基于计算听觉场景分析的说话人转换检测
2018-03-02杨登舟夏善红
杨登舟,刘 加,夏善红
(1.中国科学院电子学研究所,北京 100190; 2.中国科学院大学,北京 100049;3.清华大学 电子工程系,北京 100084)
0 概述
随着电子通信和计算机技术的快速发展,大量的语音数据被存储,如何快速地建立语音检索是亟需解决的问题。说话人转换检测(Speaker Change Detection,SCD),也称说话人分割[1],是语音信号处理中的一项实用技术,从一段语音中将不同说话人说话的时刻检测出来,将语音分割出满足要求的片段,可以很方便地建立索引,为信息的进一步处理提供便利[2-3]。
语音切分类问题可以抽象成模型判别问题,用特定长度的窗(定长窗或者变长窗)扫描整段语音,当窗内左右两部分的语音之间的差异达到某个阈值,认为在窗左半部分和右半部分发生了明显的改变,有理由怀疑此处语音的声源发生了变化[4]。在说话人转换检测的研究中,窗左右两侧语音之间的差异度量方式主要有模型差异、参数差异以及模型和参数相结合[5-6]这三大类。在基于模型的方法中,从训练数据中挑选出不同的发声源,训练出各自的模型,同时训练出所有声源的全局模型,通过分析全局模型和个体模型的不同之处,得到模型间转化关系或者找到可区分的模型差异,常用的模型包括通用背景模型(Universal Background Model,UBM)、样本说话人模型(Sample Speaker Model,SSM)、隐马尔科夫模型(Hidden Markov Model,HMM)。基于参数的方法,使用较多的特征主要包括时域短时能量、过零率、频域的子带能量、倒谱特征、线性预测系数等。通常使用差异度量准则有贝叶斯信息准则(Bayesian Information Criterion,BIC)、广义似然比(Generalized Likelihood Ratio,GLR)、KL散度(Kullback-Leibler divergence)、归一化交叉似然比(Normalized Cross Likelihood Ratio,NCLR)等。
在说话人识别问题中,由于事先可以获取训练数据,可以事先训练出多个不同的说话人模型,在判决阶段只要将一段语音的特征和所有参考模型做比较,和哪一个更近就判别成哪个,在闭集测试中,性能较好[7]。而说话人转换检测比说话人识别难度大,主要难点在于对一段语音做切分任务,并不会提供该语音中所包含的说话人的训练语料,因此不能准确获取到说话人的模型,特别是在短时说话人迅速转变的对话口语语音中完成稳定说话人建模难度更大,需要挖掘短时说话人差异区分性大、能全面描述说话人发声特性的特征。计算听觉场景分析(Computational Auditory Scene Analysis,CASA)[8]根据听觉生理学和听觉心理学的研究成果,利用计算机模拟人耳耳蜗的听觉处理机制来处理接收到的语音信息,该理论能够较好地解决诸如同信道语音分离问题,充分利用语音的周期性和短时连续性2个重要的线索来区分不同的声源。
本文提出一种基于听觉场景分析的说话人转换检测方法,将语音分割成相邻的若干语音子段,提取伽马音能量倒谱系数特征,在贝叶斯信息准则的判决下得到初始说话人转换点,最后利用浊音的基频特征对漏检和错检的转换点进行后处理,以达到较好的检测结果。
1 计算听觉场景分析
人每天在各种复杂的声学环境中倾听语音,提取需要的信息,可以从周围嘈杂的多人说话环境中锁定自己感兴趣的声源对象,只要信噪比合适,人耳可以将目标声源的声音从背景语音中完全分离出来,并且做得非常出色,取决于人类具有听觉场景分析(Auditory Scene Analysis,ASA)[9]的能力。
人耳的耳蜗基底膜就好像是一个初级的频率分析器,可以将声音中的各种频率在基底膜上的位置进行编码。当基底膜上下振动,其柯蒂氏器(Corti)也随之产生相同的振动模式,并促使毛细胞纤毛发生弯曲形变,毛细胞去极化并在其顶部产生耳蜗电位,该电位会引起毛细胞底部神经纤维的应激反应,释放出化学物质,引导神经末梢兴奋,传输至中枢神经。人耳除了具有频率分析特性,对声波强度的编码也非常高效,通过神经单元兴奋后发放神经冲动的数量来确定强度。
1.1 Gammatone滤波器组模型模拟耳蜗的频率分析
听觉场景分析中将原始语音信号拆分成多个子带信号的过程是通过Gammatone滤波器组[10]来实现的。Gammatone滤波器组是由一系列不同带宽不同中心频率的带通滤波器组成,Gammatone滤波器的冲激响应为:
gc(t)=
(1)
其中,τ是滤波器的阶数,φ是初始相位,B(fc)是滤波器组的带宽,fc是中心频率。当τ=4时和人耳听觉滤波器非常吻合。滤波器的带宽由中心频率对应的等价直角带宽(Equivalent Rectangular Bandwidth,ERB)确定:
ERB(f)=24.7×(4.37f/1 000+1)
(2)
B(f)=1.019×ERB(f)
(3)
线性频率f和“ERB-rate”尺度频率FERB的换算关系为:
FERB(f)=21.4×lg(0.004 37f+1)
(4)
将线性频率80 Hz~5 000 Hz转化为“ERB-rate”尺度频率,并在“ERB-rate”尺度下均匀取出128个,生成子带数C=128的Gammatone滤波器组。将原始语音信号s(t)通过滤波器组滤波,输出C个子带信号uc(t):
uc(t)=s(t)×gc(t),c=1,2,…,C
(5)
1.2 毛细胞触发模型模拟耳蜗的强度分析
原始语音信号s(t)经过Gammatone滤波器滤波后得到uc(t),c=1,2,…,C(为表述方便,下文将省略子带下标c,并不影响理解)。将u(t)经过Meddis毛细胞模型[11],可以得到描述听觉神经触发概率的信号v(t)。毛细胞触发概率的计算过程通过以下4个方程完成:
(6)
(7)
(8)
(9)
在式(6)~式(9)中,g、r、l、h、A、B、x、y是模型常数,q(t)、c(t)、w(t)是中间变量,在毛细胞传导模型中有具体意义,听觉末梢发放概率v(t)=h·c(t)。
2 区分性特征提取
2.1 伽马通能量倒谱系数
在语音识别、说话人识别和语种识别中都可以见到梅尔频率倒谱系数(Mel-frequency Cepstral Coefficients,MFCC)[12]发挥的重要作用。梅尔频率倒谱系数是将语音帧的快速傅里叶变换(Fast Fourier Transformation,FFT)频谱通过相互交叠且中心频率沿梅尔频率线性分布的24个三角滤波器组,对三角频窗内的能量计算对数,对数谱计算离散余弦变换(Discrete Cosine Transform,DCT)得到梅尔频率倒谱系数。伽马通频率倒谱系数[13]借鉴了梅尔频率倒谱系数特征提取的原理。MFCC中对能量求对数得到倒谱,在GFCC中变成了计算响度压缩,本文建立了一个介于GFCC和MFCC之间的特征,伽马通能量倒谱系数(Gammatone Energy Cepstral Coefficients,GECC),它和GFCC的提取不同之处如图1所示,GECC仅在于利用响度和能量的差异。

图1 特征提取流程
对毛细胞触发模型的输出v(t)进行100 Hz降采样,得到分帧信号w(m),m=1,2,…,M,M是帧数。各帧能量记为Gc(m),对Gc(m),c=1,2,…,C计算M阶的离散余弦变换来降低M个子带间的数据相关性,取前D维的数据,得到GECC特征:
m=1,2,…,2M,k=0,1,…,D-1
(10)
2.2 音高
从人的发音结构和语音的形成过程,可以把语音信号等效成激励-滤波器模型,声门产生激励,声门激励满足准周期性就可以产生有固定谐波结构的语音信号,这类语音称之为浊音[14];将不具有周期性且与噪声类似的声门激励生成的语音信号称为清音。声带、嘴唇、口腔的作用可以等效成声道滤波器响应。声道滤波器反映的主要是语义信息(音素,词汇),说话人的特性主要取决于声门激励。浊音的基频在听觉的感受就表现在音高上,每个人的音高略有不同,分布在50 Hz~500 Hz的范围内,男性的音高比女性要低,成人的音高比小孩的要低。音高的差异可以作为说话人区分的一个重要特征。
对应某个特定子带c、时间帧m内的毛细胞触发输出v(t)的自相关:
vc(mN/2-k-τ)×h2(k+N/2)
(11)
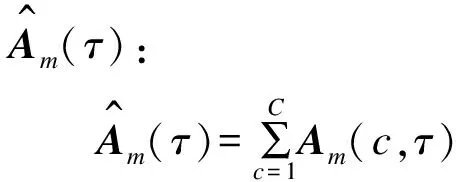
(12)
通常人类的基音范围在80 Hz ~500 Hz,对应的延时区间是τ∈[2 ms,12.5 ms],通过搜索最大值得到音高Pm:
(13)
对检测的音高序列做平滑处理,得到连续的基音轨迹。
3 说话人转换检测系统
本文基于听觉场景分析的说话人转换检测由听觉外围处理、特征提取、转换点判决3个部分组成,如图2所示。听觉外围处理将语音信号经由伽马通滤波器组滤波,再用Meddis毛细胞触发模型得到听觉神经末梢的发放概率。对发放概率按帧能量检测对应帧是浊音、清音还是静音,各帧的属性标记以后,得到浊音的连续片段,称为子段,记为S。对所有相邻的子段对(Si,Si+1)进行贝叶斯信息准则判决,得到分割初步判决结果。经过贝叶斯信息准则判决后,已经得到一定数量的说话人转换点,区间验证的作用是试图利用音高信息,对可疑的转化点进行剔除,并尝试找回已经被遗漏的转化点。

图2 基于听觉场景分析说话人转换检测系统
3.1 清浊音检测
对毛细胞触发模型的输出v(t)进行短时分帧,并计算在各子带内每帧的能量图E(c,m)。沿时间轴方向对子带能量进行能量规整:
(14)
c=1,2,…,C,m=1,2,…,M
(15)
其中,th0为低能量判决门限,th1为高能量判决门限。
首先检测浊音,在频率小于950 Hz的低频区(中心频率离950 Hz最近的子带记为Cs),浊音一定会有能量中心,而清音或者背景噪声在此区域内的能量与浊音的谐波能量相比,几乎可以忽略不计[15]。按以下约束对各帧进行标记:
c=1,2,…,Cs,m=1,2,…,M-1
(16)
其中,V表示浊音,X表示未定。标记为V的所有帧记为集合setV,标记为X的所有帧记为集合setX。
清音在高频区(频率大于950 Hz)虽然没有能量中心,但和静音相比有明显的能量分布,在setX中各帧按照以下约束进行标记:
c=Cs…C,m∈setX
(17)
其中,U表示清音,S表示静音,清音帧的集合记为setU,静音帧的集合记为setS。
3.2 分割初判决
对分帧信号标记浊音、清音、静音以后,可以得到语音的连续片段,称为子段,记为S,Si={x1,x2,…,xMi},xj是第j帧的特征矢量,Mi是第i段的帧数。说话人A说了一串语音,该段语音中包含若干A的子段,然后转变成B的若干子段。属于同一说话人的子段之间相似度较高,而不同说话人之间的相似度较低。对完整语音按照说话人不同进行分割,就可以通过检验相邻的子段对(Si,Si+1),对以下2种假设做出判决:
(18)
这是模型选择问题,如果p(H0)>p(H1),则假设H0成立,反之亦然。对子段的特征训练单高斯模型,Si~N(μi,Σi),Si+1~N(μi+1,Σi+1),Si∪Si+1~N(μ,Σ),单高斯模型对特征进行似然度打分:
(19)
(20)
(21)
此时判决结果可以表示为:
(22)
贝叶斯信息准则(BIC)在模型选择问题上具有较好的性能,并有广泛的应用[16],贝叶斯信息准则满足:
(23)
其中,D是GECC特征维度,λ是调节因子,一般设为1即可。
对所有相邻的子段对(Si,Si+1)进行贝叶斯信息准则判决,得到分割初步判决结果。
3.3 区间验证
经过贝叶斯信息准则判决后,已经得到一定数量的说话人转换点,区间验证的作用是试图利用音高信息,对可疑的转化点进行剔除,并尝试找回已经被遗漏的转化点。
根据贝叶斯信息准则判决产生的相邻转换点之间的时间帧区间内存在的子段个数N,采用不同的处理策略。
当N=1时,两相邻转换点之间有一个孤立子段,此时判断孤立子段两侧转换点之间的时间间隔是否足够小,如果小于1 s且孤立子段的音高和左右两侧有一边比较吻合,就剔除掉吻合度较低的那一侧的转化点。当1
4 实验设置与数据分析
测试数据库选用conTIMIT数据集[17],一共包含55条语音波形文件,统计语音时长3 675 s,有效分割点数1 071个,平均每个说话人段长3.29 s,最短1.14 s,最长11.75 s,标准差1.75 s。语音采样频率为16 000 Hz,实验中语音分帧帧长20 ms,帧移10 ms,GFCC特征选择23维基本特征加一阶差分特征,MFCC特征选择13维基本特征加一阶差分特征。
对说话人转化检测的性能评价,用等错率和F1值。当虚警率(False Alarm Rate,FAR)和漏报率(Miss Detection Rate,MDR)相等时,得到等错率(Equal Error Rate,EER):
(24)
(25)

(26)
用召回率(Recall)和准确率(Precision)计算F1值:
(27)
(28)
(29)
其中,FA是转换点虚报个数,MD是未检测出的转换点个数,GT是实际的转换点个数,GD是正确检测出的转换点个数。
在数据集上用贝叶斯信息准则作为距离准则得到说话人转换点,并和加权距离度量(Weighted Distance Measure,WDM)[18]准则检测的性能做对比。表1给出浊音子段、清音子段、语音子段(包含浊音和清音)的段长统计信息。分别计算分割边界转换点的漏报率-虚警率曲线,如图3~图5所示,对应的等错率结果如表2所示。单独计算浊音子段,BIC和WDM两种方法的转换点与检测点都是非常差的,80%的子段段长落在0.1 s~0.5 s范围内,造成BIC失效。在同样极短时间的条件下,清音子段的表现比浊音好得多。把相邻浊音和清音连接成语音子段,段长平均达到1.34 s,与说话人识别的最低2 s的要求已经比较接近,GECC特征在BIC准则下达到最好检测效果,等错率降到26.8%。

表1 浊音、清音、语音段长统计 s
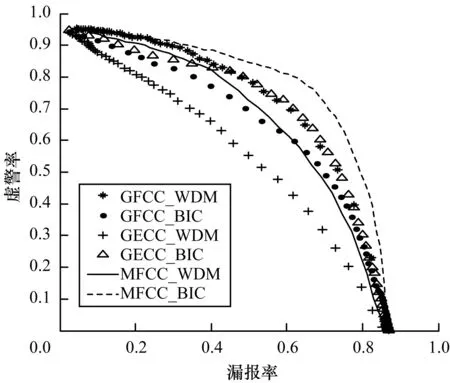
图3 浊音子段(V-S)虚警率和漏报率曲线
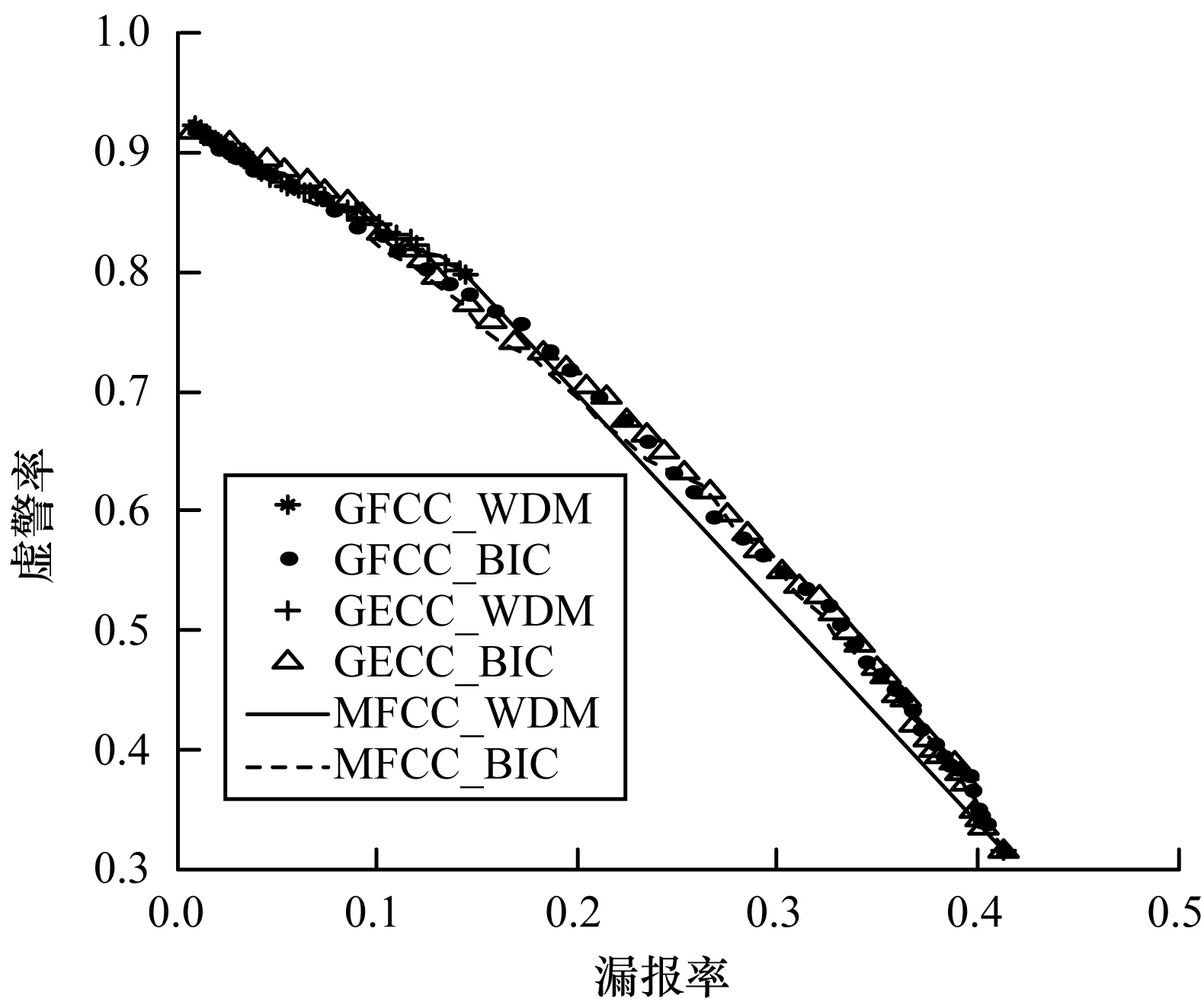
图4 清音子段(U-S)虚警率和漏报率曲线

图5 语音子段(UV-S)虚警率和漏报率曲线

表2 不同特征、不同子段类别切分等错率 %
浊音子段的音高特征在说话刚开始时会出现跳高音陡降至稳态基频区的过程,在说话结束时几乎都会发生从稳态基频降频的收尾效应,但在同一个说话人语音内跳跃幅度比较平稳,在区间验证的过程中利用这一信息,既可以剔除掉一些虚警转换点,也可以找回一些已经漏掉的转换点,从表3可以看到最终的等错率可以下降到23.2%,相应的F1值为70.0%。

表3 结合音高补偿后的检测性能 %
5 结束语
在基于听觉场景分析的说话人转变检测中,由于伽马通滤波器和毛细胞模型对人耳听觉系统的模拟,可以将语音信号按照人的听觉感知对各个频带进行精细划分,得到准确的清音和浊音信息以及稳健的基频轨迹。基于此,本文一种提出基于听觉场景分析的说话人转换检测方法。将语音分割成相邻的若干语音子段(包含清音、浊音、极短静音),提取伽马通能量倒谱系数特征,在贝叶斯信息准则的判决下得到初始说话人转换点,最后利用浊音的基频特征对漏检和错检的转换点进行后处理,最终得到较好的检测结果。在conTIMIT数据集上的测试结果表明,不做音高检测,最优性能是选用GECC特征在BIC准则下等错率达到26.8%,利用音高信息,得到GFCC特征在BIC准则下性能提高到23.2%,GECC和GECC特征的性能优于MFCC,BIC准则优于WDM准则,在短时语音说话人快速转变的口语对话环境中,即使无法训练说话人模型,也可以达到一定的检测准确性。
[1] BAZYAR M,SUDIRMAN R.A New Speaker Change Detection Method in a Speaker Identification System for Two-speakers Segmentation[C]//Proceedings of 2014 ACM Symposium on Computer Applications and Industrial Electronics.New York,USA:ACM Press,2014:141-145.
[2] MALEQAONKAR A S,ARIYAEEINIA A M.Efficient Speaker Change Detection Using Adapted Gaussian Mixture Models[J].IEEE Transactions on Audio,Speech,and Language Processing,2007,15(6):1859-1869.
[3] ZAHID S,HUSSAIN F,RASHID M,et al.Optimized Audio Classification and Segmentation Algorithm by Using Ensemble Methods[J].Mathematical Problems in Engineering,2015(11):209-214.
[4] 郑继明,张 萍.改进的BIC说话人分割算法[J].计算机工程,2010,36(17):240-242.
[5] KOTTI M,BENETOS E,KOTROPOULOS C.Computa-tionally Efficient and Robust BIC-based Speaker Segmenta-tion[J].IEEE Transactions on Audio,Speech,and Language Processing,2008,16(5):920-933.
[6] YANG J,HE Q,LI Y,et al.Speaker Change Detection Based on Mean Shift[J].Journal of Computers,2013,8(3):638-644.
[7] WU Z,EVANS N,KINNUNEN T,et al.Spoofing and Countermeasures for Speaker Verification:A Survey[J].Speech Communication,2015,66(1):130-153.
[8] 张学良,刘文举,李 鹏,等.改进谐波组织规则的单通道浊语音分离系统[J].声学学报,2011,36(1):88-96.
[9] CUSACK R,DECKS J,AIKMAN G,et al.Effects of Location,Frequency Region,and Time Course of Selective Attention on Auditory Scene Analysis[J].Journal of Experimental Psychology:Human Perception and Performance,2004,30(4):643-656.
[10] MAKA T.Change Point Determination in Audio Data Using Auditory Features[J].International Journal of Electronics and Telecommunications,2015,61(2):185-190.
[11] MEDDIS R.Simulation of Mechanical to Neural Transduction in the Auditory Receptor[J].The Journal of the Acoustical Society of America,1986,79(3):702-711.
[12] LI L.Performance Analysis of Objective Speech Quality Measures in Mel Domain[J].Journal of Software Engineering,2015,9(2):350-361.
[13] KAUR G,SINGH D,RANI P.Robust Speaker Recognition Biometric System a Detailed Review[J].Emerging Research in Management & Technology,2015,4(5):281-288.
[14] 王 民,任雪妮,孙 洁.一种高效的基音检测与评估算法[J].计算机工程与应用,2014,50(14):126-132.
[15] 胡 瑛,陈 宁.基于小波变换的清浊音分类及基音周期检测算法[J].电子与信息学报,2008,30(2):353-356.
[16] CHEN S,GOPALAKRISHNAN P.Speaker,Environment and Channel Change Detection and Clustering via the Bayesian Information Criterion[C]//Proceedings of Broadcast News Transcription and Understanding Workshop.San Francisco,USA:Morgan Kaufmann Publishers,1998:127-132.
[17] SEO J S.Speaker Change Detection Based on a Graph-partitioning Criterion[J].The Journal of the Acoustical Society of Korea,2011,30(2):80-85.
[18] KWON S,NARAYANAN S S.Speaker Change Detection Using a New Weighted Distance Measure[C]//Pro-ceedings of the 7th International Conference on Spoken Language Processing.Washington D.C.,USA:IEEE Press,2002:2537-2540.
