基于Affinity propagation和K-means算法的电力大用户细分方法分析
2018-03-06魏小曼陈星莺景伟强
魏小曼,余 昆,陈星莺,颜 拥,张 爽,景伟强
(1.河海大学 能源与电气学院,南京 211100;2.国网浙江省电力公司 电力科学研究院,杭州 310000)
随着电力市场改革的不断深入,电力大用户在电力市场中的地位日益突出,通过对大用户细分,供电公司可以进一步了解大用户,识别有价值的大用户用电行为和价值特征,从而制定有针对性的服务措施和差异化的营销策略,在有效控制资源分配成本时显著提高供电企业服务水平[1]。
电力大用户的用电量占供电公司售电量的比重大,是供电企业售电利润的最主要来源。电力大用户的价值以及发展潜力是供电企业制定决策和服务措施的重要依据。现有部分文献所提出的用户细分方法依据行业不同,将用户分为工业、商业等类型,该方法简单、高效,但不能有效地为电力公司提供决策依据[2]。而针对服务措施所提出的细分指标则主要针对用户的现有价值和发展潜力[3],却在分析未来发展潜力时忽略了用户近期和长期的发展趋势。对大用户进行定性分析是企业宏观上对大用户进行分类的一种方法,主要是根据决策者的判断来对大用户进行分析,没有严格的论证过程,决断结果片面主观,容易造成较大的决策偏差。定量分析方法则是应用智能算法根据用户属性特征值将用户进行聚类,文献[4]应用经典的K-means算法对大用户进行聚类,但K-means难以确定聚类数K,对孤立点敏感,并基于梯度下降搜索时容易陷入局部最优[5];为了改善这一问题,文献[6]引入了凝聚层次聚类算法,但当数据规模较大时,时间复杂度和空间复杂度很高,难以应用;文献[7]则是将遗传算法引入了K-means聚类,但容易出现过早收敛的现象[8];文献[9]则在K-means的基础上引入了PSO,但精度较低,容易发散。K-means聚类算法总是随机选择初始中心,然后进行迭代调整,直到不再发生明显的变化,聚类的结果往往会受到初始聚类点选择的影响[10—11]。与K-means聚类方法相比,对于大规模数据集,AP是一种快速、有效的聚类方法,它有很多优势,不需要事先指定聚类的个数,对初值的选取不敏感,对距离矩阵的对称性没有要求,是一种确定性的聚类算法,多次独立运行的聚类结果一般都十分稳定[12—13]。
考虑到工业用户的用电量大,消耗电能成本高,本文所研究的电力大用户对象主要为工业大用户。首先,本文在已有指标的基础上从2个角度提出了基于大用户未来发展潜力的细分指标,不仅考虑大用户的现有价值,也能帮助供电企业分析大用户未来为供电企业带来的价值。基于提出的细分指标采用AP和K-means聚类算法对大用户进行细分,引入的算法避免K-means算法需提前确定聚类数目和初始聚类中心,以及容易陷入局部最优而过早收敛的问题。
1 考虑大用户价值的细分指标
1.1 大用户细分需考虑的因素
大用户细分理论于20世纪50年代中期由美国学者温德尔史密斯提出,指企业在特定的市场竞争中,根据顾客的属性如对商品的爱好、需求以及行为特征等对大用户进行分类,并有针对性地对其提供产品、服务或者相应的销售模式。细分之后,每一类用户群会在某一方面有着相同的特性,而不同的细分群体则差异性明显。
对供电企业来说,用户细分这一概念发展尚不成熟,以往对于用电用户的服务仅仅是根据经验进行分类,没有科学性地、系统的分类体系,这也为电网开展差异性的服务造成了困扰。大用户细分使得企业根据顾客需求有效参与市场竞争,从而获取最大的利润。由于大用户的特征多样性,如出现大用户用电量高但信用得分低,或者用电量低但用电增长率高等不同的特征,对于供电企业来说,综合考虑大用户的用电量、信用评价得分以及用电增长率这几个因素,可以从多个角度来分析大用户对于供电企业的重要程度。
通过多指标下的电力大用户细分,供电企业可从多方面因素分析大用户的用电特征以及未来发展趋势。通过用电量这一角度分析用户的现有价值;通过用户信用得分剖析用户的价值以及未来的发展方向;通过用户的用电增长率分析用户的近期发展趋势以及长期的发展趋势。从而做到全面分析大用户对于供电企业利润增长的作用。通过对大用户价值等级分类,供电企业可以有效降低服务成本,更好地识别不同的大用户对企业的供电需求以及大用户能为企业带来的利润价值,从而指导企业合理处理企业与大用户之间的关系,以达到提高顾客满意度和忠诚度的目的,吸引大量长期大用户。
1.2 大用户细分指标及其计算方法
只有合理的大用户细分指标才能够科学地对大用户进行分类,从而得到对供电企业来说价值大小的用户级别,帮助供电企业判定用户的作用,制定有价值的营销策略,提高对企业极为重要的电力大用户的满意度,从而提高企业的利润。文献[14]—文献[15]提出的细分指标主要包括电压等级、低谷利用率、用电负荷率等用户用电特征:电耗占能耗比重、购电量比重;经营状况:企业总资产、购电量比率等电能利用情况,电费回收率、合同履约率等信用状况,年用电增长率等发展潜力。这些指标是针对商业、工业等不同性质的用户提出的,指标多、有冗余且容易淹没用户的某些特征。本文考虑到工业大用户的发展趋势和潜在价值,根据此类用户的特点针对前人所提出的细分指标进行简化和补充,剔除部分不适用于工业大用户的指标,在发展潜力部分增加工业大用户的近期用电增长率和长期用电增长率指标。总的来说,本文针对电力大用户工业用户的分类目标,建立如下的细分指标。
(1)当前价值
对于供电企业而言,用户的当前价值为用户为供电企业创造的利润总和,即供电企业对大用户的售电量所创造的电费营业总额。相对于商业、医院、政府、学校等用户而言,工业用户的用电量大得多,因此本文主要考虑工业用户的当前价值,该价值主要体现为用电量,本文采用平价时段内用户的月平均用电量来表征,如式(1)所示

式中:Em为月平均用电量;Ey为年总用电量。
(2)大用户信用
如果用户的信用低,即使其用电量大,对供电企业来说也不是有价值的用户,因此还需要对用户信用进行评价,本文采用大用户信用得分来表征。首先通过对大用户的基础信息,即对大用户的安全用电情况、电费缴纳情况及用电基础信息的准确完整情况这3个指标的大量历史碎片化数据进行系统性地清洗与分析,挖掘数据中蕴藏的行为模式以及信用特征,捕捉历史信息和信用表现之间的关系,通过对规范化后的数据进行加权平均处理,最后得到一个总的信用得分值。以该信用得分来综合评估大用户历史行为上的信用表现,在一定程度上可以作为对用户当前价值的判断,也可以作为大用户未来信用表现的预测。信用得分如式(2)

式中:C为用户信用得分;Es为用户安全用电情况;Ep为电费缴纳情况;Ia为用电基础信息的准确完整情况;a1、a2、a3为各项信息的比重,各指标权重信息是基于电力业务专家打分的层析分析法确定。安全用电考察客户是否存在违约用电、窃电,存在的种类(严重性)及次数;电费缴纳是否及时、足额;登记在案的基础信息的有效性及登记的项数等。
(3)发展潜力
发展潜力主要通过用电增长率这一指标进行表征,现有文献所提出的用电量增长率是指年用电增长率,但年用电增长率只能挖掘出用户长远的发展趋势,却无法分析用户的近期发展趋势。因此,本文采用同比用电增长率和环比用电增长率这2个指标来分析用户发展潜力。其中,环比变化用于表征用户的近期发展趋势,同比变化则用于表征用户的长期发展趋势。计算方法如下

式中:Se为用电量环比变化;为大用户上个月用电量;为本月用电量。
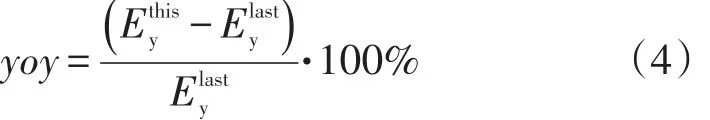
综上所述,本文所确定的细分指标如表1所示。

表1 大用户细分指标
2 综合AP和K-means的用户细分方法
选定上述的大用户细分指标基础上,本文通过结合AP算法和K-means算法对大用户进行聚类分析,建立出不同价值的大用户细分模型。
2.1 聚类算法
(1)K-means算法的改进
由于传统的K-means算法不能有效处理簇的密度不均且大小相差较大的数据集,本文将簇内的标准差与欧式距离Jc(I)按一定的比例进行加权处理,重新分配簇,将数据分配给离加权距离最小的中心点所在的簇,如式(5)所示
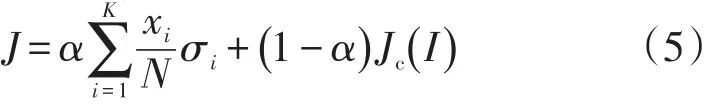
式中:N为数据集的总个数;K为聚类的个数;σi为第i个聚类的标准差;xi为第i个聚类的个数;α为松弛参数,密度较小时,设置为[0.6,1]之间,此时标准差占主导地位,若密度较大,设置在[0.1,0.5]之间,此时,欧式距离占据主要地位。
(2)AP算法
在AP算法中,以s( )i,k表示xk有多大的可能性作为xi的聚类中心,s( )i,k的值越大,这个点成为聚类中心的可能性也就越大,称为参考度p,p的大小影响聚类的数量,聚类数目K与参考度p的相对变化关系可参考文献[16]。若认为任意数据都可作为聚类中心,则p取相同的值;若取数据相似度的均值作为p的值,能得到中等数量的聚类个数。
2.2 AP和K-means混合算法
首先对本文所用的数据进行预处理,将数据执行缺失值、异常值删除以及归一化处理。将收集到的数据组成一个矩阵xm×n,其中m为电力用户数,n为确定的评价指标数,则xij为第i个用户在第 j个评价指标上的值。如果在矩阵xm×n中存在缺失值,则删除xm×n中缺失值所在行,对应矩阵维数变为。xj为所有用户在第 j个指标上的数据集合。xj的平均值为 μj,标准差为σj。定义若存在用户i,使得| |xij-μj>3σj,则对应的用户 i的数据为异常值,并将用户数据矩阵xm×n中的第i行予以删除。
将数据进行缺失值以及异常值删除后,再进行归一化处理,归一化处理如式(6)

式中:xij、yij分别为电力用户i在指标 j变换前后的数据;xjmin、xjmax分别为数据集合xj中的最小值与最大值。经过归一化处理,每个对应指标下用户数据都被映射到对应区间[0,1],使最后的聚类指标数据量纲得到了统一。
首先使用AP聚类算法对数据进行处理,输入大用户的用电量、信用得分以及用电增长率中的3个或4个指标,利用AP算法求的初始聚类中心以及初始聚类数目K。再用AP算法所求的的初始聚类中心以及聚类数目K为K-means聚类寻找聚类初值。首先对用电量、信用得分以及用电量同比增长率进行聚类分析,结果得到初始聚类数为K。采用2种算法进行聚类,避免了K-means需提前人为设定初始聚类数和聚类中心的麻烦,也避免了可能出现的局部最优的情况。
本文综合AP和K-means算法后,对电力大用户进行聚a类的步骤如下:
(1)输入经过预处理以后的用电量、信用得分、用电增长率等数据;
(2)利用AP聚类算法求得初始聚类数目K及对应的聚类中心,并将其作为K-means聚类的初值;
(3)根据距离最近原则确定第一次的聚类结果,即依次计算各个点距初始中心的距离,并给予距离重新分配簇;
(4)重新确定聚类中心,重新计算每个聚类的均值并确定新的聚类中心点;
(6)输出K个聚类集合。
3 算例分析
本文对于大用户的细分首先采用AP算法寻找初始聚类中心和聚类数,然后作为K-means算法的初值对电力大用户进行聚类分析,选用浙江某地区200户大用户2016年月平均用电量,用电增长率选用2017年5月份对比2017年4月份的用电量环比变化,2017年5月份对比2016年5月份的用电量同比变化。
3.1 初始数据分布
分别使用同比增长率、用户信用得分以及用电量和环比增长率对大用户进行细分,三维数据的初始分布情况分别如图1、2所示。
图1、2分别展示了在未进行聚类之前,同比增长率、信用得分与用电量以及环比增长率、信用得分与用电量的数据分布情况,由于四维数据难以用图形展示,所以本文仅展示三维数据图。
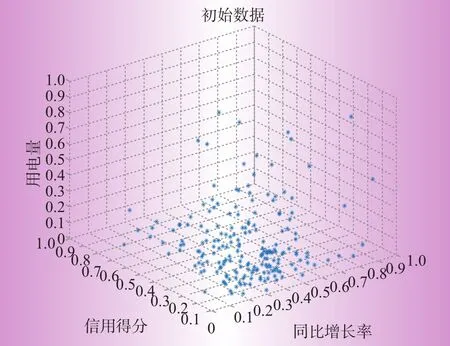
图1 同比、信用、用电量数据分布
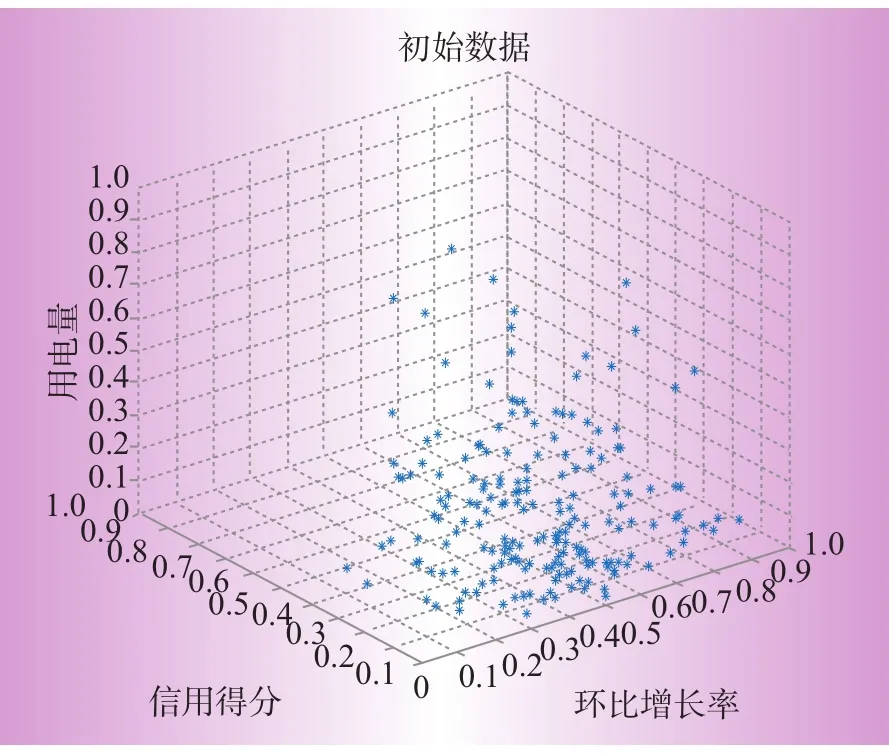
图2 环比、信用、用电量数据分布
3.2 初始聚类结果分析
通过使用AP聚类算法对数据进行处理,自行输出初始聚类中心以及初始聚类数目,并将此作为K-means聚类的初始值输入。对电力大用户的同比增长率、环比增长率、信用得分以及用电量进行AP聚类后分为8类,所得聚类中心结果如表2所示。

表2 同比、环比增长率、信用得分、用电量初始聚类中心
将AP聚类后的聚类结果(即聚类中心以及聚类数目)作为K-means聚类分析的初值,使得在K-means聚类时不用自己指定初始聚类中心以及聚类数目,减少了K-means聚类时的迭代次数。
3.3 K-means聚类分析
输入AP聚类所得的初始聚类中心作为K-means的初值,对电力大用户的同比增长率、环比增长率、信用得分以及用电量利用K-means聚类算法进行分析,形成的四维图形两两映射在平面图上,如图3所示。
对于环比增长率、同比增长率、信用得分以及用电量四维数据聚类结果如图3所示,所得聚类中心如表3所示。
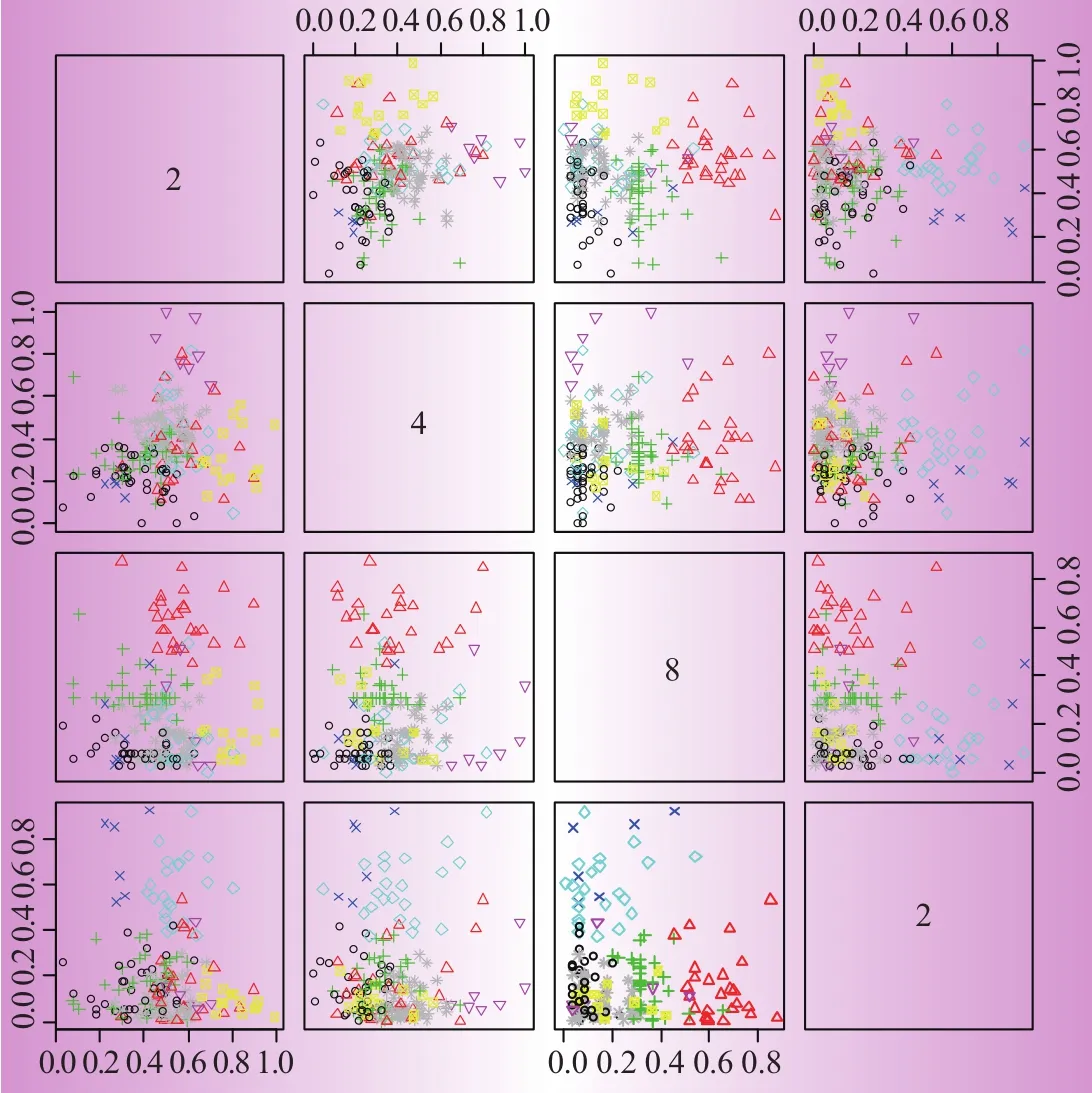
图3 环比、同比、信用、用电量聚类结果

表3 环比、同比增长率、信用得分、用电量最终聚类中心
由表3可见,经过AP和K-means 2种算法的聚类后,本文将电力大用户聚为8个用户特征群,通过分析8个特征群大用户的现有价值高低以及发展趋势和价值潜力,将大用户按照价值等级分成了4类,大用户细分群体特征如表4所示。

表4 大用户细分群体特征
通过对本文提出的几个细分指标聚类,最终将电力工业大用户聚为8个特征群。分析现有价值、信用得分以及发展潜力对于供电企业利润的影响,最终按大用户对于供电企业的价值大小分为4类,分别为低价值用户、一般用户、重要保持用户以及重要发展用户。重要用户用电量增涨趋势显著,未来一定时间内会给供电公司带来更多的利润,因此针对这一类用户,供电公司应根据其电量的增长趋势,制定适宜的售电合同,实现双方企业共赢。一般用户企业共有107户,这类用户用电量基本稳定,供电公司应维持当前营销政策,保持与电力大用户友好合作关系。针对低价值大用户,供电公司首先应履行义务保证用户供电,其次在制定售电合同上,应考虑用户信誉度,制定相应奖惩机制,合理引导大用户用电,使电力市场走上良性发展态势。
4 结束语
电力大用户是供电企业的重要的用户,针对大用户的价值视角,首先从现有指标中修改并提取出适用于电力大用户的关键细分指标,同时,考虑电力大用户近期及长期的电费增长率,提出既能挖掘出大用户的现有价值,又能发掘出大用户未来发展趋势以及发展潜力的细分指标;然后根据细分指标,采用AP与K-means相结合的算法对电力大用户进行细分,解决了K-means算法需提前指定初始聚类中心以及聚类数目的盲目性,同时也避免了K-means聚类算法容易陷入局部最优等缺点;最后通过算例分析,将电力大用户聚为8个特征群,并按价值大小划分为4类,验证了用户细分的可行性,并为供电企业提出了相应的服务措施:供电企业可舍弃低价值用户,对于重要发展用户进行重点服务和督促,提高用户的信用得分,对于重要保持用户则保证优质的服务,提高用户满意度和忠诚度。D
[1] 宋才华,蓝源娟,范婷,等.供电企业大用户细分模型研究[J].现代电子技术,2014(2):91-94.
[2] 任秀萍,姚蕊,李贞,等.实行分类服务满足工商客户用电需求[J].科技与企业,2016(3):56-56.
[3] 张晓春,倪红芳,李娜.基于数据挖掘的供电企业客户细分方法及模型研究[J].科技与管理,2013,15(6):104-109.
[4] 王扶东,马玉芳.基于数据挖掘的大用户细分方法的研究[J].计算机工程与应用,2011,47(4):215-218.
[5] 傅涛,孙亚民.基于PSO的K-means算法及其在网络入侵检测中的应用[J].计算机科学,2011,38(5):54-55.
[6] 王虹,孙红.基于混合聚类算法的大用户细分策略研究[J].电子科技,2016,29(1):29-32.
[7] Maulik U,Bandyopadhyay S,Mukhopadhyay A.Multiobjective Genetic Algorithm-Based Fuzzy Clustering[M]//Multiobjective Genetic Algorithms for Clustering.Springer Berlin Heidelberg,2011:89-121.
[8] 刘春晓,张翠芳.基于SOM和PSO的聚类组合算法[J].通信技术,2010,43(1):208-209.
[9] 李英,吴圆圆,宁福锦.基于PSO的K-means改进算法在证券大用户细分中的应用[J].现代图书情报技术,2010,26(z1):88-94.
[10] 赵宪佳,王立宏.近邻传播半监督聚类算法的分析与改进[J].计算机工程与应用,2010,46(36):168-170.
[11] 刘晓勇,付辉.一种快速AP聚类算法[J].山东大学学报(工学版),2011,41(4):20-23.
[12] AnqiBI,Wang S.TransferAffinity Propagation Clustering Algorithm Based on Kullback-Leiber Distance[J].Journal of Electronics&Information Technology,2016.
[13] Hang W,Chung F L,Wang S.Transfer affinity propagation-based clustering[J].Information Sciences,2016,(348):337-356.
[14] 卢海明.电力客户细分及增值服务系统研究[D].广州:广东工业大学,2016.
[15] 王春叶.基于数据挖掘的电力客户细分研究[D].保定:华北电力大学,2009.
[16] 黄亚萍.基于聚类分析的电子商务客户细分系统的设计与实现[D].镇江:江苏科技大学,2016.
