基于HDP模型的领域微博主题演化研究
2018-03-02高永兵杨利莹胡文江马占飞
高永兵,杨利莹,胡文江,马占飞
(1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010; 2.包头师范学院 信息工程系,内蒙古 包头 014010)
0 概述
近年来,微博已经成为最具即时性的信息共享公共平台,不仅可以在第一时间分享社会热点、交流看法和观点,也能及时传播专业领域的发展信息。以2016年旅游业为例,相关博文数近12.5亿,旅游业用户达9 623万,这些微博反映出该领域的重要信息,具有较高的参考价值,以时间为轴线对领域的发展情况进行追踪具有重要意义。主题提取可以高度概括重要信息,提高阅读效率,目前,国内外学者都针对主题演化开展了相关研究。现存的主题演化研究方法可以归纳为3类:基于社会网络的方法,基于本体的方法和基于主题模型的方法。基于社会网络的方法[1-2]将主题表示为网络节点,主题间的演化关系用节点间的有向边表示,边的权重代表演化强度,演化强度与主题词和引文有关,但是这种基于链接的方法对于新出现的主题敏感度不高,此外由已经出现的主题可能会链接到下一个无关主题从而造成主题漂移;基于本体的方法[3-4]关注主题的语义信息和增量构建过程,借鉴词共现思想,结合本体构建主题与主题间的关系网络,然而该方法对训练集的依赖性很大,不适用于动态主题演化过程。基于主题模型的方法能够自动挖掘潜在的语义信息,且模型的灵活度高,能够根据不同的应用场景做出相应的调整,具有较强的适用性。
主题模型中应用最广泛的是由文献[5]提出的潜在Dirichlet分布(Latent Dirichlet Allocation,LDA)模型,以此模型为基础衍生出许多主题演化模型[6-8],解决了原始LDA模型忽略文本的时间信息而无法描述文本主题演化的问题。然而以LDA为基础的主题模型需要人为预先指定主题数目,在整个事件的演化过程中,主题的数目是不固定的,某个主题也并非贯穿于整个事件的始终。例如,“人民币加入SDR”包含多个主题,随着时间推移,微博上讨论的主题从前期的一系列基础准备工作到如何适应市场发展,再到加入SDR后给中国经济带来的影响。在没有任何先验知识的前提下,很难准确把握主题数量。为克服以上问题,研究者提出了分层Dirichlet 过程(Hierarchical Dirichlet Process,HDP)模型[9],利用狄利克雷过程(Dirichlet Process,DP)无限维度的特征实现主题数目的自动确定。
主题演化是传统主题挖掘技术的延伸与发展,指的是按照时间发展顺序对不同阶段的文本进行主题分析,要求既能概括文本信息,又能表现发展动态。对领域微博进行主题演化研究存在诸多难点。首先,传统的主题模型都是针对长文本提出的,如何调整主题模型以适应微博数据的短文本性和交互性是一大难点;此外,随着社会分工的细化,存在许多交叉行业与领域,如何准确地抽取指定行业领域的微博也是需要考虑的问题;最后,利用主题模型挖掘出领域微博的主题后,如何既能表现该领域的主题分布,又能增加对新主题的敏感性既而表达其演化过程,也是一个难点。
综合考虑以上问题,本文提出一种针对领域微博主题演化的分析方法。首先,基于用户标签和简介的领域微博提取出领域微博数据;然后,综合考虑领域特征和时间特征,构建适用于领域微博主题挖掘的DM-HDP模型,并设计相应的采样方法推导该模型;最后,在真实的数据集上进行实验,验证DM-HDP模型的有效性。
1 相关研究
关于主题演化最早的研究可以追溯到文献[10]中提出的动态主题挖掘思想,该思想将连续的文本按时间段划分,以LDA模型为基础对每个时段内的文本建模,综合考虑α和β参数随时间的变化,建立LDA模型链,最后得到随时间变化的主题分布。然而这种方法得到的主题数目是固定的,与实际情况不符。文献[11]中提出的时段性DP混合模型,假定每个时期内的主题数量不限定,随时间的推移可以产生新的主题,已存在的主题可以保留或者消亡。该方法解决了主题数量不确定的问题,但是运用了循环中国餐馆构造过程(Chinese Restaurant Construction Process,CRCP)采样推导,假设每个词仅属于一个主题,忽略了文本单词一词多义的特性,丢失单词部分主题信息,导致模型的精度降低。文献[12]提出基于HDP模型的主题演化方法,该方法构建了三层DP代表不同层次的主题分布,认为某时段的主题分布受上一时段的参数影响,结合折棒构造方法(Stick-breaking construction)和CRCP实现动态的文本主题挖掘。该方法通过建立动态主题模型系统性地挖掘文本流的主题分布,却没有对主题的演化过程进行分析,呈现的结果不直观。文献[13]中提出的一种面向多文档流的主题演化模型,允许每个文本流都有本地主题和共享主题,为每个主题的受欢迎程度建立时间变化函数,定量地分析主题变化规律。文献[14]在LDA模型的基础上增加DP,不仅能获取模型的隐变量,还能完成超参数的动态更新和主题数的变动,然而该方法并没有对子主题的划分做详细介绍。文献[15]中提出的在线分层DP的非参数贝叶斯模型,主题的演化过程分为2个层次,对时间块内的文档建立在线HDP模型,对跨时间块的文档用时间衰减函数衡量其时间相关性,假设当前主题分布受之前几个时段主题分布的影响,就造成系统对新主题敏感度不高。
上述研究都基于长文本,对于微博这种短文本不一定适用。文献[16]提出用于挖掘微博主题的MB-LDA模型,综合考虑微博的联系人信息和文本信息,改进LDA模型以适应微博的特殊结构。文献[17]提出MB-HDP模型,利用微博的时间信息、用户兴趣和话题标签,聚合主题相关的信息。至此,目前还很少有关于领域微博主题演化的研究。
主题演化过程需考虑的两大因素是内容和时间,一方面要求在内容上按主题进行分类识别,另一方面又要保证时间上的延续和关联。本文首先按照用户标签提取出领域微博,然后以时间周期为界,将领域微博划分为多个独立单位,在此单位内部忽略时间信息,建立领域微博主题模型DM-HDP,以挖掘该时段的主题分布,将主题划分到不同的大主题下,按时间顺序为相同的大主题建立关联,进而分析主题的演化过程。
2 准备工作
2.1 HDP模型
DP是关于分布的分布,其采样点本身就是一个随机概率分布。HDP本质是DP的多层形式,可视为基于贝叶斯的传统主题模型LDA在无参方向的衍生[18]。以下介绍基于文档的两层HDP模型生成过程。首先从基分布H和参数γ构成的DP中,抽样出分布G0;然后从基分布G0和参数α0构成的DP中,为每篇文档抽取主题分布Gj,其中DP代表DP过程。
G0|γ,H~DP(γ,H)
Gj|α0,G0~DP(α0,G0)
θji|Gj~Gj
Wji|θji~Mult(θji)
(1)
式(1)中,θji指示了词Wji的主题。HDP的图模型生成过程如图1所示,其中圆形代表分布,圆角矩形代表参数,阴影部分表示可观测量,矩形表示该过程可循环。
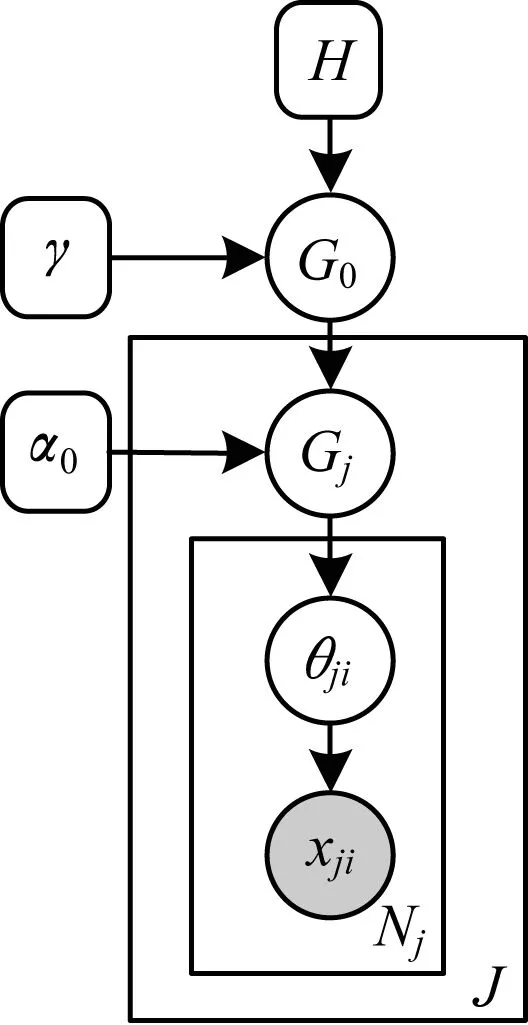
图1 HDP图模型生成过程
2.2 Stick-breaking构造
以上关于HDP的定义并不能直接应用,可应用2次Stick-breaking方法对HDP的过程进行构造,详细的构造过程参见文献[19]。
1)第1层构造如下:
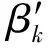
φk~H
(2)
其中,βk表示一组服从Beta分布的随机数,φk表示从基分布H中抽样的点,δφk表示抽样点的值。
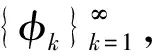
2)第2层构造如下:
πjk~GEM(α0)
φk~H
(3)
其中,πjk表示取δφk点的概率。
该构造方法并没有改变采样点,只是对采样点的权值做连续处理,HDP模型的Stick-breaking构造过程如图2所示。
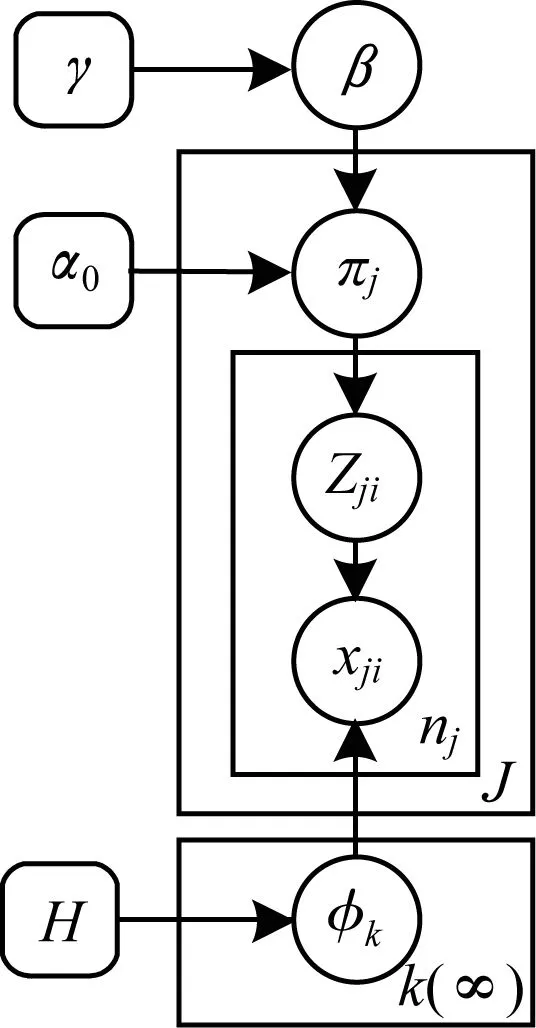
图2 HDP图模型构造过程
2.3 CRCP构造
CRCP将单词匹配主题的过程形象地比喻为顾客挑选餐桌并点菜的过程,具体如下:假设餐馆可容纳无数张餐桌,每张餐桌可容纳无数位顾客,每张餐桌上只供应一道菜。顾客进入餐馆选择餐桌并点菜,顾客可以就坐于已有餐桌也可以选择新餐桌。
1)若就坐于已有餐桌,便可以共享已点的菜肴,其概率与该餐桌上的顾客数量成正比,顾客数越多则被选中的概率越大;
2)顾客也可以以某参数概率选择新餐桌,作为该餐桌的第一位顾客应负责点菜,选择已有菜肴的概率受其被点次数的影响,菜肴被点到的次数越多则再次被点的可能性越大,顾客也可以以参数概率选择新菜肴。
3 领域微博提取
专业领域微博由长期从事具体业务的特定人群发布,带有学科性、技术性的微博数据集合一般带有明显的用户标签及简介信息。用户标签包含丰富的个性化描述信息以及用户本身的特性,能够代表用户的所属行业领域,本文利用用户标签进行领域标识。
首先构建领域关键词词典,通过抓取领域资讯网站的文档,利用现有的基于文本分类的网页爬虫技术[20]及领域模型[21]爬取领域相关信息,分析文档中的关键词,按照关键词词频统计结果,构建领域D={D1,D2,…}。将领域Di的专业词汇集表示为dij={dij1,dij2,…}。
定义1基于用户标签的领域相似度。将用户Ur的标签词汇集d(Ur)={d1,d2,…}与领域Di的专业词汇集dij进行相似度计算,若该领域的专业词汇集dij中的第k个词汇与用户的标签词汇相同(不考虑用户标签词的先后顺序),定义领域相似度如下:
(4)
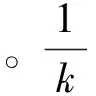
定义2领域特征指数。根据用户Ur的领域相似度ftag,统计其所发布的总微博数T(Ur)以及利用分类模型得到的专业领域微博数D(Ur),定义领域特征指数为:
(5)
分析用户发布的领域特征指数,如果其值大于某阈值,则认为此用户属于该领域,即表示为:
Di(U)={Ur|Ur∈U,F(Ur)>thr1}
(6)
其中,集合U表示用户集合,Ur是集合中的元素。仅当其领域特征指数条件F(Ur)>thr1成立时,此用户属于领域Di,由此得到属于该专业领域的用户集合Di(U)。
4 领域微博生成模型DM-HDP
上一节中,得到了基于用户的领域微博数据,然而其中不可避免地掺杂了如个人生活领悟等非专业领域信息。如果直接进行主题提取,不仅会造成时间上的浪费,也会降低主题提取的精度和质量,所以,本文提出考虑微博类型的DM-HDP模型,对专业领域微博进行主题提取。
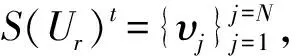

表1 DM-HDP模型中符号含义说明
4.1 模型框架
在DM-HDP模型中,每条领域微博与xv和yv2个参数相联系,代表该微博主题是否为特定时间、是否与专业领域相关,每条微博的主题分布表示为zv。由此将微博分为4类:领域特定时间主题,领域一般时间主题,公共特定时间主题以及公共一般时间主题。由x和y确定的4种微博类型如表2所示。每种微博均在不同的主题分布下,需要建立4种主题分布与之相对应,其中主要任务是领域特定时间主题的识别。

表2 由x和y确定的4种微博类型
xv和yv服从参数为θx和θy的二项分布,分别代表某条微博是特定时间还是任何时间均可讨论的内容,是专业领域相关的还是谈论生活等非领域相关的信息。且θx和θy服从参数为ηx和ηy的Beta分布,表示为:
θx~Beta(ηx),θy~Beta(ηy)
(7)

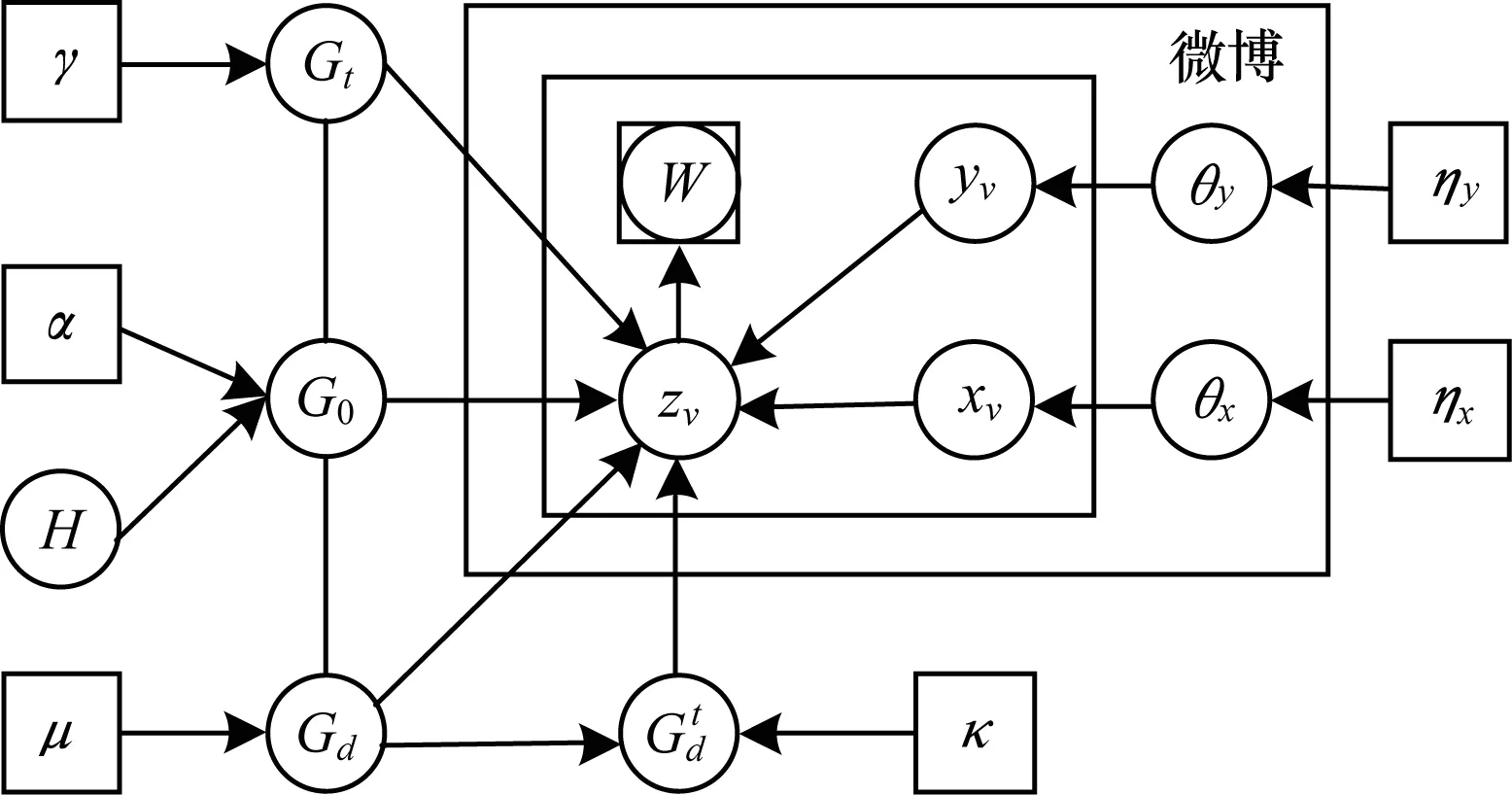
图3 DM-HDP模型的贝叶斯网络

1.Draw measure G0~DP(α,H)
2.For each time t
-draw measure Gt~DP(γ,G0)
3.For each domain parameter μ
-draw θx~Beta(ηx)
-draw θy~Beta(ηy)
-draw measure Gd~DP(μ,G0)
-for each time t:
4.For each microblog υj,for domain d,at time t
-draw xv~Multi(θx)
yv~Multi(θy)
-if x=0,y=0:draw zv~G0
-if x=1,y=0:draw zv~Gt
-if x=0,y=1:draw zv~Gd
-for each word ωji∈υj
*draw wji~Multi(zv)
4.2 Stick-breaking构造
根据式(3),可以将G0构造如下:
(8)
根据式(1),Gt、Gd可以表示为:
(9)
(10)
(11)
4.3 模型推理
MCMC方法基于改进的CRCP,根据可观测量w对所有的分布采样。由于篇幅有限,本文仅给出Gibbs采样的迭代式,详细推导可参考文献[9]。
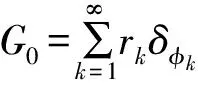
(12)
由文献[9]的5.2节,G0也可以被记为:
(13)
Gu~DP(ε,H)
(14)
r=(r1,r2,…,rk,ru)~Dir(M1,M2,…,Mk,α)
(15)
其中,k代表已有的菜肴数,将r扩展到k+1空间,依据式(15)采样得到r的分布。

(16)
同理得到ψt、πdt。
3)zv采样:给定xv和yv的值,可以得到相应的zv值,表示如下:
P(zv=k|xv,yv,w)∝P(v|xv,yv,zv=k,w)×
P(z=k|Gx,y)
(17)
P(v|xv,yv,zv=k,w)代表微博v在主题z下产生的概率,P(z=k|Gx,y)代表选择菜肴z的概率,表示如下:
(18)
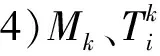
5)x和y采样:
(19)
(20)
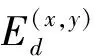
5 主题关联度计算与阈值确定
完成主题的挖掘后,如何从主题中选择既重要又新颖的主题词是一个关键。主题演化相比传统的静态主题挖掘要考虑时间因素,如果将静态主题挖掘视为空间中的一个点,主题演化过程就是一系列点以时间为轴连成的线,不仅要关注主题的分布情况,还要分析其变化过程。主题词的提取直接影响演化分析的准确度,要满足以下2个条件:1)覆盖率高,即主题词要尽可能覆盖领域微博的主要信息;2)冗余信息少,即主题词的重复信息尽可能少。因此,需要对提取出的主题做进一步的滤除。
1)子主题的相似度通常采用KL距离来衡量,在已知前一时段主题分布的情况下,对当前时段的主题词进行筛选,方法如下:设t时段中的领域微博被划分为Kt个子主题,子主题tm-1,n′与tm,n间的KL距离表示为:
(21)
2)阈值的选取也是一个关键性问题。人工给定阈值的做法可能造成较大误差,阈值过高会导致主题太分散而无法覆盖领域的关键信息;阈值过低又会造成主题信息的冗余,不具有代表性。对此,本文依据主题平均距离,将本时段某一子主题与前一时段的所有子主题做距离计算,取其均值。
(22)
其中,M-1表示tm-1时段的子主题总数目。
6 实验结果与分析
6.1 实验数据
以新浪微博作为数据来源,选取2016年6月1日—2016年12月3日的数据进行实验。微博爬虫监测约50万活跃用户,其中,每条转发微博中包含如下信息:1)ID,表示该条消息的唯一ID;2)Created-at,表示微博的时间戳;3)Text,表示微博的文本内容;4)User,表示微博的用户信息。按照定义的领域指数值筛选分类处理得到的部分数据如表3所示。

表3 领域微博数据
由于时段划分由人为设定,可能会因为时段跨度小而导致数据量过小,且领域微博的发布数量随机,会由于某一热点消息而出现微博数量激增的情况,微博集的规模会在一定程度上影响系统性能。对此,采取下列相应措施:
1)当数据集过小时(少于80篇),数据较分散,得到的主题数可能高于微博条数,主题的代表性不明显。对此,将微博文本以相同的比例复制,即在不影响词语的词频及语境的情况下,提高词语的集中度,扩大词语的采样空间。
2)当数据集过大时(大于400篇),聚类过程中容易产生“超大类”。大类中包含的特征较多,待归类的数据容易归类到与其含有共同信息的数据中,从而导致“滚雪球”式的增长。对此,将微博数据进行二次划分后再进行主题的提取。
6.2 多领域的主题数分析
选取财经、教育、旅游和体育领域,截取2016年7月4日—2016年9月25日之间12周的523条微博,设定实验的迭代次数为200,统计每个领域主题数的分布及变化情况,实验结果如图4所示。
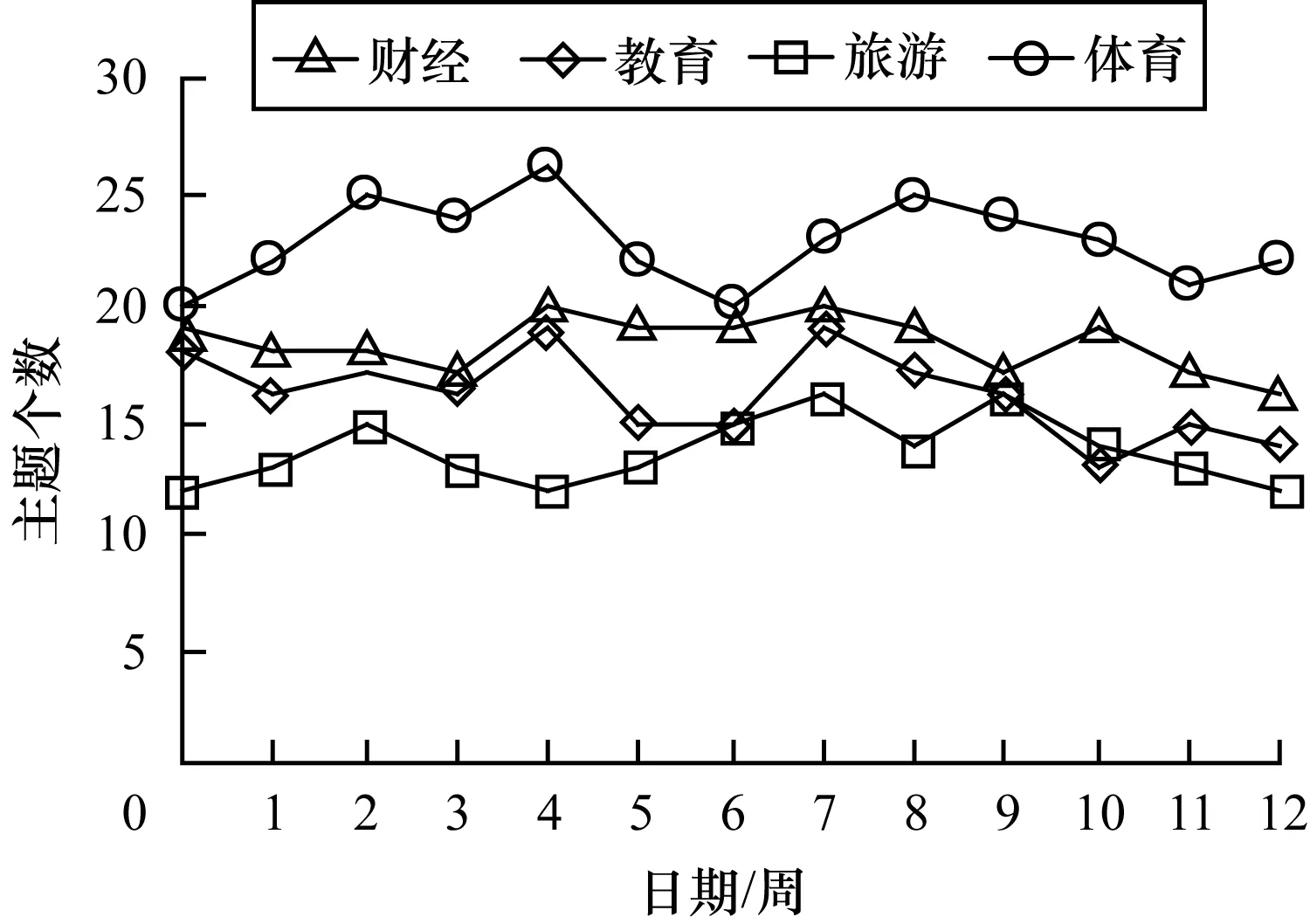
图4 各领域主题数分布
分析发现,不同领域的主题数目在12~26之间变动,并且主题数的多少与微博数据集的大小没有正比例关系,决定因素在于主题的集中程度。例如,实验中第8周的财经相关微博为58条,其主题数为19;体育相关的微博为45条,其主题数却为25。
6.3 以医疗行业为例的主题演化分析
以医疗行业微博数据为对象,设定实验的迭代次数为200,统计主题的分布情况,实验结果如表4所示。

表4 医疗行业主题分布
从表4中可以明显看出,在医疗行业下分为10个大主题,其中每个大主题又由10个子主题构成,表现出明显的层结构,有效地从微博文本中挖掘出了主题。
6.4 子主题相似性分析
为分析主题内容上的相似性,利用式(19)计算2个相邻时段的KL距离。选择表4中的前5个子主题,其演化结果如图5所示。

图5 主题相似性变化图
从图5可以看出,主题1在8月5日主题间的差异较大,此时很有可能有突发事件;主题4和主题5的分布较平稳且KL值较低,说明该主题相似度较高,此段时间内没有突发性事件。
6.5 以魏则西事件为例的主题演化分析
以时间序列为轴线,分析医疗主题下的魏则西事件,具体演化过程分析如表5所示。

表5 魏则西事件主题演化过程
演化过程的要点可简述为:2016年2月,公众从知乎网站上得知魏则西的经历,讨论的内容集中在对治疗方案及病情的关注与分析上;2016年4月,魏则西去世,公众关注点集中在魏则西之死事件存在的涉事医院外包诊所给民营机构、百度竞价排名等问题上;2016年6月,针对网友对魏则西所选择的武警北京二院的治疗效果及其内部管理问题的质疑,相关部门立即展开调查;随后,公众的注意力放在了广告和医疗体制改革上。
6.6 对比实验


图6 基于LDA模型的贝叶斯网络
6.6.1 内容困惑度
内容困惑度是广泛应用于主题模型效果评估的一项指标,其值越小,说明主题模型的效果越好。内容困惑度计算方法如下:
(23)
设置迭代次数为100,基于LDA模型的主题数设为10,各模型的困惑度如图7所示。可以看到,在迭代次数达到40时,各模型的困惑度趋于平稳。DM-HDP模型明显优于LDA,说明自动确定主题数目是提升挖掘效果的关键因素。HDP比DM-HDP模型略差,说明考虑时间信息及领域信息可以改善主题的挖掘效果。

图7 3种模型的内容困惑度对比
6.6.2 模型复杂度
模型复杂度作为衡量模型的重要指标被广泛应用于主题模型的效果评估。复杂度越低表示模型用于描述数据集的主题越少。其他指标相同时,选择复杂度较低的模型。由于本次实验采用MCMC方法对模型中的各参数进行后验概率的推导,所以模型的复杂度为主题数目与所有主题的复杂度之和。模型复杂度的计算方法参考文献[22]。
(24)
设置迭代次数为100,各模型的复杂度如图8所示。
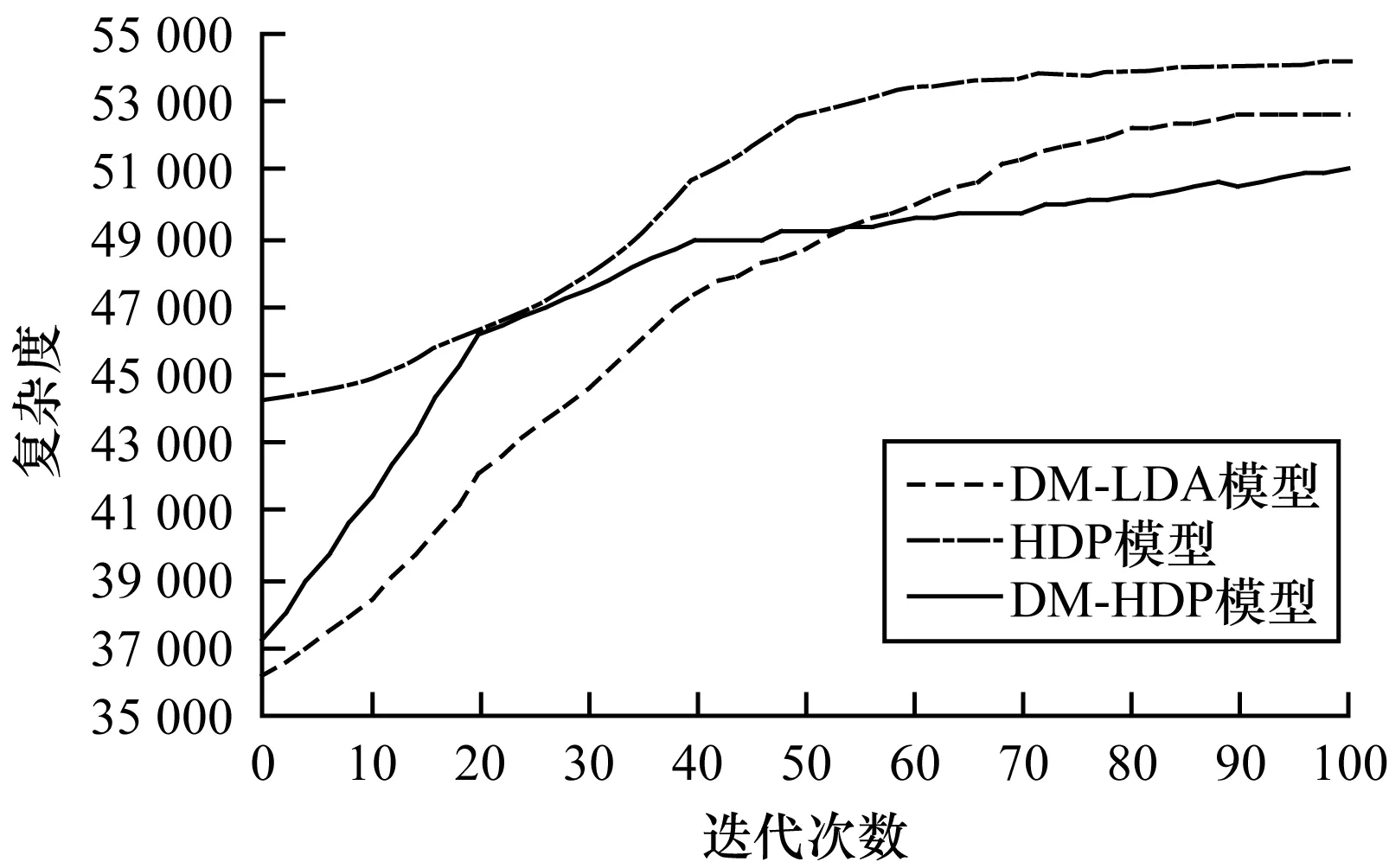
图8 3种模型的复杂度对比
可以看到,当迭代次数小于30时,DM-HDP模型的复杂度增速明显高于其他模型,在迭代次数达到80时,各模型的复杂度趋于平稳,HDP模型最高,DM-LDA次之,DM-HDP模型的复杂度最低。
7 结束语
本文主要研究对领域微博主题的提取方法。根据用户兴趣信息对爬取的混合微博进行领域筛选,判断其是否属于既定领域,并依据领域微博的特点,基于HDP模型建立领域微博主题挖掘DM-HDP模型,有效去除领域无关信息,使领域信息的专业性特点更加凸显。同时,为了推导MB-HDP模型的分布参数,应用基于改进CRCP的MCMC采样方法。对挖掘出的主题进行相关性计算,以捕捉主题的演化规律。实验数据表明,DM-HDP模型性能优于基于LDA等现有模型。为了适应海量微博数据,后续研究将侧重于寻找更加高效的采样方法,以及设计有效方案进一步整合主题的层次结构。
[1] JENSEN S,LIU X,YU Y,et al.Generation of Topic Evolution Trees from Heterogeneous Bibliographic Networks[J].Journal of Informetrics,2016,10(2):606-621.
[2] 叶春蕾,冷伏海.基于社会网络分析的技术主题演化方法研究[J].情报理论与实践,2014,37(1):126-130.
[3] 陈 千,桂志国,郭 鑫,等.基于特征本体的文本流主题演化[J].计算机应用,2015,35(2):456-460.
[4] MA J,SUN M,LI C,et al.Ontology Evolution Algorithm for Topic Information Collection[J].International Journal of Nonlinear Science,2014,18(1):86-91.
[5] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,32(3):993-1022.
[6] WANG Y,AGICHTEIN E,BENZI M.TM-LDA:Efficient Online Modeling of Latent Topic Transitions in Social Media[C]//Proceedings of ACM SIGKDD Inter-national Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2012:123-131.
[7] 胡吉明,陈 果.基于动态LDA主题模型的内容主题挖掘与演化[J].图书情报工作,2014,58(2):138-142.
[8] HOFFMAN M D,BLEI D M,BACH F R.Online Learning for Latent Dirichlet Allocation[J].Advances in Neural Information Processing Systems,2010,23(5):856-864.
[9] TEH Y W,JORDAN M I,BEAL M J,et al.Hierarchical Dirichlet Processes[J].Journal of the American Statistical Association,2006,101(476):1566-1581.
[10] BLEI D M,LAFFERTY J D.Dynamic Topic Models[C]// Proceedings of the 23rd International Conference on Machine Learning.Washington D.C.,USA:IEEE Press,2006:113-120.
[11] AHMED A,XING E P.Dynamic Non-parametric Mixture Models and the Recurrent Chinese Restaurant Process:with Applications to Evolutionary Clustering[C]//Proceedings of Siam International Conference on Data Mining.Atlanta,USA:SDM Press,2008:219-230.
[12] ZHANG J,SONG Y,ZHANG C,et al.Evolutionary Hierarchical Dirichlet Processes for Multiple Correlated Time-varying Corpora[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2010:1079-1088.
[13] HONG L,DOM B,GURUMURTHY S,et al.A Time-dependent Topic Model for Multiple Text Streams[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2011:832-840.
[14] 方 莹,黄河燕,辛 欣,等.面向动态主题数的话题演化分析[J].中文信息学报,2014,28(3):142-149.
[15] FU X,LI J,YANG K,et al.Dynamic Online HDP Model for Discovering Evolutionary Topics from Chinese Social Texts[J].Neurocomputing,2015,171(C):412-424.
[16] 张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主 题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[17] 刘少鹏,印 鉴,欧阳佳,等.基于MB-HDP模型的微博主题挖掘[J].计算机学报,2015,38(7):1408-1419.
[18] FERGUSON T S.A Bayesian Analysis of Some Nonparametric Problems[J].Annals of Statistics,1973,1(2):209-230.
[19] 周建英,王飞跃,曾大军.分层Dirichlet过程及其应用综述[J].自动化学报,2011,37(4):389-407.
[20] 陈晓伟.基于主题爬虫与文本分类的微博资讯智能生成策略研究[D].武汉:华中科技大学,2013.
[21] 张力生,年 欢,宋 辉,等.领域模型中关联语义的描述逻辑表示与应用[J].软件,2015(6):66-74.
[22] MENG X,WEI F,LIU X,et al.Entity-centric Topic-oriented Opinion Summarization in Twitter[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2012:379-387.
