基于特征向量的物联网大数据压缩算法*
2018-03-13郭雷勇
郭雷勇
0 引 言
目前,无线射频技术已经广泛应用于仓储管理、供应链管理、医疗、图书管理中。然而,这些过程中将会产生庞大的数据集。通过深入挖掘研究这些数据集,可以从中发现一些业务趋势变化,有利于加深理解并改善商业流程。如果在使用这些数据前对其进行预处理(如先对其压缩),将会更有效地深入挖掘。本文以设计无线射频物流仓储中间件项目的过程为例进行分析。
1 无线射频特征选取及数据压缩
如何确定特征向量表示一个标签在读取过程中的性质,在目前的研究领域缺乏统一认识。不同的应用选取的特性对结果影响很大。因此,对无线射频数据进行分析检测前,需要找到最能体现标签读取过程的特征。此外,原始标签数据集中包含多条重复记录,数据规模达到成百吉字节,甚至达到太字节,处理压力非常大。为了提高数据的处理效率,分析前一般都需要对无线射频数据进行预处理[1]。
在无线射频的生命周期中,通过对业务流程进行梳理,发现很多物品往往都是一整批运输的。在供应链中,越往上游,货物量越大,数据越集中,而下游阶段的数据则呈现分散趋势。在无线射频数据集中,很多货物的地点(Location)、时间(Time)属性是一致的,即这些货物以同样的时间进入同样的地点,最后再一起离开该地点。
另外,由于无线射频技术对环境的敏感性,在考虑标签在整个供应链的生命周期中,各地的仓库环境、阅读器的厂商等因素差异,其阅读器的位置、摆放角度等不同,都可能影响无线射频数据读取的特性。因此,基于全局数据的无线射频孤立点所受影响太多,准确性将大大降低,且难以准确表示孤立点的本质,不具有实际应用的意义。另外,如果直接对全局数据集进行孤立点挖掘,数据量庞大,也无法提供实时的数据挖掘[2-3]。借鉴文献[4-5]数据立方的思想,本文希望可以对海量数据根据某种特性进行压缩,以更快的方式检测其中的有效数据,以更准确地挖掘出孤立点所象征的意义,同时大大减少数据计算的规模。
本文对数据进行压缩,根据无线射频的业务时间段进行操作,只记录标签首次读取的时间Time_in、最后离开的时间Time_out以及在这段时间内的读取次数。通过这种方式减少了大量的重复数据,而又保证信息不丢失。标签的读取强度是一个能体现标签读取过程的特征,本文用SS表示,其取值范围为(0~100)。SS值越大,表明信号越强。由于无线射频技术本身的内在敏感性,信号强度往往与货物的性质(金属非金属、液体等)、标签所贴的商品位置及与阅读器所处的位置相关。越贴近阅读器,信号越强;而与阅读器距离越远,信号越弱。
2 算法思路
基于以上原因,本文提出按照每个标签的读取的实际间隔Time_duration、在该段时间内读取次数tagCnt以及标签读取时的平均信号强度SSavg作为无线射频标签的特征。本文以三元组<Time_duration,tagCnt,SSavg>代表标签在读取过程中的特征向量空间,其中读取时间间隔Time_duration=Time_in-Time_out,标签在读取过程中的平均信号强度为SSavg:

特征选取如图1所示。
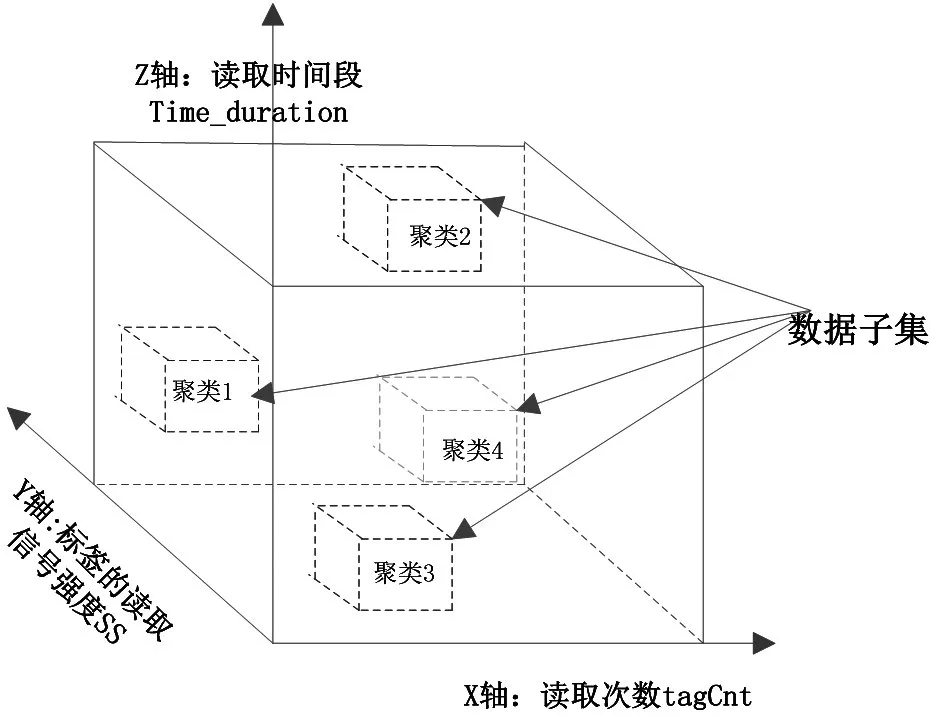
图1 数据集选取
tagCnt表示该段时间内标签的读取次数,SSi表示第i次读取的信号强度。
通过数据按照上述特征过滤压缩后,形成X={x1,x2…xn-1,xn}数据集,其中x代表一个标签。下面将具体讲述如何对原始标签数据进行压缩。
具体方法如下:
(1)假设在无线射频中间件获取的标签数据流均以四元组方式存在 < EPC,L ocation,T ime,SS>,其原始标签记录如下:

(2)给定阅读器的位置信息Location,根据业务时段,选取间隔的起始时间T_Start和结束时间T_End。根据三个特性对数据进行过滤,即只有满足阅读器位置信息Location一致,读取时间T_Start≤Time≤T_End的标签记录才会被聚合到同以个集合中。因此,会形成多个数据集聚类Cluster。经过聚集分类并压缩后的数据集,可以以四元组 < EPC,T ime _ Duration,t a gCnt,S Savg> 形式表示每个标签的压缩结果。聚类后的标签数据集如表1所示。

表1 聚集分类后的标签数据集
至此,通过对标签数据的压缩处理,大大减少了数据处理的规模。对于每个标签ID,均可用<Time_duration,tagCnt,SSavg>三元组表征标签读取过程的特征。每个聚类作为一个局部数据集,单独进行孤立点的数据挖掘。
3 算法实现
下面将具体介绍海里无线射频数据压缩算法的实现流程和伪代码。
首先给出数据压缩处理的算法实现,数据均以<EPC,Location,Time,SS>的形式存在。根据给定的Location、起始时间T_Start和结束时间T_End 3个属性,将数据聚类处理。最后,按照<EPC,Time_duration,tagCnt,SSavg>格式输出数据集。
算法实现流程,如图2所示。根据标签三元组进行聚类,为每个聚类单独创建哈希表,然后获取标签记录,再判断原始数据是否读取完成;如果数据读取完成,则将每个哈希表作为一个聚类输出,作为检测的数据集;否则,继续读取下一条数据。读取数据后需要判断在哈希表是否已有该数据,如果已经存在,只需要记录读取次数和时间;否则,不仅需要记录读取次数和时间,还需要把新的数据插入到哈希表。

图2 无线射频数据压缩算法流程
下面给出数据压缩算法的伪代码实现:
输入:原始数据集RawDataSet(EPC, Location,Time,SS),设定的阅读器Location,有效的读取的时间间隔Time_Start和Time_End
输出:经过数据压缩后cleanDataSet(EPC,Time_duration,tagCnt,SSavg)
方法:
//用哈希表储存每个标签数据TagNode的记录
Table←Empty HashTable;
for each item in Raw DataSet
if(item.Location!=Location||item.currentTime<Time_Start||item.currentTime>Time_End)//如果标签的数据流
//不在指定的位置及有效时间间隔内,则丢弃
drop item;
continue;
endif
if item.epc exists in HashTable
then//更新标签的平均信号强度
HashTable[epc].SS=(HashTable[epc].
tagCnt*SS+item.SS)/tagCnt+1
HashTable[epc].tagCnt+= 1;
HashTable[epc].tLastRead=
item.currentTime;
else//首次读到标签TagNode.epc=item.epc;TagNode.tFirstRead=TagNode.tLastRead=item.currentTime;
TagNode.tagCnt=1;
Add TagNode to HashTable
endif
endfor
for each Record in Table//将哈希表中的每条记录输出
Time_duration=Record.tLastRead-Record.tfirstRead;
Add (EPC, Time_Duration, tagCnt,SSavg) to Clean DataSet;
endfor
4 实验仿真与分析
针对本文设计的压缩算法,特设计如下实验。主要的实验工具是Visual Studio 2005与Matlab 7.70。
4.1 实验数据集来源
本实验压缩实验的数据集是按照<EPC,Location,Time,SS>四元组生成的数据集,其中EPC、Location两个属性按照均匀分布生成数据,标签到达时间Time服从泊松分布,平均读写强度则按照均值μ=0.75、方差σ=0.05的高斯分布生成数据。按照一定的比例,重复生成该数据。
4.2 数据集压缩实验
本实验按照500、1 000、5 000、20 000、50 000、100 000生成6组原始的无线射频数据集,得到数据压缩前后的数据对比,如表2、图3所示。

表2 原始数据集与压缩后数据对比
从表3、图3的实验结果来看,当原始数据集数据规模较小时,数据的压缩效果并不明显;当数据规模不断增大时,压缩效果开始显现;当数据到达100 000时,大概可获得5倍的压缩率。从实验结果来看,本算法对海量无线射频数据的压缩处理是有效的,符合预想结果。另外,需要注意的是,本算法的数据集使用随机函数生成,所以实际的压缩效果取决于重复数据的个数。经过反复测试,它的压缩效果仍然比较理想。
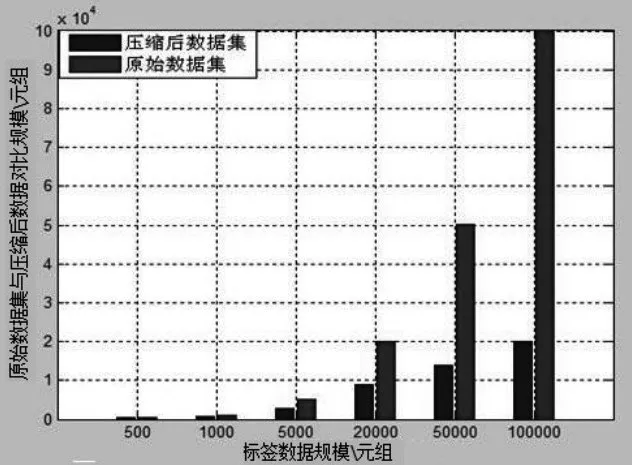
图3 在不同数据规模下数据集的压缩效果
5 结 语
本文主要讨论在海量无线射频数据中挖掘孤立点的难点及意义,针对海量的标签数据,按照标签的位置信息、读取时间进行数据聚类,大大减少了数据处理量;通过对无线射频数据读取过程特性的研究,提出了以标签在读写时间段、在该段时间内的读写次数以及标签平均读取信号强度作为标签的特征向量。仿真结果与算法分析表明,随着数据量的增加,提出的压缩算法的压缩效果越来越好。
[1] Yunsik S,MyoungHwan J,Yong-W,et al.Tag Localization in a Two-dimensional RFID Tag Matrix[J].Future Generation Computer Systems,2017,76(11):384-390.
[2] PENG Zi-ran,WANG Guo-jun,JIANG Hua-bin,et al.Research and Improvement of ECG Compression Algorithm Based on EZW[J].Computer Methods and Programs in Biomedicine,2017,145(07):157-166.
[3] Seyed N A,Suriyaprakash N, Shobha V.A Novel Test Compression Algorithm for Analog Circuits to Decrease Production Costs[J].Integration,the VLSI Journal,2017,58(06):538-548.
[4] HAN Jia-wei,Hector G.Warehousing and Mining Massive RFID Data Sets[C].ADMA,2006:1-18.
[5] Arun K B,Mamata J,Sri K K.Warehouse Efficiency Improvement Using RFID in a Humanitarian Supply Chain:Implications for Indian Food Security System[J].Transportation Research Part E: Logistics and Transportation Review,2018,109(01):205-224.
