基于多视角自步学习的人体动作识别方法
2018-03-02刘莹莹
刘莹莹,邱 崧,孙 力,周 梅,徐 伟
(1.华东师范大学 信息科学技术学院 上海市多维度信息处理重点实验室,上海 200241;2.上海交通大学 图像处理与模式识别研究所,上海 200240)
0 概述
人体动作识别是计算机视觉领域中的主要研究方向之一,其广泛应用于人机交互、虚拟现实、智能监控、人体运动分析等领域,因此,基于视频的人体动作识别具有非常重要的学术研究价值。
视频中人体动作识别的核心方法是从视频序列中提取能够有效描述动作特征的视觉信息,再通过机器学习算法对其进行分类,最终实现人体动作识别。动作识别的设计方法一般可以从特征设计、分类器设计2个角度出发。本文属于后者。
动作识别中常用的分类器设计方法主要分为基于模板的方法、基于概率统计的方法以及基于语法的方法。基于模板匹配的方法[1-2]较简单,但乏鲁棒性,常用于静态姿势或简单动作的识别;基于语法的方法[3]计算复杂度高,且其鲁棒性依赖于底层描述;基于概率统计的方法[4-5]在目前应用最广泛,该方法用一个连续的状态序列表示动作,每个状态都有自己的特征描述,用时间转移函数表示状态之间的切换规律。常见的基于概率统计的动作识别方法有支持向量机(Support Vector Machine,SVM)[6]、条件随机场(Conditional Random Fields,CRF)[7]等,这些方法需大量的训练数据来学习模型参数,且未考虑训练样本的学习顺序对学习效果的影响。
文献[8]提出课程学习算法,先用简单样本进行训练,逐步引入复杂样本,通过该机制设置合理的学习次序,可有效地提升算法的收敛速度及局部最优解的质量[9]。文献[10]在课程学习算法的基础上提出自步学习(Self-Paced Learning,SPL)。SPL的课程由模型本身基于其已经学到的内容动态生成,而非预先定义的启发式标准。文献[11]将SPL算法引入动作识别领域,SPL算法具有对于有标签训练样本需求比较低、鲁棒性好等优点,效果远好于常规机器学习算法,尤其是对较难的数据集,课程的优越性更加明显,但该算法忽略了不同视角对课程的影响。对于多分类的复杂人体动作识别,每个人的每类动作往往有不同的显著特征,因此,不同视角下的特征描述对所有类的区分能力不同,对应的课程难易度各异。
针对上述算法的不足,本文提出一种多视角自步学习(Multi-view Self-Paced Learning,MSPL)算法,将不同视角下的不同课程进行融合,学习得出更适合解决动作识别问题的综合课程。
1 MSPL算法
本文提出一种基于MSPL的动作识别方法。对于人体动作二维视频序列,提取其在多种视角下的二维特征信息后,利用多分类的SPL算法分别为各个视角训练课程,然后通过线性规划增强(Linear Programming Boosting,LPBoost)方法计算每个视角课程的权重参数,融合学习出综合课程模型。图1为基于MSPL的动作分类器训练流程。当获得测试动作序列特征时,即可用训练好的课程模型进行分类。
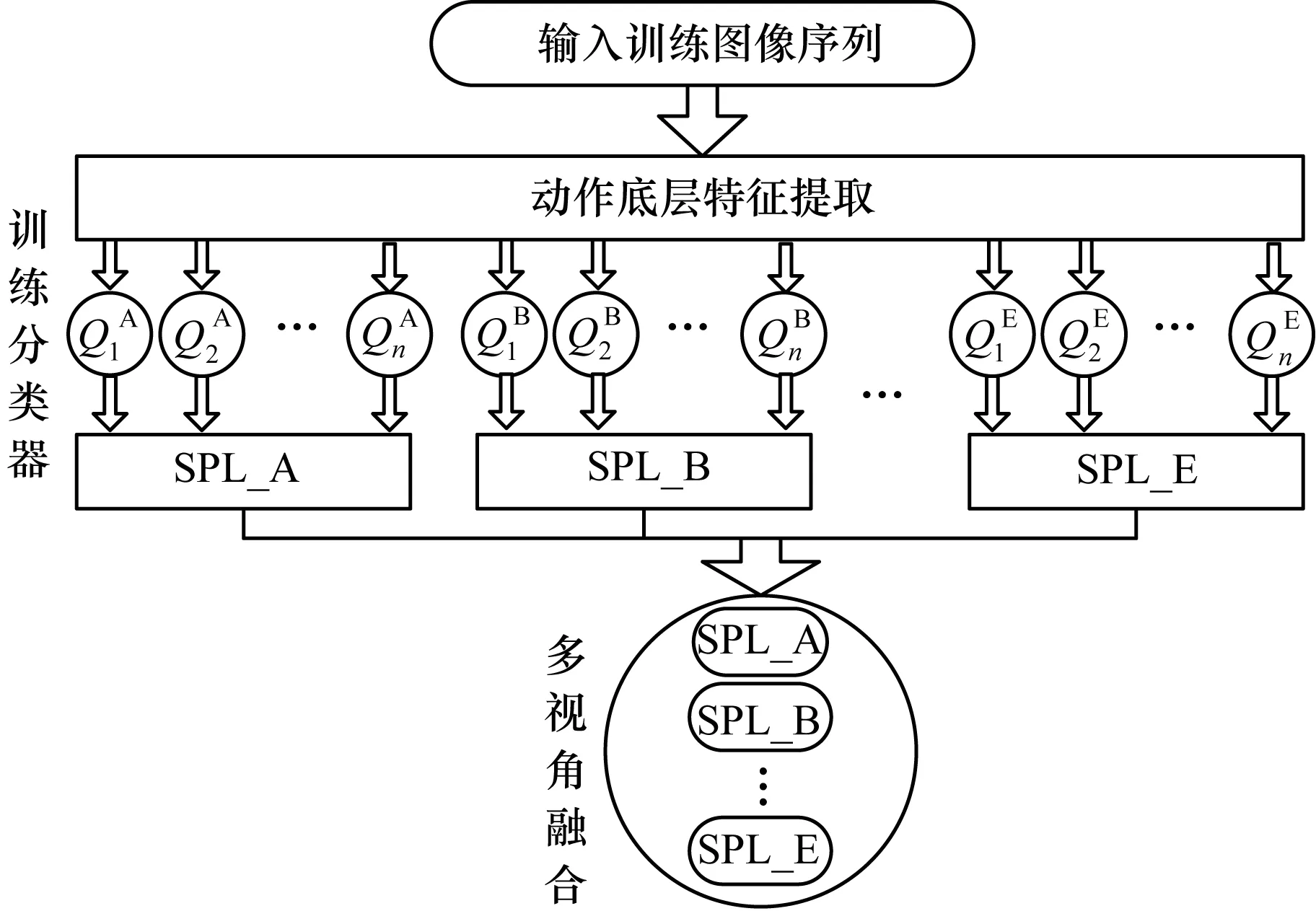
图1 基于MSPL的动作分类器训练流程
1.1 动作底层特征提取
本文在对各类二维视频特征进行综合评估后,选择5种视角下适合人体二维动作视频的底层特征:Trajectory[12],HOG[13],HOF[14],MBHx和MBHy[15](分别用视角A、B、C、D、E表示)。为了验证本文多视角融合方法的有效性,将其与各类特征进行简单合并的多特征融合方法作对比。现将5种底层特征进行简单合并得到COM特征[12],特征提取过程如下:
1)将RGB图片合成为.avi格式的视频序列,一个动作对应一个视频段。
2)分别提取人体动作序列的5种底层特征Trajectory、HOG、HOF、MBHx和MBHy,并将5种底层特征进行简单合并得到COM特征。
3)采用基于核密度估计(Kernel Density Estimation,KDE)的特征选择算法对上述底层特征进行降维。
4)将训练样本集中的数据进行聚类,以每个聚类中心为一个单词,组成字典。
5)对降维后的特征进行稀疏编码,生成稀疏向量。
6)使用最大值合并算法,得到稀疏向量的全局统计特性,最终用一个视频集特征代表一个人体动作序列。
1.2 训练分类器
输入多个视角多种类别人体动作数据集的特征及其所对应的标签:
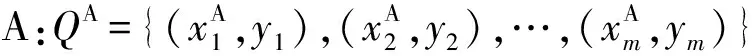
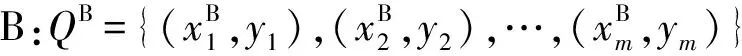
⋮
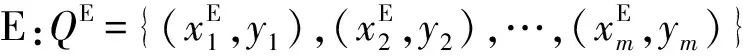
其中,Q表示训练数据集的特征描述及标签的集合;xi表示第i个观察样本的特征向量;yi∈(1,2,…,C)表示相应的类别标签;m为训练数据集的长度。
参数学习对于每个视角的特征描述,采用多分类的SPL算法训练学习出相应的课程,用SPL_A、SPL_B、SPL_C、SPL_D、SPL_E表示,具体过程参阅1.3节内容。
融合用LPBoost方法计算各个课程的权重参数,融合学习得出综合的课程模型。具体过程参阅1.4节内容。
1.3 SPL算法
SPL算法以人的教学过程为背景,先从简单样本开始进行训练,逐步引入复杂样本,并在此基础上考虑“学习者的反馈”。具体的过程如下。
对于训练数据集:
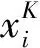

(1)
其中,参数λ用来控制学习进度。
式(1)表明样本的损失值受到相应的权重值影响。SPL目的是使E(ωK,vK;λK)值最小。
通常用交替凸搜索 (Alternative Convex Search,ACS)方法[10]来求解式(1)。
1.4 多视角融合
为了实现多视角融合,本文用LPBoost[17-18]方法学习出每个视角下课程的权重参数,即通过求解下面的线性过程[16]得到权重矩阵B:
(2)
(3)
i=1,2,…,n,yj≠yi
(4)
(5)
εi≥0,i=1,2,…,n
(6)

1.5 测试与结果输出
向训练好的分类器输入待识别人体动作数据集的多视角特征向量:
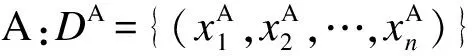
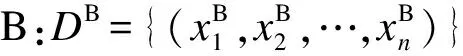
⋮
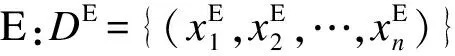
其中,D为待识别数据集的特征描述;xi表示第i个待识别样本的特征向量;n为待识别数据集的长度。
该过程输出每类动作的识别结果:
(7)
其中,fs,yi(xi)表示xi样本在s视角下的SPL模型所预测出的yi类别的值。
2 实验结果与分析
2.1 实验数据
为了验证本文方法的识别效果,利用UTKinect-Action[19]和Florence3D-Action[20]2个数据集进行实验。UTKinect-Action数据集包括扔、推、拉、挥手、鼓掌、行走、起立、坐下、捡起、搬运10种动作类型。 Florence3D-Action数据集包括喝水、接电话、拍手、系鞋带、坐下、看手表、起立、鞠躬、挥手9种动作。这2个数据库提供了二维图像数据、深度信息图以及骨骼关节的位置数据。本文实验仅利用数据集的二维图像数据,即RGB图片(如图2所示),因为在实际应用中很容易由普通摄像机获取二维图像数据。

图2 UTKinect-Action数据集
2.2 实验过程
2.2.1 实验设置
分别用单视角的SPL和SVM方法,以及基于上述2种方法的多视角融合方法进行实验,对UTKinect-Action数据集的199个动作样本进行随机处理,其中80个用作训练样本,20个用作验证样本,99个用作测试样本。对Florence3D-Action数据集采用类似的设置。
2.2.2 最优参数的选取
SVM常用交叉验证方法[21]获取最优的惩罚系数c和核函数半径gamma。首先在一定的范围内对c和gamma取值,然后利用训练样本和验证样本进行5-折交叉验证,得到此组c和gamma下由验证样本得到的分类准确率,最终取使验证数据集分类准确率最高的一组c和gamma作为最佳的参数。为了统一标准,在对同一视角的特征进行分类实验时,SPL和SVM 2种方法的参数c、gamma都采用相同的最优参数设置。
2.3 结果分析
表1和表2分别是UTKinect-Action数据集和Florence3D-Action数据集在利用验证样本求得最优参数后,在5种不同单一视角下的SVM和SPL分类准确率、利用COM特征的SVM和SPL分类准确率以及本文LPBoost融合方法的SVM和SPL分类准确率。
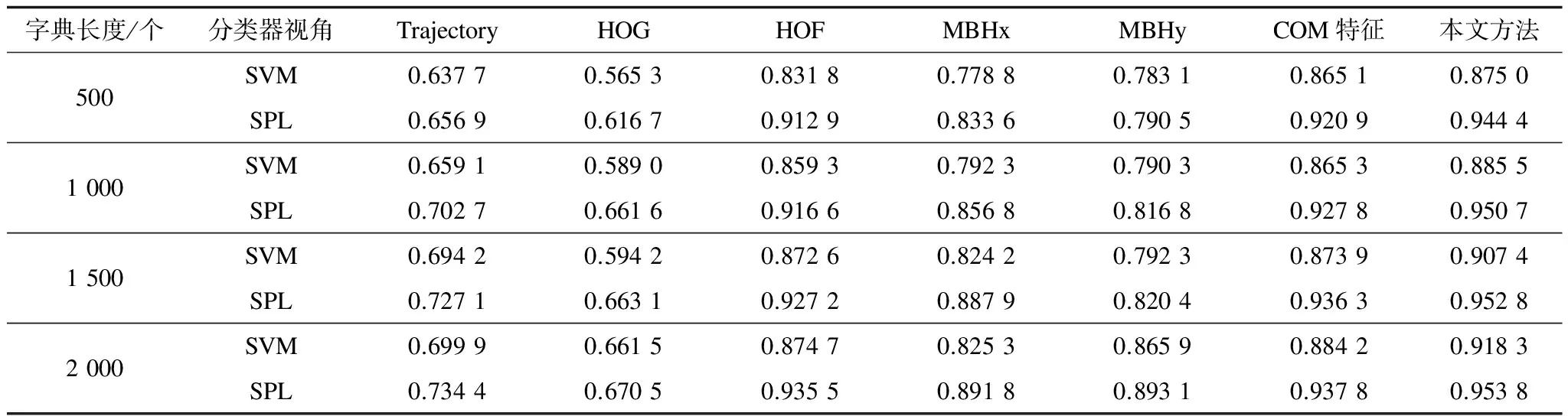
表1 不同方法在UTKinect-Action数据集上的识别结果

表2 不同方法在Florence3D-Action数据集上的识别结果
2.3.1 分类器效果分析
在UTKinect-Action数据集上,对SVM、SPL以及本文多视角融合方法的SVM、SPL(以MSVM、MSPL(OURS)表示)4种分类器的效果进行比较。对SVM、SPL分类器进行比较时,在表1中选取识别效果最好的视角特征HOF。由于SPL算法按照课程学习的思路,先从简单样本开始进行训练,逐步引入复杂样本,并在此基础上考虑分类器的学习情况,因此理论上SPL的分类效果应该比SVM好,同理,MSPL的分类效果比MSVM好。 从图3的实验结果中可以看到,在相同的字典长度和视角下,SPL的分类效果都比SVM好,SPL比SVM的分类准确率平均高5%左右。在相同字典长度下,MSPL的分类效果都比MSVM好,MSPL比MSVM的分类准确率平均高5.3%左右,验证了课程学习思路的有效性。MSVM的分类准确率都高于SVM,MSPL的分类准确率都高于SPL,验证了多视角融合方法确实可以提升分类准确率,且MSPL可以学到更加适合动作识别问题的综合课程。在字典长度比较小的情况下,SVM和SPL分类器对视角的选取比较敏感,此时多视角融合方法可以显著提升分类器的识别效果。选取识别效果最好的视角特征时,MSVM的分类准确率比SVM平均高3%左右,MSPL的分类准确率比SPL平均高5%左右。

图3 分类器对识别结果的影响
2.3.2 融合方法分析
从图4中可以看到,在相同的字典长度下,用本文融合方法(MSVM、MSPL)得到的识别准确率都高于将多视角特征进行简单合并的融合方法(以CSVM、CSPL表示),验证了本文利用LPBoost进行多视角融合的方法更加有效,且表明MSPL可以学到更适合解决动作识别问题的综合课程。
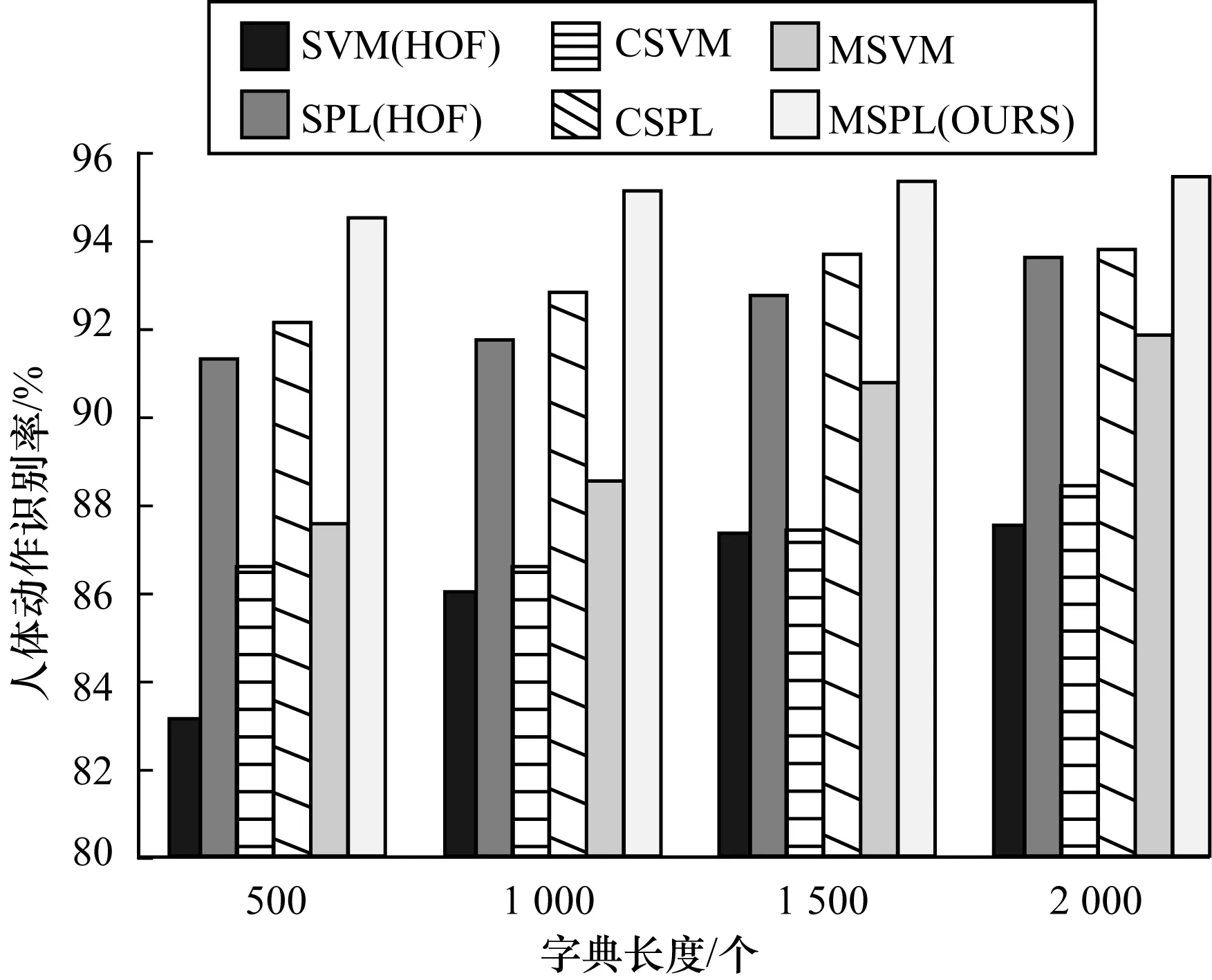
图4 融合方法对识别结果的影响
2.3.3 字典长度分析
从表1实验结果可以分析出,当字典长度增大时,识别率普遍会有一个显著的提升,因为字典长度越大,特征描述越全面。但在字典长度达到一定大小后,识别率提升幅度减小,甚至趋于平稳。随着字典长度增加,计算时间相应增大。所以,进行动作识别时需要合理选择字典长度,综合考虑识别效果和识别过程的耗时。
2.3.4 训练样本长度分析
用UTKinect-Action和Florence3D-Action 2个数据集分别对SVM、SPL、MSVM和MSPL(OURS)进行训练样本长度分析实验,字典长度设置为500个。
UTKinect-Action数据集共199个样本,随机选取训练样本,样本大小分别设置为40个、50个、60个、70个、80个,选取99个测试样本,其余为验证样本。对于Florence3D-Action数据集采用类似的设置。实验结果如图5所示。可以看出:随着训练样本长度的增大,SPL和MSPL 2种分类器的识别率相对较高且上升幅度较小,基本趋近平稳;SVM和MSVM 2种分类器得到的识别准确率都呈现明显的上升趋势,但大小仍明显低于SPL和MSPL。实验结果表明,SPL和MSPL的鲁棒性较好,尤其针对有标签的训练样本比较少时,仍能保持比较稳健的性能,再次验证了本文MSPL分类器的识别效果优于其他3种分类器(SVM、SPL、MSVM)。

图5 多视角融合方法中训练样本长度对识别结果的影响
2.3.5 参数敏感度分析
本文在UTKinect-Action数据集(500个单词的字典长度)上,测试SVM、SPL、MSVM、MSPL 4种分类器对c和gamma2个参数的敏感度。从图6可以看到,SVM分类器的识别结果随着参数c和gamma变化的波动范围较大,SPL分类器的识别结果随着参数c和gamma变化的波动范围减小,说明SPL较SVM对参数不敏感,自身鲁棒性较好。MSVM分类器对参数的敏感性与SVM相似,MSPL分类器对参数的敏感性与SPL相似,MSPL分类器较MSVM分类器鲁棒性更好。
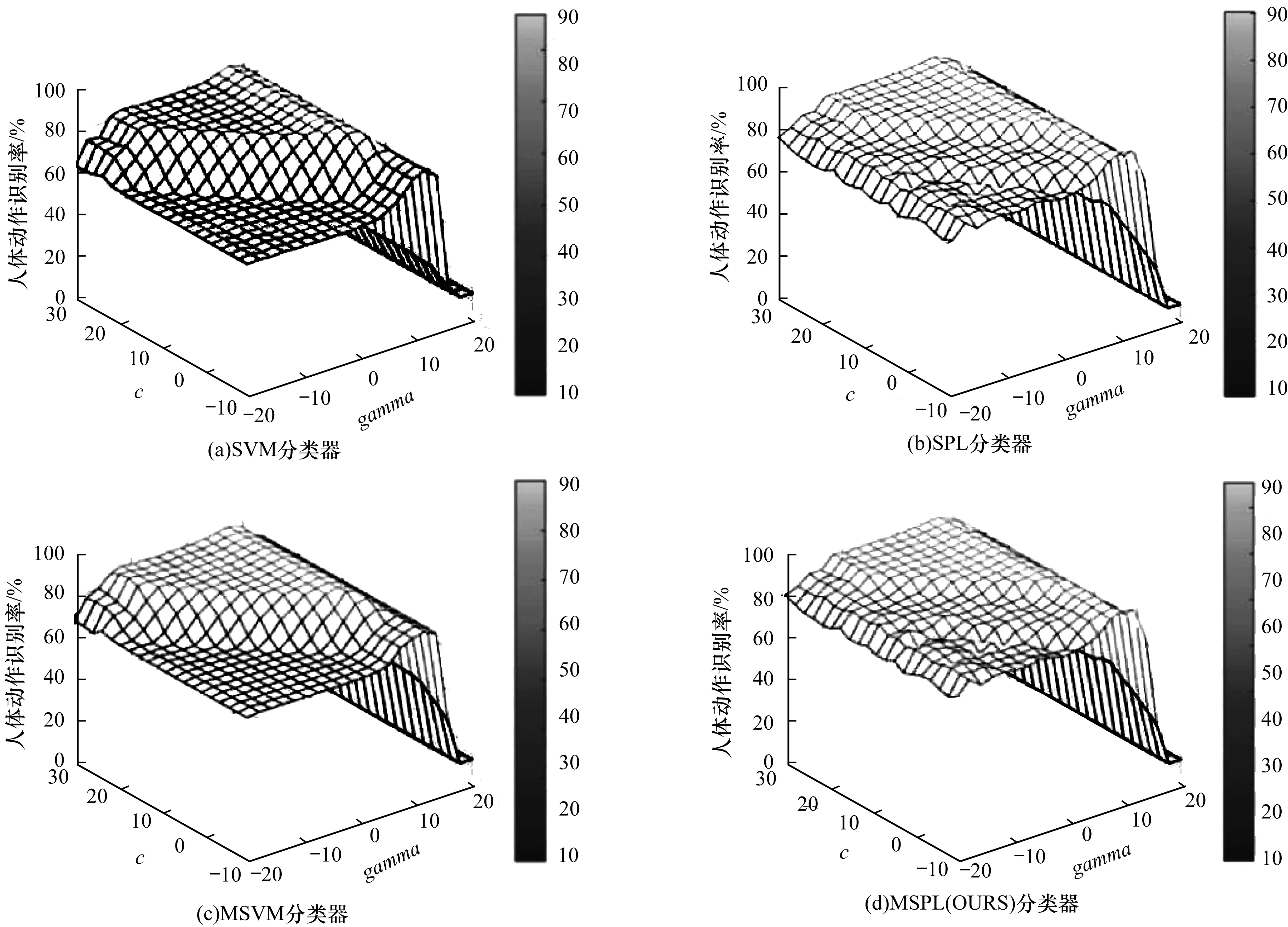
图6 UTKinect-Action数据集在不同分类器下的识别结果对比
3 结束语
本文改进SPL动作识别算法,提出基于MSPL模型的人体两维视频动作识别方法。该方法在保留SPL本身优良特性的基础上,能够融合各个不同视角下学习的课程,获取更适合解决动作识别问题的综合课程,从而提高动作识别的准确率。在2个识别难度较高的多类复杂动作数据集上进行实验,结果表明本文算法具有较高的准确率与鲁棒性。此外,本文选取的5个视角动作特征仅需使用普通两维摄像机即可获取,无需升级现有视频捕获设备,相较于依靠三维特征信息的动作识别方法,具有成本低廉、实时性高和数据处理量小等优点,可应用于道路暴力行为监控、商场偷窃行为监测等领域。本文将各个视角下单独学习的基础课程进行融合,但每个视角下课程的内容有一定的联系性,因此,后续的工作将集中于挖掘每个课程之间的联系,同时联合学习得出更全面高效的课程。
[1] 罗会兰,冯宇杰,孔繁胜.融合多姿势估计特征的动作识别[J].中国图象图形学报,2015,20(11):1462-1472.
[2] LIU J,ALI S,SHAH M.Recognizing Human Actions Using Multiple Features[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recog-nition.Washington D.C.,USA:IEEE Press,2008:1-8.
[3] NEVATIA R,ZHAO T,HONGENG S.Hierarchical Language-based Representation of Events in Video Streams[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshop.Washington D.C.,USA:IEEE Press,2003:38-39.
[4] YAMATO J,OHYA J,ISHII K.Recognizing Human Action in Time-sequential Images Using Hidden Markov Model[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,1992:379-385.
[5] SHI Q,CHENG L,WANG L,et al.Human Action Segmentation and Recognition Using Discriminative Semi-markov Models[J].International Journal of Computer Vision,2011,93(1):22-32.
[6] 朱国刚,曹 林.基于Kinect传感器骨骼信息的人体动作识别[J].计算机仿真,2014,31(12):329-333.
[7] NATARAIAN P,NEVATIA R.View and Scale Invariant Action Recognition Using Multiview Shape-flow Models[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2008:1-8.
[8] BENGIO Y,LOURADOUR J,COLLOBERT R,et al.Curriculum Learning[C]//Proceedings of the 26th Annual International Conference on Machine Learning.New York,USA:ACM Press,2009:41-48.
[9] BENGIO Y,COURVILLE A,VINCENT P.Representation Learning:A Review and New Perspectives[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1798-1828.
[10] KUMAR M P,PACKER B,KOLLER D.Self-paced Learning for Latent Variable Models[C]//Proceedings of the 23th Annual Conference on Neural Information Processing Systems.Cambridge,USA:MIT Press,2010:1189-1197.
[11] JIANG L,MENG D,YU S I,et al.Self-paced Learning with Diversity[C]//Proceedings of the 27th Annual Conference on Neural Information Processing Systems.Cambridge,USA:MIT Press,2014:2078-2086.
[12] WANG H,KLASER A,SCHMID C,et al.Dense Trajectories and Motion Boundary Descriptors for Action Recognition[J].International Journal of Computer Vision,2013,103(1):60-79.
[13] DALAL N,TRIGGS B.Histograms of Oriented Gradients for Human Detection[C]//Proceedings of IEEE Con-ference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2005:886-893.
[14] LAPTEV I,MARSZALEK M,SCHMID C.Learning Realistic Human Actions from Movies[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2008:1-8.
[15] DALAL N,TRIGGA B,SCHMID C.Human Detection Using Oriented Histograms of Flow and Appearance[C]//Proceedings of European Conference on Computer Vision.Berlin,Germany:Springer,2006:428- 444.
[16] GEHLER P V,NOWOZIN S.Let the Kernel Figure It out:Principled Learning of Preprocessing for Kernel Classi-fiers[C]//Proceedings of IEEE Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2009:2836-2843.
[17] 许允喜,蒋云良,陈 方.基于支持向量机增量学习和LPBoost的人体目标再识别算法[J].光子学报,2011,40(5):758-763.
[18] 方育柯,傅 彦,周俊临,等.基于选择性集成的最大化软间隔算法[J].软件学报,2013,34(5):1132-1147.
[19] XIA L,CHEN C C,AGGARWAL J K.View Invariant Human Action Recognition Using Histograms of 3D Joints[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops.Washington D.C.,USA:IEEE Press,2012:20-27.
[20] SEIDENARI L,VARANO V,BERRETTI S,et al.Recognizing Actions from Depth Cameras as Weakly Aligned Multi-part Bag-of-poses[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops.Washington D.C.,USA:IEEE Press,2013:479-485.
[21] 汤荣志,段会川,孙海涛.SVM训练数据归一化研究[J].山东师范大学学报(自然科学版),2016,31(4):60-65.
