基于语义的文本数据流概念漂移检测算法
2018-03-02胡学钢张玉红
储 光,胡学钢,张玉红
(合肥工业大学 计算机与信息学院,合肥 230009)
0 概述
网络社交媒体在现实生活中被广泛应用,例如网络聊天、购物评论和在线新闻等,由此产生了大量的文本数据流。这些数据流的主题会随着时间随机变化,这种变化被称为概念漂移[1-2]。概念漂移检测是数据流分类中的重要问题。
根据数据流是否含有标记信息,可将现有的概念漂移检测算法分为监督、无监督和半监督3类。监督方法适用于有标记数据,依据衡量数据流分类过程中的错误率变化程度进行概念漂移检测,衡量模型包括伯努利分布[3-5]、决策树[6-8]和Bayes模型[9]等。无监督方法适用于无标记数据,主要分为2种:一种是借助聚类等方法,通过比较聚类簇的变化程度进行概念漂移检测[10];另一种是借助特征向量化和特征提取的方法,通过比较提取出的特征集合或是依据特征计算出的信息熵的变化程度进行概念漂移检测[11]。半监督方法适用于部分标记数据,概念漂移检测方法大多与无监督方法一致[12]。上述方法都基于某种信息量的变化程度进行概念漂移检测,其中监督方法效果直接取决于基分类器的性能,无监督或半监督方法效果直接取决于聚类或者特征提取效果,在一定条件下可以有效地实现概念漂移检测。
然而在实际应用中,由于信息的传播速度快、交流范围广,导致文本数据流中的概念通常会随着时间频繁变化。例如在奥运会期间,体育新闻的内容会随着项目不同而不停更新,从球类到游泳,从田径到射击,项目最密集时这种更新甚至会以分钟为单位。这种频繁的概念漂移一方面降低了分类器的适用性,另一方面使得用于区分不同数据分布的样本数量不足,难以累积充分的样本来评估数据块之间的变化程度。
针对上述问题,本文考虑文本数据流隐含的语义信息,提出一种新的概念漂移检测算法。通过引入潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[13]计算语义相似度,并基于相邻数据块共有词比例和相似主题比例,在频繁漂移情况下实现有效的概念漂移检测。
1 相关研究
本节主要介绍已有关于概念漂移检测的研究,分监督概念漂移检测算法和无监督或半监督概念漂移检测算法2类进行介绍。
1)监督概念漂移检测算法
文献[1]对监督类的概念漂移检测方法进行了全面综述;文献[2]提出一种基于分类器与数据集中概念相似度错误方差的方法来判断概念是否发生漂移;文献[3-4]提出基于伯努利数据分布设置阈值以区分概念漂移与噪音的方法DDM;文献[5]采用分类错误率替换错误分类实例的机制改进了DDM方法,提出了一种更适用于检测突变式概念漂移的方法EDDM;文献[6]提出一种使用随机决策树构建集成分类器,并采用双层阈值来区分噪音和漂移的方法CDRDT;文献[7-8]提出一种依据窗口中原始数据分布变化来检测概念漂移的方法SWCDS,以及利用双层窗口机制跟踪概念漂移以提高适应性的方法DWCDS;文献[9]提出基于决策树和Bayes混合模型的集成分类方法 WE-DTB,利用Hoeffding边界和μ检验实现了数据流环境下概念漂移的检测和分类。
在实际应用中,多数算法采用不同的错误率评估方法来降低概念漂移检测过程中噪音的干扰,例如Hoeffding边界[10,14-16]、μ检验[8]等。这些算法对含噪音数据流效果显著,但本质上是通过分类错误率进行概念漂移检测,性能主要受限于标签信息和分类器性能。
2)无监督或半监督概念漂移检测算法
为处理不完全标记数据流中重现概念漂移问题,针对连续属性数据流,文献[10]采用K-Means算法在增量式构建决策树的叶子节点标记无标签示例,提出基于聚类簇差异度量的概念漂移检测方法,即采用存储历史概念簇的机制,同时更新概念漂移检测条件的算法REDLLA;针对多数算法忽略特征空间和样本空间分布特点的现状,文献[11]利用特征选择和加权,构建基于特征项分布的信息熵及特征动态加权概念漂移检测模型。该模型根据特种特征和样本空间的拟合性,使用特征信息熵捕捉概念漂移,同时利用改进的LDA模型特征动态加权算法解决了特征权重的取值问题;文献[12]提出一种基于KNN模型和增量Bayes的概念漂移检测算法KnnM-IB,使用增量Bayes算法分类难处理的样本,同时利用可变的滑动窗口对少量标记信息进行主动学习,以此进行概念漂移检测。
无监督或半监督概念漂移检测算法通过聚类或特征提取等方法,利用聚类簇或特征集合的分布变化衡量原始数据分布变化进行概念漂移检测。这些算法适用于半标记或未标记数据,但本质上是通过数据分布变化进行概念漂移检测,性能直接取决于能否拥有足够的训练样本用于区分数据分布的差异。
2 基于语义的概念漂移检测方法
本文针对频繁漂移数据流提出一种无监督基于语义的概念漂移检测算法,首先给出算法框架,如图1所示,本文算法框架综合考虑了单词和主题2个层面的语义相似度检测概念漂移。

图1 本文算法框架
1)共有词比例计算
文本数据流中语义的直接表现形式是单词,因此,共有词比例一定程度上可以体现2个数据块的语义相似度,且计算方法简单、效率高。例如在线购物评论数据中消费者关注的商品从书籍变化为电器时,虽然2个类别会有一些共有词,例如“price”“quality”等,但2个数据块中主要用于描述商品名称的单词会发生较大的变化,例如从“book,comic,novel,…”变化到“dvd,television,fridge,…”。
当共有词比例较大时,一般认为对应的相邻数据块语义相似度较高,因此,本文认为共有词比例较大时无概念漂移。当共有词比例较小时,可能存在概念漂移,有待于进一步检测。
2)相似主题比例计算
基于共有词比例的检测方法没有考虑单词的语义权重,当比例较小的共有词拥有较大的语义权重时,仅使用该方法会造成误检。例如20-Newsgroups数据中属于“hockey”概念的2个数据块,由于“match”“hockey”“League”等高频词语的数量较少,而“Canada”“CBC”“NHL”等低频词语的数量较低,因此此时基于共有词比例的检测方法反而会误判发生概念漂移。为防止此类误检发生,本文引入LDA模型中的主题概念进行检测。若相邻两数据块主题较为相似,则认为未发生概念漂移,否则认为发生概念漂移。
下面简要介绍LDA模型。LDA是一种基于语义的文档主题生成模型,能提取出文档-主题-词概率矩阵,其中主题-词的概率矩阵可用于表示主题空间。在本文中视每个数据块为一个文档并为其建立LDA模型,并由此得到相邻数据块的主题空间。对于数据块Di,可以得到其主题集合Zi={z1,z2,…,zh}以及文档-主题的概率分布θDi={P(z1|Di),P(z2|Di),…,P(zh|Di)};而对于主题zi∈Zi,可以得到其主题-单词的概率分布φzi={P(w1|zi),P(w2|zi),…,P(wm|zi)},其中P(wl|zi)表示单词wl属于主题zi的概率,即wl在zi中的语义权重。本文通过比较单词在不同主题中的语义权重来衡量主题相似度,并根据数据块之间的相似主题比例来衡量数据块的语义相似度,从而实现概念漂移的检测,弥补了共有词比例难以体现语义权重的不足。
为保证表述的准确性,本文定义了相关变量,如表1所示。

表1 变量定义
本文算法详细步骤如下:
步骤1计算共有词比例rw
通过计算共有词比例rw来进行概念漂移检测,如图2所示,求得Di和Di+1中单词集合交集即可计算量数据块共有词所占比例。

图2 共有词比例计算示意图
对于文本数据流D={D1,D2,…},使用|WDi|表示数据块Di的单词个数。利用相邻数据块共有词比例衡量其语义相似度,计算公式如式(1)所示。
(1)
由于此步骤用于快速排除相邻数据块语义相似度较高的情况,其余情况可以由后续步骤进行检测,因此当rw大于阈值α时,判定未发生概念漂移,否则需要执行步骤2。
步骤2计算相似主题比例rz
引入LDA模型,通过计算相似主题比例rz进行概念漂移检测,如图3所示。

图3 相似主题比例计算示意图
LDA模型可以计算出文档-主题-单词的三层概率分布,本文算法引入LDA模型,主要利用主题-单词的概率P(wl|zi)计算相似主题比例,实现概念漂移检测。

(2)
(3)

将相似主题比例视为相邻数据块的语义相似度,上述计算可用于概念漂移的检测。计算过程如式(4)所示。
(4)
其中,h为LDA模型在数据流D上划分的主题个数。
与共有词比例类似,当rz大于阈值α时,可以判定这2个数据块语义相似度较高,未发生概念漂移,否则发生概念漂移。
经过以上各步骤,本文算法利用隐含的语义弥补频繁漂移情况下训练数据的有限性,通过计算共有词比例和相似主题比例,实现了概念漂移检测。
本文算法由共有词比例计算和深入语义权重的相似主题比例计算2个步骤组成,挖掘了数据隐含的语义信息,弥补了频繁漂移情况下单个概念数据量不足的缺陷,减少了概念漂移检测的漏检。算法具体如下:
算法基于语义的无监督文本数据流概念漂移检测算法
输入数据流D,数据块中的主题个数h,阈值α、β
输出发生的概念漂移次数n
1.While D not end,read chunks Di,Di+1from the stream D;
2. Count|WDi|,|WDi+1| and |WDi∩WDi+1| to calculate rw;
3. If(rw>α)
4. Then no drift and break;
5. Use LDA to get Zi,Zi+1and each j for topics by h;
7. For zi∈Zi,i=1 to h

9. Then lz′j=1 and break;
10. Sum lz′jto calculate rz;
11. If(rz>α)
12. Then no drift and break;
13. Else drift and n++;
14.Return n;
3 实验与结果分析
本节探讨了算法的阈值选取,并通过同基准算法的对比,从算法在多种频繁漂移文本数据流上的普适性和不同漂移频繁程度对算法的影响2个方面评估本文算法。
3.1 基准数据集、基准算法及评价指标
由于网络中存在的真实文本数据流分布较为随机,不能保证包含所有种类的概念漂移,用于评估概念漂移检测算法性能时不够严谨,缺乏说服力,而且包含大量的噪音,需要经过复杂的预处理,因此实验选取常用于评估算法性能的3个基准文本数据集,通过不同的组合方式模拟真实情况下的文本数据流,3个数据集分别是亚马逊网站购物数据(Amazon)、路透社新闻数据(Reuters)以及20新闻组数据(20-Newsgroups),具体信息如表2所示,其中亚马逊网站购物数据是由多种商品的购物评论组成,而路透社新闻数据和20新闻组数据则是由多个领域中的多篇新闻报道组成。

表2 数据集信息
本文从对于多种频繁漂移文本数据流的普适性和漂移频繁程度不同对算法性能的影响2个方面考察算法,设置了2个系列的实验数据,其中本文算法使用单词形式的文本数据流,而对比算法使用经过特征向量化、词频筛选处理后的文本数据流。
由于基准数据中包含多个不同的领域,来自不同领域的数据之间概念不同,通过从不同的领域中选取数据组成数据块并拼接构成实验数据流的方式,可以模拟真实数据流中的概念漂移情况,具体构造方法如下:
1)多种频繁漂移文本数据流
为考察算法的普适性,本文选取3个来自不同基准数据集的实验数据与基准算法进行对比实验。
(1)Amazon数据集:数据共有4个概念,对每个概念重复取样获得8个数据块,并将其组成共32个数据块的实验数据,其中每个数据块由200条数据构成。数据经过特征向量化、词频筛选后维度为256,其中设定3次概念漂移,多次重复实验取平均值作为最终实验结果。
(2)Reuters数据集:数据共有5个概念,对每个概念重复取样获得2个数据块,并将其组成共10个数据块的实验数据,其中每个数据块由200条数据构成。数据经过特征向量化、词频筛选后维度为224,其中设定4次概念漂移,多次重复实验取平均值作为最终实验结果。
(3)20-Newsgroups数据集:数据共有4个领域,每个大类包含3个~5个概念,从每个领域中随机选取一个概念,对每个概念重复取样获得3个数据块,并将其组成12个数据块的实验数据,其中每个数据块由200条数据构成。数据经过特征向量化、词频筛选后维度为201,其中设定3次概念漂移,多次重复实验取平均值作为最终实验结果。
2)Amazon实验数据序列
为考察漂移频繁程度不同对算法性能影响,本文从亚马逊网站购物数据中抽取数据,构建了漂移频繁程度不同的多组实验数据。对Amazon原始数据的4个概念分别重复取样各获得8个数据块,共32个数据块、6 400条数据,再将获得的数据块按照8种不同的顺序进行排列以获得8组漂移频繁程度不同的实验数据,其中漂移次数最多的有31次,最少的有3次。
本文选取5种概念漂移检测算法作为基准算法,其中监督概念漂移检测的算法有DDM[3-4]、CDRDT[6]、DWCDS[7-8]和HDDM-W-Test[16]算法,而无监督或半监督概念漂移检测的算法则为REDLLA[10]算法。由于基于监督概念漂移检测的算法受分类器性能影响,选择决
策树(DT)和朴素Bayes(NB)分类器作为对比,并在此基础上进行分类性能的对比,分类过程运用集成分类的方法,窗口大小为4个数据块。
评价指标:概念漂移检测的结果需要提供有意义的、可以量化描述的结论,根据概念漂移检测的特点,通常采用误检数和漏检数作为评价指标[17]。
为了在保证精度的同时提高时间效率,设定LDA模型内部迭代次数为1 000,数据流划分的主题数目为10,主题的关键词集合大小为20。
3.2 阈值选取
本节主要说明阈值a和b的取值。由于a用于快速剔除语义相似度高的相邻数据块,因此本文根据经验值设置其值为0.5;b用于衡量主题的语义相似度,需要根据实验决定,具体实验结果如图4所示。

图4 阈值b取值实验结果
根据阈值不同取值的实验结果,可以看出阈值越小漏检次数越多,阈值越大误检次数越多。经过多次重复试验,本文选取0.2作为主题相似度阈值b的取值。
3.3 算法普适性分析
使用多种频繁漂移文本数据流进行实验,具体结果如表3所示,该表显示了本文算法与对比算法在误报次数、漏报次数方面的概念漂移检测性能。

表3 概念漂移检测结果
首先,实验结果表明在频繁漂移情况下,监督概念漂移检测方法普遍漏检严重,尤其是对于Reuters数据,对比算法的正确检测数量都为0,这是由于频繁漂移情况下训练样本的缺少导致分类器性能低下,漂移发生时分类错误率的变化不够明显。同时选取的2种基分类器实验结果类似,证明了这种情况的普遍性。
其次,无监督或半监督概念漂移检测方法的效果也较差,尤其是REDLLA算法,在3组实验数据集上均有较多漏检和误检。漏检较多是由于频繁漂移情况下,算法获取的样本数量不足以区分不同概念的数据分布;误检较多则是由于文本数据流本身数据块之间分布差异较大,且无监督或半监督算法不使用标记信息。
在3个基准数据集上的实验结果表明,与对比算法相比,本文算法的概念漂移检测结果均优于对比算法,尤其在漏检指标上大幅度优于对比算法。这是由于本文算法考虑了文本数据隐含的语义信息,使用相邻数据块的语义信息增强了概念的区分度,弥补了频繁漂移情况下数据量有限的不足,能够进行有效的概念漂移检测。
表4考察了本文算法与对比算法在分类错误率上的差异,表中数据为所有数据块的平均分类错误率。由于本文算法仅进行概念漂移检测,因此在考察分类精度时计算了2种分类方法的结果。由表4可见,实验结果平均分类错误率较大,原因在于采取了未进行降噪等预处理的原始数据,而且设定的漂移较为频繁,概念变化速度较快。此外,该算法在Amazon和 20-Newsgroups数据集上的分类错误率高于基准算法,这是由于基准算法频繁漂移情况下漏检较多,漏检时训练集不会更新导致其中出现概念重现问题,概念的重现使得基准算法在漏检较多时反而具有较低的分类错误率。由于本文算法仅考虑概念漂移检测,因此集成分类器机制带来的概念重现问题不做进一步讨论。

表4 分类错误率 %
综合所有分类错误率结果则可以证明,在大部分情况下,本文概念漂移检测算法得到的检测结果在相同的分类机制下能获得相当的分类精度。
3.4 不同漂移频繁程度下的算法性能分析
本节对比本文算法与3种基准算法在不同频繁程度下在Amazon实验数据序列上的实验结果,基分类器选取NB方法,结果如表5所示,其中,N表示漂移次数。可以看出,随着漂移频繁程度的增加,漏检数也会上升,而本文算法漏检数上升幅度明显小于对比算法。DDM算法在频繁程度较高时漏检次数较高,这是由于频繁发生概念漂移时,分类精度一直较低,变化程度不明显。REDLLA算法在频繁程度低时误检较多,在频繁程度较高时漏检较多,前者是由于文本数据块本身数据分布差异程度较大,不使用标签信息时会造成较多的误检,后者则是由于频繁漂移时同一概念的数据样本过少,难以区分不同概念的数据分布。而本文算法利用语义信息弥补样本数量有限的不足,在漂移频繁程度较低时效果与对比算法相当,而在频繁漂移程度较大时大幅度减少了漏检数量。
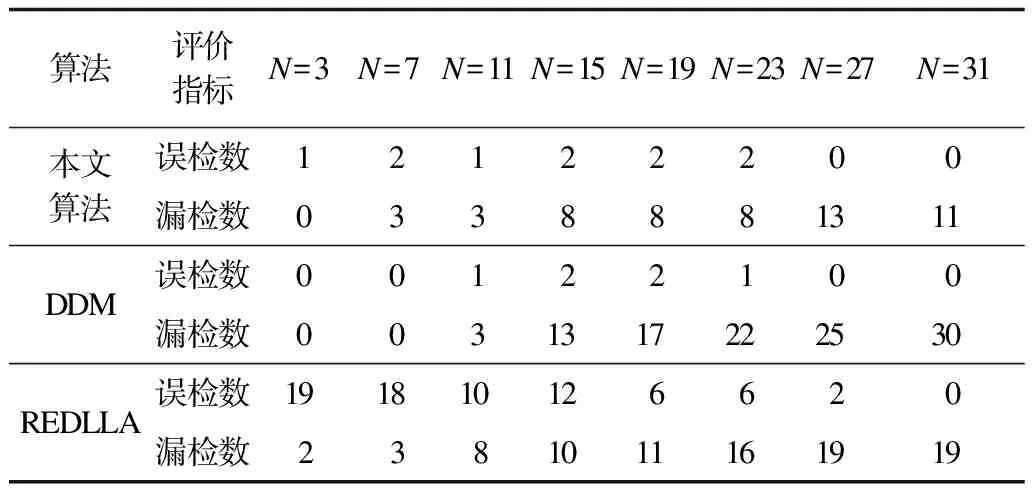
表5 漂移频繁程度对算法性能的影响
4 结束语
概念漂移检测是数据流分类研究的难点,尤其对于频繁漂移数据流。监督概念漂移检测方法通常基于分类错误率,过度依赖于分类器的性能,且需要在分类结束后才能进行概念漂移检测;无监督或半监督的分类算法利用聚类或者特征提取的方法计算相邻数据块的差异程度以检测漂移,在样本数量不足时效果不理想。而本文算法利用了数据隐含的语义信息,基于语义相似度进行概念漂移检测,效果不受基分类器性能影响,且受样本数量影响度较小。然而该算法性能对相似阈值敏感,因此,发现阈值与数据分布间的内在关系以提升算法普适性将是未来工作重点。此外,本文仅关注了文本数据流的概念漂移问题,如何面向其他实际应用领域包括煤矿典型动力灾害数据流、电信通话数据流、天气预报数据流等实现概念漂移的检测,也将是下一步的研究方向。
[1] WIDMER G,KUBAT M.Learning in the Presence of Concept Drift and Hidden Contexts[J].Machine Learning,1996,23(1):69-101.
[2] WANG Haixun,FAN Wei,YU P S,et al.Mining Concept-drifting Data Streams Using Ensemble Classifiers[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2003:789-802.
[3] GAMA J,MEDAS P,CASTILLO G,et al.Learning with Drift Detection[M]//BAZZAN A L C,LABIDI S.Advances in Artificial Intelligence.Berlin,Germany:Springer-Verlag,2004:286-295.
[4] GAMA J,CASTILLO G.Learning with Local Drift Detection[M]//LI Xue,ZAÏANE O R,LI Zhanhuai.Advanced Data Mining and Applications.Berlin,Germany:Springer-Verlag,2006:42-55.
[5] BAENA-GARC M,CAMPO-VILA J D,FIDALGO R,et al.Early Drift Detection Method[C]//Proceedings of the 4th International Workshop on Knowledge Discovery from Data Streams.Pittsburgh,USA:[s.n.],2006:1-10.
[6] LI Peipei,WU Xindong,HU Xuegang,et al.A Random Decision Tree Ensemble for Mining Concept Drifts from Noisy Data Streams[J].Applied Artificial Intelligence,2010,24(7):680-710.
[7] 朱 群,张玉红,胡学钢,等.一种基于双层窗口的概念漂移数据流分类算法[J].自动化学报,2011,37(9):1077-1084.
[8] ZHU Qun,HU Xuegang,ZHANG Yuhong,et al.A Double-window-based Classification Algorithm for Concept Drifting Data Streams[C]//Proceedings of IEEE International Conference on Granular Computing.Washington D.C.,USA:IEEE Press,2010:639-644.
[9] 桂 林,张玉红,胡学钢.一种基于混合集成方法的数据流概念漂移检测方法[J].计算机科学,2012,39(1):152-155.
[10] LI Peipei,WU Xindong,HU Xuegang.Mining Recurring Concept Drifts with Limited Labeled Streaming Data[J].ACM Transactions on Intelligent Systems and Technology,2012,3(2):241-252.
[11] 孙 雪,李昆仑,韩 蕾,等.基于特征项分布的信息熵及特征动态加权概念漂移检测模型[J].电子学报,2015,43(7):1356-1361.
[12] 郭躬德,李 南,陈黎飞.一种基于混合模型的数据流概念漂移检测算法[J].计算机研究与发展,2014,51(4):731-742.
[13] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[14] HOFFMAN M D,BLEI D M,BACH F R.Online Learning for Latent Dirichlet Allocation[M]//LAFFERTY J D,WILLIAMS C K I,SHAWE-TAYLOR J.Advances in Neural Information Processing Systems.[S.l.]:Neural Information Processing Systems Foundation,Inc.,2010:856-864.
[15] LI Peipei,WU Xindong,HU Xuegang,et al.Learning Concept-drifting Data Streams with Random Ensemble Decision Trees[J].Neurocomputing,2015,166(C):68-83.
[16] FRIASBLANCO I,CAMPOAVILA J D,RAMOSJIMENEZ G,et al.Online and Non-parametric Drift Detection Methods Based on Hoeffding’s Bounds[J].IEEE Transactions on Knowledge and Data Engineering,2015,27(3):810-823.
[17] HABABOU M,CHENG A Y,FALK R.Variable Selection in the Credit Card Industry[C]//Proceedings of NESUG’06.Philadelphia,USA:SAS Institute Inc.,2006:1-5.
