大数据下医保欺诈的有效识别模型
2018-03-12陈清凤朱亩鑫
陈清凤,朱 宁,朱亩鑫
(桂林电子科技大学数学与计算科学学院,广西 桂林 541004)
0 引言
随着参保覆盖面和基金规模的迅速扩大,定点服务机构的大量增加,我国的医保信息系统也得到了广泛的应用,如何利用海量的医疗数据建立有效的医保欺诈预警模型,为医保中心实施监管的工作提供决策支持,是当前所要解决的首要任务.
对于医疗保险欺诈的理论分析和实证研究,国外学者主要从社会心理学、博弈论以及数据挖掘的角度进行研究.Arrow[1]根据信息不对称理论,首次对健康保险欺诈问题进行了探讨和研究.随后Pauly[2],Schiller,Moreno[3]分别从管控道德风险和剔除受投保方操纵信号的方式反制欺诈.在此基础上,Artis[4],Chiappori[5],Brocket[6]等人分别采用Probit、AAG、Pridit、logit等统计模型,对具体的欺诈行为进行识别.但由于这些模型对数据有一定的要求,加上欺诈的复杂性,这使得传统的单一模型在实际的应用中受到很大的限制.为此Marisa S[7],Sokol[8],Lious[9],等人把人工智能识别模型和统计回归模型进行有效的组合,分别建立了基于BP神经网络模型、遗传算法、贝叶斯网络、糊集聚类算法、数据挖掘的欺诈识别模型,并用于特定的例子中,识别效果较好.除此之外基于启发式和机器学习的电子欺诈识别技术也被广泛的应用于医疗保险欺诈识别.
国内学者对医疗保险欺诈问题主要是运用信息不对称和博弈论,围绕欺诈的类型、表现形式、欺诈的成因分析和反欺诈措施等三个方面进行理论研究,关于社会医疗保险欺诈的识别和度量的研究还较少[10].对于社会医疗保险欺诈的识别,较早应用的是徐远纯[11]根据粗糙集理论的特征属性提出的欺诈风险识别方法,随后陈辉金、韩元杰[12]基于数据挖掘和信息融合技术建立孤立点集来挖掘可疑数据;梁子君[13]利用贝叶斯网络建立了识别、评估和管控欺诈风险的概念模型;叶明华[14]把统计回归和神经网络进行有效融合,建立了基于江、浙、沪机动车保险索赔数据构建了欺诈识别的BP神经网络模型.杨超[15]在叶明华的研究的基础上,运用嵌入logistic回归分析的BP神经网络模型研究识别被保险人道德风险引致的欺诈.总的来说,如何从海量的复杂隐秘的医疗保险数据中识别出具有欺诈行为的信息还没有得到具体的解决,为此把统计方法与大数据相结合的识别模型的研究是有意义的.
本文在大数据背景对医疗保险欺诈这一课题进行研究,首先对给定的医疗数据进行预处理,通过主成分分析构建欺诈识别的有效指标体系;其次由K-Means聚类得到可疑的医保欺诈行为的类别;再次,利用因子分析方法,根据特征因子分析诈骗类的特征确定其诈骗方式;最后把模型用于由样本经验分布的反函数生成的大数据中.具体流程如图1.
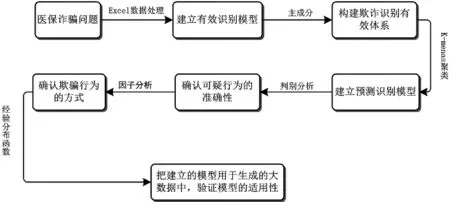
图1 医保欺诈模型流程图
1 数据预处理
本文以2015年“深圳杯”数学建模夏令营A题:医保欺诈行C医保数据为研究数据,共289 001条记录.为了构造医保诈骗有效识别的数据集,本文利用大数据挖掘技术对参保人信息进行数据预处理,利用Excel软件中的vlookup函数对原始数据进行定性筛选,去掉不必要的数据.
数据清洗基于课题的研究意义和方向,结合给出的6个表格的医疗数据,进行数据清洗.首先利用Excel中的透视表剔除缺失值个数大于列数20%的行,并删除对于本次数据挖掘没有意义数据,保留相关数据列,观察得到的数据集中没有重复记录,省去了对重复记录的处理.其次是对于缺失的必要数据,例如刷卡次数缺失的数据,其占总样本的25.5%,采用数据归约中多项式回归的方法填补空缺,其他指标也如此.
数据的转换清洗得到的数据转换为便于处理的形式,日期采用“年-月-日”格式,医嘱ID号精简成数字型.
生成有效识别数据集从给定的数据中提取出用于描述样本的指标,从而解释医疗数据的标签和分类的来由.根据参保人信息数据集和医保交易记录数据集中的属性对数据进行适当处理,进而派生出所需要的识别指标.对医保交易记录数据集中的重要属性进行不重复计数处理,派生出总费用、刷卡总次数、一次性消费最高额、平均消费金额以及医嘱子类、开嘱医ID、下医嘱科室、核算分类、执行科室和病人科室的不重复计数这10个指标.
本文选取了具有代表性的属性,并根据参保人信息数据集中的PAPMI_PAPER_DR(身份证ID)和医保交易记录数据集中的WorkLoad_PAPMI_DR(病人病历ID)将两数据集进行自然连接,从而生成目标数据集,即医保诈骗有效识别数据集,见表1.此时数据集已经从初始的289 001条原始记录整合成58 014条目标记录.
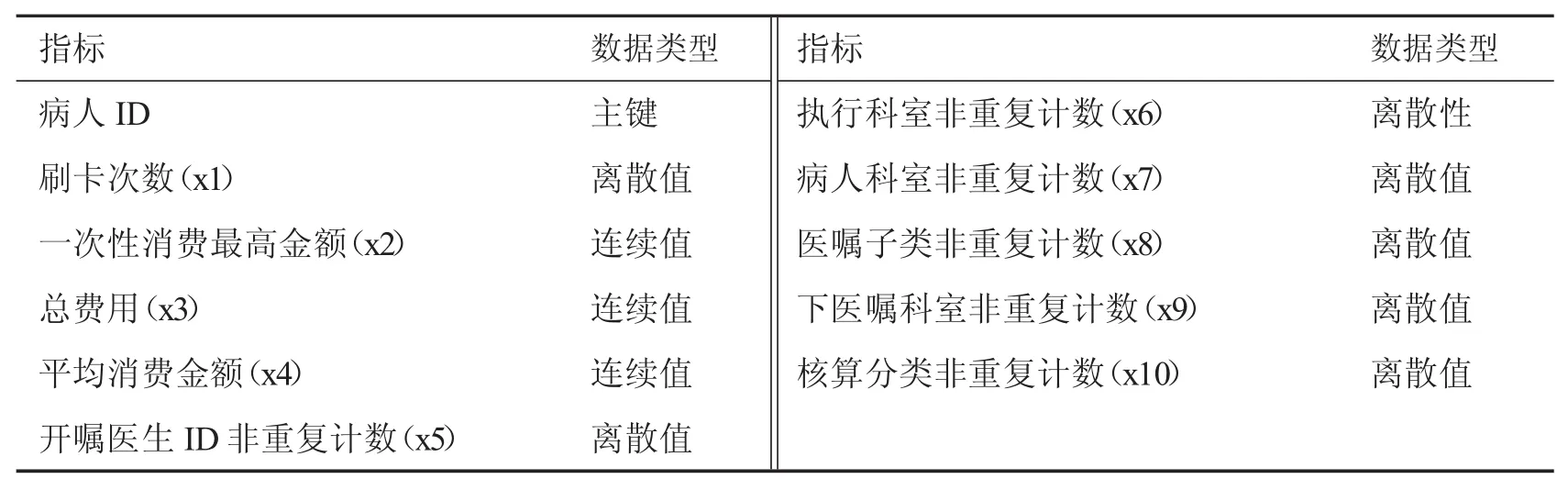
表1 参保人信息和医保交易记录交叉数据集
数据标准化根据zij=(xij-x)i/si对提取出的数据集进行标准化处理,其中zij为标准化后的变量值,xij为实际变量值.
2 欺诈识别的有效指标体系的构建
由于得到的识别指标过多,如果对所有的指标进行分析可能会存在信息重叠,对部分个体的欺诈识别因子进行主成分分析,提取综合指标来消除指标间相关性.首先,对指标进行了相关分析,运用SAS统计软件导入包含58 014个医保人信息的数据集,计算出各指标之间的Pearson相关系数,结果如表2.
由表2可以看出,部分指标之间存在着严重的相关性,如病人科室不重复计数和下医嘱科室不重复计数间的相关系数高达0.999,接近于1;一次性消费最高数额和总费用的相关系数也达到了0.758,说明原指标变量间有一定的相关性.此时如果直接对原来的指标进行分析就会造成信息的重复使用而使得结果不准确.
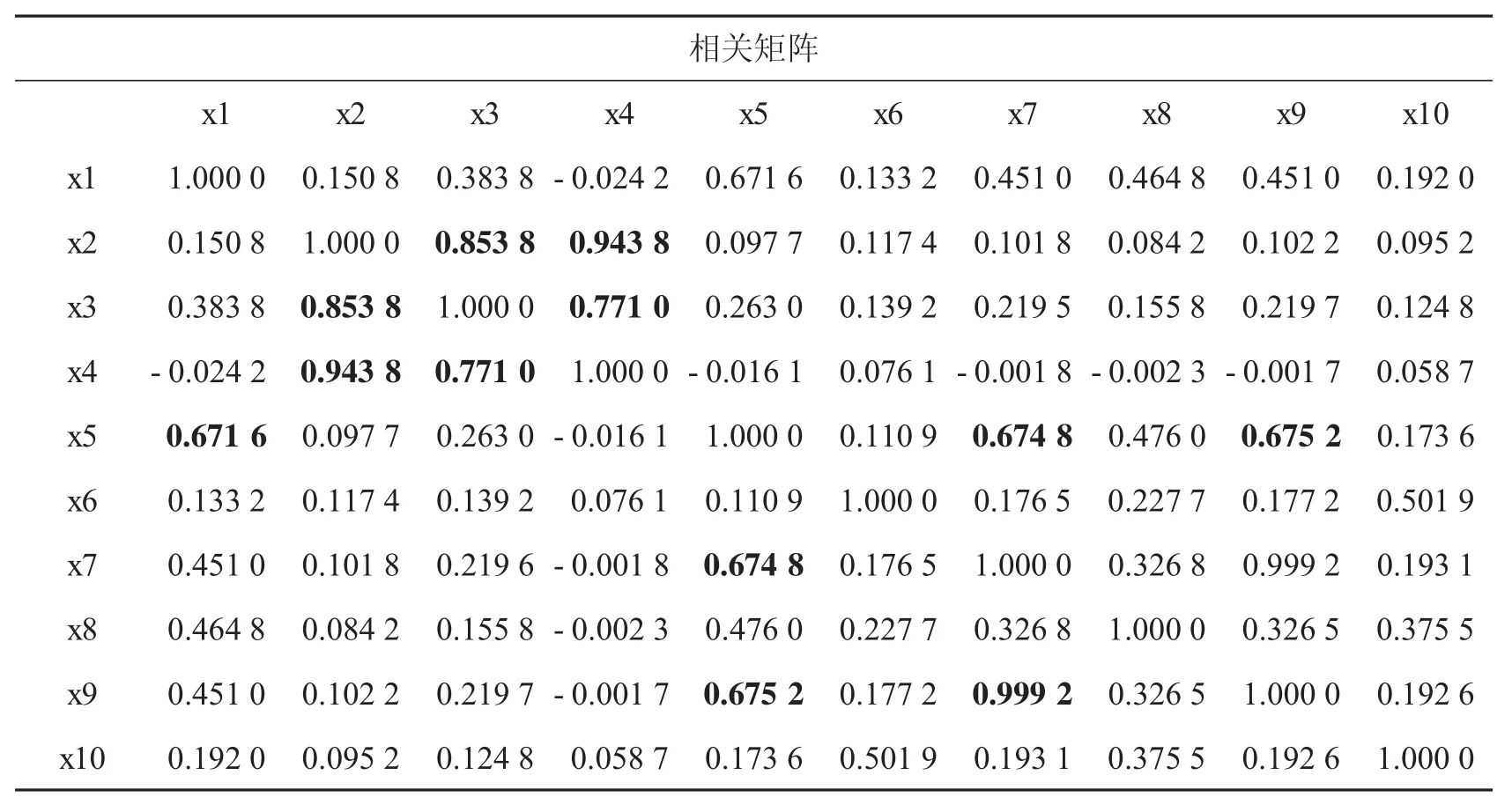
表2 指标之间Pearson相关系数
随后,通过主成分分析来消除指标之间的相关性,提取出欺诈识别模型的综合指标,结果如表3.
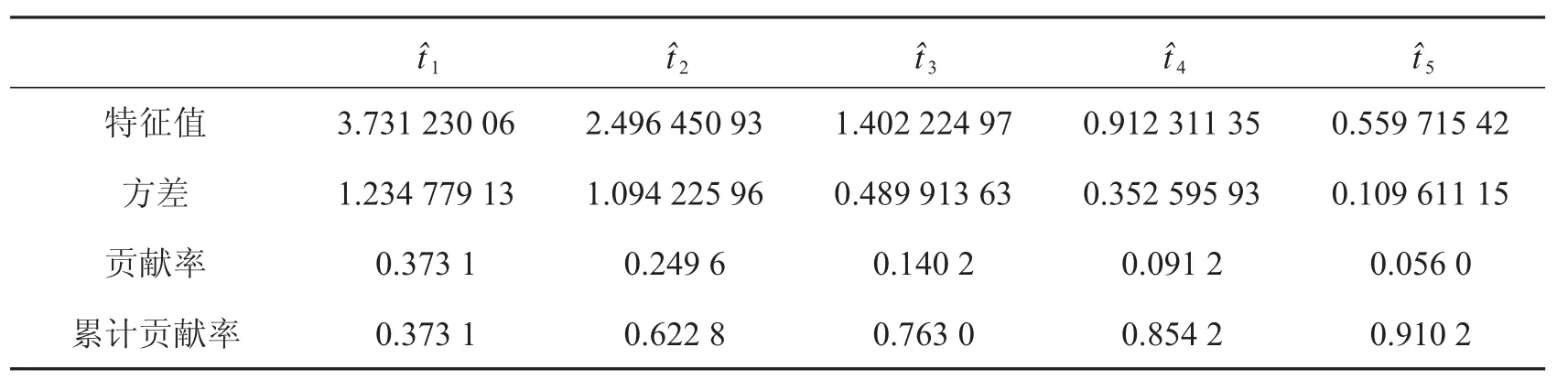
表3 主成分分析结果
由表3的数据可以看出,前五个主成分的累计贡献率已达到91.02%,可以认为它们能较好地概括原始指标的大部分信息,即用前五个主成分作为欺诈识别指标.
3 欺诈识别的统计模型
3.1 随机样本的类平均聚类
为了更好的识别出医保数据中的欺诈行为,根据收集到的六万人的消费交易记录,利用类平均聚类对其进行聚类获取先验信息,将主成分分析得到的前五个主成分作为综合指标,通过无放回简单随机抽样方法抽取5组样本(每一组容量5 000)进行聚类,下面对其中一组建立医保诈骗识别模型.聚类的信息如表4.
从R2统计量来看,当NCL(聚类数)>5时下降较缓慢,且NCL=5时下降较大,半偏相关统计量达到最大;从伪F统计量来看,NCL=5时,取得极大值,且NCL=5时,PST2(伪F统计量)取得极大值.由此可知,随机样本分成5类较合适.
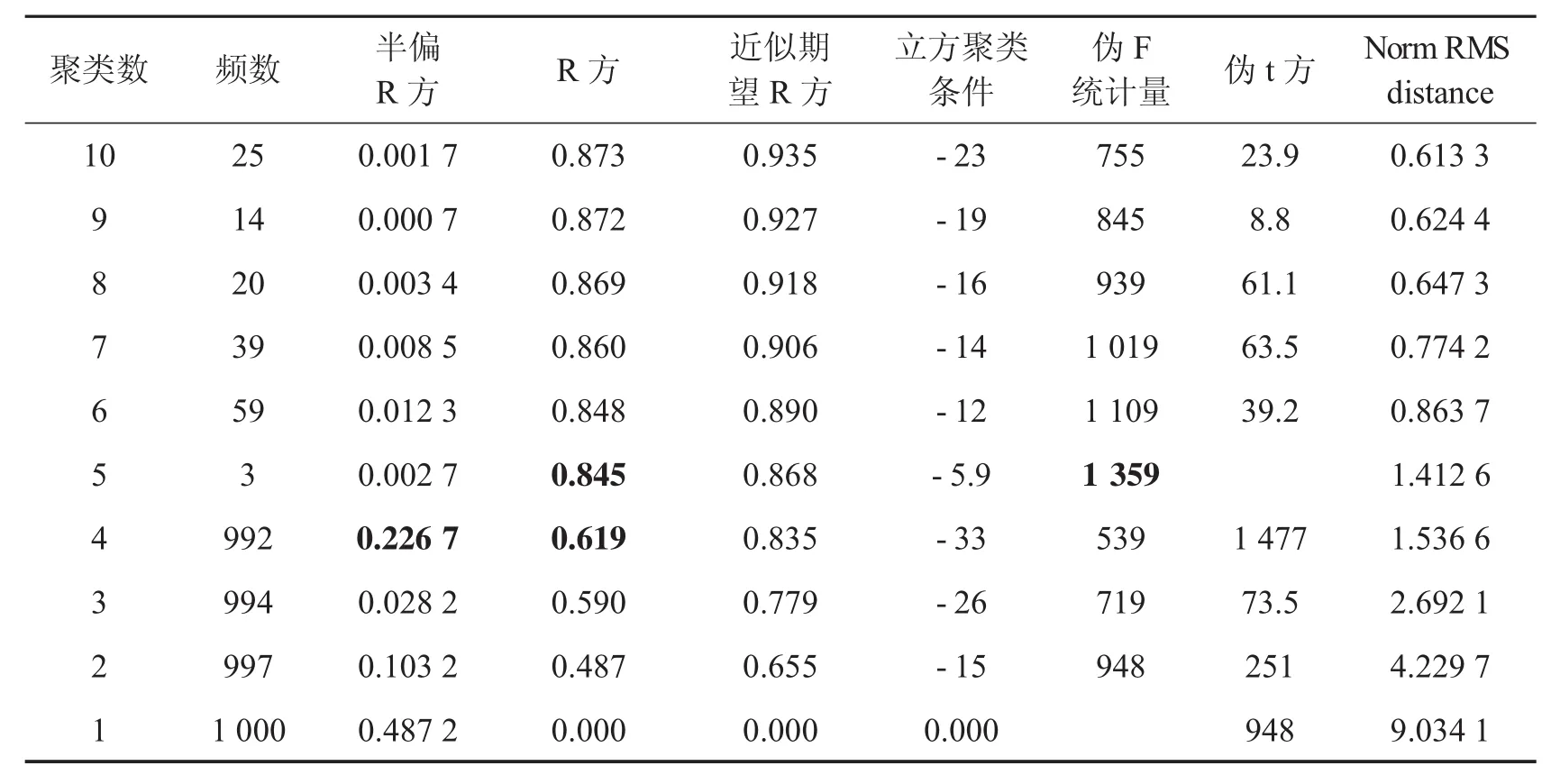
表4 随机样本类平均聚类结果
重复以上步骤,再对随机抽取的其他4组样本进行K-Means聚类分析,过程与上面样本类似.通过对利用无放回简单随机抽取方法抽取到的5组样本量为5 000的样本依次进行主成分聚类分析,其中有3组样本认为聚成5类最合适,其余2组比较分散,将这些信息作为先验信息,根据最大似然函数的原理认为全部样本聚成5类是合适的.聚类结果如表5.
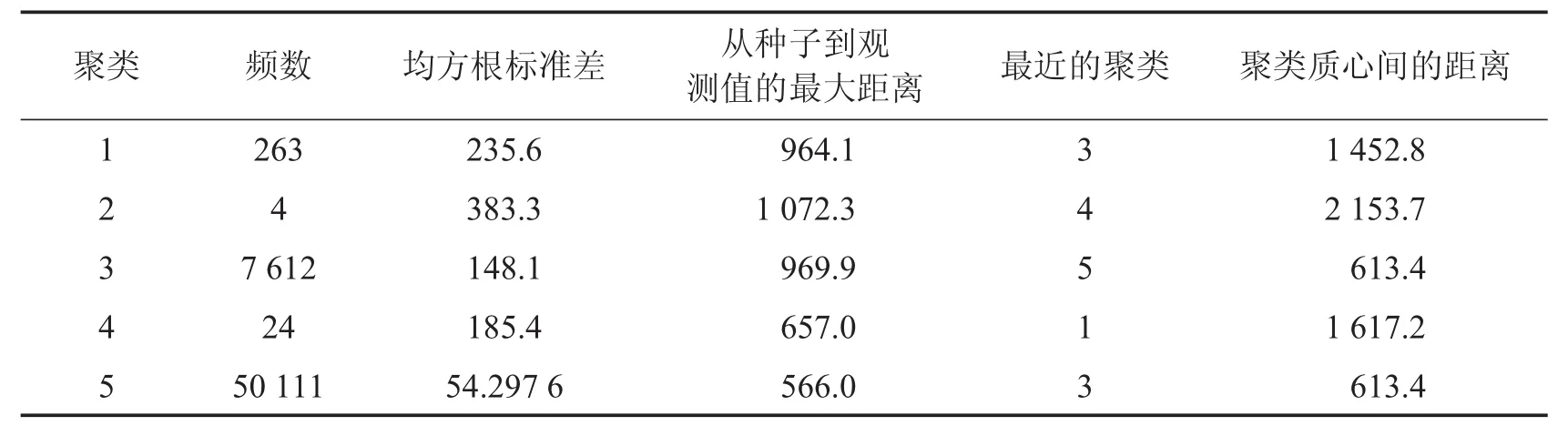
表4 K-Means动态聚类
由表4看出第五类包含的样本最多,共有50 111条记录,其次是第三类,而第1、2、4类的个数较少.由于医疗保险诈骗事件属于小概率事件,且诈骗的形式有多种,比如拿着别人的医保卡配药、在不同的医院和医生处重复配药等,可以表现为单张处方药费特别高、一张卡在一定时间内反复多次拿药等.由表4的数据可直观的认为第1、2、4类属于医保诈骗的可能性较大,因为它们组内均方根的标准差和从凝聚点到各类内观测值的最大距离都比较大,说明这些类之间有一定的差异,存在着问题,需要谨慎对待.
3.2 模型检验—判别分析
为了验证K-Means动态聚类结果的合理性,利用判别分析中的交叉确认估计来判断聚类准确性,结果如表5和表6.
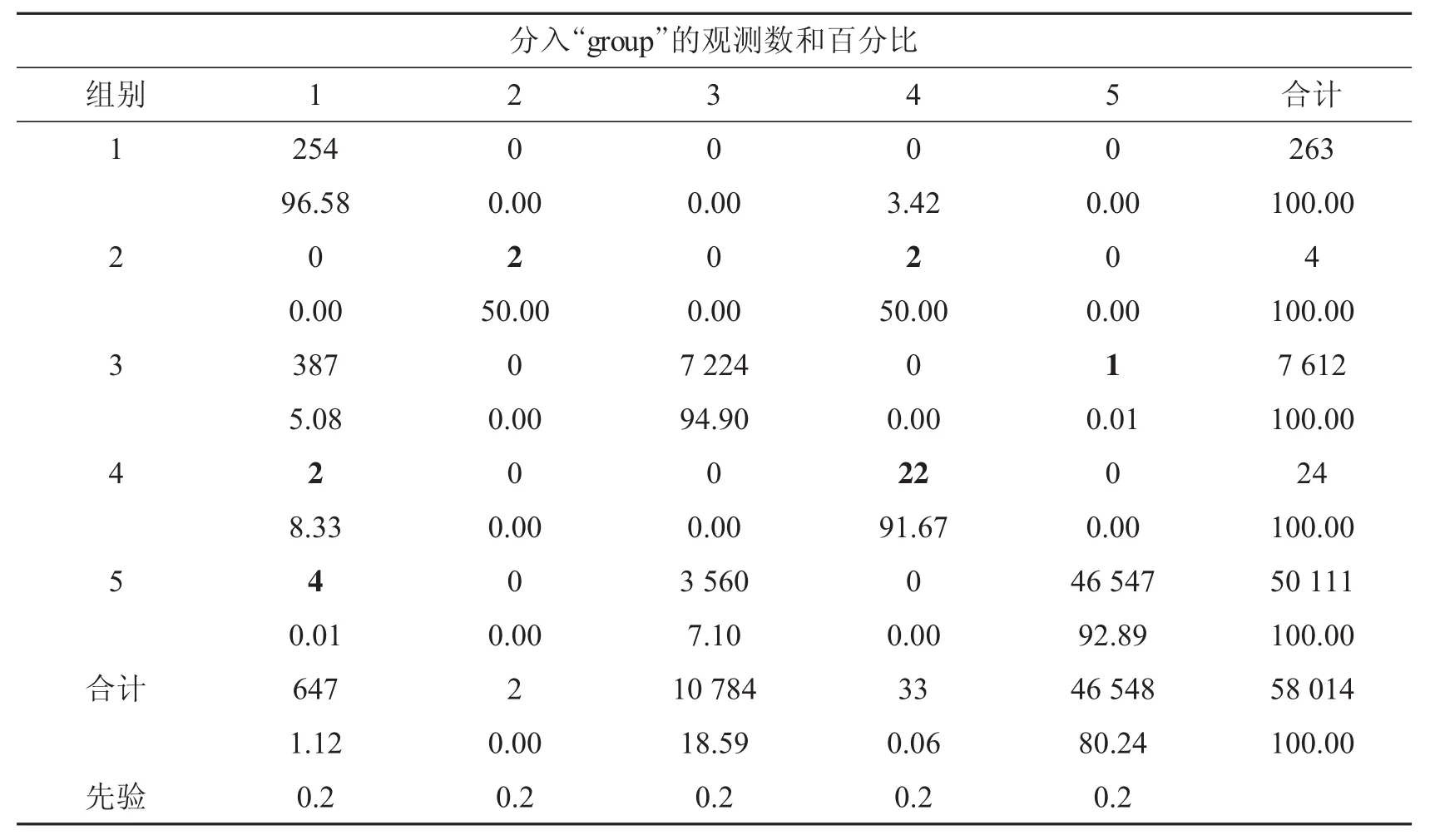
表5 各组错判具体情况

表6 错判概率
由表5和表6的数据可知,聚类时总体的错判概率为0.147 9.其中第1组中错判的样本量为9个,错判概率为0.034 2,且这9个错判的样本都被错判到第4组;第2组中错判的样本量为2,错判概率高达0.500 0,且这2个错判的样本都被错判到第4组;第3组中错判的样本量为388,错判概率为0.051 0,其中387个样本被错判到第1组,1个样本被错判到第5组;第4组中错判的样本量为2,错判概率为0.083 3,且这2个错判的样本都被错判到1组;第5组中错判的样本量为3 564,错判概率高达0.071 1,其中4个样本被错判到第1组,3 560个样本被错判到第3组.
结合K-Means聚类的结合和判别分析的结果可知,在57 723个非欺诈个体中有391个可能属于欺诈个体,错判概率为0.677%;而初始判断为欺诈类别的291个样本中有0个被错判,此时错判概率为0%.由此可以初始确定的诈骗类别是合理的.
3.3 医保欺诈识别的特征模型—因子分析
利用因子分析找出潜在的对医疗数据中较为可疑的医疗数据的特征进行分析,通过公共因子来查找出K-Means聚类中的第1,2,4类可疑诈骗的基本特征,最终确定诈骗方式.设特征值(Eigenvalues)、贡献率(Contribution rate)和累计贡献率分别用(Cumulative contribution rate)Eig、CR、CCR表示,则进行因子分析后的统计量如表7.
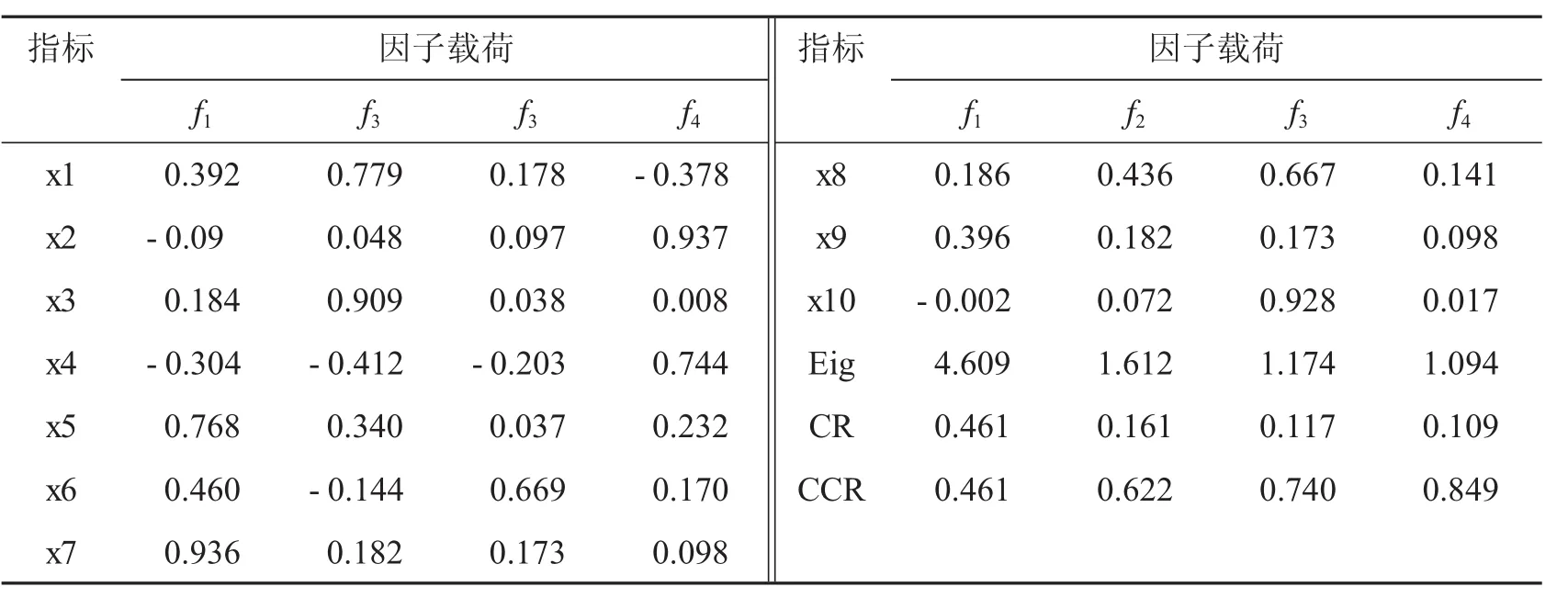
表7 因子分析统计量
从表7可以看出,在以100%的累计方差贡献率确定的10个因子中,前4个因子特征值大于1,累计方差贡献率高达84.9%,故考虑提取4个公因子.又从最大方差旋转的因子载荷矩阵可知,公因子f1主要在病人科室非重复计数、开嘱医生ID非重复计数、执行科室非重复计数上具有较大的正载荷,故命名为科室分类因子;公共因子f2主要在刷卡次数、费用有很大的正载荷,故命名为刷卡费用因子;公共因子f3主要在执行科室非重复计数、医嘱子类非重复计数有较大的正载荷,故命名为医疗服务因子;公共因子f4主要在一次性消费最高金额、平均消费金额有很大的正载荷,故命名为费用因子.
通过上述分析可发现此类有个共同特点就是一次性消费平均消费最高金额,病人科室非重复计数所占比率最高,存在故意串通医生开大处方行为,购大量药品等来套取统筹医保基金的嫌疑,属于医疗保险服务供方与需方合谋的诈骗行为.
以此类推可以得到第2、第4类的诈骗方式.其中,第2类欺诈的方式可定义为贩卖药品诈骗,是指医保患者通过医保卡去不同的医保定点医院多次重复看病、取药,然后再将多取的药品贩卖,从而达到骗取医保基金的目的;第4类诈骗方式定义为分解收费诈骗,即定点医疗机构在为参保患者提供医疗服务过程中,人为地将一个完整的连续的医疗服务项目分成两个或两个以上的医疗服务项目,并按分割后的项目进行收费,从中获取差价进行医疗诈骗.
综上所述,可将欺诈行为分成三大类:
1.医疗保险服务供应方的诈骗行为;
2.医疗保险需求方的诈骗行为;
3.医疗保险服务供应方与需求方合谋的诈骗行为.
结合各类的具体特征,又可以将各欺诈行为分别定义为分解收费诈骗、贩卖药品诈骗、提供虚假证明或伪造病历诈骗、冒名顶替诈骗.
3.4 大数据下的模型的优越性
为了验证模型的适用性,将识别模型应用于生成的海量数据中运行.首先,把第一个指标的数据(刷卡次数(x1))由origin软件拟合出样本的分布函数为:
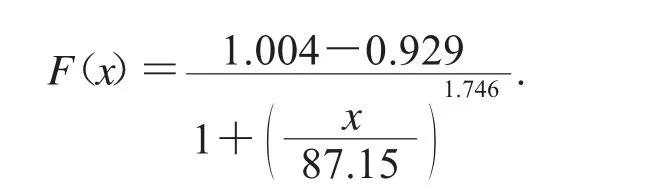
其次,产生符合该分布随机,通过分布F(x)反函数求出随机数对应的样本x值,重复以上步骤便可得其他各指标的数据的样本的分布函数,最后把提出的识别欺诈模型带入求得的样本值中,再利用上述方法重新运行一遍,以便验证之前所用方法是否正确.
4 结论
研究结果表明:基于主成分K-Means聚类和因子分析的数据挖掘方法对医保欺诈行为能够进行较为准确的预警,与直接进行聚类相比,文中提出的模型运行速度较快、效率较高,并适用于大数据中的欺诈行为的识别.在设计思路上从统计分析的角度出发,定量地研究了如何从大量数据中识别出少数的可疑的医保诈骗行为.
[1]ARROW K J.Uncertainty and the welfare economics of medical care[J].Uncertainty in Economics,1978,82(2):141-149.
[2]PAULY M V.Taxation,health insurance,and market failure in the medical economy[J].Journal of Economic Literature,1986,24(2):629-675.
[3]SCHILLER J.The impact of insurance fraud detection systems[J].Journal of Risk and Insurance,2006,73(3):421-438.
[4]ARTÍS M, AYUSO M, GUILLÉN M.Detection of automobile insurance fraud with discrete choice models and misclassified claims[J].Journal of Risk and Insurance,2002,69(3):325-340.
[5]CHIAPPORI P A,SALANIE B.Testing for asymmetric information in insurance markets[J].Journal of Political Economy,2000,108(1):56-78.
[6]BROCKETT P L.Fraud classification using principal component analysis of RIDITs[J].Journal of Risk and Insurance,2002,69(3):341-371.
[7]VIVEROSMS,NEARHOSJ P,ROTHMAN MJ.Applying data mining techniques to a health insurance information system[C]//VLDB'96 Proceedings of the 22th International Conference on Very Large Data Bases.San Francisco:Morgan Kaufmann Publishers Inc.1996:286-294.
[8]SOKOL L,GARCIA B,RODRIGUEZ J,et al.Using data mining to find fraud in HCFA health care claims[J].Topics in Health Information Management,2001,22(1):1-13.
[9]LIOU FM,TANG Y C,CHEN J Y.Detecting hospital fraud and claim abuse through diabetic outpatient services[J].Health Care Management Science,2008,11(4):353-358.
[10]林源.国内外医疗保险欺诈研究现状分析[J].保险研究,2010(12):115-122.
[11]徐远纯,柳炳祥,盛昭瀚.一种基于粗集的欺诈风险分析方法[J].计算机应用,2004,24(1):20-21.
[12]陈辉金,韩元杰.数据挖掘和信息融合在保险业欺诈识别中的应用[J].计算机与现代化,2005(9):110-112.
[13]梁子君.保险公司操作风险管理——用贝叶斯网络评估和管理保险欺诈[D].上海:上海财经大学,2006.
[14]叶明华.基于BP神经网络的保险欺诈识别研究——以中国机动车保险索赔为例[J].保险研究,2011(3):79-86.
[15]杨超.基于BP神经网络的健康保险欺诈识别研究[D].青岛:青岛大学,2014.
