基于改良程序谱的软件故障定位方法
2018-03-06余晓菲陈慧峰蒋建民
余晓菲,张 仕,蔡 蕊,陈慧峰,蒋建民
(福建师范大学数学与信息学院,福建 福州 350007)
1 引言
计算机软件的失败(Failure)[1]是指一个服务偏离了它正确的行为,即实际输出不等于期望输出;错误(Error)[1]是指可能导致失败的系统状态;故障(Fault)[1]则是指系统错误的原因,即我们通常意义上的bug。故障会导致错误,从而会造成计算机系统功能减弱或消失,为了找出软件故障的位置,手工调试需要投入大量的人力,成本极高,所以希望利用自动诊断技术帮助定位故障位置,从而辅助程序员快速定位错误,订正程序错误代码。
软件故障定位大致可分为基于静态分析的故障定位和基于测试的故障定位TBFL(Test-Based Fault Localization),其中,基于静态分析的故障定位是通过分析程序代码找出故障位置而不运行程序;而基于测试的故障定位则是通过执行大量的测试用例,从而利用执行过程数据进行故障定位。基于测试的故障定位方法又可分为基于执行覆盖的故障定位、基于依赖关系的故障定位与基于模型的故障定位,本文对基于执行覆盖的故障定位方法进行改良,并进行优化实验,从而论证本文方法的有效性。
近年来,利用程序谱进行故障定位的方法层出不穷,Renieris和Reisst[2]提出了最近邻查询方法NNQ(Nearest Neighbor Queries),对比成功执行的覆盖和失败执行覆盖之间的相似度差异,但却只考虑了程序实体的执行与否,没有真正反映两个覆盖的相似性。Jones等人[3]提出了Tarantula技术,读取出每个程序版本的覆盖情况和运行结果(执行通过或不通过),从而计算每一个语句错误的可能性—可疑度,再根据可疑度进行排名。在此基础上,Aberu等人[1,4]受聚类分析影响提出了Jaccard公式,受分子生物学影响又提出了Ochilai公式,提高了故障定位的有效性,并验证出Ochilai公式的故障定位效果比Tarantula公式和Jaccard公式更好。Hao等人[5]提出了相知相似度故障定位方法SAFL(Similarity Aware Fault Localization),通过消除大量相似的测试用例来提高故障定位的检查率。Wong 等人[6]认为应该关注错误用例的影响,他们认为当执行测试用例时,执行成功的测试用例数量越多,它对计算可疑度的贡献就越小。
虽然上述方法都利用测试用例的执行情况分析了测试用例与故障间的联系,但是却没有针对执行失败的测试用例的覆盖情况进行分析。本文针对单错误问题对已有方法进行改进,基于测试用例执行失败的程序语句覆盖提出了故障基概念。由于每一个执行失败的测试用例都必然执行了错误语句,即错误语句必然被覆盖,那么在单错误情况下,将所有执行失败的测试用例的覆盖情况取交集,则会缩小故障语句的覆盖范围,从而提高查找效率。本文利用故障基的想法对Tarantula方法、Jaccard方法和Ochiai方法进行改良,并进行实验比较,以说明利用故障基改良基于程序谱的故障定位方法可以有效提高故障定位效果。
本文第2节详细介绍了程序谱的概念以及涉及到的故障定位技术;第3节通过实例介绍了改良程序谱的故障定位方法;第4节是实验验证,将本文提出的方法同现有方法相比较,以验证结果的显著性差异;第5节是总结和对未来工作的展望。
2 故障定位技术
2.1 程序谱
程序频谱详细描述了程序的执行信息[7],可以被用于追踪程序的行为[8]。本文的程序谱是指程序执行的过程信息,不但包含程序运行轨迹,也包含了程序运行过程的状态变化。早期,Collofello和Cousins[9]便提出程序谱可以用于定位软件的故障,即当程序执行失败时,程序谱信息可以用于查找可能导致执行失败的可疑代码,从而缩小程序员查找故障位置的范围。
本文利用一个文件记录需要的程序谱信息,其中包括0/1形式的矩阵用于指示程序运行时哪些代码被执行,以及程序输出结果正确与否的一维矩阵。
2.2 基于程序谱的故障定位技术
基于频谱的故障定位SBFL(Spectrum-Based Fault Localization)技术一直是个热门研究方向,其中Tarantula方法最为典型。该方法通过在gcc编译时添加参数,以便能够在程序运行过程中生成程序的运行覆盖情况;再分析运行覆盖并输出覆盖矩阵,并以此为依据计算每个执行语句的可疑度分数;最后以可疑度值为依据排序,可疑度分数越高的语句排名越靠前,程序员查错时先检查排名靠前的语句。
基于程序谱的故障定位技术主要利用了如下四个反映程序执行覆盖情况的指标:
N(s)=〈nep(e),nef(e),nnp(e),nnf(e)〉
其中,e表示程序实体;nep(e)表示执行了程序实体并且成功的测试用例数;nef(e)表示执行了程序实体并且失败的测试用例数;np为套件中所有执行成功的测试用例数且有np=nep(e)+nnp(e);nnp(e)表示未执行程序实体并且成功的测试用例数;nnf(e)表示未执行程序实体并且失败的测试用例数;nf为套件中所有执行失败的测试用例数且有nf=nef(e)+nnf(e);n为套件中所有的测试用例数且有n=np+nf。
Tarantula技术根据每个测试用例覆盖执行语句的轨迹信息和相应的执行结果(成功和失效)来计算每条语句的可疑度,其计算公式如下:
(1)
近年来,研究者提出了很多类似的技术,有些效果相差不大,有些效果要优于Tarantula,其中Aberu等人就相继提出了Jaccard技术和Ochilai技术,并实验证明了Ochilai技术进行故障定位的效果要优于Tarantula和Jaccard的。
Jaccard怀疑率计算公式如下:
(2)
Ochilai怀疑率计算公式如下:
(3)
3 改良程序谱
3.1 一个例子
图1中展示了一个程序实例test函数和一组由5个测试用例组成的测试套件,我们将通过该实例说明改良程序谱方法的基本思路。

Figure 1 Examples of improved program spectra图1 改良程序谱例子
函数test接受三个整数输入x,y,z,输出结果为三个数中的中间值,该程序故障处S4,其中的“x>y”应该为“x 所谓的故障基,是将执行失败的测试用例的语句覆盖做交运算,从而得到的程序语句集合。作为引例,图中未列出用其他计算公式计算可疑率的情况,而是以Tarantula为例,先计算了Tarantula公式不引入故障基时的可疑率,再计算引入故障基后Tarantula的可疑率(可疑率表示每一行语句用公式计算出的可疑分数,可疑值最大为1,值越大则排名越靠前,表示语句越可能包含故障),当几个程序的可疑度相同时,所有语句排名都取排名的最大值。 以故障语句S4作为例子,使用Tarantula计算语句可疑度。未引入故障基之前,总的测试用例数为5;分子为执行失败测试用例数与所有失败测试用例数的比值,计算得1;分母为执行成功测试用例数占所有成功测试用例数的百分比与分子之和,计算得1;故语句S4可疑率为1,但有四个语句计算得到的可疑度都为1,所以排名同为4。当引入故障基后,测试用例变成3个程序执行通过的测试用例与1个故障基,即4个测试用例数进行可疑度计算。同理,在计算故障语句S4时,分子分母都为1,故可疑率为1,排名为1。从例子中可以发现,引入故障基后,故障语句S4的排名从4变成1,且增加了可疑率为0的语句,说明其有效缩小了查找范围,大大提高了查找效率。 对基于频谱的故障定位方法而言,故障定位的效果和效率都高度依赖于测试用例,所以测试用例的选取以及使用测试用例的多少都对实验有至关重要的影响。针对测试用例的研究,本文提出的方法充分利用了执行失败测试用例的程序语句覆盖情况,缩减了运行时的执行失败测试用例数量,极大提高了软件故障定位的效率和有效性。 在程序运行时,每一个执行失败的测试用例都必然执行了错误语句(否则程序运行结果正确,不会产生失败执行的情况),即错误语句必然被覆盖。那么在单错误的情况下,将所有执行失败的测试用例的覆盖情况取交集,则会缩小故障语句的覆盖范围,并且交集一定会包含故障语句的覆盖,文中将交集取得的覆盖情况集合称为故障基。 将执行失败测试用例的覆盖情况设为集合vi,vi={vi1,vi2,…,vij,…,v(in-1),vin},我们称它为失败执行覆盖,其中i为执行失败测试用例编号,j为语句行号,n为总语句数,vi为第i个执行失败测试用例的执行情况,vij为第i个执行失败测试用例的第j条语句的覆盖情况,覆盖情况取值为0或1,覆盖为1,未覆盖为0。 失败测试用例集的覆盖V={v1,…,vi,…,vm},其中vi为第i个执行失败测试用例的执行情况,故障基FaultBase={f1,…,fk,…,fn},其中: 以图1中函数test为例,执行失败测试用例数为2,语句数为12,所以图1中共有两个失败执行覆盖v1和v2,其中,v1={1,1,1,1,0,1,1,0,0,0,0,1},v2={1,1,1,1,1,0,0,0,0,0,0,1}。 利用故障基定义,可以计算得到该例子中的故障基为FaultBase={1,1,1,1,0,0,0,0,0,0,0,1}。 大多数的故障定位研究都使用开源的评测程序[10]进行实验,本文使用SIR(Software artifact Infrastructure Repository)中的Siemens suite测试套件[11],Siemens suite包含七个小规模程序,代码行数在174~573,分别是tcas、shedule、schedule2、print_tokens、print_tokens2、replace和tot_info,由C语言编写而成,其具体情况如表1所示。 这七个程序共有132个版本,每个版本的程序都被人工注入单个错误。本实验用到了132个版本中的118个,其中,8个版本由于虚拟机运行时出现“core dumped”故障,所以无法获取cover文件,分别是replace的第27个版本,print_tokens2的第10个版本,schedule的第1、5、6、9版本,print_tokens2的第10个版本以及schedule2的第8个版本;而print_tokens的第4个和第6个版本由于C文件中没有出现语句错误,错误出现在.h文件中,实验系统无法获取其完整的执行轨迹信息,故不考虑;此外,schedule2的第9个版本、replace的第8个和第14个版本、tcas的第38个版本由于没有测试用例失败,所以不会显示故障。 Table 1 Description of the Simense suite 为了获取足够的信息完成本文的实验,我们需要获取三个方面的信息:程序错误代码的实际位置、每个测试用例运行结果的正确与否、程序谱。 为了获取程序错误代码的实际位置,本文将故障版本和正确版本相比较,检查代码的不同之处,并标记故障。对于单错误程序,其故障位置可能不是单一的,例如,语句缺失错误,只需要在缺失位置所在的语句块中加入该语句便可修正该错误,在这种情况下,我们把该语句块的任一位置均看作故障位置,那么一个故障版本可能存在多个故障位置,但在比较实验效果时只能有一个故障位置。据此,我们将最快定位到故障语句的位置作为本实验观察效果的故障位置,相当于找到一个错误就找到错误位置。最后,比较输出的不同,将其标记为故障位置。此外,本实验不考虑空白行、注释、函数及变量声明。 为了判定每个测试用例运行结果的正确与否,区分执行失败的测试用例和执行成功的测试用例。首先,对正确版本的程序运行所有测试用例,将获得的输出记录为期望输出;其次,对故障版本的程序运行所有的测试用例,将这些输出定义为实际输出;最后,对比期望输出和实际输出,把两种输出不同的测试用例均定义为失败运行。 为获取程序谱,我们利用gcc编译器实现编译时的插桩,以便记录程序运行情况。再利用gcov工具提取覆盖情况,并生成0-1矩阵反映代码执行覆盖。在读取并解析gcov文件过程中,若程序语句出现宏定义、注释、空白行等,此时覆盖中的“-”读成从不覆盖,“####”读成未覆盖,其余字数都为该执行语句的执行次数,读为具体覆盖次数。 为了能够统一评价标准,本文利用检查率作为实验效果评估标准。所谓检查率,是指程序员按照可疑率排序逐个检查相关程序,直到发现错误代码所需要检查的代码数量占程序总代码行数的百分比。检查率越低,说明程序员在故障定位时需要检查的代码行数越少,说明故障定位的效果越好,反之,则说明故障定位方法效果差。 表2和图2~图4体现了基于改良程序谱的故障定位方法实验效果,其列出了每个分数范围内所有的故障版本百分比。为了更好地对比,本文采用和文献[12,13]相同的分段方法,除了0%~60%与99%~100%,其余都以10%为间距进行分段。 将Tarantula、Jaccard、Ochilai这三种技术的运行结果与改良后的运行结果比较。其中的分数表示不需要检查的代码数占所有代码的百分比(对应图2~图4的横坐标),在分数段99%~100%则说明是最能精准定位到故障语句,即检查的代码数量最少。从表2可以看出,在分数为99%~100%区间内,即检查代码数量在1%内便可确定故障代码位置,改良后使Tarantula与Jaccard的测试运行提升了7.63%,说明改良程序谱后只需检查更少量的代码行就可以找出故障位置。在检查率为60%~70%区间内,Tarantula与Jaccard的测试运行在改良后减少了8.48%,说明需要检查的代码比例为30%~40%的故障版本在减少,它们不需要检查这么多的代码就可以找到故障位置,很显然,表2中的数据说明了改良程序谱后这三个技术的效果都相较之前有很大的提升。 Table 2 Percentage of test runs at each score level Figure 2 Comparison of inspection rates of ordinary Tarantula technology with improved one图2 Tarantula技术改良前后的检查率对比 Figure 3 Comparison of inspection rates of ordinary Jaccard technology with improved one图3 Jaccard技术改良前后的检查率对比 Figure 4 Comparison of inspection rates of ordinary Ochilai technology with improved one图4 Ochilai技术改良前后的检查率对比 从表2中我们也可以看出,不论是Tarantula、Jaccard、还是Ochilai,在经过改良程序谱后,每个检查率区间都会出现相近的故障版本数,即故障版本占全部版本百分比的数量差不多。文献[1,4]已经证明Ochilai效果要优于Tarantula和Jaccard,由表中三种改良前的技术所对应的故障版本百分比容易得出:在99%~100%范围内Ochilai所占的故障版本数都要更多,此时需要检查更少代码便能发现故障的故障版本数量增多,但是在改良了程序谱后,三者出现了同样的故障版本百分比17.80%。同样,在分数段90%~99%时,故障版本百分比数量分数大致平稳在50.80%。同理可以发现,改良程序谱后Ochilai对检查率值并没有相较于Tarantula、Jaccard有显著提升,Tarantula技术虽然效果没有Ochilai的效果好,但是在改良程序谱后,两者出现了极其相近的效果。 图2~图4分别展示了Tarantula、Jaccard、Ochilai这三种技术改良前后对应分数水平的故障版本百分比。横坐标为分数水平(不需要检查的代码数占所有代码的百分比),因为60%~70%分数段内测试运行百分比已达到100%,0%~60%也必然达到100%,所以0%~60%区间不在图中重复出现。纵坐标表示横坐标上某一分数值对应的故障版本的百分比,图2中90%~99%区间曲线最陡,在90%时已达到约68.7%,说明在这区间内故障版本数量占总版本数最多,即查找率在1%~10%的故障版本数量最多。在本文所研究的技术中,每个错误的版本来自同一个测试套件,所以纵坐标不仅代表测试运行的百分比,而且还表示故障版本的百分比。 在每个分数阶段,画出点并连线后形成图2~图4中所示的折线图,表示在该分数段或更高分数段内找到的故障版本百分比。例如图2中Tarantula技术,存在约53.4%的故障版本,只需要检查小于或等于10%的代码就可以发现故障语句,即可以达到90%甚至更高的分数。图2~图4都很直观地显示了技术改良后的检查率要明显高于改良前的,很显然改良程序谱后有效提升了检查率,可以更好地帮助程序员精准定位故障位置。 本文的改良程序谱想法是针对执行失败的测试用例而言,而具体测试用例及其数量对结果有很重要的影响,由于使用的Siemens suite 自带了实验所需测试用例,所以我们排除它对实验的影响。由表2可知,执行失败测试用例数最多的是print_tokens2的版本,执行失败测试用例数最少的是schedule2的版本,所以,本文使用Tarantula经典算法,比较执行失败测试用例的多少对实验效果的影响,并对计算出的可疑度进行排名,计算出检查率。 表3和表4中的排名1和检查率1代表Tarantula技术的排名和检查率,排名2和检查率2代表改良程序谱后的Tarantula技术的排名和检查率。由表3可以看出,print_tokens2版本经改良程序谱后排名提升很多,检查率也大大减小,效果最佳,这说明执行失败的测试用例越多,实验的效果就越好,故障定位效果越显著。而从表4可以看出,虽然在改良程序谱后排名也在靠前,可疑度也有减小,但效果提升却不够明显,这说明执行失败的测试用例越少,取得的效果越不显著。 由上可知,执行失败的测试用例数的数量对实验结果有至关重要的影响,且执行失败测试用例数的数量越多,效果越好。 Table 3 Comparison of print_tokens2 Table 4 Comparison of schedule2 基于频谱的故障定位一直是软件故障定位的热门研究方向,Tarantula算法被提出后,很多研究者提出了新的改进公式的方法,和Tarantula技术一样根据可疑度进行排名,帮助程序员定位故障。本文通过引入故障基的概念,对算法Tarantula、Jaccard、Ochilai进行改良;最后通过实验结果的比较,说明了改良方法的有效性,并分析了测试用例数量对实验效果的影响。此外,本文还分析了执行失败的测试用例数量对该方法的影响,即执行失败的测试用例数量越多,效果越显著。 本文基于对程序谱的分析和改良,虽然取得了很好的效果,但这是限定在单错误情况下,后续将深入研究多错误情况下故障定位的有效性。本文实验表明,在程序语句数越多或测试用例数越多时,其效果也会更加显著。但是,本文只利用Siemens suite套件进行实验,在后继工作中将针对多种程序体量、不同测试数据进行更加详细的比较。此外,本文主要是考虑执行失败测试用例对基于程序谱定位方法的影响,以后的工作中将结合考虑执行失败的测试用例和执行成功的测试用例,探索更加高效的方法。 [1] Abreu R,Zoeteweij P,Gemund A J C V.On the accuracy of spectrum-based fault localization[C]∥Proc of the Testing: Academic and Industrial Conference on Practice and Research Techniques,2007: 89-98. [2] Renieris M,Reiss S.Fault localization with nearest neighbor queries[C]∥Proc of the International Conference on Automated Software Engineering,2003: 30-39. [3] Jones J A,Harrold M J, Stasko J.Visualization of test information to assist fault localization[C]∥Proc of ICSE’02,2002: 467-477. [4] Abreu R, Zoeteweij P,Gemund A J C V.An evaluation of similarity coefficients for software fault localization[C]∥Proc of the Pacific Rim International Symposium on Dependable Computing,2006: 39-46. [5] Hao Dan,Zhang Lu,Pan Ying,et al.On similarity-awareness in testing-based fault localization [J].Automated Software Engineering,2008,15(2): 207-249. [6] Wong W E,Qi Y,Zhao L,et al.Effective fault localization using code coverage[C]∥Proc of the Annual International Computer Software and Applications Conference,2007: 449-456. [7] Wong W E,Gao R,Li Y,et al.A survey on software fault localization[J].IEEE Transactions on Software Engineering,2016,42(8):707-740. [8] Reps T,Ball T,Das M,et al.The use of program proling for software maintenance with appli-cations to the year 2000 problem[C]∥Proc of ESEC’97,1997: 432-449. [9] Collofello J S,Cousins L.Towards automatic software fault localization through decision-to-decision path analysis[C]∥Proc of International Workshop on Managing Requirements Knowledge,1987: 539-544. [10] Chen Xiang, Ju Xiao-lin, Wen Wan-zhi, et al.Review of dynamic fault localization approaches based on program spectrum[J].Journal of Software,2015,26(2): 390-412.(in Chinese) [11] Harrold M J,Rothermel G,Wu R,et al.An empirical investigation of program spectra[C]∥Proc of the SIGPLAN/SIGSOFT Workshop on Program Analysis for Software Tools and Engineering,1998: 83-90. [12] Cleve H,Zeller A.Locating causes of program failures[C]∥Proc of the International Conference on Software Engineering,2005: 342-351. [13] Renieris M,Reiss S.Fault localization with nearest neighbor queries[C]∥Proc of the International Conference on Automated Software Engineering,2003: 30-39. 附中文参考文献: [10] 陈翔,鞠小林,文万志,等.基于程序频谱的动态缺陷定位方法研究[J].软件学报,2015,26(2):390-412.3.2 故障基
4 实验准备
4.1 实验基础

4.2 实验流程
5 实验评估
5.1 实验结果



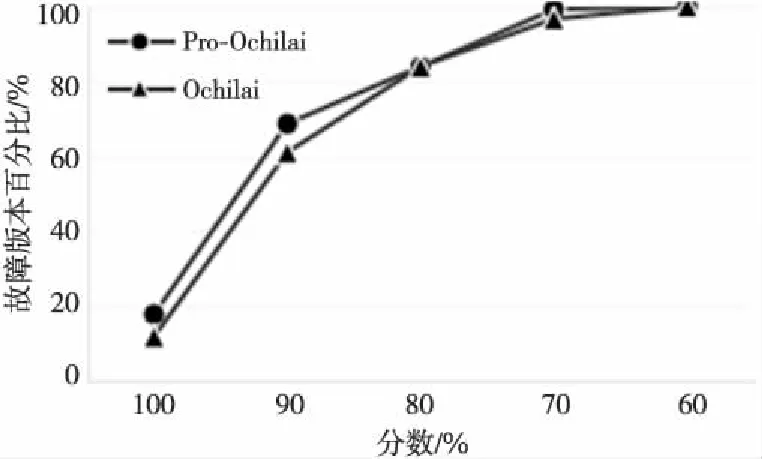
5.2 实验影响因素
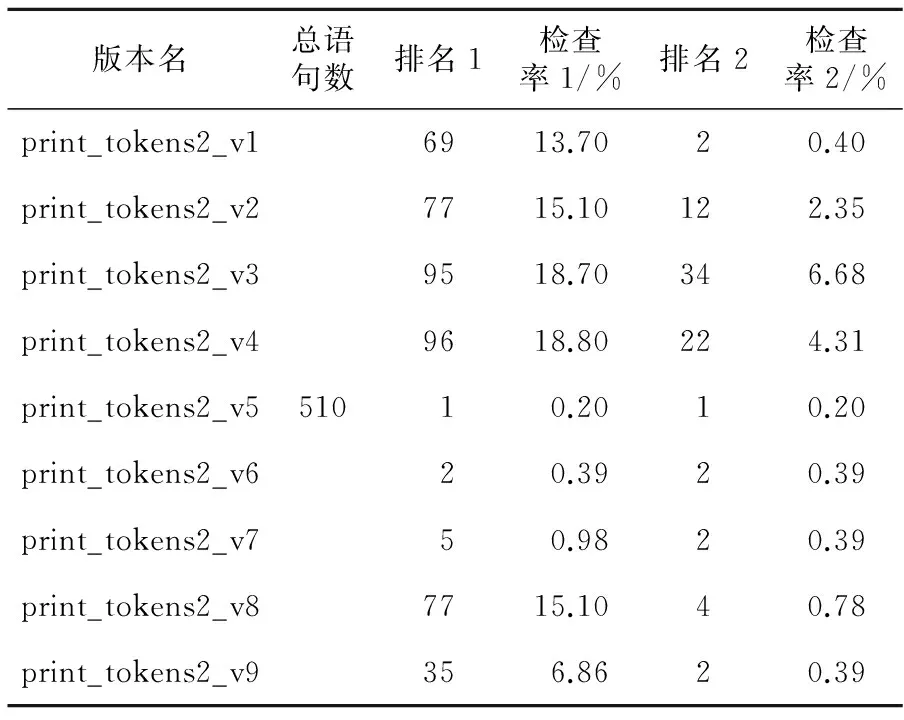
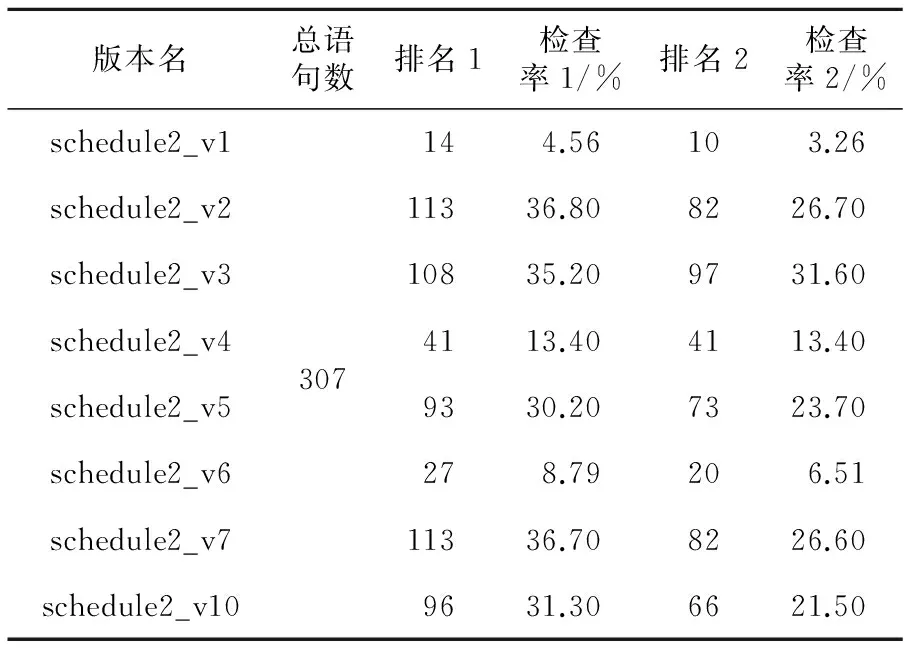
6 结束语
