面向高考阅读理解观点类问题的答案抽取方法
2018-03-08王素格李书鸣穆婉青
王素格, 李书鸣, 陈 鑫, 穆婉青, 乔 霈
(1.山西大学 计算机与信息技术学院 山西 太原 030006;
0 引言
文本信息处理技术的飞速发展为人类运行信息及知识获取提供了基础和工具.自从1999年文本检索会议(TREC)[1]组织了自动问答评测,自动问答成为了自然语言处理领域的研究热点.从现有研究看,问答系统涉及的问题可以分为事实型问题和复杂类问题[2].针对简单文本和简单问题,微软建立了一套面向儿童的开放域数据集MCTest[3]进行研究;Facebook的bAbI[4]项目提出了有理解能力的问答系统需要解决的20类问题.这些项目包含大量主观题,需要深层理解文本,综合各类信息之后才能准确回答.因此,作为问答系统的重要分支[5],阅读理解技术的研究也变得愈发重要.
在阅读理解问题求解时,首先需要应用问题分析技术对问句进行分类[6],然后根据各类问题的特征,选取不同的特征集,通过制定规则和构建不同的阅读理解模型来解决此类问题.而对于很多类型的问题,例如:怎么样、为什么等,并不适合使用简单的一个短语或一句话作答.
高考语文是检测一个学生阅读理解能力的重要考试,主要考查学生理解、分析、综合和鉴赏评价等方面的能力,其中一类题型要求考生结合阅读材料阐述自己的观点是否与作者的观点一致.例如:
【问题】作者认为“他们面对一棵树,竟是一种最美的完善”,你是否认同这个观点?
【问题观点】他们面对一棵树,竟是一种最美的完善.
【阅读材料中相关答案句】
① “秋天的每一棵树,都负载着一颗成熟的心灵.”
② “那是一排挂满冰霜的树,然而它们却至今虔诚地站着,在我记忆的春天.”
③ “树的四季都在承受烈日和风雨,它坦然地以一种坚毅面对一树同样的叶子.”
④ “我总渴望像树一样活着,坦然地正视自己的一生.”
……
该题目中的“他们面对一棵树,竟是一种最美的完善.”是作者的观点,考生需要结合阅读材料,分析阅读材料中作者为什么这么说的相关句,并根据这些句子给出自己的判断,是同意还是反对此观点.通过对2014—2016年全国和部分省市的语文高考试卷中该类题目的统计,其结果见表1.

表1 2014—2016年部分省市的语文高考试卷观点类题目统计
由表1可以看出,该题型所占比例非常高.对此类题目进行深入分析,将有效提升机器人在高考语文答题上的成绩.
与常见的公开领域简单文本阅读理解不同,若要准确回答该类问题,可以假定考生与作者的观点一致,因此,需要查找材料中与问句的观点相关的内容.阅读材料使用了多个方面刻画这一问题中的观点,而每个方面又使用了不同的词.例如,“最美的完善”应该包括“成熟、虔诚”等方面.对于这类问题的回答,若按照常用的关键词匹配方法,只能抽取出一些与树有关的介绍.近几年,LDA模型及其扩展在自然语言处理中得到充分重视和深入研究[7-9].因此,针对该类题型,本文将LDA模型应用到阅读理解观点类问题答案句抽取中.通过构建基于LDA的作者观点主题分布一致的句子查找算法,在此基础上,采用观点识别技术获取阅读材料中带观点的句子,再利用句子间的内容相似性对句子进行排序,用于答案句抽取.
1 问题观点答案句查找
1.1 问题观点与阅读材料中句子主题分布相似度计算
通常一篇散文包含多个主题,阅读材料中与答案相关的句子可以作为对问题观点的某个方面的答案,若仅仅使用关键词抽取答案,将会降低答案的准确率.因此,我们假设阅读材料中的答案句与问题中的观点句具有相似的主题分布,利用LDA对其进行隐含主题分析,再将问题中的观点句q加入到阅读材料D后,将D中的每个句子看作一个文档,则
(1)
其中:w是句子s中的一个词;z是主题集合Z中的一个主题;N是s中所有词的个数;θ是一个主题向量;zn表示s中第n个词选择的主题;γ是D中隐含主题间的相对强弱;β是所有隐含主题自身的概率分布.参数γ和β通常设为50/K、0.01,K是D中所有主题的个数.
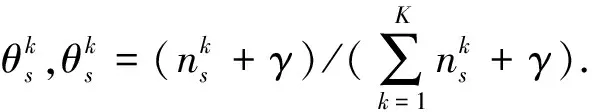
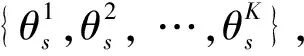
在表示句子的主题情况下,可以通过计算与之对应的主题概率分布,从而实现计算句子s与问题q的主题分布相似度,
(2)
1.2 问题观点与问题主题相关句相似度计算
在高考阅读理解题型中,阅读材料中的句子可以作为问题观点的原因解释,为了获取这些相关句子,需要对问题观点中的词语进行扩展.例如,对于引言部分的例子,可将题目中的“完善”扩展为文中出现的“成熟”,“坚毅”等.
由于词嵌入具有良好的语义特性,是词语表示的常用方式.利用词语表示构造句子间相似度计算方法,用于获得阅读材料中与问题中观点一致的句子.利用词嵌入,将句子中所有词语向量相加,即可获得句子的向量表示.
假设句子s的向量表示为s=(u1,u2,…,un),问题q的向量表示为q=(v1,v2,…,vn),则句子s和问题q的相似度值计算公式为
(3)

图1 问题语义角色分析示例Fig.1 An example of question semantic role analysis
在计算句子相似度时,如果观点句中含有公共的词语较多且长度较短时,这类观点句与问题句的相似度将会很高,而这类句子实际上与问题观点无关.例如“树”,在阅读材料中出现较多,而含有“成熟”、“坚毅”等词的句子则出现较少,使得这类句子相似性很低.语义角色分析技术通过分析句子的谓词-论元结构,可以找出句子的中心,分析出句子描述的事件.因此,为了优化与问题中的观点句相似句子的排序,在计算相似度之前,需要先对问题中的观点句进行语义角色分析,以获取观点句中重要的核心论元.例如,“他们面对一棵树,竟是一种最美的完善”,通过采用LTP(language technology platform)语义角色标注,获得的结果如图1所示.
A0、A1[10]都是句子经过语义分析后得到的论元.其中A0表示动作的施事,A1表示动作的受事.按照汉语的常用表述方式,一句话的后半部分比前半部分更重要.例如,先抑后扬等手法.我们假设问题中的观点句后半部分的受事更重要.通过对语料库所有问题中的观点句进行分析,验证了此设想.因此,如果问题中的观点句存在多个A1,我们选取问题中的观点句中最后一个A1替代原问题中的观点句进行相似度计算.
1.3 观点句识别的特征
由于答案句是对问题中观点句的一种解释,假设候选答案句中包含观点句,为了获取这些观点句,需要在主题建模之后,建立用于识别观点句的分类器.为此,根据以往的研究成果[11]及大量的散文阅读语料,收集构建包括情感词、主张性动词、程度副词和评价词4类的分类特征集合,如表2所示.

表2 特征集合
2 答案句抽取流程
利用第1节介绍的方法,设计答案抽取的过程如下:
1) 将问题q和阅读材料D进行合并,得到语料库Corpus=D∪{q},利用LDA对Corpus主题建模,主题数设定为k,获得每个句子si(i=1,2,…,n)的主题分布向量θsi,以及问题q的主题分布向量θq;
2) 利用公式(2)计算每个句子si和问题q的主题分布相似度,并对其按照相似度由大到小排序;
3)D′={s1},i=1;
fori,i≤n-1,i++;
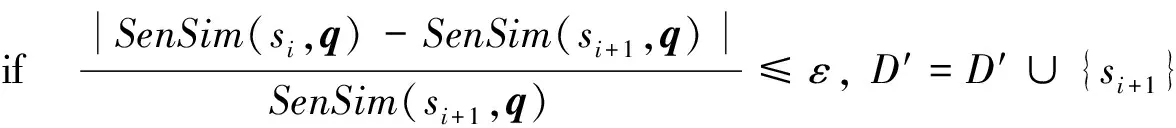
else break;
4) 利用第1.3节建立的特征集,训练SVM分类器,用于选择D′中具有观点特征的句子D″;
5) 对问题中的观点句进行语义角色分析,提取A1替代原问题的观点句;
6) 使用公式(3)计算SenSim(D″,A1),选取相似度排名在前α的句子作为答案句.
3 实验
3.1 语料来源与评价指标
实验数据包括2014—2016年的高考题,除此之外,还选取了部分省其他年份的高考题,总共21篇,按照标准答案,共标注了161条答案句.
另外,人工标注了4 119条当代名家的散文句子,用于训练SVM分类器,其中2 367条为观点句;情感词特征集选用了大连理工大学信息检索实验室的情感词汇本体;评价词选用了知网公布的评价词集,其中负面评价词3 100个,正面评价词3 700个;人工收集了主张性动词55个,程度副词63个.
由于本文面向的是散文阅读理解观点类问题的答案抽取,实验中所用到的词向量都是利用前期网络爬取的文学作品数据,通过谷歌开源的Word2Vec工具包训练获得,文学作品总共7万篇,词向量规模为477 M,维度为200维.
本文采用“HumSent准确率”评价指标,即在系统返回的对所有问题的答案句中,由人工评价认为是正确的答案句所占的比例,计算式为HumSent=抽取出的正确答案句条数/总共抽取的句子条数.
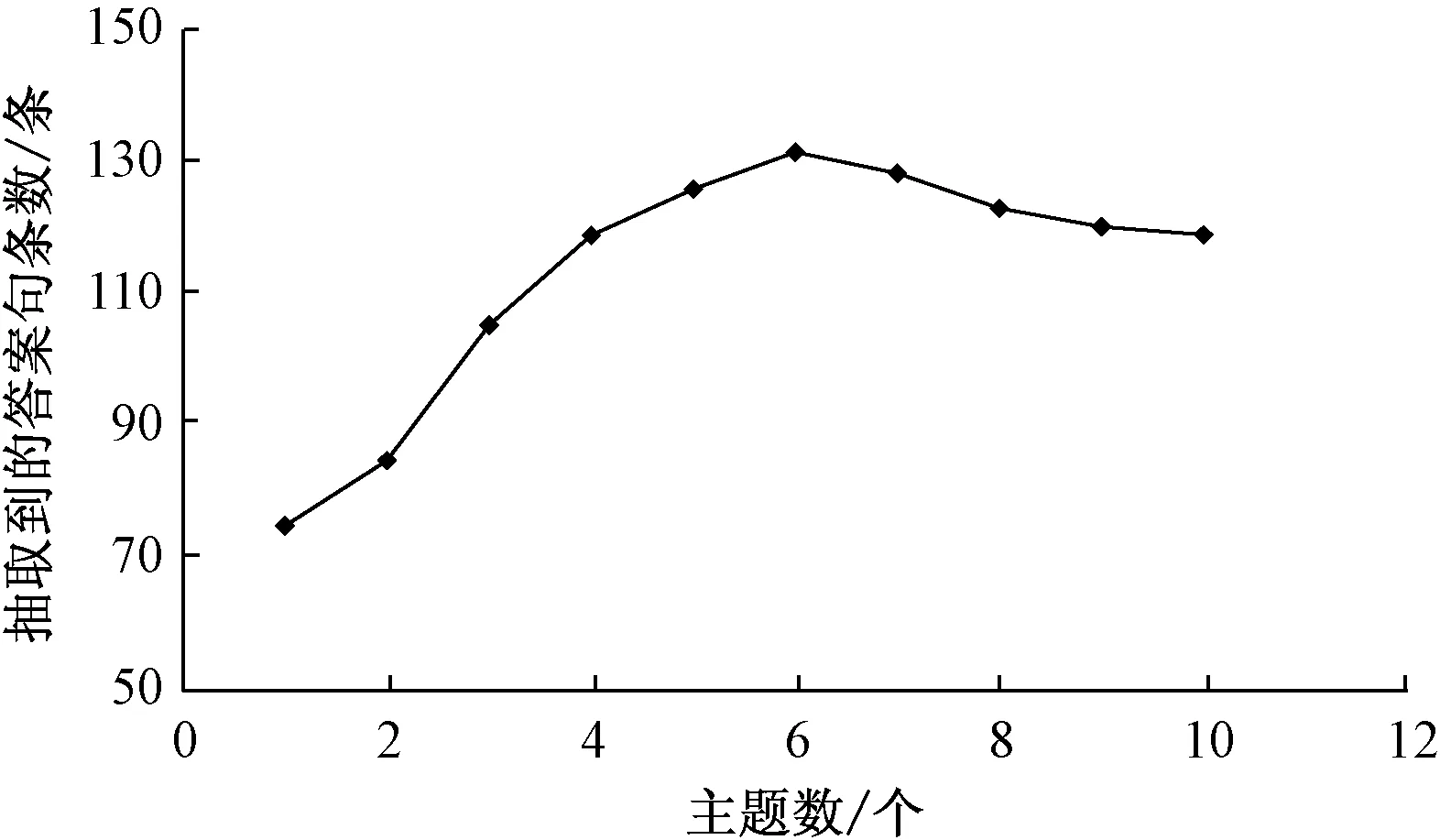
图2 不同主题数对应的抽取答案句结果Fig.2 Results of different topic number for answer extraction
3.2 主题数对答案句抽取的影响
当使用LDA对文本建模时,需要预先设定语料库的主题数,假设每篇文章包含1~10个主题.按照1.1节中所述主题获取方法,以及第2节答案句抽取流程中的步骤1)~4),通过对21篇文章抽取的句子中包含的答案句进行统计,在各个主题下的结果如图2所示.
由图2可知,在21篇语料中,当主题数大于2时,该方法抽取到的句子包含的答案句明显多于主题数为1时的结果.当主题数为6时,抽取到的句子中包含的答案句最多,而主题数再增多之后,结果又逐渐变差.这也说明采用多主题分析散文阅读材料,可以挖掘更多的语义信息,也有助于观点类问题的答案句抽取.
3.3 抽取答案句的方法比较
为了验证本文提出方法的性能,选取下面5种方法与其进行比较.
1) How-net[12]:利用How-net,计算阅读材料中每个句子中的每个词与问题句中的每个词在How-net上的语义距离,加和之后取平均值作为这句话与问题句的相似度;
2) Word2Vec:利用Word2Vec,计算阅读材料中的句子与问题观点的相似度;
3) LDA:利用LDA,计算阅读材料中的句子与问题观点的主题分布相似度;
4) Word2Vec+SVM:在2)的基础上,再使用SVM分类器选择观点句;
5) LDA+Word2Vec:使用LDA方法,选取阅读材料中与问题中观点句主题分布一致的句子,在此基础上,利用Word2Vec计算与问题观点的相似度.
基于How-net词语间的语义相似度计算式为
PrimSim(p1,p2)=η/(d+η),
其中:p1i代表词W1在How-net上的一个义原,词W1有多个义原;d是义原p1和p2在义原层次体系中的路径长度,是一个正整数;η是一个可调节参数.
基于How-net的句子相似度计算式为
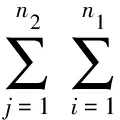
其中:n1,n2分别为句子S1,S2中词的个数,W1i,W2j分别为句子S1,S2中的一个词.
上述SVM分类器的参数采用默认设置,如表3所示.

表3 SVM 参数
为了验证本文方法的性能,利用第2节答案句抽取流程,对21篇文章进行答案句抽取.ε=0.5,抽取句子条数α=3和α=5以及答案句实际条数为λ.8种方法在21篇文章上准确率的平均结果如表4所示.
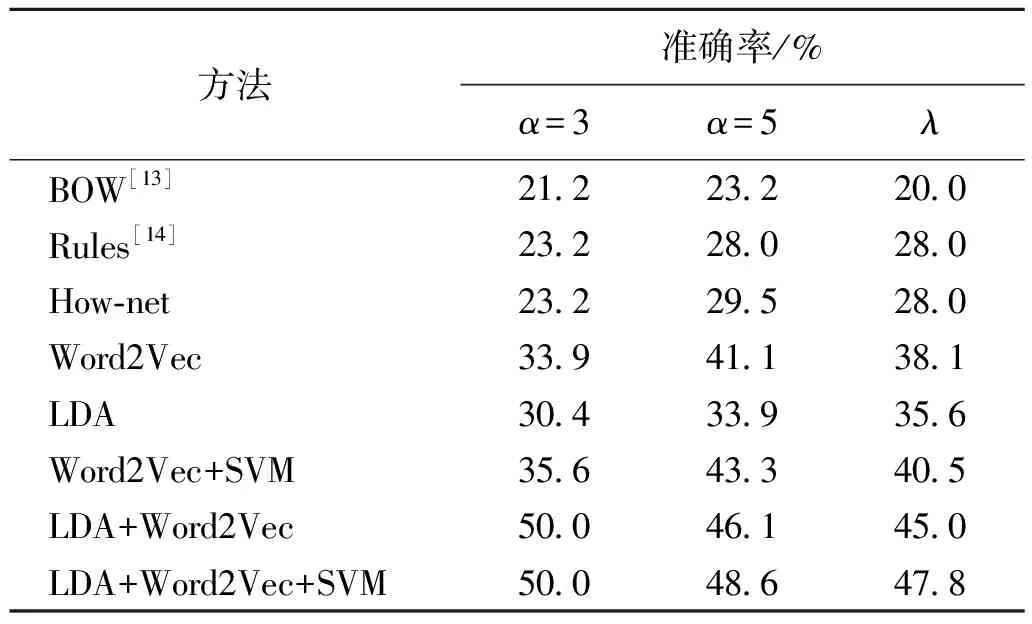
表4 8种方法在观点类问题上的HumSent准确率
由表4可以看出:
1) 词袋BOW[13]模型、规则Rules[14]方法和How-net得到的准确率都较低,主要原因是它们只能找出重复词较多的那些答案句.
2) Word2Vec在训练时,由于有大规模语料作为基础,总体准确率比How-net高出10%左右,比仅利用主题分布相似度计算的LDA方法高出3%左右.
3) 对于Word2Vec+SVM,虽然SVM方法可以对部分非观点句进行排除,但由于答案最后是根据排序后再抽取,与Word2Vec相比总体准确率的提升不明显.
4) 对于LDA+Word2Vec,由于在问题主题分布分析后,再使用词嵌入计算方式,抽取的准确率明显高于仅仅使用How-net、Word2Vec和LDA的方法.说明使用主题分析的方法能有效将答案句排在前面,而且总体准确率比没有使用LDA的3种方法How-net、Word2Vec、Word2Vec+SVM至少高出6%左右.
5) LDA+Word2Vec+SVM整体结果优于How-net、Word2Vec、Word2Vec+SVM和LDA+Word2Vec,说明将三者结合对于解决高考散文的观点类问题更有效.
4 结束语
针对阅读理解观点类题目,本文将LDA主题模型应用于问题答案候选句抽取中.利用观点类题目特点,对问题中的观点句进行了语义角色分析,减少了仅使用词向量进行句子相似度计算时那些常用词语带来的干扰,通过标注一批散文观点句的语料,起到加强筛选散文中观点句的作用.最后通过实验证明,本文利用多种方法结合后可以提升获取答案句的性能.
通过对该方法无法识别部分结果的分析,发现两类情况:一类是对文章的高度概括,答案句与问题涉及到了深度推理;另一类是现有的词嵌入向量表示计算的方式不能很好地刻画阅读材料与问题的相关性.下一步将开展相关性分析以及阅读材料与问题的因果分析来解决这些问题.
[1] VOORHEES E M, TICE D M. Building a question answering test collection[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval. Athens,2000:200-207.
[2] 张志昌, 张宇, 刘挺,等. 开放域问答技术研究进展[J]. 电子学报, 2009, 37(5):1058-1069.
[3] RICHARDSON M, BURGES C J C, RENSHAW E. MCtest: a challenge dataset for the open-domain machine comprehension of text[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.Seattle,2013:193-203.
[4] WESTON J, BORDES A, CHOPRA S, et al. Towards AI-complete question answering: a set of prerequisite toy tasks[J]. Computer science, 2015,16(1):103-129.
[5] HIRSCHMAN L, LIGHT M, BRECK E, et al. Deep read: a reading comprehension system[C]// Meeting of the Association for Computational Linguistics. Stroudsburg,1999:325-332.
[6] 张志昌, 张宇, 刘挺,等.基于话题和修辞识别的阅读理解why型问题回答[J]. 计算机研究与发展, 2011, 48(2):216-223.
[7] 朱艳辉, 张永平, 杜锐,等. 基于LDA与评价对象的微博观点摘要[J]. 郑州大学学报(理学版), 2017, 49(1):45-49.
[8] 郭蓝天, 李扬, 慕德俊,等. 一种基于LDA主题模型的话题发现方法[J]. 西北工业大学学报, 2016, 34(4):698-702.
[9] 陈攀, 杨浩, 吕品,等. 基于LDA模型的文本相似度研究[J]. 计算机技术与发展, 2016, 26(4):82-85.
[10] PALMER M, GILDEA D, KINGSBURY P. The proposition bank: an annotated corpus of semantic roles[J]. Computational linguistics, 2005, 31(1):71-106.
[11] 丁晟春, 孟美任, 李霄,等. 面向中文微博的观点句识别研究[J]. 情报学报, 2014, 33(2):175-182.
[12] 闫红, 李付学, 周云. 基于HowNet句子相似度的计算[J]. 计算机技术与发展, 2015, 25(11):53-57.
[13] HIRSCHMAN L, LIGHT M, BRECK E, et al. Deep read: a reading comprehension system[C]// Meeting of the Association for Computational Linguistics. Stroudsburg,1999:325-332.
[14] RILOFF E, THELEN M. A rule-based question answering system for reading comprehension tests[C] //Association for Computational Linguistics.Washington,2000:13-19.
