基于聚类思想的加权条件熵及属性约简
2018-03-08范会涛
范会涛, 冯 涛
(河北科技大学 理学院 河北 石家庄 050018)
0 引言
粗糙集理论是20世纪80年代提出的一种研究不完整、不确定知识和数据的表达、学习、归纳的理论方法[1].由于粗糙集理论无需提供问题所需处理的数据集合以外的任何先验信息,可充分体现数据的客观性.因此,粗糙集理论被广泛应用于数据挖掘、模式识别、人工智能等领域[2-3].随着现实世界中大量应用数据在结构和形式上日益复杂化和多样化,基于划分和等价关系的经典粗糙集模型已经很难满足大量现实问题的实际需要,于是有些学者将论域的划分扩展为覆盖,将等价关系扩展为非等价关系,提出了一些新的粗糙集模型.
粗糙集利用信息粒对数据集合的近似,描述对象之间的不确定关系.而信息粒化过程在很大程度上取决于对象之间的关系,既可以采用基于等价关系、相似关系、邻域关系的方法对信息进行粒化,也可以利用聚类分析的方法对信息进行粒化,由聚类分析得到的相似类可视为信息粒.在聚类分析的粒化方面,文献[4]提出了一种基于数据聚类的信息粒化方法,文献[5]提出了基于聚类的数值数据信息粒化方法.因此,可以利用聚类分析的粒化结果与粗糙集理论相结合进行知识约简.
属性约简是一种删除不相关和冗余属性的降维方法.基于信息熵、正域、可辨识矩阵、决策成本和知识粒度等已提出了许多启发式属性约简算法[6],文献[7-8]分别提出了基于近似决策熵、强化正域的属性约简方法,文献[9]提出了一种最小测试代价约简的改进算法,文献[10]提出了基于贴近度的协调序决策系统属性约简算法,文献[11]提出了基于α信息熵的模糊粗糙属性约简方法.然而这些方法都把对象平等对待,但是现实生活中对象的权重往往都不相同.文献[12]提出了基于代价敏感的对象权重确定方法,并将该权重用于粗糙集的约简之中,但是该权重确定方法过分依赖专家,使得权重的确定受到较大的主观因素的影响.本文结合粗糙集理论与聚类分析的方法,给出了一种新的对象权重确定方法与加权熵的定义方式,并提出一种相容关系下的属性约简算法.
1 预备知识
首先,在给出新的约简算法之前先回顾一下关于粗糙集和熵的相关知识和已有结论.
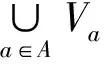
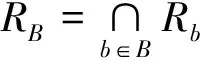
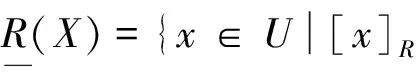
信息熵是粗糙集的一种不确定性度量,度量了信息系统提供的平均信息量的大小.经典粗糙集中信息熵和条件信息熵的定义如下.
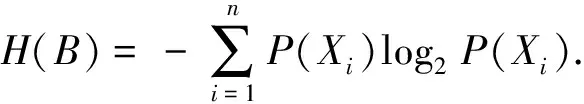
条件信息熵度量了两个属性集之间的依赖程度,即表示知识Φ从知识Ψ中所获得的信息量.
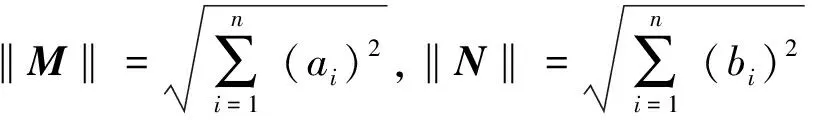
若将余弦相似度应用于信息系统的对象中,由于信息系统中的属性值往往都是正数,若信息系统出现负值时,利用文献[15]中的公式a′=(a-amin)/(amax-amin)对数据进行模糊化处理,将属性值归一化为[0,1]区间上的值后再对对象求余弦相似度.因此,余弦相似度在信息系统中有如下性质.
性质1设S=(U,C∪D,V,f)是一个信息系统,M和N分别表示对象xi和xj在属性集C∪D上的属性值构成的向量,0表示零向量,则对象xi和xj的余弦相似度cos′()满足以下性质:
(1) 0≤cos′(M,N)≤1; (2) cos′(M,M)=1;
(3) cos′(0,N)=0,其中N≠0; (4) cos′(M,N)=cos′(N,M).
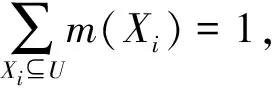
定义5[2]设S=(U,C∪D,V,f)是一个决策信息系统,U为非空有限论域,C为条件属性集,D为决策属性集.记RC={(xi,xj):fl(xi)=fl(xj)(al∈C)},RD={(xi,xj):fd(xi)=fd(xj)(ad∈D)},若RC⊆RD,则称(U,C∪D,V,f)为协调决策信息系统,否则称(U,C∪D,V,f)为不协调决策信息系统.
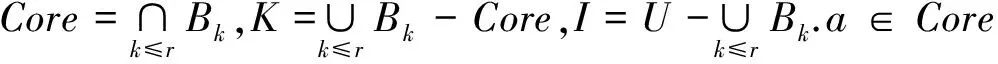
2 一种基于聚类思想的相容关系
经典粗糙集中的关系都是等价关系,但是现实生活中的关系往往都是非等价关系.因此,结合聚类思想给出一种新的相容关系,并利用这种相容关系构造信息粒.在聚类分析中,余弦相似度常常用于衡量两个个体间差异的大小.余弦相似度利用余弦值表示向量的相似程度,两个向量的余弦值越接近1,则两个向量越相似.余弦值等于1,则两个向量相等,可以用聚类分析中的这种想法去构造信息系统中的相似类.但是在粗糙集中不仅要度量两个对象属性值构成的向量的夹角,还要度量它们的模.显然,余弦相似度无法满足度量向量模的要求.例如设对象x1和x2的属性值构成的向量分别为M=(2,4)和N=(3,6),可得M和N的余弦相似度为1,即x1和x2归为一类,但是在粗糙集中,这样的结果显然不符合实际,因此对此相似性度量进行了改进.给出如下新的相似性度量的定义.
定义7设S=(U,A=C∪D,V,f)为一个信息系统,U为非空有限论域,C为条件属性集,D为决策属性集,xi,xj∈U,M和N分别表示对象xi和xj在属性集A下的属性值构成的向量,则对象xi和xj的sim相似度simA(xi,xj)=cos′(M,N)×(1-‖M‖-‖N‖/max{‖M‖,‖N‖}),其中|·|表示绝对值,规定当M=N=0时,‖M‖-‖N‖/max{‖M‖,‖N‖}=0.
性质2在信息系统S=(U,A=C∪D,V,f)中,∀xi,xj,xk∈U,M、N和Q分别表示对象xi、xj和xk在属性集A下的属性值构成的向量,0表示零向量,则sim相似度满足以下性质:
(1) 0≤simA(xi,xj)≤1; (2)simA(xi,xi)=1;
(3)simA(xk,xj)=0,其中Q=0,N≠0; (4)simA(xi,xj)=simA(xj,xi);
(5) 若simA(xi,xj)=1,则必有M=N.
定义8设S=(U,A=C∪D,V,f)为一个信息系统,U为非空有限论域,C为条件属性集,D为决策属性集,A=C∪D的值集是全序集.根据sim相似度定义如下一种新的关系:
∀xi,xj∈U},
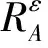
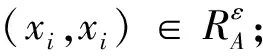
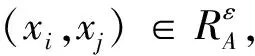
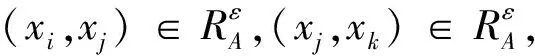
性质4对于任意的X,Y⊆U,sim上、下近似满足以下性质:
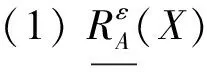

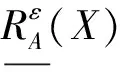

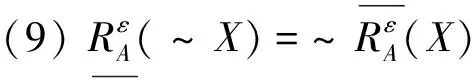
3 基于聚类思想的对象权重确定方法
现有的权重确定方法主要集中在属性权重上,虽然属性权重会对决策和约简产生较大的影响,但在现实生活中对象权重也会对约简结果产生影响.一些学者利用代价敏感和AHP方法在对象权重的确定方法上做出了一些成果,但是这些方法都受到较大的主观因素的影响.因此,利用聚类分析的思想构造二元关系的方法来给出对象权重,从而降低主观因素的影响.
易证m(Xi)满足mass函数的基本性质,因此是一个mass函数.mass函数是2U上的概率分布函数,可以构造出2U上的每个信息粒的一个不确定性度量——粒的权重.
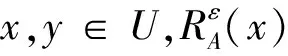
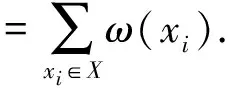
性质5设S=(U,A=C∪D,V,f)是一个信息系统,ω(xi)是对象xi∈U的权重,则ω(xi)满足以下性质:
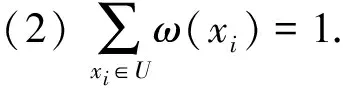
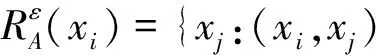
4 基于加权条件信息熵的属性重要度确定方法与约简算法
信息熵是信息论的主要内容之一,它可以对信息量进行量化度量.知识从信息中获得,所以知识也是一种特殊的信息[13].因此,熵理论也可用于粗糙集的研究中.下面给出一种基于对象权重的加权条件熵的定义方式,并提出了基于加权条件熵的属性重要度确定方法和属性约简算法.
性质6由X得到的加权信息熵满足以下性质:
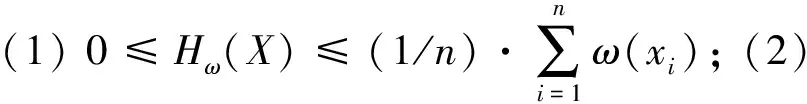
(3)若所有的相容类权重都相同,即ω(X1)=ω(X2)=…=ω(Xn)=ω时,则当Xi/U=1/2时,Hω(X)取得最大值,并且Hω(X)=ω.
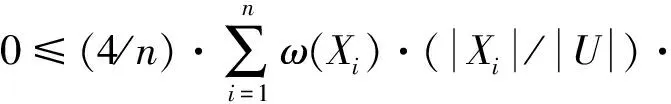
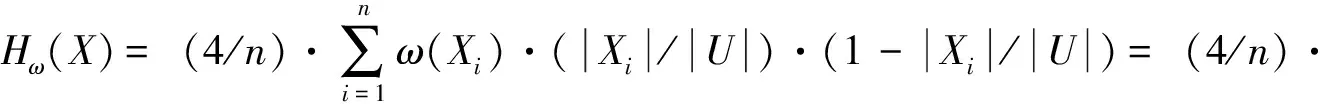
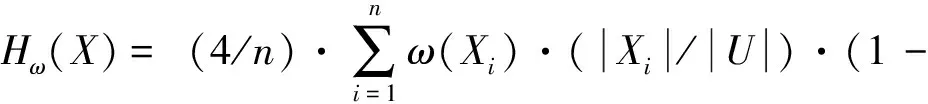
令~Xi表示Xi的补集,由于ω(~Xi)与ω(Xi)不一定相等,因此,Hω(~X)和Hω(X)不一定相等,即加权信息熵不满足对称性.新定义的加权信息熵满足上面几条性质,符合加权信息熵的条件.下面给出相应的加权条件熵的定义.
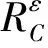
性质7X相对于D的加权条件熵满足以下性质:
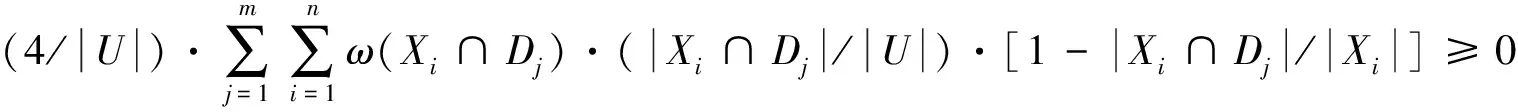
现有的属性约简算法主要是在对象重要度相同的基础上给出的,但是在现实生活中,对象的重要性往往都是不相同的.虽然文献[12]考虑了对象权重对约简的影响,但是其考虑的对象权重需要依赖专家的先验知识得到,增加了主观因素对约简算法的影响.为了降低这种影响,根据聚类分析与粗糙集相结合所得的属性重要度与熵理论给出新的基于加权条件熵的属性约简算法,该算法是一种基于熵不变的约简算法.
定义15设S=(U,C∪D,V,f)是一个信息系统,U为有限非空论域,C为条件属性集,D为决策属性集.若对于B⊆C,有Hω(DB)=Hω(DC),且对于B的任何真子集B′都有Hω(DB′)≠Hω(DC),则称B为C的一个熵约简.
定理1设S=(U,C∪D,V,f)是一个信息系统,U为有限非空论域,C为条件属性集,D为决策属性集,则有
(1) 若S为协调信息系统,则Hω(DC)=0;
(2) 若S为不协调信息系统,则Hω(DC)>0;
(3) 若S是一个协调信息系统,a是决策核心,则有H(DC)=0,Hω(DC-{a})>0;
(4) 若S是一个不协调信息系统,a是核心属性,则有Hω(DC-{a})≠Hω(DC).
定义16对于加权目标信息系统Sω=〈U,W,C·D,V,f〉,U为有限非空论域,C为条件属性集,D为决策属性集,W为权重集合.设B⊂C,则对于任意属性a∈C-B,属性a对属性集B的内部属性重要度为SGF(a,B,D)in=|Hω(DB)-Hω(DB-a)|;属性a对属性集B的外部属性重要度为SGF(a,B,D)out=|Hω(DB)-Hω(DB∪a)|.
基于给出的内部属性重要度和外部属性重要度,提出了两种启发式约简算法,见表1.算法首先选取信息系统的核心属性,然后添加外部属性重要度大的属性,最后再删除多余属性即可得到最终约简.算法1和算法2分别介绍了协调信息系统和不协调信息系统的属性约简算法.
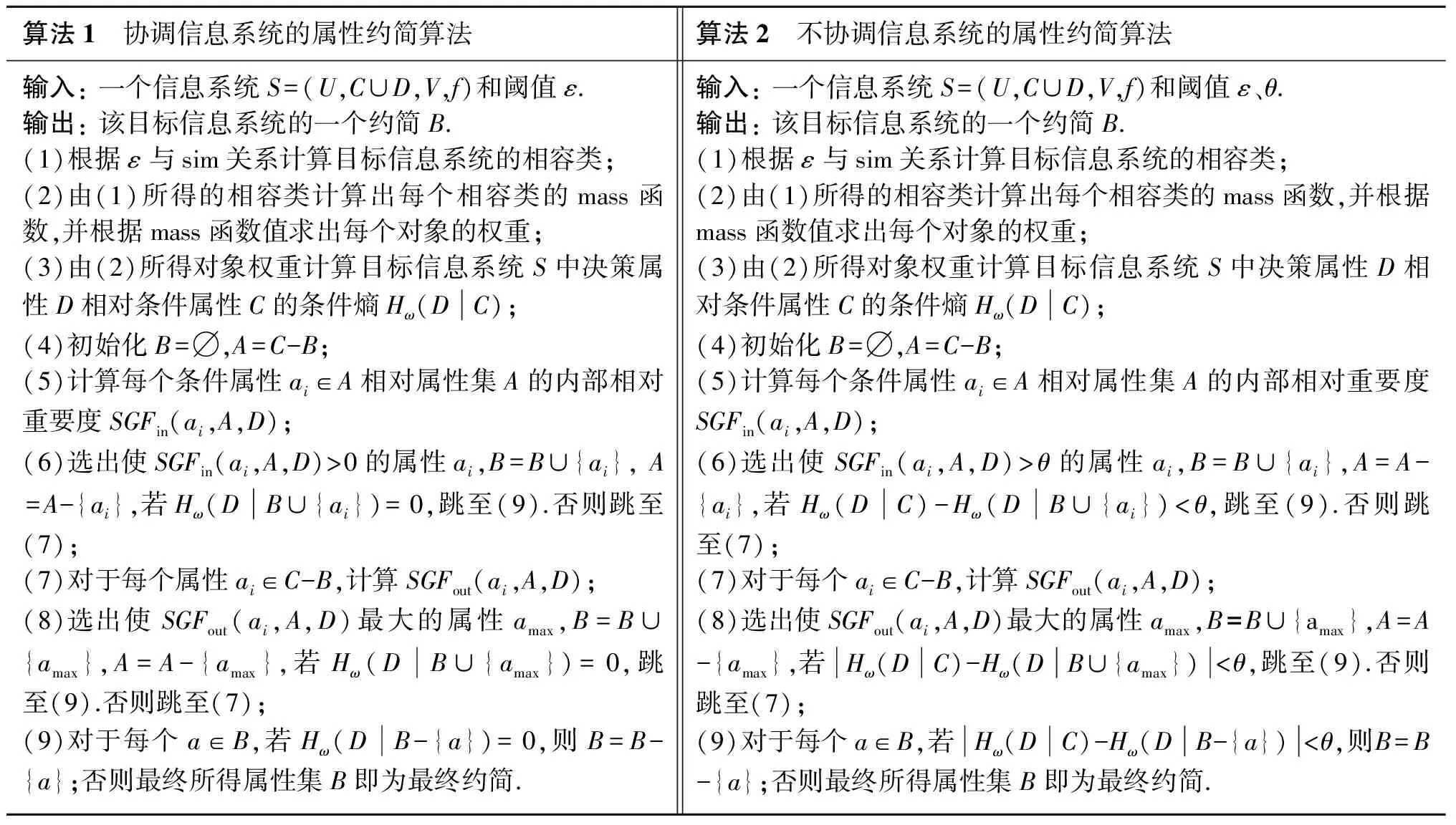
表1 信息系统的属性约简算法Tab.1 Attribute reduction algorithm for information system
例1为了说明算法的合理性,以表2的信息表为例进行仿真计算.
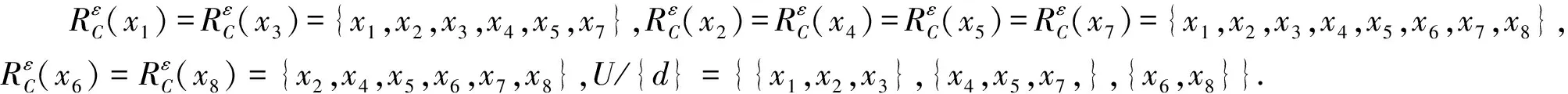
由重要度定义求得a1的内部重要度SGF(a1,B,D)in=|Hω(DB)-Hω(DB-a1)|=0,同理可得a2,a3,a4的内部重要度SGF(a2,B,D)in=0.013 3,SGF(a3,B,D)in=0.124 ,SGF(a4,B,D)in=0,又由于原信息系统是不协调的信息系统,所以根据SGF(ai,B,D)>0.002得RED={a2,a3}.又由于此时满足|Hω(DC)-Hω(DB∪{amax})|<θ,再逐个删除多余属性即得最后约简RED={a2,a3}.
为了验证所提出的算法在大数据中的有效性,从UCI数据库找出几组数据分别与文献[11,17]中的α-FRS算法和FNRS算法进行了对比实验,进行约简之前按照文献[11,17]的方法对有数据缺失的对象进行了删除,并将处理后的数据集描述列于表3中.对几组数据集选取合适的ε与θ值,本文算法与α-FRS算法和FNRS算法的约简结果对比分别列于表4和表5中.数据集Ecoli在不同参数下的约简结果列于表6中.

表2 信息表

表3 数据集描述Tab.3 Description of data sets

表4 α-FRS算法与本文算法约简结果的比较Tab.4 The reduction comparison of α-FRS and the proposed algorithm

表5 FNRS算法与本文算法约简结果的比较Tab.5 The reduction comparison of FNRS and the proposed algorithm
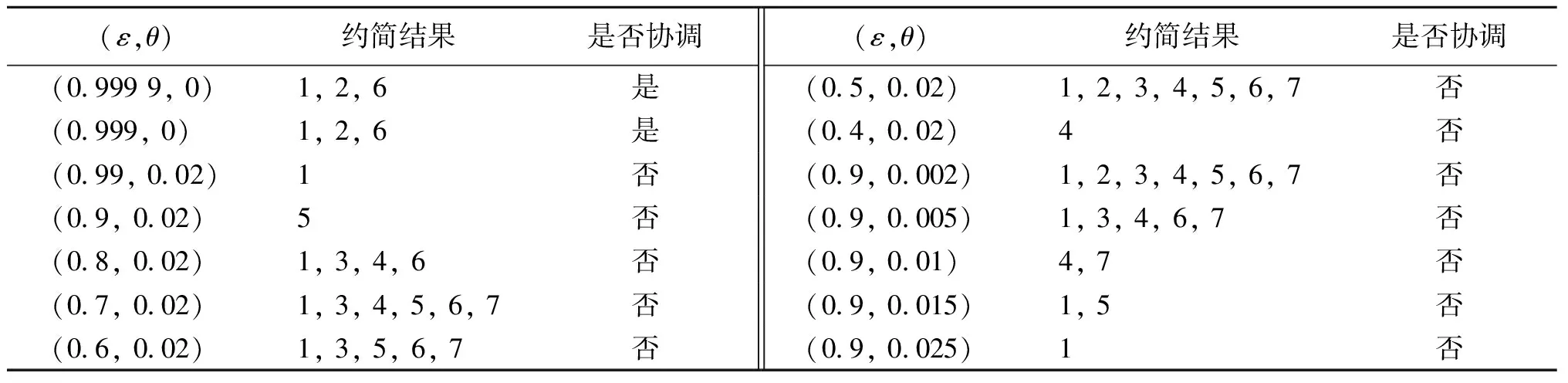
表6 数据集Ecoli在不同参数下的约简结果Tab.6 The reduction with different thresholds on the data of Ecoli
根据表6参数的变化可以看出,随着ε的减小,信息系统会变得不协调,而参数θ的变大会使得约简越来越小.根据专家的经验对数据集设置合适的ε与θ值,就能得到一个合适的约简结果.
5 结束语
将粗糙集理论与聚类分析的方法相结合提出了一种新的对象权重的确定方法,并且将对象权重与熵理论相结合给出了一个新的加权条件熵的定义,同时给出了基于加权条件熵属性重要度的新定义.最后基于此属性重要度给出了属性约简算法,并且用UCI中选取的几组数据集验证了该算法的合理性和有效性.
[1] PAWLAK Z.Rough sets[J].International journal of computer and information sciences,1982,11(5):341-356.
[2] 张文修,仇国芳.基于粗糙集的不确定决策[M].北京:清华大学出版社,2005.
[3] 汤建国,佘堃,祝峰.覆盖粗糙集的技术与方法[M].成都:电子科技大学出版社,2013.
[4] 雷聪聪.一种基于数据聚类的信息粒化方法[D].郑州:郑州大学,2010.
[5] 钱宇华.复杂数据的粒化机理与数据建模[D].太原:山西大学,2011.
[6] JING Y G,LI T R,HUANG J F,et al.An incremental attribute reduction approach based on knowledge granularity under the attribute generalization[J].International journal of approximate reasoning,2016,76: 80-95.
[7] 江峰,王莎莎,杜军威,等.基于近似决策熵的属性约简[J].控制与决策,2015,30(1):65-70.
[8] 史博文,李国和,吴卫江,等.基于强化正域的属性约简方法[J].计算机应用研究,2017,34(1):107-109.
[9] 何华平,陈光建.一种最小测试代价约简的改进算法[J].郑州大学学报(理学版),2015, 47(1):74-77.
[10] 孟慧丽,张倩倩,徐久成.基于贴近度的协调序决策系统属性约简算法[J].郑州大学学报(理学版),2016, 48(3):90-93.
[11] 潘瑞林,李园沁,张洪亮,等.基于α信息熵的模糊粗糙属性约简方法[J].控制与决策,2017,32(2):340-348.
[12] 刘金福,于达仁,胡清华,等.基于加权粗糙集的代价敏感故障诊断方法[J].中国电机工程学报,2007,27(23):93-99.
[13] 于迎春.覆盖粗糙集中基于信息熵的几个定义[J].商业文化,2012(2):344.
[14] 陈大力,沈岩涛,谢槟竹,等.基于余弦相似度模型的最佳教练遴选算法[J].东北大学学报(自然科学版),2014,35(12): 1697-1700.
[15] QIAN Y H,WANG Q,CHENG H H,et al.Fuzzy-rough feature selection accelerator[J].Fuzzy sets and systems,2015,258:61-78.
[16] 张文修,梁怡,徐萍.基于包含度的不确定推理[M].北京:清华大学出版社,2005.
[17] WANG C Z,SHAO M W,HE Q,et al.Feature subset selection based on fuzzy neighborhood rough sets[J].Knowledge-based systems,2016,111:173-179.
