基于节点热度与缓存替换率的ICN协作缓存
2018-03-03丁尧,郑烇,郭晨,王嵩
丁 尧,郑 烇,郭 晨,王 嵩
(中国科学技术大学 自动化系 未来网络实验室,合肥 230026)
0 概述
根据Cisco公司的VNI预测,2015年至2020年期间,全球IP流量将以22%的年均复合增长率高速增长。其中,大部分流量都由内容获取类应用产生。除此之外,各地区流量会有显著差异[1]。
信息中心网络(Information-Centric Networking,ICN)[2]架构的重要特征之一便是利用泛在化、透明化的网内缓存来提高内容获取的传输效率和网络资源利用率[3-5]。而ICN默认缓存策略LCE[6](Leave Copy Everywhere)会产生大量内容冗余备份,且节点缓存替换率较高,无法充分利用缓存资源。在此基础上,文献[7]提出了CLFM(Cache Less for More)策略,但没有考虑到介数越大的节点缓存替换率也越高,后续请求无法利用节点缓存数据,而且根据网络拓扑结构计算的节点介数固定不变,无法更好地体现流量区域差异性和时间差异性带来的影响。
本文提出基于节点热度与节点缓存替换率的ICN协作缓存策略HotRR,在数据包返回路径上选择特殊节点缓存内容,利用更少的缓存资源获取更大的缓存收益。针对节点在不同区域和不同时间段内网络流量的差异性,通过动态变化的节点热度衡量节点在网络拓扑结构中的重要程度,同时考虑节点的缓存替换率,避免重要的节点处于高频率的内容替换状态。本文考虑上述因素,旨在进一步降低网络延迟、网络交通流量和服务器负载,从而改善缓存系统性能,获得更好的用户体验。
1 ICN缓存模型与相关技术
1.1 ICN缓存系统模型
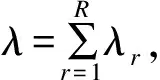
缓存命中是指一个请求在内容分发路径上的某个节点找到请求内容,反之称为未命中。如果缓存未命中,请求将会遍历分发路径,直到源端的内容服务器。假设内容单元大小相同,当节点的缓存已满,缓存替换策略采用LRU。
1.2 相关技术
目前有关ICN缓存的研究主要包括2个方面:1)缓存系统性能优化,包括缓存大小规划、缓存空间共享机制、缓存决策策略、缓存替换算法、对象可用性、缓存网络拓扑优化;2)缓存系统建模与分析,包括对象流行度模型、外生请求到达模型、缓存网络拓扑模型、请求关联度模型、缓存系统稳态分析[3]。
ICN默认的缓存决策策略LCE[6]在返回路径的每个节点缓存数据,本质上没有协同缓存,会产生大量内容冗余备份,降低系统内容的多样性。
文献[7]针对LCE问题提出了CLFM策略,其将网络抽象成一张图,由于每个缓存节点连接的情况各不相同,因此内容缓存在不同节点上能够发挥的效用不尽相同。CLFM通过选取图中介数较大的节点,介数越大意味着被访问的概率更高,把更多的缓存内容放在这些节点上能够更大程度发挥缓存的作用。但CLFM只重视了节点在拓扑图中的作用,没有考虑到缓存内容本身发挥的作用。而且节点介数无法更好地体现流量的区域差异性和时间差异性所带来的影响。随着网络规模的增大,往往越重要节点的请求越多,导致缓存的内容更替频繁,即使流行度很大也很有可能被替换掉,从而后续请求无法充分利用前期缓存[8]。
ProbCache方法[9]是一种基于概率的缓存方式。在该方法中,内容的缓存概率和请求的距离(请求节点到提供内容节点的度量)成反比。越接近于源节点,内容被缓存下来的几率就越低。同时缓存容量充足的节点在接收缓存内容时享有比较高的优先权,其目的在于让缓存内容存放在接近用户的节点上,并且尽量地减少内容替换的发生。但是ProbCache没有考虑缓存内容同质化的情况,可能会引起边缘节点缓存的竞争。
关于ICN缓存问题的研究,研究者尽可能地找寻相应的协同缓存机制[10-13]。通过协同机制的作用,一方面能让用户更快地获取到所需内容,另一方面减少网络中缓存的同质化现象,更大效率地发挥缓存的作用。
2 HotRR缓存放置策略
2.1 设计思想
在ICN网络结构中,经过一个节点的交通流量越多,则在此节点缓存内容更有可能发生内容请求命中。所以,在数据包返回路径上选择交通流量最大的节点缓存数据可以降低兴趣包的跳数。但是网络交通流量具有动态性,如果用网络拓扑结构中静态的节点介数来衡量节点的重要程度,无法体现网络流量的区域差异性和不同时间段的差异性。可能同一地区、同一节点在不同的时间段网络流量有很大波动,不同的地区和节点在同一时间段的网络流量也可能有很大的波动。因此,本文提出基于节点热度的ICN缓存策略(简称Hot策略),动态地统计节点到达的请求数作为节点热度,以衡量节点的重要程度。在此基础上,考虑到交通流量越大的节点经过的数据包越多,节点的内容替换越频繁,使流行内容在节点的缓存时间变短,导致网络的内网缓存命中率下降,延迟增大,本文在综合考虑节点热度和缓存替换率的基础上,提出HotRR缓存放置策略,周期性地动态计算节点热度和缓存替换率,得到内容是否被缓存在节点的度量指标Score(节点热度越高同时节点缓存替换率越低,节点的度量值Score越高),在数据包返回路径上选择Score值最高的节点缓存内容,可以利用更少的缓存资源获得更多的缓存收益。
下面通过实例说明本文的缓存策略,如图1所示。在t=0时刻,所有节点的已缓存空间为空,用户B向源服务器请求内容f。

图1 LCE、CLFM与HotRR策略实例
对于LCE策略,路径上的每个节点都保留一份内容副本。现在假设用户C请求相同的内容f,则在节点v4命中请求内容,但是在节点v1、v2、v5有冗余的内容副本。
对于CLFM策略,节点v2的介数最大,在v2节点缓存内容f。此后用户C或者用户A请求相同的内容只需经过较少的跳数就可获取内容,而且不会产生内容f的冗余副本。但是由于v2的节点介数大,导致缓存替换率较高,流行内容可能会被替换掉,后续请求只能重新到源服务器获取内容f。
对于HotRR策略,如果用户B、C请求数较多,经过节点v4的网络交通流量较大,则内容f被缓存在节点v4(同时考虑节点v4的缓存替换率,如果节点v4缓存替换率较高,则内容f可能被缓存在v2)。如果用户A请求数较多,经过节点v2的网络交通流量较大,则内容f被缓存在节点v2(同时考虑节点v2的缓存替换率,如果节点v2缓存替换率较高,则内容f可能被缓存在v4)。所以,HotRR策略会周期性地动态统计节点热度和缓存替换率,根据网络的实时状况判断内容的放置位置,使得网络的平均请求跳数较低,从而改善用户体验。
2.2 算法实现
2.2.1 Hot缓存策略
节点的度量值Score只与节点热度有关。周期性地动态统计节点热度:
Hot[v,i]=α×Hot[v,i-1]+(1-α)×rNum[v,i]
(1)
其中,Hot[v,i]表示节点v在周期i内的节点热度,rNum[v,i]表示节点v在第i周期内到达的请求数,α(0<α<1)表示节点v的第(i-1)周期的节点热度在第i周期的节点热度中所占的权重。
周期性地计算节点的度量值Score,将其作为在数据包到达时内容是否被缓存在节点的依据:
Score[v,i]=Hot[v,i]
(2)
其中,Score[v,i]表示节点v在周期i内的得分。
2.2.2 HotRR缓存策略
综合考虑节点热度和缓存替换率,周期性地动态统计节点缓存替换率:
(3)
其中,RR[v,i]表示节点v在周期i内的缓存替换率,β(0<β<1)表示节点v的第(i-1)周期的缓存替换率在第i周期的缓存替换率中所占的权重,m[i]表示第i周期内被替换内容的个数,sv(fk)表示节点v被替换内容fr的大小,C(v)表示节点v的总缓存容量。
最后,周期性地计算节点的度量值Score:
(4)
其中,Score[v,i]表示节点v在周期i内的得分。
由于衰减因子α、β在0~1之间,通过Score[v,i]的递归式可知,较近周期的请求数和缓存替换率对节点得分Score影响较大,较远周期的影响较小,可以更好地体现网络动态性带来的影响。
HotRR策略的算法步骤如下:在兴趣包中添加Score标签,初始化为0,用来记录兴趣包在请求路径上所有节点中最大的节点度量值,作为数据包返回过程中内容是否被缓存在节点的依据。兴趣包每经过一个节点,如果缓存命中,则直接返回数据;如果缓存未命中,比较兴趣包记录的Score值和节点的Score值,取其大者作为兴趣包的Score值,继续往上游转发,直到请求被满足。当兴趣包被满足时,把兴趣包记录的Score值传递给数据包的Score字段。在数据包返回过程中,如果路径上节点的Score值大于等于数据包的Score值,则在此节点缓存内容。继续往下游转发,直至最初的内容请求者。
算法HotRR
初始化:
∀v∈V,Hot(v)=0,RR(v)=0,Score(v)=0
α=0.2,β=0.2
T=1 s//周期
//节点v对收到的兴趣包的处理过程
1.++rNum(v)//请求的数量
2.if(runtime%T == 0)
3. Hot(v)=α*Hot(v)+(1-α)*rNum(v)
4. RR(v)=β*RR(v)+(1-β)*Rep/C
5. //Rep代表m_cs中替换的次数
6. //C代表m_CS的缓存大小
7. Score(v)=Hot(v)/(e^RR(v))
8.if CacheHit
9. data.setTag(make_shared
10. interest.getTag
11. return data package
12.else
13. auto scoreTag=interest.getTag
14. if( *scoreTag< Score(v) )
15. interest.setTag(make_shared
16. Score(v)))
17. 将此兴趣包转发至下一跳节点
//节点v对收到的数据包的处理过程
1.if(m_CS is full)
2. ++Rep
3.if 节点v与Consumer直接相连
4. 将数据包转发至Consumer
5. 请求最终被满足
6. return
7.else
8. auto scoreTag=data.getTag
9. if( *scoreTag <= Score(v) )
10. 数据将被缓存在 m_CS中
11. 将数据包转发至下一跳节点
3 实验与结果分析
3.1 实验性能指标
ICN缓存的目标为:1)降低内容传输延迟;2)降低交通流量,避免拥塞;3)减轻服务器负载。本文提出平均请求跳数θ(t)作为目标1)和目标2)的衡量标准,源服务器命中率φ(t)作为目标3)的衡量标准:
(5)
(6)
其中,hr(t)表示时间段[t-1,t]内请求内容fr所需的跳数,Q表示时间段[t-1,t]内总请求数,wr(t)表示时间段[t-1,t]内在源服务器命中内容fr请求的次数。
平均请求次数θ(t)越低,说明内容传输延迟越小、交通流量越少;源服务器命中率φ(t)越低,说明请求的网内命中率越高,源服务器的负载越小。
3.2 仿真环境及参数设置
仿真环境:操作系统Ubuntu14.04 LTS 64 bit;硬件采用Intel®CoreTMi5-4200U CPU @ 1.60 GHz×4,4 GB内存;采用基于NS3的NDN仿真器ndnSIM2.2[14]。
实验参数:总内容数为10 000个,每个内容为单一数据块;到达节点的请求服从泊松分布,λ=100 request/s;内容请求服从Zipf-Mandelbrot分布[15];选取不同的节点缓存容量进行对照实验,缓存容量指节点可以缓存的内容数量上限,如缓存容量为100时,该节点最多可以缓存100个内容;仿真时间为300 s。
3.3 实验数据分析
本文以LCE和CLFM策略作为对照实验,以检验Hot策略和HotRR策略的有效性。
3.3.1 随机树状拓扑对实验的影响
首先,仿真拓扑结构选择深度为8、节点数为50的随机树状拓扑。
当节点的缓存容量取不同的值,LCE、CLFM、Hot、HotRR策略的平均请求跳数如图2所示。可以看出,4种策略的平均请求跳数均随着节点缓存容量的增大而减小,但HotRR策略性能相对而言最优,Hot策略比CLFM策略性能提升约4%,比LCE策略性能提升约21%。在考虑节点缓存替换率的基础上,HotRR策略相对于Hot策略性能提升约5%。

图2 平均请求跳数随节点缓存容量的变化
源端命中率随节点缓存容量的变换趋势如图3所示。可以看出HotRR策略性能相对而言最优,相对于ICN默认的LCE缓存策略,Hot策略性能提升较显著。同时,Hot策略比CLFM性能提升约5%。同理,在考虑节点缓存替换率的基础上,HotRR策略相对于Hot策略性能提升约8%。
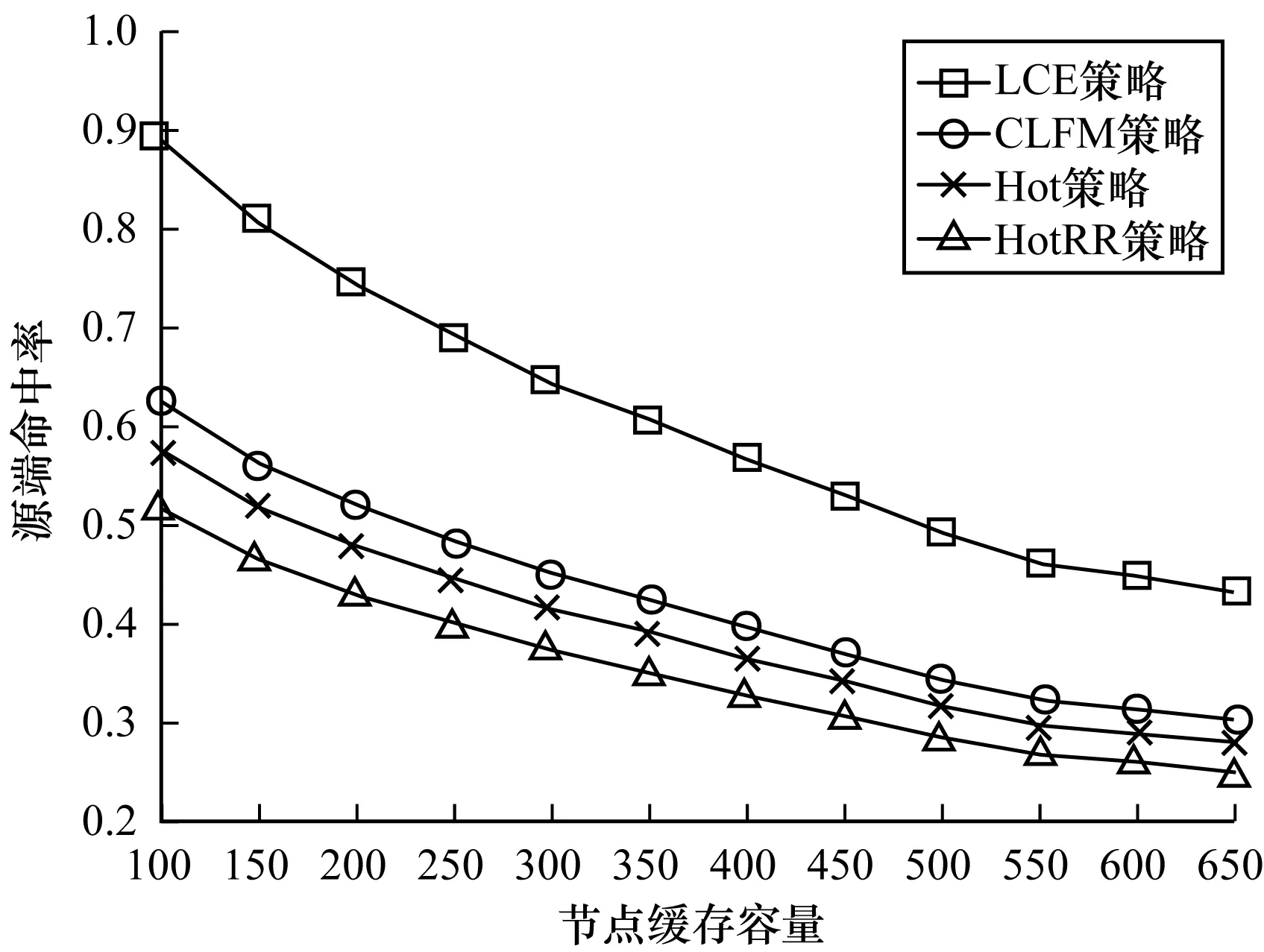
图3 源端命中率随节点缓存容量的变化
其次,考虑随机树状拓扑结构的规模对实验的影响。取节点缓存容量为400,进行对照实验。实验结果如图4所示。可以看出,HotRR策略性能相对最优。

图4 平均请求跳数随节点数量的变化
3.3.2 二叉树拓扑对实验的影响
首先,仿真拓扑结构选择深度为8的二叉树。当节点的缓存容量取不同的值,LCE、CLFM、Hot策略、HotRR策略的平均请求跳数如图5所示,源端命中率随节点缓存容量的变换趋势如图6所示。可以看出,HotRR策略性能相对最优。
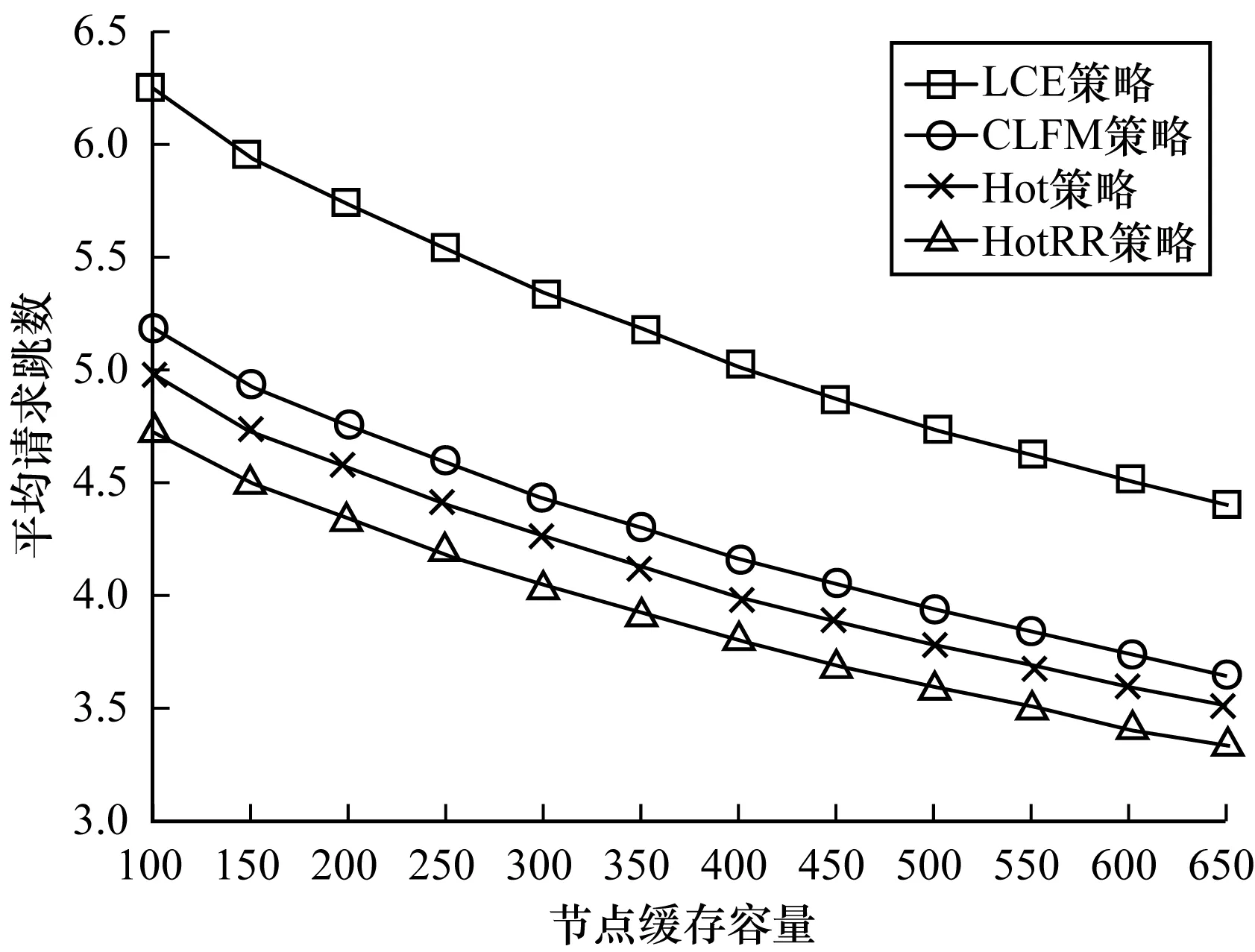
图5 平均请求跳数随节点缓存容量的变化

图6 源端命中率随节点缓存容量的变化
其次,考虑不同深度的二叉树对实验结果的影响。取节点缓存容量为400,进行对照实验。实验结果如图7所示。可以看出,可见HotRR策略性能相对最优。

图7 平均请求跳数随二叉树深度的变化
4 结束语
本文分析ICN默认的LCE缓存放置策略,针对其存在的问题,使用更能反映网络动态性和节点重要性的节点热度代替CLFM策略中的节点介数,并结合节点缓存替换率提出HotRR缓存放置策略。该策略解决了LCE策略造成的缓存冗余问题,同时更有效地将内容缓存在重要节点上,并可避免重要节点内容被替换频繁。仿真实验表明,在平均请求跳数和服务器源端命中率方面,HotRR的性能皆优于LCE和CLFM策略。下一步将在本文研究基础上,结合缓存放置策略和路由机制,利用邻域缓存信息设计性能更优的缓存策略。
[1] Cisco Systems,Inc..Cisco Visual Networking Index:Forecast and Methodology:2015~2020[EB/OL].(2016-06-01).http://www.cisco.com/c/en/us/solutions/collate ral/service-provider/visual-networking-index-vni/complete- white-paper-c11-481360.html.
[2] BENGT A,DANNEWITZ C,IMBRENDA C,et al.A Survey of Information-Centric Networking[J].IEEE Communications Magazine,2012,50(7):26-36.
[3] 张国强,李 杨,林 涛,等.信息中心网络中的内置缓存技术研究[J].软件学报,2014,25(1):154-175.
[4] RAN Jianhua,LV Na,ZHANG Ding,et al.On Performance of Cache Policies in Named Data Networking[C]//Proceedings of International Conference on Advanced Computer Science and Electronics Information.[S.l.]:Atlantis Press,2013:668-671.
[5] CHAO Fang,YU F R,TAO Huang,et al.A Survey of Energy-efficient Caching in Information-Centric Net-working[J].IEEE Communications Magazine,2014,52(11):122-129.
[6] JACOBSON V,SMETTERS D K,THORNTON J D,et al.Networking Named Content[C]//Proceedings of the 5th International Conference on Emerging Networking Experi-ments and Technologies.New York,USA:ACM Press,2009:1-12.
[7] CHAI W,HE D,IOANNIS P,et al.Cache “Less for More” in Information-Centric Networks[J].Computer Communications,2013,36(7):758-770.
[8] 崔现东,刘 江,黄 韬,等.基于节点介数和替换率的内容中心网络网内缓存策略[J].电子与信息学报,2014,36(1):1-7.
[9] PSARAS I,CHAI W K,PAVLOU G.Probabilistic In-network Caching for Information-Centric Networks[C]//Proceedings of the 2nd Edition of the ICN Workshop on Information-Centric Networking.New York,USA:ACM Press,2012:55-60
[10] 曲 桦,王伟萍,赵季红.内容中心网络中一种改进型缓存机制[J].计算机工程,2015,41(3):41-46.
[11] LI Jun,WU Hao,LIU Bin,et al.Effective Caching Schemes for Minimizing Inter-ISP Traffic in Named Data Network-ing[C]//Proceedings of IEEE International Conference on Parallel and Distributed Systems.Washington D.C.,USA:IEEE Press,2012:580-587.
[12] 刘外喜,余顺争,蔡 君,等.ICN 中的一种协作缓存机制[J].软件学报,2013,24(8):1947-1962.
[13] MING Zhongxing,XU Mingwei,WANG Dan.Age-based Cooperative Caching in Information-Centric Networks[C]//Proceedings of IEEE INFOCOM’12.Washington D.C.,USA:IEEE Press,2012:268-273.
[14] MASTORAKIS S,AFANASYEV A,MOISEENKO I,et al.ndnSIM 2.0:A New Version of the NDN Simulator for NS-3:NDN-0028[R].Los Angeles,USA:Los Angeles University of California,Los Angeles,2015.
[15] BRESLAU L,CAO Pei,FAN Li,et al.Web Caching and Zipf-like Distributions:Evidence and Implica-tions[C]//Proceedings of the 18th Annual Joint Con-ference of the IEEE Computer and Communications Societies.Washington D.C.,USA:IEEE Press,1999:126-134.
