一种基于嵌入式实时操作系统Vxworks下的数据压缩技术
2017-05-17王江泉张小研
王江泉++张小研


摘要:嵌入式实时操作系统Vxworks本身的数据压缩技术与其它主流操作系统不能够相互兼容,本文针对Vxworks提出了一种新的数据压缩技术,并且详细描述了数据压缩技术算法的数据模型及其实现方法,对研究其他压缩技术提供了思路和研究方法。
关键词:Vxworks;数据压缩技术;压缩算法
中图分类号:TP316 文献标识码:A 文章编号:1007-9416(2017)03-0070-02
1 引言
随着现代信息技术的快速进步,特别是计算机技术的高速发展,计算机存储技术面对诸多困难和挑战。数据压缩技术是在保证信息完整性的前提下,通过数据量的缩减达到存储空间减少的或按照某种算法重新组织原始数据,减少数据冗余、提高其传输存储和处理效率的一种技术方法。
Vxworks是美国风河公司研制的一种具备发展能力强、性能极其优越及人机交互友好的嵌入式实时操作系统(RTOS),在RTOS领域中起到重要的引导作用,Vxworks以高可靠性、高精度计时和优良的实时性在载人航天、卫星通讯、军事工业等高精端领域得到广泛的应用及推广。
Vworks本身自带的数据压缩技术只能在Vxworks自身操作系统使用,与其他平台不能够相互兼容,存在局限性,而主流平台的常用压缩软件在Vxworks下因平台属性不同又不能兼容。本文所描述的数据压缩技术为无损压缩,主要用于存储数据库记录或处理文本文件,且能够跨平台使用,支持Vxworks与其他主流操作系统之间相互应用。
2 数据压缩原理
数据压缩技术作为一种非常重要的的计算机技术[1],会在很多场景下得到应用,比如计算机文件系统、数据库的应用、大数据量信息的传输、多媒体移动通信系统等。压缩可以分为无损压缩和有损压缩,有损,指的是压缩之后就无法完整还原原始信息,但是压缩率可以很高,主要应用于视频、话音等数据的压缩,因为损失了一点信息,人是很难察觉的;无损压缩则用于文件或者信息等重要信息必须完整复原的场合。
数据压缩技术是以信息论作为基础理论发展起来的一种技术。如果以信息论的观点看数据压缩技术,压缩把信息中冗余的部分信息去除,即去除掉可以确定的信息或者可推算得到的信息,而保留信息中非常不确定的信息,即用一种非常靠近信息本质的描述来代替原有信息中的冗余描述,这个实质的描述就是信息论中的信息量,而整个过程就是数据压缩技术。
数据压缩技术的核心思想就是利用数据的重复结构信息来进行数据压缩[2]。举个简单的例子,比如一段字符串“取之以仁义,守之以仁义者,周也。取之以诈力,守之以诈力者,秦也。”,如果不使用压缩,采用Unicode编码共计32个字符64个字节。如果使用数据压缩,其中字符“取之以”、“仁义”、“,”,、“者”、“守之以”、“也”、“诈力”、“。”均重复出现过,只需指出其之前出现的位置,便可表示整段字符串。
3 数据压缩算法
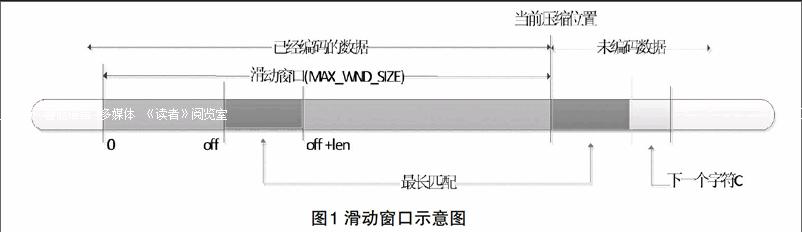
本压缩技术所采取的的压缩算法是一种基于字典、“滑动窗口”的无损压缩模型算法,包含一个码表字典、一个动态滑动窗口和一个预读缓冲器。
码表作为压缩使用的字典,采用最优二叉树进行编码,动态窗口是个历史缓冲器,它被用来存放输入流前字节的有关信息,与动态窗口相匹配的是预读缓冲器,它被用来存储当前输入流的字节信息。
数据信息首先存储于预读缓冲器,通过之前的滑动窗口与当前预读缓冲器中的信息进行匹配,查找两者最匹配的数据。如果匹配上的数据中,数据匹配长度大于最小预定匹配长度,就会输出一对数组数据,含距离 (distance),长度(length)等信息。其中距离(distance)表示在当前的输入流中重复的字符在之前滑动窗口中能够相匹配的字节数据位置,而长度(length)是指能够匹配的数据长度。如果匹配的信息数据长度小于最小预定匹配长度,输出当前字节,对数据信息不做改动。滑动窗口示意图如图1所示。
数据压缩算法流程为:
(1)从当前需要压缩的起点位置开始,匹配未进行编码的数据,并尽量在当前的滑动窗口中查找最长的字符匹配数据,如果能够找到,则执行步骤 2 ,否则执行步骤 3。
(2)输出三元参数数组( off,len,c )。其中 off 为当前预读缓冲器中匹配的数据相对滑动窗口边界的偏移量,len为两者所能够匹配的长度,c 为下一个即将匹配的字符,即不匹配数据的第一个字符。然后滑动窗口向后移动 len+1 个字节,继续执行步骤 1。
(3)针对不匹配的数据,输出三元参数数组( 0,0,c )。其中 c 为不能够匹配字符。然后对滑动窗口进行一个字符的滑动,继续执行步骤 1。
4 算法实现
4.1 三元参数数组设计
针对三元参数数组的第一个参数——相对滑动窗口的偏移(off),依据概率理论计算,匹配数据接近滑动窗口尾部的概率要大于接近滑动窗口头部的概率,所以字符串在滑動窗口的边界位置比较容易找到相同的匹配串,但对于通常情况下大小固定的的窗口(例如 4096 字节大小的窗口),偏移值一般情况下为均匀分布,可以通过固定的字节位数进行描述。编码 off的位数计算为MaxNum = upper_bound( log2( MAX_NumCount))。因此,用 12 位字节数就可以对大小为 4096的滑动窗口进行偏移编码。在数据进行压缩前,滑动窗口字节数并没有达到 最大值,而是随着压缩过程的不断进行而增长, 因此偏移字节计算所需要的位数可以通过窗口的当前大小动态进行编码。
为了尽量对数据进行压缩,可以对窗口内的偏移(off) 采用可变字长编码方式,本算法采用哈夫曼编码(Huffman Coding)对off重新编码,统计每个符号的出现次数。依据每种符号所统计的出现次数,建立标准的Huffman 树,获得每种符号根据Huffman树所得到的编码,形成码表字典。对于字符出现次数较多的情况,可以用较少的编码实现,对于字符出现次数很少的,用较多的编码进行实现。
针对三元参数数组的第二个参数——所匹配字符串得长度(len),它在一般情况下不会太大,只有在极少数情况下才会出现较大的长度,因此,应该采用一种变长的编码技术对长度值进行编码,此编码还必须为前缀编码[3]。
本算法中编码为Golomb 编码,比如对整数长度x采用 Golomb 编码,参数变量选择为 p,则:
a = 2p;
j = ((x - 1)/a);
y = x - ja – 1;
通过计算可知长度x的编码由两部分组成,其中前部分是由 j 个 1 和 1 个 0 组成,后半部分为p位的字节组成,其值等于 y,当参数p 为0、1、2、3时的 Golomb 编码表如下:
值 x p = 0 p = 1 p = 2 p = 3
------------------------------------------------------------------------------------------------------------
1 0 0 0 0 00 0 000
2 10 0 1 0 01 0 001
3 110 10 0 0 10 0 010
4 1110 10 1 0 11 0 011
5 11110 110 0 10 00 0 100
6 111110 110 1 10 01 0 101
7 1111110 1110 0 10 10 0 110
8 11111110 1110 1 10 11 0 111
9 111111110 11110 0 110 00 10 000
算法中所采用的Golomb 编码不仅仅符合前缀编码的要求,而且数值比较小的x值可以用较少的位编码,数值较大的x值用较长的位编码。如果x的取值范围为比较小的数时,Golomb 编码就能够对空间进行有效的节省,编码参数 p 的值,根据经验一般为3或者4。
针对三元参数数组的第三个参数——不能够匹配的字节c,因为该字符的概率为随机数,只能采用标准的8位进行编码,可以直接输出该字符。
4.2 查找匹配串
本压缩算法的核心内容是在滑动窗口中寻找最长的匹配字节串,每一次滑动窗口移动之后,都要在滑动窗口中查找下一个匹配串,如果匹配算法的时间效率高于O(n2),那么总的算法效率将高达 O(n3),这在实际应用中是无法接受的。
本压缩算法主要通过在滑动窗口中控制能够匹配字符串的最大长度(比如24个字节)方法,将滑动窗口中每个24字节串单独抽取出来,按照一定的大小顺序形成二叉有序树,在组织的二叉有序树中对字符串进行匹配,可以有效提高效率。
4.3 数据的解压缩
因为数据压缩时需要做大量的字符匹配工作,而解压缩时所需要做很少的工作。因此数据解压缩的整个过程很简单,只要对滑动窗口进行维护即可,同时查询存储于压缩文件的码表字典,随着三元数组的不断输入,算法会在滑动窗口中找到满足要求的匹配串,在输出流文件中对符合字符串进行输出(如果off和len 数值都为0,只需要输出后继字符c )。
5 结语
本文中所论述的數据压缩技术在嵌入式实时操作系统Vxworks和主流操作系统之间能够相互兼容,使得对Vxworks的应用做了进一步的扩展,且在工程实践中得到良好的应用。本文详细描述了数据压缩技术算法的数据模型及其实现方法,对研究其他压缩技术提供了思路和研究方法。
参考文献
[1]闫阳,张正炳.浅谈数据压缩技术[J].长江大学学报(自科版),2004,1(4):120-121.
[2]于翔.数据压缩技术分析[J].青海大学学报(自然科学版),2002,20(5):52-54.
[3]SalomonD.数据压缩原理与应用[M].吴乐南,译.北京:电子工业出版社,2003.
