基于残差的优化卷积神经网络服装分类算法
2018-03-06张振焕周彩兰
张振焕,周彩兰,梁 媛
(武汉理工大学计算机学院,湖北 武汉 430070)
1 引言
随着智能手机和平板电脑的迅速普及,移动互联网飞速发展,近几年网络购物作为一种新兴的商务模式,以其廉价、便捷的特点占据了极大的市场,并广泛地被大众所接受。服装电子商务的迅猛发展也标志着服装商务新模式的出现。人们不再局限于时间和地点,通过一部联网的手机就能轻松获得想要的商品。为了使消费者能快速准确地搜索到自己想要的服饰,如今购物网站如淘宝、京东、天猫商城主要通过图像及文本标注的方式描述商品信息,用户通过在搜索栏中输入关键字获取商品链接。然而,当用户需求商品的周边信息不明确时,这种基于关键字文本的检索方式有时很难获取用户的真实需求,而且随着每天大量新图像的产生,需要消耗大量人力物力来对图像进行精准的文本标注。同时,由于不同人对同一幅图像可能产生不同的理解,在对图像进行文本标注时,会产生主观性和不确定性,进而影响检索结果。
针对服装图像的检索,研究者们提出了基于图像内容的服装分类和检索算法。传统的服装识别分类技术主要借助数字图像处理、模式识别的方法,通过对图像检测分割、特征提取等操作,基本上都是基于底层的视觉特征或人工设计的视觉特征来实现服装的分类。但是,由于服装图像包含非常多的细分类,也存在非常多的视觉变化,包括光照、形变、拍摄视角、镜头缩放尺度、背景影响等等,使得人工设计特征越来越难以满足实际分类的需求。
随着深度学习的兴起,卷积神经网络在人脸识别、 图像分类与物体检测的方向上都取得了很多重要的进展,也为深度学习在服装分类中的应用奠定了坚实的基础。近两年,研究者们就把深度学习与服装分类结合,并取得了不错的效果。Kiapour等人[1]把Street-to-Shop的服装检索场景形式化为Crossdomain的商品相似度学习问题,并设计了一种用于特定类别的相似度计算的网络参数学习方式。但是,此文只基于离线卷积神经网络CNN(Convolutional Neural Network)特征学习相似度,并没有进行端到端模型的探索。与上文不同,Huang等人[2]在处理街拍场景(Street Scenario)与电商场景(Shopping Scenario)服装图像之间的检索问题时,提出了一种端到端的双路神经网络模型DARN(Dual Attribute-aware Ranking Network)来学习深度特征。但是,在面对更细粒度属性的分类时,该模型的分类能力还显不足。来自香港中文大学的Liu等人[3]收集了一个规模更大且语义标注更全面的服装数据集DeepFashion,还提出了一种FashionNet,融合了大类、属性、服装ID以及关键点四种监督信息来进行服装特征学习。厉智等人[4]提出基于深度卷积神经网络的改进服装图像分类检索算法,采用深度卷积神经网络从数据库中自动学习服装的类别特征并建立哈希索引,实现服装图像的高效分类和快速索引。
服装分类是服装检测、服饰检索的基本工作,上述研究工作都使用深度卷积神经网络学习服装分类,从网络低层开始逐层学习服装图像特征的分布,并在网络的全连接层将特征图抽象为多维的特征向量,最终将特征向量输入分类器计算每个类别的得分,得分最高的输出即被视为该图像的分类结果。在选择用于服装分类的深度卷积网络时,不仅需要考虑分类的准确率,还需要考虑图片处理的实时性。如今深度卷积网络的改进朝着通过增加用于提取特征的卷积层的数量来提升模型的分类能力发展。但是,深度卷积网络存在以下两个问题:(1)随着卷积网络深度的加深,训练网络时由于会出现梯度消失或梯度爆炸的问题而使训练变得困难[5,6]。随着深度残差网络[7]的提出,通过给每个卷积层增加一个从输入直接到达输出的恒等映射连接,使得反向传播时需要计算的梯度大于或等于1,不会随着逐层传播而变得很小很小,从而解决深层网络训练时梯度消失的问题。(2)随着网络模型结构变得复杂,网络模型的参数变多,虽然这样做可以提升准确率,但是随之带来的便是更大的计算量和更高的内存需求,这会极大地影响模型对输入图像的处理速度,当需要实时处理巨量的用户输入图像时,就需要计算能力更强的GPU服务器作支撑来达到实时处理图像的要求。因此,本文通过改进网络结构来加快网络处理图像时的计算速度,以达到对输入图像更快的准确分类。
2 基于残差的优化卷积神经网络服装分类算法
从2010年至今,每年举办的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像分类比赛是评估图像分类算法的一个重要赛事。其中,2010年和2011年的获胜队伍都是采用的传统图像分类算法,主要使用SIFT(Scale Invariant Feature Transform)、LBP(Local Binary Pattern)[8]等算法来手动提取特征,再将提取的特征用于训练SVM(Support Vector Machine)等分类器进行分类。直到2012年的比赛中,Krizhevsky等人[9]提出的AlexNet首次将深度学习应用于大规模图像分类,并取得了16.4%的错误率。该错误率比使用传统算法的第2名的参赛队伍低了大约10%。之后卷积网络结构朝着网络层数更深、卷积层个数更多的方向改进。比如16层的VGGNet[10]、28层的GoogLeNet[11]以及之后深度残差网络的出现,都表明了层数更深的网络模型在图像分类任务上取得了更好的分类效果。目前在对用于学习服装图像特征的深度卷积网络的选择上,大多数研究者使用的是AlexNet和VGGNet这两种网络,其中文献[1,2,4]使用了AlexNet,文献[3]使用了VGGNet。上述文献中用于分类的服装类别在15~25类不等,而在解决更多类别的服装分类问题时,比如DeepFashion服装数据集拥有46个服装类别,由于AlexNet和VGGNet都属于层数较少的网络,网络学习能力和表征能力都受到网络层数的限制。因此,本文提出了基于残差的优化深度卷积神经网络,用于更多类别的服装分类。
2.1 基于残差的连续小滤波器结构
本文提出了一种新的基于残差的优化卷积神经网络服装分类模型,该网络的主要组成部分如图1所示,由两个小滤波器(3*3的卷积核大小)的连续卷积层和从输入到输出的直接连接构成,其中x为网络输入层或上一层的输出,经过非线性卷积层得到f(x),与自身的恒等映射相加构成该结构的输出y。
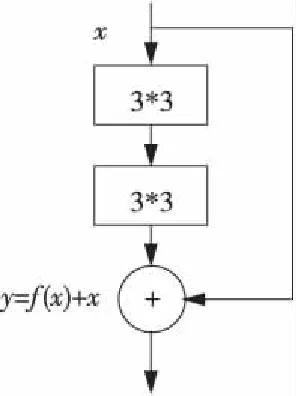
Figure 1 Continuous small filter structure based on residual图1 基于残差的连续小滤波器结构
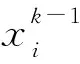
(1)
本文采用两个连续的滤波器大小为3*3的卷积层,使得图像经过两次非线性激活函数计算,增强了模型对于复杂程度和非线性程度的表达能力和泛化能力。因为考虑到使用更多连续的滤波器组合会使得模型层数增多,参数更多,当数据集不大时训练容易出现过拟合的情况;同时会增加模型处理图像的时间,因此选择使用两个连续的小滤波器卷积层结构。
卷积神经网络在每次训练完一小批量的图像之后,代价函数会计算预测结果与真实值的距离并得到一个用于反向传播时从输出层开始逐层往前更新网络权重的损失值。设loss为代价函数求得的损失值,代价函数为l(·),则loss的计算公式如下:
loss=l(on)
(2)
其中,on是网络第n层的输出特征图,in是第n层的输入也是第n-1层的输出,每一层输出特征图的计算公式如下:
on=fn(in,wn,bn)
(3)
随着卷积神经网络的不断加深,反向传播时用于更新权重的梯度会逐层变小,导致无法对网络前面几层的权重进行调整。公式(4)所示为反向传播时对网络第一层求偏导数的梯度计算公式:
(4)
从公式(4)可以看出,当卷积神经网络层数很多时,通过反向传播计算得到的浅层梯度已经很小很小,几乎无法对浅层网络权值进行更新,进而减弱了浅层网络的学习能力。
如图1所示,残差连接是一种快速连接[12],直接跨越一层或多层,它将输入通过恒等映射转换成输出。此时每一层的梯度计算公式如下:
(5)
在网络中加入残差连接,可以使得梯度在反向传播时永远大于或等于1,解决了深层网络训练困难的问题。
2.2 残差网络中的激活层
在卷积神经网络中加入激活函数,可以提升网络的非线性建模能力。如果没有激活函数,那么网络仅能够表达线性映射,即使网络有很多卷积层,整个网络和单层神经网络也是等价的,因此在网络中加入激活函数是很有必要的。本文采用文献[13]中提出的线性校正单元ReLU(Rectified Linear Units)f(x)=max(0,x)作为激活函数。ReLU函数能够在x>0时保持梯度不衰减,从而缓解梯度消失问题,与传统激活函数sigmoid、tanh相比可以更快地达到相同的训练误差和更高的准确率。
深度卷积神经网络的训练,实际上是一个学习数据分布的过程。训练网络时每一层的权重都在发生变化。网络浅层权重更新时,该层的输出特征图也随之发生变化,导致下一层的权重需要重新学习这个新的数据分布,进而会影响之后每一层的权重更新。由于每一层需要的学习率不一样,在训练网络时通常要使用较小的学习率才能保证代价函数的损失值有所下降,这会影响网络的训练速度。而本文加入批量归一化(batch normalization)[14]算法,先对每一层的输入数据做一个归一化处理(归一化为均值为0,标准差为1),使得数据分布稳定,在训练时就可以使用较大的学习率,从而加快网络收敛,提高训练速度。
如图2所示为一般的“卷积层+BN层+ReLU层”的排序顺序,BN层和ReLU层都会放在卷积层之后。
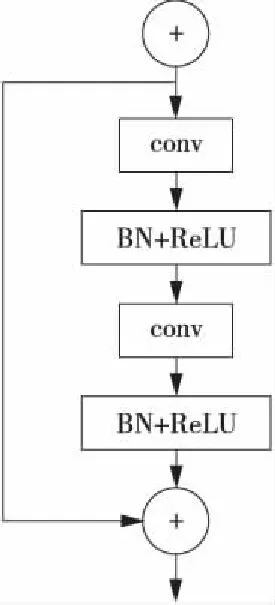
Figure 2 Order in the traditional network图2 传统网络中的排列顺序
这样的排序顺序在残差网络中存在以下两个问题:(1)残差模块的输入分成两个支路向深层传递,而右边非线性支路的输入特征图直接经过卷积层,并未经过BN层的归一化处理,这样便失去了引入BN层的意义;(2)由于ReLU函数的恒正性,非线性支路的最后输出总是非负的,因此随着层数的加深,输入会逐层叠加变大,这样很可能会影响网络的表征能力。本文针对上述存在的两个问题,提出了一种新的用于非线性支路中的“BN层+ReLU层+卷积层”的排列顺序,如图3所示,图中虚线框内的网络结构其实还是和图2所示的传统结构一样,本文提出的排列方法很好地将传统方法应用到残差网络中,既保持了左边支路的恒等映射,又保证了右边支路具有非线性学习能力,且加快了网络训练速度。
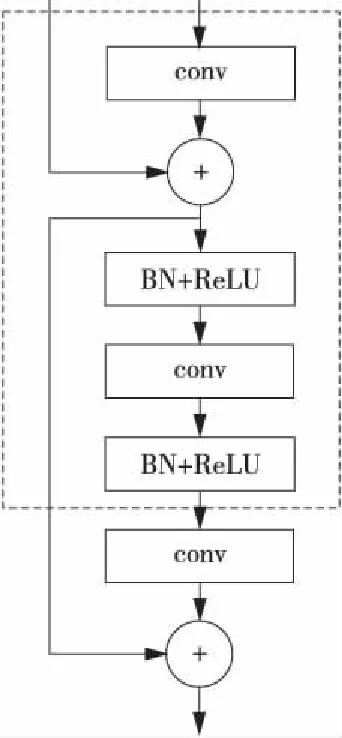
Figure 3 Order in the residual network图3 残差网络中的排列顺序
2.3 并行池化结构
卷积网络由卷积层和池化层组成,网络通过池化来降低卷积层输出的特征向量,同时改善分类结果,使模型不易出现过拟合。常见的两种池化层为平均池化层和最大池化层。平均池化层的作用是指在池化过程中,对指定的池化域内所有值求和并提取其平均数作为子采样特征图中的值;最大池化层则是提取指定的池化域内的最大值作为子采样图的特征值。一般的卷积网络在降维处理时直接在卷积层之后加入池化层,由于对特征图进行池化操作之后会丢失3/4的特征信息,这样会导致模型的特征表达能力遇到瓶颈。
本文的池化层部分选择了“最大池化+卷积层”的并行化模块的池化结构,加入额外的卷积层,通过卷积的方式学习特征的同时缩小特征图,解决了传统网络池化操作时会出现特征信息丢失的问题。采用最大池化层是因为提取池化域内的最大值更有利于学习图像的纹理分布。
2.4 全局均值池化
对于分类问题,传统卷积神经网络[5,15]会将最后一个卷积层的特征图通过量化之后与全连接层连接,最后再连接一个用于分类的softmax逻辑回归分类层。然而,由于全连接层参数个数太多,网络参数大部分都聚集在全连接层,这样会使得网络模型容易出现过拟合现象,降低了网络泛化能力。
本文将一般网络中的全连接层替换为平均池化层。与全连接层不同的是,我们对最后一个卷积层输出的每个特征图进行全局均值池化,使得每张特征图都可以得到一个输出结果。采用均值池化,可以大大减少网络参数个数,避免模型过拟合,加快模型训练速度和计算速度;另一方面,每张特征图相当于一个输出特征,该特征即表示输出类别的特征。
3 实验及结果分析
3.1 实验准备
本文通过在两个标准数据集上做实验来验证本文网络的性能:CIFAR-10和香港中文大学多媒体实验室提供的服装数据集DeepFashion。
实验平台包括:PC机,Intel Core i7,显卡型号GTX1070, 8 GB显存,Ubuntu操作系统,caffe深度学习框架。在实验中,本文提出了一个新的网络—Res-FashionNet,网络框架主要由九个如图1所示的残差模块组合而成,每三个残差模块之后都连接一个”最大池化+卷积层”的并行化模块的池化结构用于网络降维。为了防止模型过拟合,在第2个并行池化结构之后添加dropout层,将该层任意一半的输出特征图上的像素值设置为0。特别地,在最后的分类输出层,使用全局均值池化层替代了全连接层。本文将该网络与目前常用的服装分类的经典卷积神经网络AlexNet、VGGNet作性能比较。由于未采用完全的网络训练优化方法,无法达到最优的精度,但都保证了每个网络采用相同的训练方法。
本文采用小批量梯度下降方法(Mini-batch gradient Descent)和常用的梯度下降优化算法——动量法(Momentum)来训练模型。在训练时对数据集采用mirror的数据增强方式,增大数据集。学习率的调整采用固定的更新策略,初始学习率设置为0.01,在CIFAR-10数据集上的训练中,分别在60 epochs、120 epochs和180 epochs时将学习率降低为上一次的0.1。而在DeepFashion数据集的测试中,则设置了分别在10 epochs、20 epochs和30 epochs时将学习率降低为上一次的0.1。
3.2 CIFAR-10
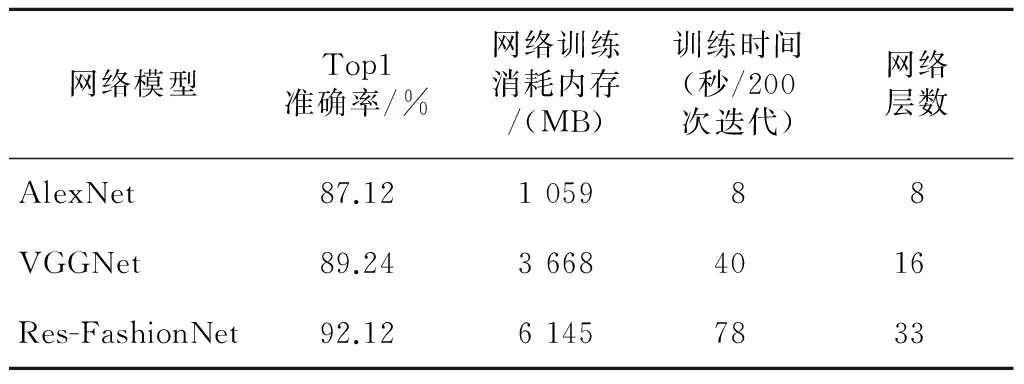
CIFAR-10数据集包含10个类别的图像,共有50 000张图像作为训练集,10 000张图像作为测试集验证。每张图像大小为32*32,网络训练和测试时输入处理的每批图像数量为50张。如图4所示为三个网络的训练收敛情况,纵坐标为损失值,横坐标为训练迭代次数。从图4和表1中可以看出,本文提出的优化残差网络在准确率和收敛速度上都优于VGGNet和AlexNet。相较于AlexNet,VGGNet基于3*3的卷积核构建了更深的网络结构,结合文献[11]中同样是将深层网络GoogLeNet用于图像分类赛事(ILSVRC)并取得了很好的结果,都表明了当卷积神经网络达到一定的深度之前,随着网络层数加深,模型的学习能力和表征能力越强,收敛也越快。但是,当网络规模达到一定的深度之后,模型的分类精度并不会随着层数的增加而增加,网络训练会出现梯度弥散[8]的问题。

Figure 4 Network training convergence图4 网络训练收敛情况
网络模型Top1准确率/%网络训练消耗内存/(MB)训练时间(秒/200次迭代)网络层数AlexNet87.12105988VGGNet89.2436684016Res-FashionNet92.1261457833
那么既然现在的网络训练方法难以训练我们认为的网络层数越深,学习能力越好的模型,本文对此问题的改进想法是尝试降低模型学习的难度,让前馈网络学习到的映射关系由原来的g(X)=X变成g(X)=F(X)+X,其中X是网络中每一层的输入。我们可以转换为学习一个残差函数F(X)=g(X)-X。只要F(X)=0,就构成了一个恒等映射g(X)=X。下面举例说明网络引入残差效果会更好。
假设F(X)是输入经过线性函数的求和前网络映射,g(X)是从输入到求和后的网络映射,g(X)=F(X)+X。比如把输入5映射到输出5.1,那么引入残差前是F′(5)=5.1,引入残差后是g(5)=5.1,g(5)=F(5)+5,F(5)=0.1。这里的F′和F都表示线性函数映射,下面证明引入残差后的映射对输出的变化更敏感。假设输出从5.1变化为5.2,映射F′的输出增加了1/51=2%,而对于残差网络从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。
总结而言,残差连接在网络中的作用相当于差分放大器。残差的思想是去掉相同的主体部分,从而突出微小的变化。另一方面,深层网络在反向梯度传播时,由于残差连接的存在,梯度永远不会小于1;若某一层的梯度接近于1,则相当于该层的线性网络部分梯度为0,可训练权值不更新,但梯度仍然可以反向传播,这样就不会影响深层网络的训练。
如表1所示,使用基于残差的卷积网络没有因为层数加深而出现训练困难的问题,和AlexNet相比,Top1准确率提升了5%。而与使用全连接层的VGGNet相比,本文使用全局均值池化层替换全连接层,大大减少了网络参数,因此虽然本文网络层数是VGGNet的2倍,但训练消耗内存并没有成双倍增加,训练速度的下降也在可接受范围内,同时准确率还提升了3%,也说明了本文提出的一系列优化网络的方法提高了卷积神经网络的学习能力。
3.3 DeepFashion
DeepFashion包含超过80万张服装图像,其中有商店里发布的规范的图像,也有买家发布的自拍照。每张图像都有详细的标签标注。该数据集由四个部分组成,分别对应四个基于服装数据集的图像处理任务:分类和属性预测、服装关键点预测、服装店内检索、服装跨域检索。本文中用来做服装分类实验的数据即来自上文提到的分类和属性预测部分,共29万张图像,包含Tee、Top、Blouse等46个服装类别标签,是目前已知的图像数量最多、标签信息最全的公开服装数据集。
该数据集由于图像初始尺寸参差不齐,大小各异,综合全部图像取图像长宽的均值,制作数据集时统一将尺寸resize设为251*251。如表2所示,其中FashionNet为文献[3]中提出的网络,除了AlexNet,其它两个模型的分类准确率都比FashionNet的好,而本文提出的Res-FashionNet得到了目前已知的在该数据集上最好的准确率,Top3分类精度相较于FashionNet提升了3.4%,Top5提升了2.2%。
为了检验模型的实际应用能力,需要对模型做进一步测试。测试工作分为两方面:(1)测试四种模型处理图像所需的时间;(2)测试模型对数据集外随机图像的分类效果。因此,本文自制两组测试集分别用于上述两组测试:(1)从互联网上爬取大小不限的100张服装图像用于测试模型处理图像所需时间;(2)按照46类别服装每一类搜集20张左右的图像,并确保类别正确,图像大小不限。一共收集了1 000张服装图像制作模型分类测试集。
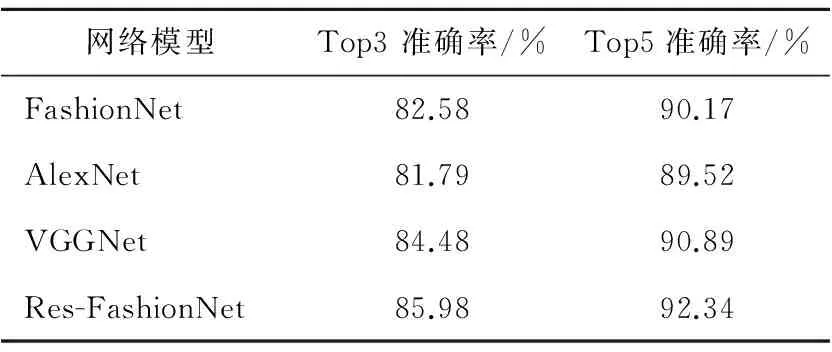
Table 2 Top3 and Top5 accuracy rate comparison on the DeepFashion dataset
在实际应用服装分类模型时,不仅需要考虑模型分类的准确性,更需要考虑模型进行图像处理所需要的时间。模型处理图像的速度主要是由网络参数个数和网络计算方式所决定的。计算方式主要是求卷积核参数和输入的内积,本文没有针对这一点进行改进。而VGGNet网络的参数多达13 800多万个,其中网络的第一个全连接层的参数为7*7*512*4096≈1亿。全连接层的参数占了网络总参数的3/4,参数太多一方面会降低模型的训练速度和前馈计算速度,另一方面会增加模型的复杂度,使模型出现过拟合现象。因此,本文使用核大小为7*7的均值池化层替换全连接层,前面的网络由16层增加到33层,最终本文网络的参数个数为7 000多万个,通过增加网络层数来增加模型的表征能力,又大大减少了网络参数个数来提高模型的处理速度。
如表3所示,比较三个模型处理图像的速度,AlexNet最快,但由于网络层数过浅,卷积核个数不多,并不具有很高的分类精度。其次便是本文提出的Res-FashionNet,在Top1和Top3的准确率上都优于VGGNet和AlexNet,而且在处理图像速度上,大大地优于VGGNet处理图像的速度,该实验结果也说明了本文对网络结构的改进是可行的。相较于VGGNet和AlexNet,本文提出的网络更适合于多类别的服装图像分类。由于网络上获取的图像相较于DeepFashion中的图像背景更为复杂,且图像中人物拍摄角度多样,服装容易发生变形或被遮挡,导致了这里的Top3准确率相较于表2低了10%,这也是之后进一步研究更精确的服装图像分类时应考虑的问题。

Table 3 Performance comparison of the three models on the self-made test dataset
4 结束语
针对如今已知的服装分类算法在大型服装数据集上分类精度一般的情况,本文提出了基于残差的优化卷积神经网络服装分类算法,在提高分类精度的同时拥有较快的图像处理速度。该网络的主要组成结构采用基于残差的连续小滤波器卷积结构,在可以接受的网络层数范围内最大化网络的非线性学习能力,也采用残差连接解决了深层网络训练困难的问题;同时,结合传统的激活层BN+ReLU与残差网络结合提出了改进的“BN+ReLU+卷积层”的结构,使用并行池化结构替代传统的单一池化层,增强了模型的表征能力;特别地,将平均池化层替代全连接层,减少了网络参数,加快了训练速度和模型处理图像的速度,且在一定程度上防止了过拟合。本文提出的网络在服装图像的分类精度和处理速度上相较于目前常用的基于深度学习的图像分类模型都有所提高。在接下来的工作中研究的内容主要为图像中的服装主体检测,通过去除背景干扰提高服装的分类精度。
[1] Kiapour M H,Han Xu-feng,Lazebnik S,et al.Where to buy it:Matching street clothing photos in online shops [C]∥Proc of ICCV,2015:3343-3351.
[2] Huang Jun-shi, Feris R S,Chen Qiang,et al.Cross-domain image retrieval with a dual attribute-aware ranking network [C]∥Proc of ICCV,2015:1062-1070.
[3] Liu Zi-wei, Luo Ping,Qiu Shi,et al.DeepFashion:Powering robust clothes recognition and retrieval with rich annotations [C]∥Proc of CVPR,2016:1096-1104.
[4] Li Zhi, Sun Yu-bao, Wang Feng, et al.Garment image classification retrieval algorithm based on deep convolution neural network [J]. Computer Engineering,2016,42(11):309-315.(in Chinese)
[5] Bengio Y,Simard P,Frasconi P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks,2002,5(2):157-166.
[6] Glorot X,Bengio Y.Understanding the difficulty of training deep feedforward neural networks [J].Journal of Machine Learning Research,2010(9):249-256.
[7] He Kai-ming,Zhang Xiang-yu,Ren Shao-qing.et al.Deep residual learning for image recognition [C]∥Proc of CVRP,2015:770-778.
[8] Ojala T, Pietikainen M,Harwood D.Multiresolution gray scale and rotation invariant texture classification with local binary patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI),2002,24(7):971-987.
[9] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks [C]∥Proc of International Conference on Advances in Neural Information Processing Systems,2012:1-9.
[10] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [C]∥Proc of ICLR’2015, 2015:1-14.
[11] Szegedy C,Liu Wei,Jia Yang-qing,et al.Going deeper with convolutions [C]∥Proc of CVPR,2015:1-9.
[12] Srivastava R K,Greff K,Schmidhuber J.Highway networks [C]∥ICML 2015 Deep Learning workshop,2015:1-6.
[13] Nair V,Hinton G E.Rectified linear units improve restricted boltzmann machines [C]∥Proc of International Conference on Machine Learning,2010:807-814.
[14] Ioffe S, Szegedy C.Batch normalization:Accelerating deep network training by reducing internal covariate shift [J].Computer Science,2015,arXiv:1502.03167.
[15] Goodfellow I J, David Warde-Farley,Mehdi Mirza,et al. Maxout networks [J].JMLR WCP,2013,28(3):1319-1327.
附中文参考文献:
[4] 厉智,孙玉宝,王枫,等.基于深度卷积神经网络的服装图像分类检索算法[J].计算机工程,2016,42(11):309-315.
