海量小数据分布式聚类优化与负载均衡算法
2018-03-02汪明明陈庆奎
汪明明,陈庆奎,b
(上海理工大学 a.光电信息与计算机工程学院; b.管理学院,上海 200093)
0 概述
随着物联网技术的发展,各种传感器和嵌入式设备都在时刻产生数据,必然会遇到海量物联网数据高效存储的问题。由于物联网数据是海量的和异构的[1],因此传统的关系型数据库并不适合海量物联网数据的存储场景。
随着Hadoop生态圈的成熟和分布式文件系统的广泛使用,现已有许多关于海量数据的解决方案[2-5]。然而文献[2]方案并未对小数据进行优化,文献[3]方案在小数据量大时存在索引过大问题,文献[4-5]方案主要适用于单个文件较大的情况(一般Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)的文件块大小为64 MB),在单个文件较小时读写性能较差,但是大部分传感器采集到的数据是小数据,如温度、湿度、地理位置等。虽然Hadoop采用了Har File[6]和Hadoop顺序文件[7]将多个小文件合并成大文件对小数据进行优化,然而性能较差。此外,文献[8-11]提出了基于小数据文件特征的优化方法,但仅针对特殊文件格式和内容的数据,不具有通用性。
文献[12]设计了SensorFS系统。该系统使用了把相似传感器的数据合并成同一个大文件的方案,从而最优化读写吞吐量。同时,其在HDFS上层提出了DMFS来实现基于内存的分布式写缓存和分布式文件合并,具有很好的读写性能。但SensorFS的传感依赖图(Sensing Dependency Graph,SDG)建立过程和基于SDG的传感器聚类过程都在主节点(Master)进行操作,这使得Master节点在传感器量很大的情况下会成为性能瓶颈。此外,该文献给出基于内存和CPU使用率的粗粒度的负载均衡方案,并不能很好地实现集群内部的负载均衡。
针对SensorFS集中式传感器聚类算法存在的问题,本文提出分布式算法,在海量传感器的情况下提高聚类速度并且减轻Master节点内存负担。此外,考虑到良好的负载均衡能有效提升系统整体性能和稳定性[13-15],本文针对各个传感器不同的文件传送速率,以传感类为单位提出一种细粒度的负载均衡算法。
1 相关研究
文献[12]中基于SDG的传感器聚类算法可以有效地把相似的传感器数据合并成同一HDFS文件块,从而实现读写最优化。SDG的原理为通过计算传感器两两之间的相似度和依赖关系来构造有向加权图,而基于SDG的聚类算法则是根据构造出的有向加权图对传感器进行分类。图1为SensorFS系统架构,从中可以看出,写调度和传感器聚类都在Master节点上执行,即表明Master节点不仅要缓存ChunkServer和传感器映射的数据信息,还要负责根据传感器和各自追踪的对象集合来构建SDG图和进行聚类,而这两者都是非常消耗内存的操作,在数据量大的情况下,Master节点必然会成为瓶颈。此外,SensorFS的负载均衡机制是在每个ChunkServer子集群内部根据CPU和内存使用率来进行粗粒度的均衡,即在每个ChunkServer子集群之间是不做负载均衡的,子集群内部的负载均衡通过监控Master ChunkServer的内存和CPU,在其负载过大时选择一个空闲的Slave ChunkServer转换成Master ChunkServer来实现,这样会出现子集群之间负载不均衡的情况。而在同一个子集群中,当同一子集群内部长时间负载过大时,会引起频繁主从切换的问题,反而对集群性能产生反作用。

图1 SensorFS系统架构
2 改进的SensorFS系统架构及核心技术
2.1 改进的SensorFS系统架构
针对SensorFS的不足,本文设计优化后的Mater和ChunkServer节点的功能架构,如图2所示。其中,Master节点只负责初始写调度,即只有在Sensor首次发出写请求时会经过Master节点,如图3所示。当Senser获取到对应的ChunkServer信息后就会把该信息缓存下来,再次发出写请求时直接和对应ChunkServer交互,不经过Master节点,如图4所示,从而大幅降低Master节点的请求压力。传感器聚类由原来的Master节点的集中式传感器聚类改变为在各个ChunkServer内部先对各自节点上的传感器进行基于SDG的聚类,然后由Master节点对这些类进行聚类。此外,各个子节点会计算各个传感器的数据是否达到负载,并根据负载均衡算法进行均衡。

图2 Master与ChunkServer的功能架构
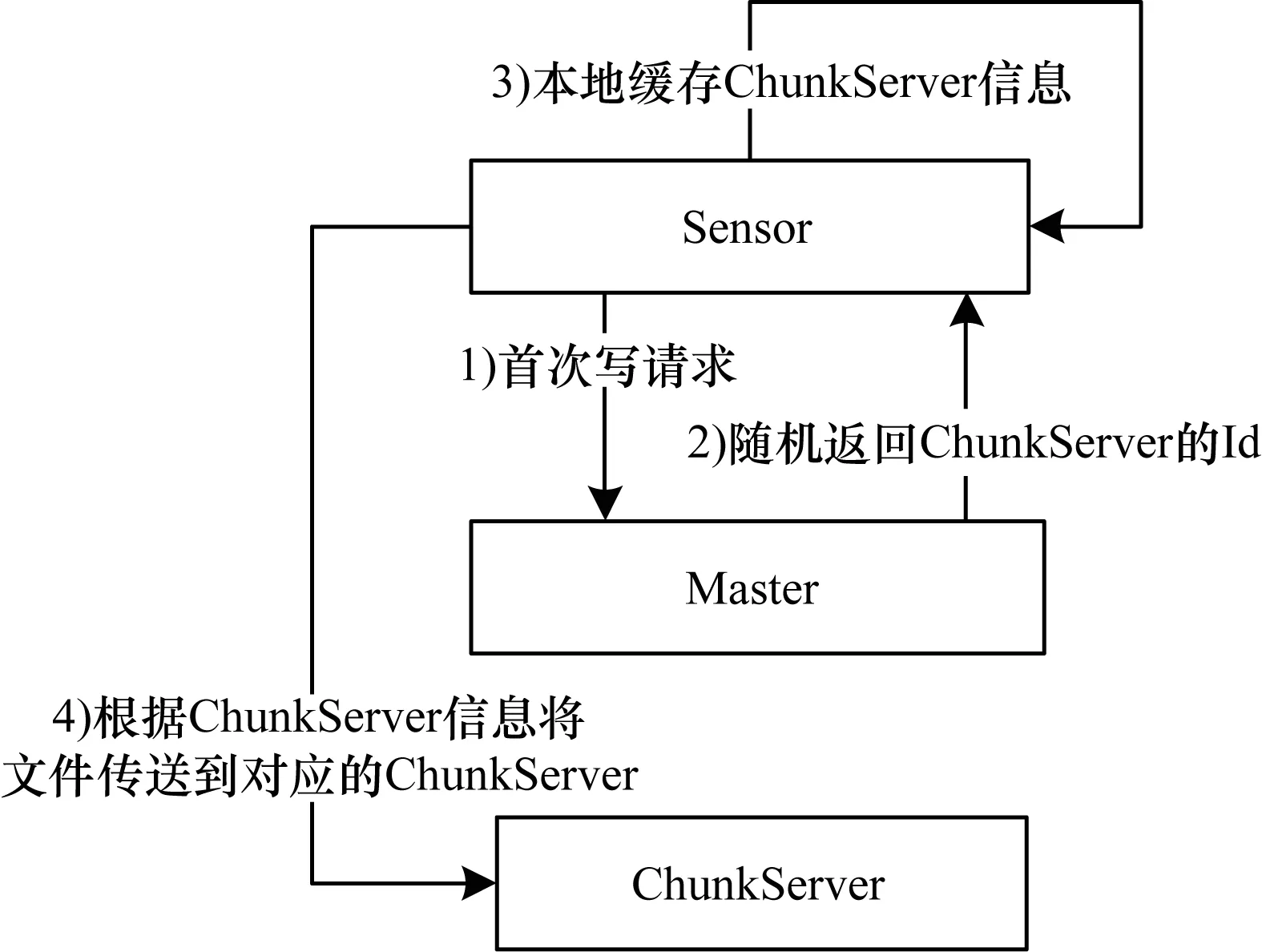
图3 Sensor首次请求响应过程
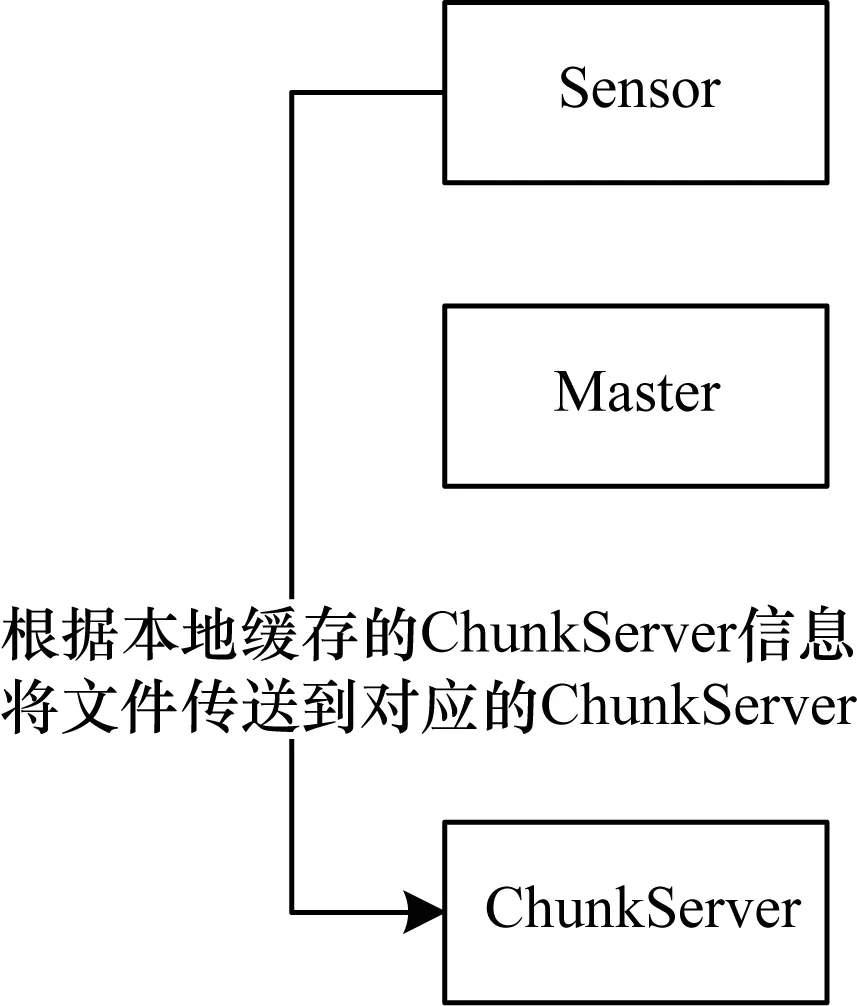
图4 Sensor非首次请求响应过程
改进系统的协同交互过程如图5所示。假设Sensor对应本地缓存的ChunkServer为ChunkServer1,一开始Sensor会把数据传送向ChunkServer1,在经过图3中步骤2)~步骤4)后,Master节点返回负载均衡调度信息通知源节点ChunkServer1和目的节点ChunkServer2,系统则根据返回的信息进行数据传输和传感器调度。

图5 改进的SensorFS系统交互过程
2.2 分布式传感器聚类
分布式传感器聚类的总体过程如图6所示,其中,三角形代表各个传感器si,圆形表示聚类后产生的类cj。

图6 分布式传感器聚类过程
本文用ok表示传感器感知到的对象,用O表示对象ok的集合,每个传感器si都对应其检测到的对象的集合Oi,用S表示传感器si的集合,用C表示聚类后类的集合,用CSi表示第i个ChunkServer子节点,用SDG_SK表示基于SDG的聚类过程。
式(1)表示对CSi节点上的n个传感器S及对应对象的集合通过SDG_SK进行聚类,最终得到CSi节点上m个类及每个类所共有的对象的集合(Oc1,Oc2,…,Ocn),记作CCSi,m,整个过程对应图6上方的ChunkServer部分。
CCSi,m=SDG_SK(O1,O2,…,On)
(1)
式(2)表示Master节点收集k个CS节点上已经通过式(1)聚类完成后的所有类的集合及每个类对应的所共有的对象的集合(CCS1,m,CCS2,m,…,CCSk,m),然后对传感类通过SDG_SK进行聚类,得到p个聚类后类的集合Cp,整个过程对应图6中间的Master部分,不同的地方在于Master节点上大圈内部是小圈(传感器类)而不是三角形(传感器)。
Cp=SDG_SK(CCS1,m,CCS2,m,…,CCSk,m)
(2)
本文提出的将集中式传感器聚类操作转化为分布式传感器的方案,首先由各个ChunckServer子节点对各自内部的传感器进行聚类操作,这样可以把内部传感器聚为m个类并且提取出各个传感器类的共有特征,然后再由Master节点对这些已经预先聚类过的类及类特征进行聚类,从而降低Master节点的内存和计算压力,同时提高聚类算法的并行度,减少在对海量传感器数据执行聚类算法时的时间消耗。假设T1集中式传感器聚类的耗时,T2为分布式传感器聚类的耗时,N为集群节点数量,Tcom为ChunkerServer把聚类后的类信息传送给Master节点的通信时间,Tmaster为Master节点对类进行聚类的时间。Tcom和Tmaster随着设定的聚类后类的数量M的增大而增大,但M一定远小于传感器的数量Nsensor,因此,在Nsensor极大时可将(Tcom+Tmaster)近似看为0,此时分布式传感器聚类的耗时T2仅为T1的1/N,随着节点N数量越大,聚类耗时就越少。
(3)
分布式传感器聚类算法具体描述如下:
算法1分布式传感器聚类算法
Slave节点(CSi):
设置聚类后的目标类的数量m;
获取CSi节点上的n个传感器S及对应对象的集合(O1,O2,…,On);
对上一步获取到的数据进行聚类SDG_SK(O1,O2,…,On)得到CCSi,m;
把本节点上的CCSi,m传输到Master节点
Master节点:
接收所有子节点上的数据CCSi,m;
得到CSi节点上m个类及每个类所共有的对象的集合(CCS1,m,CCS2,m,…,CCSk,m);
对传感器类进行聚类SDG_SK(CCS1,m,CCS2,m,…,CCSk,m)得到Cp
2.3 细粒度负载均衡

Δt=t2-t1
(4)
(5)
(6)
(7)
(8)
(9)
集群负载均衡的过程在Master节点上通过总传感器类负载均衡算法完成,如算法2所示。
算法2细粒度负载均衡调度算法
对于主节点上的传感器集合Cp中的每一个传感器类C:
计算该类的负载L
把C拆分为2类:C1 和 C2
把拆分出的2类加入待调度类的列表
Else
从可用节点列表获取一个可用节点
If 该节点的当前总负载大于L:
把集合C中的传感器迁移到该节点
Else
把该节点中的传感器迁移到集合C所在节点
迁移目标节点的总负载+=L
把该节点从可用节点列表移除
整个基于传感器的负载均衡算法基于3个目标:

2)在满足目标1)的情况下最小化R的值,将整个负载均衡问题转化为一个最优化问题。
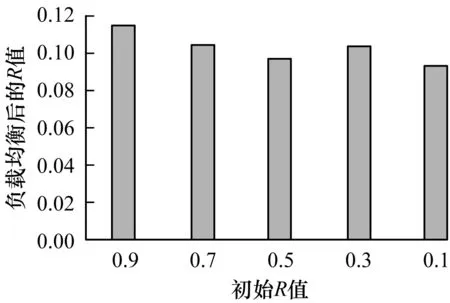
3)在需要把类A和类B迁移到同一个节点上时,若LA 本文基于仿真环境产生测试数据,所提供的可调整参数如表1所示,通过调整其中参数的值,可以对分布式聚类性能和负载均衡性能进行评估:调整SENSOR_NUM的值可以测试出分布式聚类在不同传感器数量的情况下的性能;调整CLUSTER_NUM的值可以影响聚类复杂度和传输数据的量;CLUSTER_SAME_OBJECT_NUM为每个传感器类共有的对象数量,调整该值可以影响单传感器类传输到主节点的数据量。 表1 测试程序可调参数 图7和图8分别为在目标传感器类个数为10和100的情况下,不同数量的传感器聚类时间随着节点数量增大时的变化趋势。节点数量为1时的聚类时间即集中式传感器聚类所消耗的时间,可以看出分布式传感器聚类时间小于集中式传感器聚类时间,并且聚类时间随着节点数量的增加而变短。此外还可以看出,在传感器数量较少时,分布式传感聚类相对于集中式传感器聚类时间优势不明显,这是因为分布式传感器聚类多了数据传输时间,而在传感器数量较少时,计算时间也较为短,相对而言数据传输时间的所占比重也会变大。但是,随着数据量的增大,传输时间所占的比重也就越小,考虑到物联网数据的海量性特点,分布式传感器聚类算法的优势也就越明显。 图7 目标传感器类个数为10时的聚类时间 图8 目标传感器类个数为100时的聚类时间 图9和图10分别为在传感器个数为100 000和1 000 000的情况下,目标传感器类个数分别为10和100时的聚类时间比较。 图9 传感器个数为100 000时的聚类时间 图10 传感器个数为1 000 000时的聚类时间 从2幅图中折线的下降趋势和斜率可以看出,目标类数量越大,折线下降得越快,即表明分布式传感器聚类算法的效果越好。这是因为目标传感器类数量越多,聚类所花费的时间也就越长,此时提高聚类的并行度的效果也就越好。 本文的负载均衡的最小单位为一个传感器类,图11展示了在不同目标传感器类个数情况下的负载均衡性,集群均衡度R越趋近0则负载越均衡。从图11可以看出,目标传感器类越多,负载越均衡,这是因为传感器类越多,每个传感器类的所包含的传感器数量就越少,即粒度越小。 图11 不同目标传感器类个数情况下的负载均衡性 在设定目标传感器类为50时,图12表明在集群初始均衡度从0.9到0.1变化时进行负载均衡后集群的均衡度。从图中可以看出,均衡后的R值基本在0.1处上下浮动。因此,细粒度负载均衡调度算法能提高集群负载的均衡性。 图12 目标传感器类个数为50时的负载均衡性 本文设计了分布式传感器聚类算法和基于传感器的细粒度的负载均衡算法。通过理论分析与实验表明,分布式传感器聚类算法能有效地提升海量传感器时的聚类速度,减轻Master节点的内存和CPU压力,并且把传感器传送文件的速率考虑在内。而负载均衡算法则能有效提升系统的均衡性和稳定性。考虑到雾计算能利用物端的计算能力来提升物联网的性能,因此,下一步是将其引入系统架构中,使部分计算任务在物端完成,从而在降低集群计算压力的同时,减少网络传输数据量并降低延迟,提升物联网文件计算与存储性能。 [1] 田 野,袁 博,李廷力.物联网海量异构数据存储与共享策略研究[J].电子学报,2016,44(2):247-257. [2] 李 敏,倪少权,邱小平,等.物联网环境下基于上下文的Hadoop大数据处理系统模型[J].计算机应用,2015,35(5):1267-1272. [3] 马友忠,孟小峰.云数据管理索引技术研究[J].软件学报,2015,26(1):145-166. [4] GARCIA H,LUDU A.The Google File System[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43. [5] SHVACHKO K,KUANG H,RADIA S,et al.The Hadoop Distributed File System[C]//Proceedings of the 26th IEEE Symposium on Mass Storage Systems and Technologies.Washington D.C.,USA:IEEE Press,2010:1-10. [6] Hadoop Archives(2016)[EB/OL].[2016-11-10].http://hadoop.apache.org/docs/stable1/hadoop_archives.html. [7] Hadoop Sequence File (2016) [EB/OL].[2016-11-10].http://hadoop.apache.org/common/docs/current/api/org/ap ache/hadoop/io/SequenceFile.html. [8] LIU Xuhui,HAN Jizhong,ZHONG Yunqin,et al.Implementing WebGIS on Hadoop:A Case Study of Improving Small File I/O Performance on HDFS[C]//Proceedings of 2009 IEEE International Conference on Cluster Computing and Workshops.Washington D.C.,USA:IEEE Press,2009:1-8. [9] CHEN Jilian,WANG Dan,FU Lihua,et al.An Improved Small File Processing Method for HDFS[J].Inter-national Journal of Digital Content Technology and Its Applications,2012,6(20):296-304. [10] XUE Shengjun,PAN Wubin,FANG Wei.A Novel Approach in Improving I/O Performance of Small Meteorological Files on HDFS[J].Applied Mechanics and Materials,2011,117-119:1759-1765. [11] ZHANG Yin,HAN Weili,WANG Wei,et al.Optimizing the Storage of Massive Electronic Pedigrees in HDFS[C]//Proceedings of the 3rd International Conference on Internet of Things.Washington D.C.,USA:IEEE Press,2012:68-75. [12] HAO Xingjun,JIN Peiquan,YUE Lihua.Efficient Storage of Multi-sensor Object-tracking Data[J].IEEE Transactions on Parallel and Distributed Systems,2015,27(10):2881-2894. [13] JIANG Yichuan.A Survey of Task Allocation and Load Balancing in Distributed Systems[J].IEEE Transactions on Parallel and Distributed Systems,2016,27(2):585-599. [14] 陈 涛,肖 侬,刘 芳.对象存储系统中自适应的元数据负载均衡机制[J].软件学报,2013,24(2):331-342. [15] 孙 耀,刘 杰,叶 丹,等.分布式文件系统元数据服务的负载均衡框架[J].软件学报,2016,27(12):3192-3207.3 实验与结果分析
3.1 实验准备

3.2 分布式聚类性能实验




3.3 负载均衡性能实验

4 结束语
