基于深度卷积网络的特征融合图像检索方法
2018-03-10杨红菊李尧
杨红菊,李尧
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.计算智能与中文信息处理教育部重点实验室(山西大学),山西 太原 030006)
0 引言
近些年,基于内容的图像检索技术在计算机视觉领域备受关注[1-3],很大程度上帮助和改善了人们的生活。基于内容的图像检索方法是基于给定的查询实例,在数据库中查找纹理和语义与之相似的实例。基于内容的图像检索方法分为两个阶段:特征提取和相似度计算。特征提取用于描述图像局部纹理或整体的语义信息,相似度计算用于度量图像特征之间的距离,其中特征提取在检索领域扮演着重要角色。
传统的图像特征提取方法虽然取得了较好的进展,但并不能弥补电子设备所捕获的特征和视觉神经所感知到的语义信息之间的差异,例如尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)[4],方向梯度直方图(Histograms of oriented gradients,HOG)[5],局部二进制模式(Local Binary Pattern,LBP)[6]等。最近研究表明,由多个非线性映射层所组成的卷积网络在图像分类[7-8]、检索[1-3]、物体检测[9]等视觉相关领域取得了突破性的进展。不仅如此,基于深度模型的卷积网络(convolution neural network, CNN)和循环网络在语音识别[10-11]和自然语言领域[12-13]也有着广泛的应用。
卷积网络在图像检索领域有着广泛的应用[7,14-17],主要可分为基于卷积层的特征和基于全连接层的特征表示。全连接层的特征使用一维向量进行编码,Krizhevsky等[7]将全连接层的数值作为特征用以检索任务,取得了突破性的进展。Babenko等[14]使用主成分分析将全连接层的特征从高维空间映射到相对较低的维度,提高了检索性能。虽然降低特征维度有助于提高检索效率,但这种两段式的特征计算方法会丢失某些潜在的语义特征。受到文献[14]工作的启发, Xia等[15]将图像编码为维度相对较低的二进制向量,但由于在数据预处理阶段需要构造图像之间的相似度矩阵,并不适合数据集相对较大的情况。Lin等[16]在倒数第二个全连接层后添加一个编码层学习图像的隐含特征,该层的激活值由阈值操作计算得到,提高了检索的效率和精度。Yang 等[17]在二进制编码层对网络计算得到的数值特征添加相关的约束条件,使得编码表达能力也有所提高。
最近的研究表明[18],全连接层的特征趋向于刻画图像全局的语义信息,卷积层对图像的局部语义信息比较敏感。传统的图像检索任务中,多使用全连接层的激活值作为特征进行相似度检索,失去了对图像局部信息的刻画能力。因为对于自然的图像,全局的语义轮廓信息并不能区分有些类别之间的区别:例如在区分“狗”和“长颈鹿”时,使用高层的语义特征从外形轮廓上就可以区分出类别之间的差距,而对于有些“狗”和“猫”的差异,需要从局部细节纹理上进行区分。Babenko等[19]将卷积层计算得到的三维特征图,通过局部加权的方式编码为一维的特征向量,用于图像检索任务。Ng等[20]提出使用VLAD聚合算法,将三维的特征图聚合为一维的特征向量,进行编码任务,提高了检索的精确度。
文献[19-20]的特征融合方法仅考虑到二维特征图中的每个像素权重,并未考虑到每个维度的权重。基于该问题,本文提出了一种基于卷积层特征的融合方法(Spatial Weight Feature, SWF),将三维的特征图编码为一维的特征向量, 使用卷积层的特征去刻画图像的局部纹理信息,用于检索任务。
1 卷积特征融合
1.1 卷积神经网络
近年来,基于深度模型的卷积网络在计算机视觉领域取得了突破性的进展。CNN是由多个非线性映射层组成的网络架构,主要包括卷积层,池化层以及全连接层,其中卷积层和全连接层之间需要学习对应的网络参数。
CNN首先通过前向传播计算输入图像的预测分类结果,使用对应的图像标签计算分类误差,然后反向传播误差梯度更新网络权重。卷积层是网络的核心组成部分,主要使用卷积核提取图像的局部细节纹理,颜色以及形状等特征。卷积核的大小随着网络层次的加深逐渐减小,卷积核越小,提取图像特征的能力越强。池化层用于对卷积层计算得到的特征图进行下采样操作,降低网络模型的复杂度,对急剧变化的特征图进行均衡化操作。全连接层用于将三维的特征图编码为一维的特征向量,将图像的局部细节特征归结为全局的语义信息。激活函数用于对卷积得到的特征图进行非线性映射。网络最后连接一个多分类器,使用输入图像对应的标签和预测得到的结果计算对应的误差梯度,用以更新网络权重。经过若干次迭代计算之后,网络的误差趋于稳定,分类精确变高。
1.2 特征融合
卷积层计算得到的是三维的特征图,并不能直接用于检索任务,首先需要将三维的特征编码为一维的描述算子。基于该问题,本文使用局部特征融合方法,将三维的特征图编码为一维特征向量用于相似度计算,同时保持特征的区分能力。
本文使用F∈R(K×W×H)表示卷积层计算得到的特征图,K表示特征图的个数,W和H分别代表每个特征图的宽和高。由于每个特征图代表图像不同细节方面的纹理特征,可以将其编码为对应的浮点数,最终得到一个K维的向量。式(1)中,f(x,y)表示特征图坐标(x,y)上的激活值,Φ(k)(I)表示计算得到的一维向量中的特征值,具体表述如下:
(1)
公式(1)中,在对特征图进行加权时,将每个像素值均视为等价的地位,权重均赋值为1。但是在人的视觉神经中,对于一幅图像,并非是关注图像的每个细节,而是前景物体或者一些重要的区域。基于该问题,本文假设一幅图像中,最重要的区域是中心区域,越向边缘靠拢像素值的权重越低。使用α(x,y)∈R(W,H)代表特征图中每个位置对应的权重,可以将上述公式(1)改为表达式(2):
(2)
每个像素值所对应的权重系数α(x,y)依赖于在整个特征图中出现的位置,本文使用高斯核来计算每个像素值的权重,权重计算公式如式(3)所示,其中W和H分别表示特征图的宽和高,σ设定为W的三分之一:
(3)
对于三维特征中的每个二维特征图而言,也有与之对应的权重。本文使用β∈R(K)表示每个维度的权重。每个二维特征图所对应的权重和该平面中激活值大于零的个数成正比,并且特征图中激活数值总和N也应该被考虑在内,如表达式(5)所示:
β(k)=log(N/ξ(k))
(4)
(5)
其中ξ表示二维特征图中激活值大于0的像素个数和总像素个数的比例。如果v>0则Ι[v]=1,否则Ι[v]=0。将每个特征图的权重也考虑在特征编码中,得到的特征如下式所示:
(6)
最终计算得到特征向量用Φ(I)∈RK表示。之后使用主成分分析和白化操作,对计算得到的特征向量进行处理。如下所示:
Φ(I)=diag(s1,s2,s3…sN)-1MΦ(I)
(7)
(8)
其中M∈RN×C将C维的特征向量编码为N维向量。使用L2范数处理计算得到的向量,如式(8)所示。最终将三维的特征图F∈RK×W×H编码成为一维的特征向量Φ(I)∈RK,使用欧式距离来计算两个特征之间的距离。
2 实验结果
本文对提出的编码方法在INRIA和Oxford数据集上进行评估。INRIA Holidays总计包含1 491张图像,其中500张作为查询实例。Oxford数据集包含5 062张图像,55张查询实例。使用VGG网络提取图像的卷积层特征,每个图像均放缩到586×586大小作为网络的输入,从最后一个卷积层提取得到的特征图大小为512×37×37。卷积网络使用开源的神经网络库Caffe[21]实现。
将本文提出的SWF与传统的聚合模型,如Avg Pooling, Fisher Vectors[22],Triangulation embedding[23]以及SPoc进行比较。上述所有的聚合方法最终均使用主成分分析将特征编码到相对较低的维度。使用平均查准率(mean average precision,MAP)评估算法的查询性能,实验结果如表1所示。
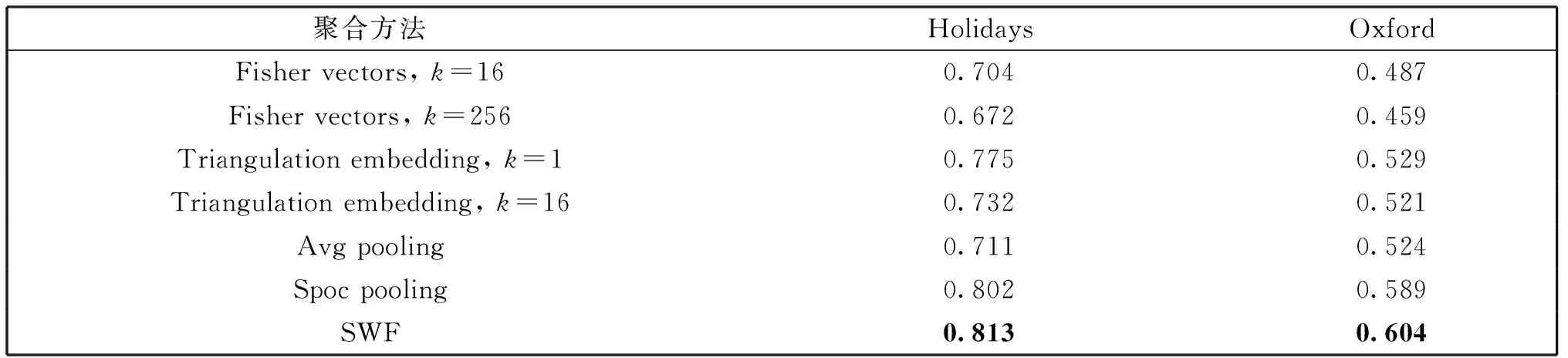
表1 检索平均查准率
从表1可以看出,相比较于其他的模型,基于SWF的聚合方法,在平均查准率上高于其他的聚合模型,这主要是因为对不同维度的特征赋予了合适的权重因子,去除了特征图编码中存在的不相关信息。在数据集Holidays上的平均查准率要高于Oxford,因为在Oxford上,每个图像存在的噪点相对较多,并且对于每个建筑存在多个视角方面的实例。同时,本文对不同层的编码结果也进行检索效果评估,结果如表2所示。从中可以发现编码长度在256维之后的检索效果趋于稳定,同时发现,第五个池化层计算得到的特征向量具有较强的编码能力,在平均检索精度上优于其它层得到的结果。这是由于深层的特征更加趋向于刻画图像整体的轮廓,去除了局部细节有可能产生的噪音所导致的。

表2 不同长度的编码特征平均查准率
为了进一步验证算法的有效性,本文从Oxford上挑选出两个图像,对SWF和Sum pooling方法进行查询结果的可视化,如图1所示。从左到右,相似度依次递减,用绿色方框框起来的表示查询正确的图像,黄色代表原图像。发现基于SWF加权的特征编码方法检索到正确的图像个数相对较多,并且查询到的图像中包含的建筑视角也大致相同。

Fig.1 Retrieval results in SWF aggregation method图1 SWF检索效果
为了进一步探究提出编码方法的特性,本文对SWF的编码方法计算得到的特征进行可视化,如图2所示。可以看出,对于直接将每个维度对应的激活值相加得到的特征图,存在较多的噪点,如Sum pooling。而SWF加权特征图,去掉了不相关的图像区域,突出了图像中心区域中的建筑整体轮廓,去掉了边缘中无关的信息,进而提高了特征的编码能力。
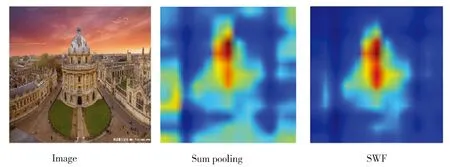
Fig.2 Illustration of different feature aggregation methods图2 不同特征融合方法示意图
从上述的检索平均精准度和检索结果示意图可以看出,本文所提出的特征融合方法较适合于将三维的特征图编码为一维特征向量,用于检索任务,达到了相对较好的结果。从图2的特征融合结果可以看出,对每个特征维度赋予相对应的权重,可以减小图像中不相关区域的噪点,突出语义的整体轮廓。并且图2中的高亮区域对应的物体和原图像对应的实例区域几乎重合,表明本文所提出的特征聚合方法,可以提取出自然图像中对分类性能至关重要的区域,关注于图像中最为感兴趣的区域的特征编码,而并非图像的整个区域,进而提高了检索效率。
3 结语
基于深度卷积网络,本文提出了一种基于特征加权的编码方法,将三维的特征图编码为一维的特征向量用于检索任务。在数据集Oxford和INRIA上均取得了相对较好的结果。虽然使用卷积层的特征在平均查准率上有所提升,但这种两段式的编码方法会降低图像特征的表达能力,在后续的工作中将继续探讨如何将两段式的编码方法变为端到端的特征提取框架,用于检索任务,提高检索效率。
[1] Jiang K,Que Q,Kulis B.Revisiting Kernelized Locality-sensitive Hashing for Improved Large-scale Image Retrieval[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2015:4933-4941.DOI:10.1109/CVPR.2015.7299127.
[2] Yan K,Wang Y,Liang D,etal.CNN vs.SIFT for Image Retrieval:Alternative or Complementary? [C]∥Proceedings of the 2016 ACM International Conference on Multimedia. New York, USA: ACM, 2016: 407-411.DOI:10.1145/2964284.2967252.
[3] Babenko A,Lempitsky V.Aggregating Local Deep Features for Image Retrieval[C]∥Proceedings of the IEEE International Conference on Computer Vision.New York,USA:IEEE,2015:1269-1277.DOI:10.1109/ICCV.2015.150.
[4] Ng P C,Henikoff S.SIFT:Predicting Amino Acid Changes That Affect Protein Function [J].NucleicAcidsResearch,2003,31(13):3812-3814.DOI:10.1093/nar/gkg509.
[5] Dalal N,Triggs B.Histograms of Oriented Gradients for Human Detection[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2005,1:886-893.DOI:10.1109/CVPR.2005.177.
[6] Ojala T,Pietikäinen M,Mäenpää T.Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns[J].IEEETransactionsonPatternAnalysis&MachineIntelligence,2002,24(7):971-987.DOI:10.1109/TPAMI.2002.1017623.
[7] Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks[C].Advances in Neural Information Processing Systems,2012,25(2):2012.DOI:10.1145/3065386.
[8] Szegedy C,Liu W,Jia Y,etal.Going Deeper with Convolutions[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2015:1-9.DOI:10.1109/CVPR.2015.7298594.
[9] Tsai Y H,Hamsici O C,Yang M H.Adaptive Region Pooling for Object Detection[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2015:731-739.DOI:10.1109/CVPR.2015.7298673.
[10] Graves A,Mohamed A,Hinton G.Speech Recognition with Deep Recurrent Neural Networks[C]∥ICASSP2013:Acoustics,speech and signal processing,2013 ieee international conference on. IEEE,2013:6645-6649.DOI:10.1109/ICASSP.2013.6638947.
[11] Graves A,Jaitly N,Mohamed A.Hybrid Speech Recognition with Deep Bidirectional LSTM[C]∥ASRU2013:Automatic Speech Recognition and Understanding,2013 IEEE Workshop on. IEEE,2013:273-278.DOI:10.1109/ASRU.2013.6707742.
[12] Tseng S Y,Chakravarthula S N,Baucom B,etal.Couples Behavior Modeling and Annotation Using Low-Resource LSTM Language Models[J].Interspeech,2016,2016:898-902.DOI:10.21437/Interspeech.2016-1186.
[13] Sutskever I,Vinyals O,Le Q V.Sequence to Sequence Learning with Neural Networks[C].AdvancesinNeuralInformationProcessingSystems,2014,4:3104-3112.
[14] Babenko A,Slesarev A,Chigorin A,etal.Neural Codes for Image Retrieval[C]∥European conference on computer vision. Springer International Publishing,2014:584-599.DOI:10.1007/978-3-319-10590-1_38.
[15] Xia R,Pan Y,Lai H,etal.Supervised Hashing for Image Retrieval Via Image Representation Learning[C]∥Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence. Menlo Park,CA:AAAI,2014:2156-2162.
[16] Lin K,Yang H F,Hsiao J H,etal.Deep Learning of Binary Hash Codes for Fast Image Retrieval[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2015:27-35.DOI:10.1109/CVPRW.2015.7301269.
[17] Yang H F,Lin K,Chen C S.Supervised Learning of Semantics-Preserving Hashing via Deep Neural Networks for Large-Scale Image Search[J].ComputerScience,2015.DOI:10.1109/TPAMI.2017.2666812.
[18] Lai H,Pan Y,Liu Y,etal.Simultaneous Feature Learning and Hash Coding with Deep Neural Networks[C]∥Proc of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2015:3270-3278.DOI:10.1109/CVPR.2015.7298947.
[19] Ng Y H,Yang F,Davis L S.Exploiting Local Features from Deep Networks for Image Retrieval[C]∥Computer Vision and Pattern Recognition Workshops.IEEE,2015:53-61.DOI:10.1007/978-3-319-10590-1_53.
[20] Babenko A,Lempitsky V.Aggregating Deep Convolutional Features for Image Retrieval[J].ComputerScience,2015.DOI:10.1145/2647868.2654889.
[21] Jia Y,Shelhamer E,Donahue J,etal.Caffe:Convolutional Architecture for Fast Feature Embedding[C]∥Proceedings of the 22nd ACM international conference on Multimedia.ACM,2014:675-678.DOI:10.1109/CVPR.2007.383266.
[22] Perronnin F,Dance C.Fisher Kernels on Visual Vocabularies for Image Categorization[C]∥Computer Vision and Pattern Recognition,2007.CVPR′07.IEEE Conference on.IEEE,2007:1-8.DOI:10.1109/CVPR.2014.417.
[23] Jégou H,Zisserman A.Triangulation Embedding and Democratic Aggregation for Image Search[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:3310-3317.DOI:10.1109/ICCV.2015.150.
