) 更新用户隐含特征矩阵和服务隐含特征矩阵
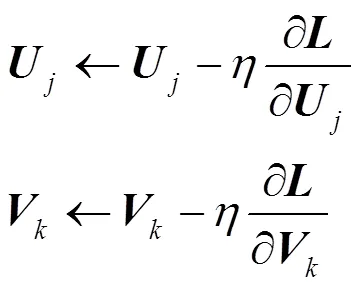
7) 记录上次交叉熵损失函数
8) 利用式(14)算出新的所有服务的QoS预测值
9) 利用式(15)算出新的预测排序列表的概率分布
13) end for
15) 将所有服务按照top-1概率由大到小进行排序,得到最佳服务排序列表,推荐给用户
16) end for
end

3.4 TELSR描述
经过上述分析,TELSR的具体过程如下。
1) 运用PUSC计算每一个用户与其他用户的概率型相似度。
2) 运用TNSC为每一个用户建立可信邻居集合。
3) 根据训练数据集得到用户服务评分矩阵,初始化用户隐含特征矩阵和服务隐含特征矩阵。
4) 运用PABL得到每一个用户的最佳服务推荐列表。
TELSR首先通过Plackett-Luce模型将用户表示为已调用服务集合的概率分布,并利用PUSC计算用户的概率型相似度,其优点在于利用了服务的排序位置信息,使相似度计算更加准确;为了消除推荐系统中恶意用户随意打分的影响,利用TNSC为用户建立可信邻居集合,其优点在于充分挖掘用户间的直接信任关系和间接信任关系,缓解了用户信任网络稀疏性问题;最终利用可信邻居集合改进QoS预测值的准确性,并利用列表级排序学习的强大数据处理能力,训练出最优的排序模型,为用户提供最符合其偏好的服务推荐列表。
3.5 算法时间复杂度
4 实验结果与分析
4.1 实验设置
本实验使用由Zheng等[22]收集并公共发布的WS-DREAM数据集,它是由分布在全球20多个国家的150个电脑节点收集的QoS信息,构成了约150万条QoS调用记录,其内容主要包括Web服务的往返响应时间RTT、数据块大小、响应结果等属性,表1展示了该数据集的部分服务实例信息。
本文选用往返响应时间RTT作为评价QoS的标准,当用户调用某服务超过100次时,计算出RTT的均值,最终得到一个150×100的用户服务矩阵。为了研究算法的推荐准确性,本文从原始的用户服务矩阵中随机地剔除部分QoS值,形成了5个不同的稀疏矩阵,其密度分别为0.04、0.08、0.12、0.16、0.20。之所以选择小密度矩阵,是因为在海量的Web服务环境中,用户只调用过很少的服务,因此,其真实的用户服务矩阵就是很稀疏的。
本文使用5重交叉验证作为实验方法,将稀疏矩阵随机分为5份,每次选择其中的4份即矩阵的80%作为训练集,选择余下的1份即矩阵的20%作为测试集。每次实验重复5次,取平均值得到最终的评估结果。由于本文认为用户更在意最终获得的服务推荐列表中服务排序的准确性,因此,采用NDCG(normalized discounted cumulative gain)作为衡量算法推荐性能的标准。NDCG值越大,表示算法的推荐性能越好[7]。
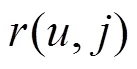
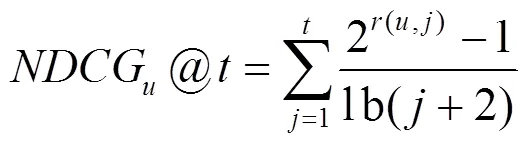
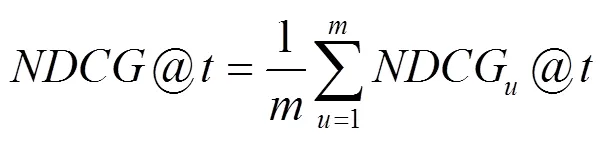
4.2 参数对算法性能的影响

表1 部分数据集信息
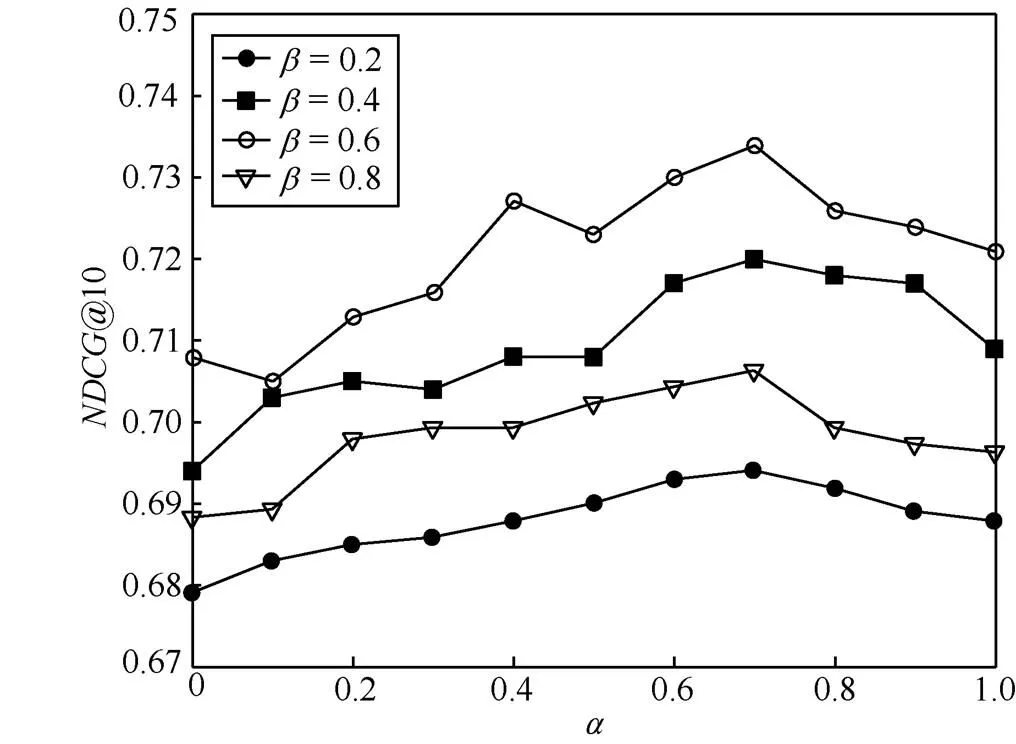
图3 参数对于推荐性能的影响
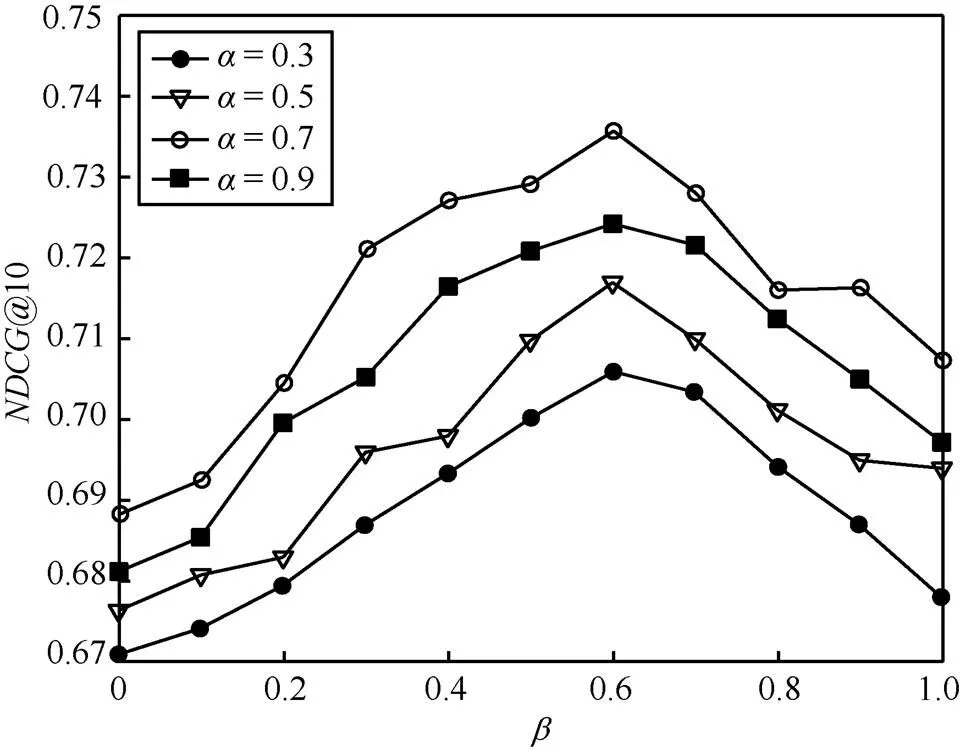
图4 参数对于推荐性能的影响
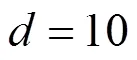
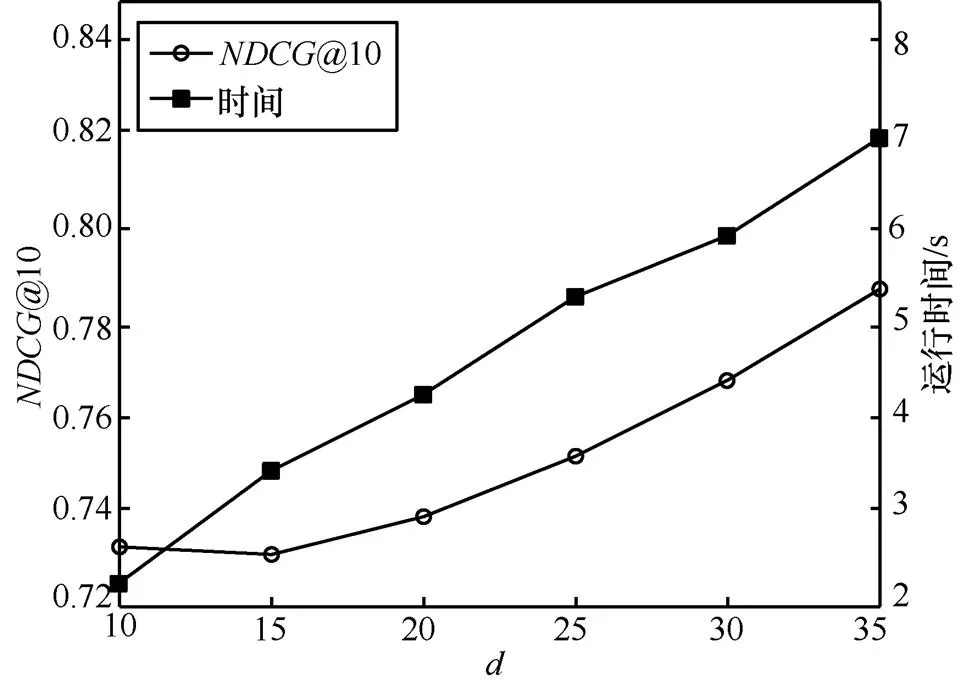
图5 隐含特征数d对于推荐性能的影响
4.3 算法运行时间的比较
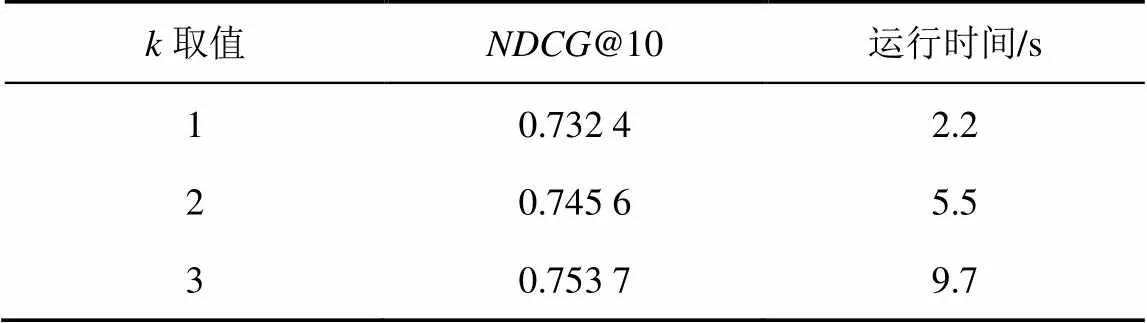
表2 k取值的影响
由表2可以看出,随着的取值不断增大,算法的推荐性能提高非常小,但是算法的运行时间却大幅增加。当=3时,算法的推荐性能@10比=1时提高了2.9%,但是运行时间增加了341%。而=1时,算法就可以在较短的运行时间内实现较好的推荐性能。因此,本文实验中均设置=1。
为了衡量算法的运行时间性能,将TELSR与以下4种经典的推荐算法做比较。
1) CF-DNC[23]
该算法首先利用“兴趣相似用户集选取算法”动态选取目标用户的相似邻居,然后提出“用户信任计算模型”,筛选出目标用户的可信邻居用户集,最后提出了一种新的协同过滤算法,综合利用可信邻居的评分信息,对服务的评分值进行预测。
2) TACF[12]
该算法有效融合了服务调用时间信息,提出“时间感知的相似度算法”,寻找更加准确的相似用户和相似服务,然后设计“个性化随机游走算法”来克服数据的稀疏性,最后利用混合协同过滤算法预测服务的QoS值。
3) listPMF[24]
该算法改进了概率矩阵分解模型,根据用户评分得到用户的偏好序列,并通过最大化预测的偏好序列和已知的偏好序列的后验概率来实现项目的推荐,属于基于列表级排序的协同过滤算法。
4) listCF[6]
该算法通过计算用户共同打分项目集合的Jansen-Shannon散度,来度量用户的相似度,并通过最小化目标用户和邻居用户的加权交叉熵损失函数来做预测,属于基于列表级排序的协同过滤算法。
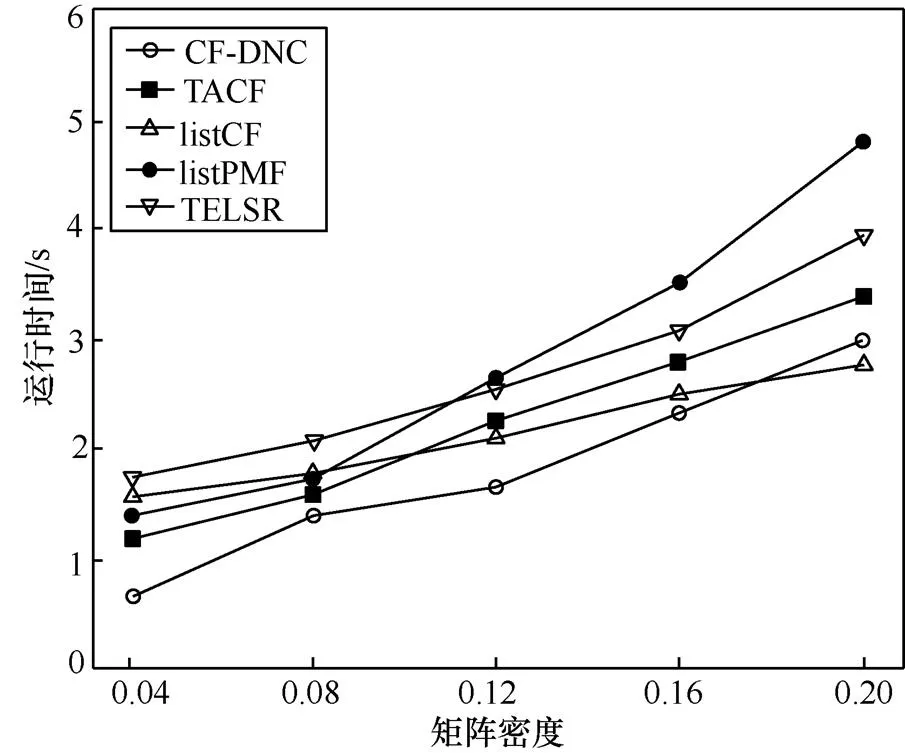
图6 不同算法运行时间的比较
由图6可以看出,随着矩阵密度的增加,本文提出的TELSR的运行时间比listPMF短,但是比CF-DNC、TACF和listCF稍长,具体原因如下。
1) listPMF基于用户和项目的隐含特征矩阵来预测用户的偏好序列。当矩阵密度增加时,需要预测的用户偏好序列数量增多,且随着隐含特征矩阵的不断更新,算法计算量成倍增长,导致listPMF的运行时间大幅度增加,甚至超过了TELSR。
2) CF-DNC和TACF均是在传统的Pearson相关系数的基础上改进的相似度计算方法,可以直接利用数据集中的QoS值。而TELSR采用PUSC,首先需要根据已有的QoS数据计算出用户调用服务的概率分布,才能进行下一步的相似度计算。
3)listCF选取出邻居用户之后,直接利用列表级排序算法进行QoS值预测。而TELSR还增加了用户信任度的计算,并结合用户相似度提出了可信邻居构建算法TNSC。
由于TELSR属于混合型算法,内容同时涉及用户相似度、信任度和QoS预测,因此,其计算量更大,但根据第3.5节和图6可知,随着矩阵密度的增加,其运行时间仍保持了线性增长的趋势,说明TELSR算法是可以应用在大型Web服务数据集上的。
4.4 推荐准确性的比较
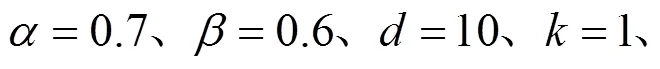
2) 在5种算法中,listCF和TELSR表现最为优异,它们均属于listwise CF,但是TELSR在listCF的相似度的基础上加入了信任度的计算,因此其推荐性能相对于listCF有所提升,且提升幅度随着矩阵密度的增加而增加。因为随着矩阵中已知QoS值的服务的增多,TELSR能够在用户之间发现更多的有效推荐行为,从而使其信任度计算更加准确,进一步提升了算法的推荐性能。
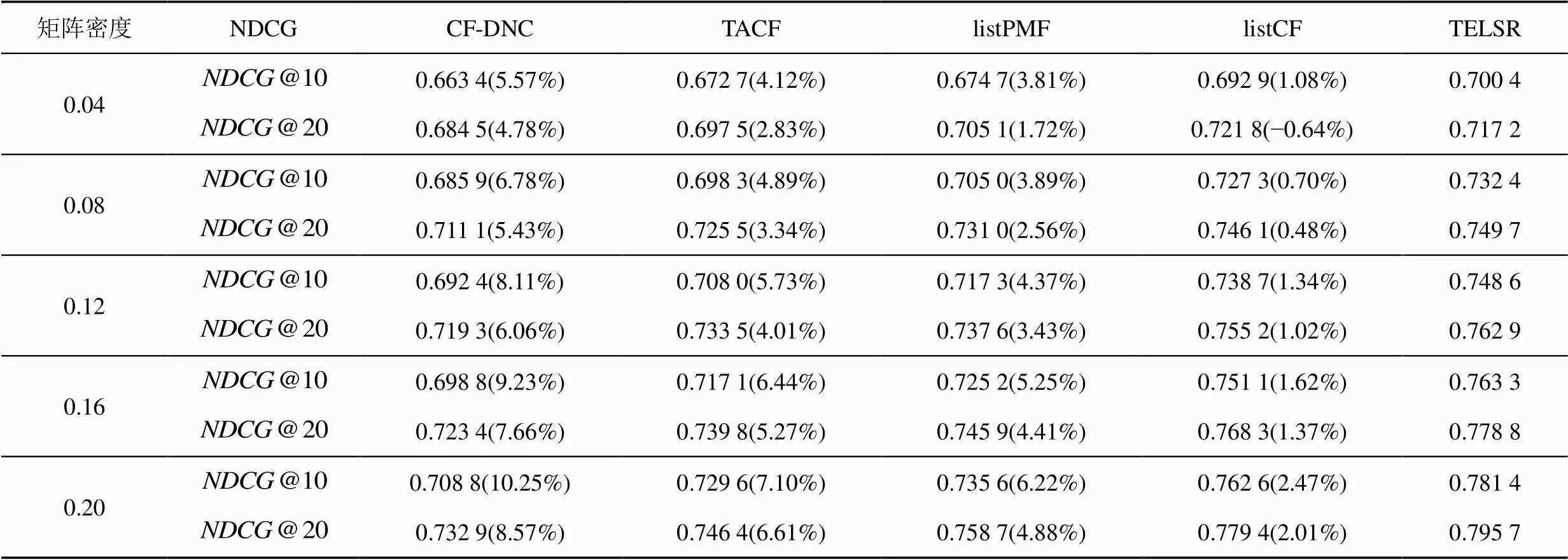
表3 推荐准确性比较
4.5 抵抗恶意用户能力的比较
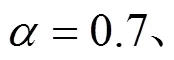
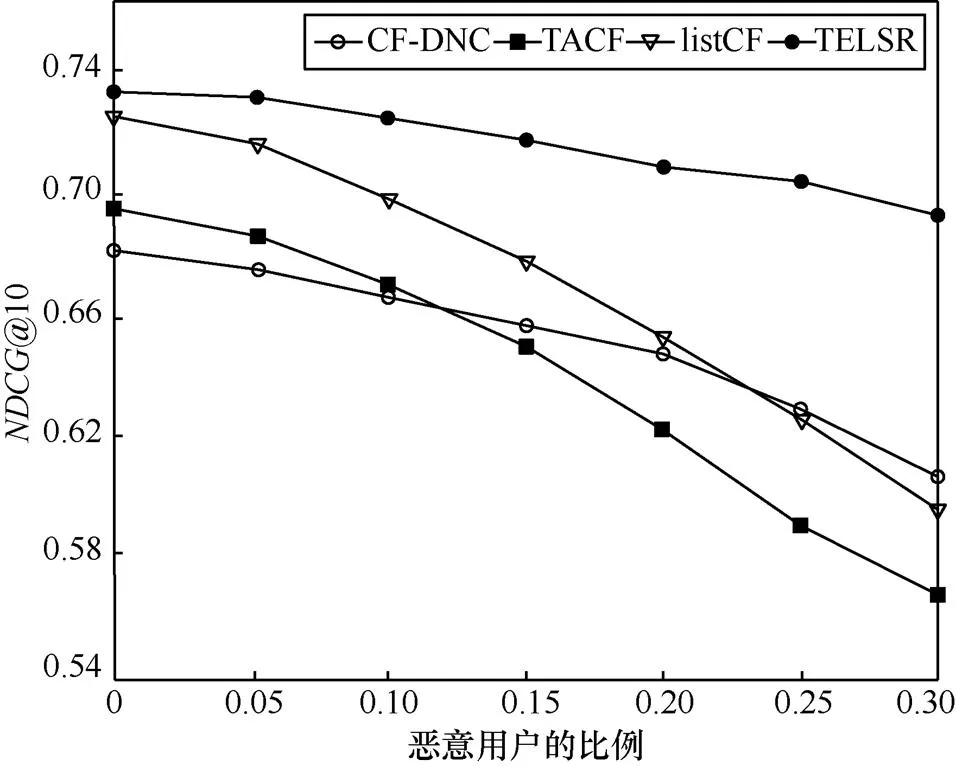
图7 抵抗恶意用户能力比较
由图7可知,随着恶意用户比例的增加,TACF和listCF的推荐性能下降很快,因为它们没有建立任何防御机制,一旦系统中的相似用户演变为恶意用户,算法的准确性会受到很大的影响;而CF-DNC考虑到了用户的信任关系,具备一定的抗攻击能力,但是其在计算相似度时没有考虑服务的排序位置信息,所以导致推荐精度不够高;TELSR利用概率分布模型计算用户相似度,并结合用户的信任关系进行服务推荐,在具备较高推荐精度的同时,还能够较好地抵抗恶意用户的攻击。
5 结束语
本文针对传统服务推荐算法中仅依据QoS预测值排序带来的不准确性以及用户信任关系稀疏性问题,提出基于信任扩展和列表级排序学习的服务推荐方法。该方法首先在分析服务排序位置信息重要性的基础上,给出概率型用户相似度计算方法,提高了用户相似度计算的准确性;然后,利用信任扩展模型充分挖掘用户之间的信任关系,并给出可信邻居构建算法,以抵抗某些恶意用户的攻击;最后,利用可信邻居集合改进矩阵分解模型,并给出列表级排序学习预测算法,为用户训练出最优的服务排序模型。实验证明,TELSR具有较高的推荐精度,并且可以应用到大型的Web服务数据集上。下一步工作将优化用户信任模型,并考虑QoS值的时间效应,进一步增强推荐模型在动态环境中的适用性。
[1] 李玲, 刘敏, 成国庆. 一种基于FAHP的多维QoS的局部最优服务选择模型[J]. 计算机学报, 2015, 38(10): 1997-2010.
LI L, LIU M, CHENG G Q. A local optimal model of service selection of multi-QoS based on FAHP[J]. Chinese Journal of Computers, 2015, 38(10): 1997-2010.
[2] MA Y, WANG S G, YANG F C, et al. Predicting QoS values via multi-dimensional QoS data for Web service recommendations[C]//IEEE Conference on Web Services. 2015: 249-256.
[3] LIU Z, MA J, JIANG Z, et al. IRLT: integrating reputation and local trust for trustworthy service recommendation in service-oriented social networks[J]. Plos One, 2016, 11(3):e0151438.
[4] 张莉, 张斌, 黄利萍, 等. 基于服务调用特征模式的个性化Web服务QoS预测方法[J]. 计算机研究与发展, 2013, 50(5):1066-1075.
ZHANG L, ZHANG B, HUANG L P, et al. A personalized Web service quality prediction approach based on invoked feature model[J]. Journal of Computer Research and Development, 2013, 50(5): 1066-1075.
[5] QI L, DOU W, ZHOU Y, et al. A context-aware service evaluation approach over big data for cloud applications[J]. IEEE Transactions on Cloud Computing, 2015, PP (99): 1.
[6] HUANG S S, WANG S Q, LIU T Y, et al. Listwise collaborative filtering[C]//The 38th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 2015: 343-352.
[7] 黄震华, 张佳雯, 田春岐. 基于排序学习的推荐算法研究综述[J]. 软件学报, 2016, 27(3): 691-713.
HUANG Z H, ZHANG J W, TIAN C Q. Survey on learning-to-rank based recommendation algorithms[J]. Journal of Software, 2016, 27(3): 691-713.
[8] GOLDBERG D. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61-70.
[9] PARK C, KIM D, OH J, et al. TRecSo: enhancing top-recommendation with social information[C]//International Conference Companion on World Wide Web, International World Wide Web Conferences Steering Committee. 2016: 89-90.
[10] 王海艳, 杨文彬, 王随昌. 基于可信联盟的服务推荐方法[J]. 计算机学报, 2014, 37(2): 301-311.
WANG H Y, YANG W B, WANG S C. A service recommendation method based on trustworthy community[J]. Chinese Journal of Computers, 2014, 37(2): 301-311.
[11] LIU J, TANG M, ZHENG Z, et al. Location-aware and personalized collaborative filtering for Web service recommendation[J]. IEEE Transactions on Services Computing, 2015, 9 (5): 686-699.
[12] HU Y, PENG Q, HU X. A time-aware and data sparsity tolerant approach for Web service recommendation[C]//IEEE International Conference on Web Services. 2014: 33-40.
[13] WEI L, YIN J, DENG S, et al. Collaborative Web service QoS prediction with location-based regularization[C]//IEEE International Conference on Web Services. 2012: 464-471.
[14] 胡堰, 彭启民, 胡晓惠. 一种基于隐语义概率模型的个性化Web服务推荐方法[J]. 计算机研究与发展, 2014, 51(8): 1781-1793.
HU Y, PENG Q M, HU X H. A personalized Web service recommendation method based on latent semantic probabilistic model[J]. Journal of Computer Research and Development, 2014, 51(8): 1781-1793.
[15] WANG X Y, ZHU J K, ZHENG Z B, et al. A spatial-temporal QoS prediction approach for time-aware Web service recommendation[J]. ACM Transactions on the Web, 2016, 10(1): 1-25.
[16] WEIMER M, KARATZOGLOU A, LE Q V, et al. Cofirank maximum margin matrix factorization for collaborative ranking[C]//The 21th Int’l Conference on Neural Information Processing Systems. 2007: 1-8.
[17] SHI Y, KARATZOGLOU A, BALTRUNAS L, et al. TFMAP: optimizing MAP for top-context-aware recommendation[C]//ACM Special Interest Group on Information Retrieval. 2012: 155-164.
[18] MOLLICA C, TARDELLA L. Bayesian mixture of Plackett-Luce models for partially ranked data[J]. Statistics, 2015, 2(4): 208-222.
[19] CAO Z, QIN T, LIU T Y, et al. Learning to rank: from pairwise approach to listwise approach[C]//The 2007 ACM conference on Machine learning. 2007: 129-136.
[20] FANG W, ZHANG C, SHI Z, et al. BTRES: beta-based trust and reputation evaluation system for wireless sensor networks[J]. Journal of Network & Computer Applications, 2015(59): 88-94.
[21] 郭弘毅, 刘功申, 苏波, 等. 融合社区结构和兴趣聚类的协同过滤推荐算法[J]. 计算机研究与发展, 2016, 53(8): 1664-1672.
GUO H Y, LIU G S, SU B, et al. Collaborative filtering recommendation algorithm combining community structure and interest clusters[J]. Journal of Computer Research and Development, 2016, 53(8): 1664-1672.
[22] ZHENG Z B, ZHANG Y L, LYU M R. Distributed QoS evaluation for real-world Web services[C]//The 8th International Conference on Web Services. 2010: 83-90.
[23] 贾冬艳, 张付志. 基于双重邻居选取策略的协同过滤推荐算法[J]. 计算机研究与发展, 2013, 50(5): 1076-1084.
JIA D Y, ZHANG F Z. A collaborative filtering recommendation algorithm based on double neighbor choosing strategy[J]. Journal of Computer Research and Development, 2013, 50(5): 1076-1084.
[24] LIU J, WU C, XIONG Y, et al. List-wise probabilistic matrix factorization for recommendation[J]. Information Sciences, 2014(278): 434-447.
Trust expansion and listwise learning-to-rank based service recommendation method
FANG Chen1,2, ZHANG Hengwei1,2, ZHANG Ming1,2, WANG Jindong1,2
1. The Third College, Information Engineering University, Zhengzhou 450001, China 2. State Key Laboratory of Mathematical Engineering and Advanced Computing, Zhengzhou 450001, China
In view of the problem of trust relationship in traditional trust-based service recommendation algorithm, and the inaccuracy of service recommendation list obtained by sorting the predicted QoS, a trust expansion and listwise learning-to-rank based service recommendation method (TELSR) was proposed. The probabilistic user similarity computation method was proposed after analyzing the importance of service sorting information, in order to further improve the accuracy of similarity computation. The trust expansion model was presented to solve the sparseness of trust relationship, and then the trusted neighbor set construction algorithm was proposed by combining with the user similarity. Based on the trusted neighbor set, the listwise learning-to-rank algorithm was proposed to train an optimal ranking model. Simulation experiments show that TELSR not only has high recommendation accuracy, but also can resist attacks from malicious users.
service recommendation, learning-to-rank, probabilistic user similarity, trust relationship
TP393
A
10.11959/j.issn.1000-436x.2018007
方晨(1993-),男,安徽宿松人,信息工程大学硕士生,主要研究方向为服务推荐、数据挖掘等。

张恒巍(1978-),男,河南洛阳人,博士,信息工程大学副教授,主要研究方向为网络安全与攻防对抗、信息安全风险评估。
张铭(1993-),男,河南安阳人,信息工程大学硕士生,主要研究方向为云资源调度。

王晋东(1966-),男,山西洪洞人,信息工程大学教授,主要研究方向为网络与信息安全、云资源管理。
2017-04-05;
2017-12-26
张恒巍,13083710760@163.com
国家自然科学基金资助项目(No.61303074, No.61309013);河南省科技攻关计划基金资助项目(No.12210231003)
: The National Natural Science Foundation of China (No.61303074, No.61309013), Henan Science and Technology Research Project (No.12210231003)
