基于大数据挖掘技术的智能变电站故障追踪架构
2018-02-27高洪雨马志广张艳杰何登森
王 磊, 陈 青, 高洪雨, 马志广, 张艳杰, 何登森
(1. 国网技术学院, 山东省济南市 250002; 2. 电网智能化调度与控制教育部重点实验室(山东大学), 山东省济南市 250061)
0 引言
电力系统故障诊断作为智能电网自愈功能实现的基础课题,近年来的研究成果非常丰富,在生产现场也得到了一定的应用[1]。目前的故障诊断技术主要依靠保护启动、保护动作信息以及断路器跳闸信号进行故障推理,例如基于时间序列相似性匹配的方法[2]、基于随机优化技术的方法[3]、基于推理链的方法[4]、采用多数据源融合的诊断方法[5]以及与或树模型[6]等。上述故障诊断算法需要及时、稳定的实时数据来支撑。但是由于目前的各种信息系统缺乏有效的数据预处理机制且彼此之间相互独立,造成了如下两种不利因素:第一,故障后各级变电站报警信息同时向地调或省调度中心汇集,多次网关中转以及通信信道不稳定极易造成信息丢包或时序错误;第二,现代电网故障诊断技术需要的数据在变电站服务器、生产控制大区以及管理信息大区都有分布,存在跨调度安全隔离区和跨多系统的问题,信息壁垒严重。
另一方面,大数据技术及云计算的兴起与不断完善,引起了智能电网数据管理模式的根本改变[7-9]。大数据技术是能够通过对大量、多种类和来源复杂的数据进行高速捕捉、发现和分析,用经济的方法提取数据价值的技术体系或技术架构[10]。大数据技术规模性、多样性、高速性的特点恰好能够弥补上述电力故障信息系统的不利因素[11-12]。
目前智能变电站配置了多种信息采集系统,目的是对站内各种设备进行有效监控。众多信息带来海量数据的同时,也给检修人员带来极大不便,面对约2 s就会翻屏的实时告警监视器,难免出现遗漏,这在一定程度上降低了信息资源的利用率。本文出发点是在故障后利用故障诊断的结果对保护或断路器的不正确动作情况进行分析,并运用大数据体系架构对电力系统故障信息收集方式进行改进,重点利用数据挖掘技术对目前故障诊断算法中的难点问题——保护或断路器拒动的情况进行反向追踪,充分利用电力系统中各类信息源的同时,扩展了故障诊断算法的功能。
1 基于大数据平台的电网故障信息架构
大数据平台能够运用资源优化调度、高速数据传输机制、数据副本管理等技术解决数据库集群所面临的数据高峰时刻的网络传输瓶颈及误码问题。鉴于故障后的诊断程序需要在短时间内处理大量的电气量或非电气量信息,因此本文在前期工作的基础上[13],选择大数据平台作为故障诊断系统的数据支撑环境,利用分布式存储技术来获取和管理变电站层故障数据,这样能够避免数据在调度端的过度拥塞,给上层的诊断程序提供更加稳定、快捷的数据接口。
1.1 大数据概念及实现方法
目前无论是数字化改造过的传统变电站还是智能变电站都配备了众多监控系统,单个变电站公用信号分类图中包含的画面索引包含全站测控检修、全站测控检修异常报警、逆变电源柜故障报警、时间同步系统主机柜告警、网络报文分析和制造报文规范(MMS)记录仪报警、同步相量测量主柜相量测量单元(PMU)装置报警、站控层网络交换机柜交换机报警、消防装置火灾告警、Ⅰ-Ⅳ区数据通信网装置报警、时钟检测单元(TMU)装置电源失电告警、局部放电在线监测(PDM)等多达60个报警窗,报警信息分为遥测、遥信、遥控、遥调、事件顺序记录(SOE)、保护事件、保护告警、保护管理、通信、电压无功控制(VQC)、开关刀闸动作、故障信息、越限告警等14类。按照每秒收到实时告警信息8条计算,每天约70万条。保存周期为一个月,在极端情况下,实时数据库中滚动的报警信息可达2千万条。对于整个电网的设备监测平台而言,要存储的监测或管理的数据量更加庞大,依靠传统的关系数据库很难满足智能电网对故障快速诊断及自愈的需求。因此本文试图利于大数据技术对现在的电网数据环境进行改进,并给出电网故障大数据平台的一种可选架构。
由于大数据是最近几年兴起的理论,其内涵和外延在不断演进,技术标准也相对开源,通常情况下被采用的定义是:大数据是指无法在一定时间范围内用传统数据库软件对其内容进行抓取、管理和处理的大量数据集合。大数据技术对智能电网建设的影响显而易见:大数据将为智能电网提供可靠的数据来源与稳定的数据质量,进而为各级调度中心对电网状态的掌控提供高效的管理机制[14]。例如可用于电网故障诊断的数据源(数据采集与监控(SCADA)系统、故障信息系统、通用面向对象变电站事件(GOOSE)、能量管理系统(EMS)等)都会通过相应的数据引擎注册为智能电网大数据平台的一部分,而大数据将通过资源管理框架对上述数据源进行统一的作业调度和数据管理,保持了各数据采集系统独立运行的同时,能够对电网故障数据并行处理,并随时保持高吞吐量的访问控制。
大数据领域当前最为流行的开源软件为Apache Hadoop[15]。Hadoop是一个能够对大量数据进行分布式处理的开源软件框架,用户可以根据其提供的框架来构建面向应用的分布式计算平台。根据Hadoop 2.0协议框架,本文提出的电网故障大数据平台架构如图1所示。
图中所示的故障大数据平台架构中,最底层是Hadoop分布式文件系统(Hadoop distributed file system,HDFS)。HDFS是一种能够在通用硬件上运行的高容错性分布式文件系统,可以提供超高吞吐量的访问数据,非常适合大数据集的应用。在故障大数据平台架构中,HDFS用来管理所有故障诊断所能用到的数据,例如用来生成电网可缩放矢量图形(SVG)图元拓扑的公共信息模型(CIM)配置文件、故障录波形成的Comtrade文件、保护配置及自检信息、断路器在线监测信息、SOE、信道自检以及Web日志等。相对于传统的分布式数据库,HDFS具备更好的分布式数据协调能力,集群间通过 HDFS 的 Hadoop RPC 协议通信,能够运用备份存储技术增加系统的容错性。Hadoop通过统一资源管理框架(yet another resource negotiator,YARN)为各类应用计算提供资源调度和管理。YARN在框架中的作用是为故障诊断及追踪中的多个子程序(例如需要实时计算的故障诊断程序、站内报警信息查询程序、电网拓扑处理程序、离线录波分析程序等)提供统一的资源调度服务,共享集群资源。YARN将框架中的数据资源与诊断程序分离,其优点在于,当上层的诊断算法有变化时,不会影响到HDFS;而集群中出现新的数据监测系统时,诊断程序不会因新资源的加入而全部重写。YARN的上层是以Apache Spark为主要计算框架的故障诊断程序。Apache Spark是由UC Berkeley AMP lab开发的分布式计算框架[16-17]。Apache Spark能够兼容Apache Hadoop的API,因此可以任意读写HDFS中的资源,能够与YARN无缝连接。相比Hadoop自身携带的MapReduce大规模数据集计算模型,Spark完全基于内存计算,包括中间结果也完全缓存在内存中,因此运算性能更加优越,对实时处理系统的处理更为高效。
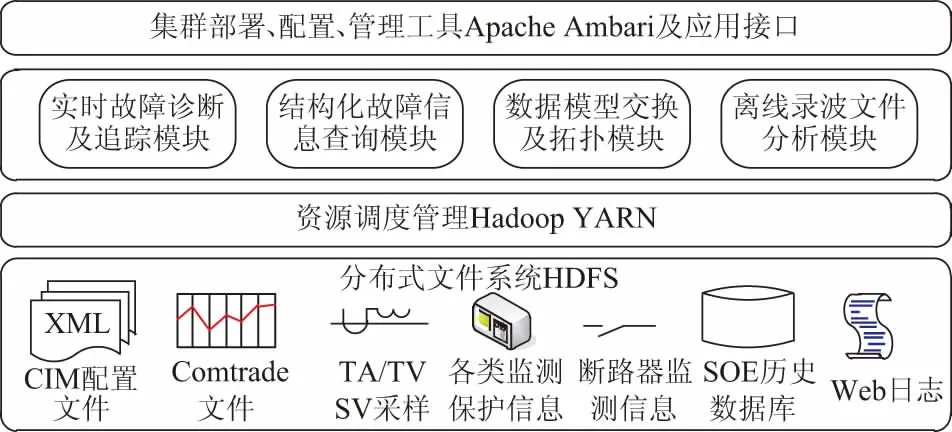
图1 电网故障大数据平台架构Fig.1 Big data platform of power grid fault
鉴于上述分析,本文将故障后的处理程序分为4个模块。第一,实时故障诊断及追踪模块。该模块是诊断程序的主体部分,负责对报警数据进行分析,找出故障元件或者保护、断路器拒动的原因。由于该模块的处理优先级最高,本文选择Spark Streaming组件对该模块进行处理。Spark Streaming组件的特点是能够接收实时数据,按周期将数据分为多批次进行处理,处理周期短,一般为毫秒级。Spark流式计算程序能够最大限度地契合故障诊断程序实时处理的特点,将Spark的运算性能发挥出来。第二,故障信息查询模块。目前电网的分级调度机制规定只有事故级报警信息才能上传调度主站,很多对故障诊断有用的预警信息仅在变电站后台存储,因此可以利用Spark SQL对站内数据进行查询,为故障追踪提供支持。Spark SQL具备传统SQL的交互式查询功能,采用基于Spark的内存处理方式,能够对分布式数据集进行结构化查询且性能非常高。由于Spark平台具有高度整合性,Spark SQL的查询结果能够直接提供给故障诊断及追踪模块的Spark Streaming进行处理。第三,数据模型交换及拓扑模块,能够实现调度主站与变电站之间的数据交换以及电网拓扑计算,实现图形的快速拼合与分析,形成全网拓扑,进而通过拓扑计算找出无源子网,缩小故障诊断范围。第四,离线录波文件分析模块作为故障后的分析部分,被设计为一个批处理系统。该模块的处理对象为几十兆的录波文件,可以选择Hadoop的分布式计算组件MapReduce对其进行离线计算,MapReduce的优势在于大块数据处理,数据就近复制策略也使其具有良好的容错性,适合录波文件的分析与存储。
框架的最上层是集群部署、配置、管理界面以及应用接口层。该界面由Apache Ambari实现。Apache Ambari是一种基于Web的大数据部署工具,支持Apache Hadoop集群的供应、管理和监控。应用接口可以给智能电网的自愈程序提供诊断结果,或者在调度中心给出故障简报。
电网故障大数据平台的运行过程为:首先Ambari通过图形用户界面为Spark启动某个程序模块,进而Spark将该模块所需的资源调度交给YARN进行处理;YARN可以被看作一个云操作系统,它将Spark程序作为一个Client并在集群节点上为其启动一个资源管理器,对Spark程序分配内存、CPU、信道等资源;Spark部署完毕之后,可以通过携带的执行命令对指定位置的HDFS数据资源进行存取、统计或者删除操作;操作结果输出之后,Spark在YARN资源管理器中注销任务,释放资源。
1.2 基于大数据平台的故障追踪过程设计
为了更好地对电网故障大数据平台进行业务流分析,本文从数据处理实时性角度对电网故障诊断及追踪过程做了分析,将其分为三个处理系统:实时处理系统、准实时处理系统和批处理系统。实时处理系统是将接收到的数据或消息进行实时处理响应;准实时处理系统是将数据以批量的形式输入,一旦检测到数据进入立即开始处理;批处理系统是将数据以成批的多组文件形式输入,以工作流的方式对其进行调度处理。三个处理系统的工作方式如附录A图A1所示。
在实时处理系统中,事故级信息由保护启动、保护动作以及断路器跳闸信息组成,对应站内告警窗中危急类信息。变电站会将事故级信息实时上报,在调度端也能够得到最高级别的响应。目前的电网故障诊断算法也都基于事故级信息,因此实时处理系统优先级最高,反应也最迅速。若故障诊断算法得出的结论为保护及断路器均正确动作,则将诊断简报抄送调度人员或转智能电网自愈程序;若故障诊断算法判断出有保护、断路器拒动或误动,则将准实时处理系统上线。在准实时处理系统中,一般级信息由GOOSE链路诊断信息、录波提示、采样值(SV)链路断线等信息组成,对应站内告警窗中的严重类信息;预告级信息由保护装置告警、保护电压互感器(TV)采样异常、线路测控光纤采样异常、断路器在线监测等信息组成,对应站内告警窗中的一般类信息。变电站内一般级和预告级信息采用轮询的方式采样,但是仅在变电站内部作为检修处理的依据,不上报调度端。当实时处理系统判断出有保护或断路器不正确动作时,一般级和预告级信息将会为不正确动作原因的查找提供必要的支撑,因此本文将采取数据挖掘的方式将其设计成准实时处理系统。变电站中录波文件存储空间较大,一般在几十到几百兆之间,针对录波文件存储空间大、实时性要求不高的特点,本文采用批处理系统的方式。停电区域内涉及的变电站录波文件以批处理的形式进行分析,为故障诊断提供具体的故障相别、故障时间以及准确的故障位置。结合图1所示的电网故障大数据平台架构,故障诊断及追踪程序分4步完成。
步骤1:当故障发生后,保护及断路器动作等事故级报警信息被调度中心服务器收集,触发Spark中各故障诊断应用程序,应用程序会向YARN集群资源管理器提交任务申请。资源管理器负责调度各程序模块的运行资源,如内存、CPU、网络、磁盘空间等。
步骤2:资源管理器对每个任务分配工作节点(worker node,WN)。工作节点相当于各模块的执行器,故障诊断模块、信息查询等模块的程序代码都会被分发到相应的WN上。WN还能够定时向资源管理器反馈本节点的资源使用情况以及程序运行状态,同时接收资源管理器的启动或停止请求。
步骤3:各WN执行程序代码,其中,WN1从HDFS中提取报警信息(结构化数据),利用故障诊断算法找到故障元件,若诊断结果涉及保护或断路器不正确动作的情况,则利用WN2提供的站内数据进行故障追踪;WN2利用Spark SQL对HDFS中的站内信息进行查询,筛掉录波完成、局放在线监测等与故障诊断及追踪无关的信息,将保护、断路器及信道相关的设备告警信息传送至WN1;WN3从HDFS中提取符合CIM模型的SVG文件(半结构化数据),形成全网拓扑,并根据断路器跳闸信息计算出停电区域,输出到WN1;WN4对故障后产生的录波文件(非结构化数据)进行离线分析。
步骤4:WN1将故障诊断及追踪结果返回故障诊断请求接口,即Ambari用户界面;WN4将离线分析结果,例如故障相别、故障时间等线下发送至诊断请求接口。
故障诊断程序工作流程如图2所示。
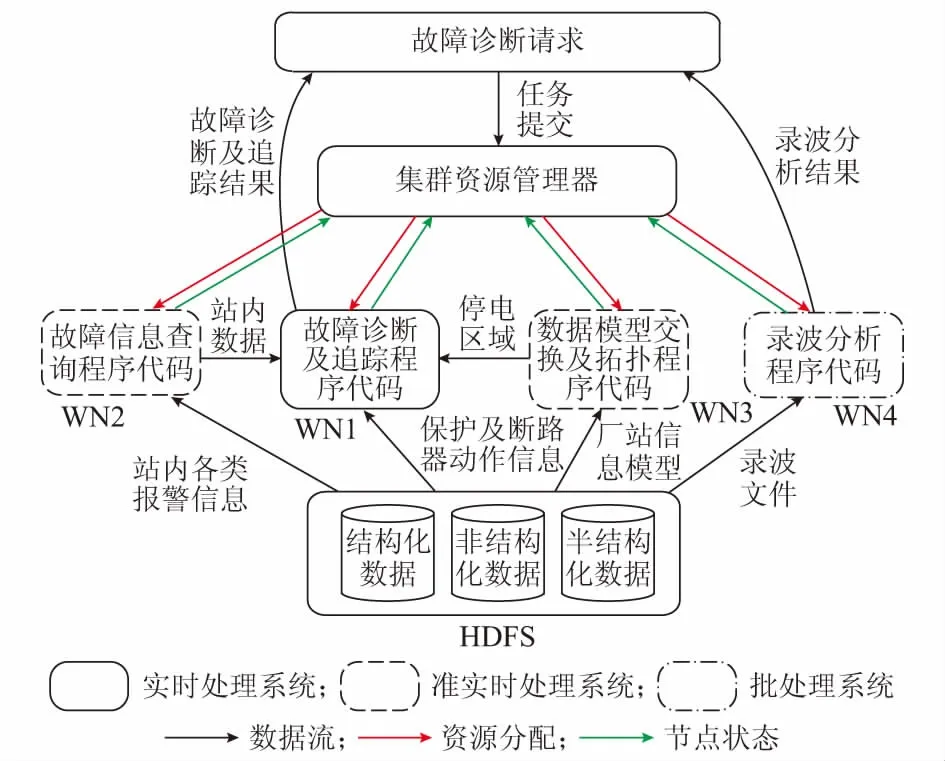
图2 故障追踪程序流程图Fig.2 Flow chart of fault trace program
与目前C/S形式的故障诊断模型相比,基于大数据平台的故障诊断程序由Spark统一调配,计算资源由调度端单机运行变为以多个变电站服务器为依托的集群运行,无论是从CPU还是内存资源都能得到极大的提升。另外,诊断用的报警信息不用上传至调度端,可以通过YARN直接从HDFS集群中直接调用,减少了调度端的数据拥塞,提高了诊断程序的可靠性。
2 适用于电网故障追踪的数据挖掘方法
目前的故障诊断算法在保护及断路器均正确动作的前提下,对故障元件的分析比较准确。但是在保护或断路器发生拒动的情况下,很多诊断算法只是根据远后备的动作情况判断出有拒动的情况发生,并不能推断出是保护还是断路器拒动,更不能对拒动的原因进行故障追踪。电网故障追踪在本文中的含义是指在调度端对收集到的报警信息调用故障诊断算法之后,发现有断路器及保护存在不正确动作的情况,运用数据挖掘技术对变电站内部的数据进行分类抽取,进而找出错误动作的过程。
导致目前故障追踪研究较为少见的根源在于当前的诊断算法完全依赖上传至调度端的事故级报警信息,未能对在变电站层的故障断面进行全面的分析。如果要深入到变电站层进行数据分析,需要解决两方面的问题:第一,如何将变电站配置的各类信息系统的数据与故障诊断及追踪程序高效对接;第二,怎样在海量的站内数据中提取出能够被故障追踪算法所用的数据。第1节提出基于大数据平台的故障诊断应用程序能够解决诊断程序与变电站数据的对接问题,本节将运用数据挖掘技术解决变电站层数据的分析。
数据挖掘是指从大数据集或数据仓库中,提取有用的、人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用信息[18]。由于数据挖掘应用的领域不尽相同,随之也产生了相应的算法,例如适用于频繁模式和关联规则的Apriori算法、适用于数据分类的决策树算法以及直接聚类方法k-means算法。
本文将智能变电站(或者经过数字化改造的传统变电站)的各类数据采集系统作为原始数据源,重点对其中涉及的故障诊断相关信息进行数据挖掘,进而对调度端的故障追踪程序提供决策支持。
2.1 基于决策树的故障数据挖掘方法
决策树(decision tree,DT)是目前最为广泛的数据挖掘分类算法,主要用于处理非连续型变量的分类及预测问题,可以用树形结构或IF-THEN形式进行描述,是一种可收敛的分类器或预测模型。决策树通过对输入信息不断的细化分类,使依赖变量的差别最大化,最终将数据分类到无交集的分枝,在依赖变量的值上建立最强的分类[19]。相对于神经网络聚类、高斯混合聚类、k-means等聚类算法,决策树具有如下优点:决策树模型可用图形或规则进行描述,对于推理过程具有可解释性;由于决策树的大小与数据集大小无关,因此计算量不会随数据量增多而变大。由于电网故障后需要在短时间内对各变电站产生大量报警信息进行分析,因此本文选择决策树对报警信息进行分类,以期对调度端的故障追踪程序提供决策支持。
决策树的生成采用自顶向下的递归分治算法,在最初的训练集上选择最能体现分类目标的样本属性对训练样本进行分类,进而建立一个分类节点,然后继续这一过程直到这棵树能准确地分类训练样本,或所有的属性都已被使用过。
决策树的定义如下:对于一个数据集D={d1,d2,…,dn},其中每一元组ti∈D包含变量A={a1,a2,…,am}。同时给定类别集合C={c1,c2,…,ck}。对于数据集D,决策树T具有下列性质。
1)每个内部节点都被标记一个属性ai∈A,表示一个变量的测试。
2)每个分枝代表一个测试输出,表示变量的一个可能值。
3)每个叶节点被标记为一个类cj∈C,表示分类结果的类别。
利用决策树对数据进行分类和预测的步骤如附录A图A2所示。
决策树分类算法是一种监督式学习方法,以训练样本作为输入,以监督模型作为分类规则,通过归纳算法产生决策树,再对陌生数据集进行预测分析[20]。结合智能变电站信号传输机制以及保护、断路器的硬件结构,本文将监督模型分为三类进行测试:保护拒动信号类、信号通道故障信号类、断路器拒动信号类,其作用是在决策树构造前期使训练样本按照监督模型有序分类。保护拒动信号类如附录A图A3所示,信号通道故障信号类如附录A图A4所示,断路器拒动信号类如附录A图A5所示。
决策树构建步骤如下。
步骤1:训练集(某段时间内所有的报警信息)首先进入归纳算法,若样本在监督模型中,则生成为监督模型最上层节点中的树叶节点。
步骤2:若不在监督模型中,则选取故障后报警窗中重复出现次数最大的某条记录分割为一个节点,根据监督模型的中间逻辑,为该分割记录的节点分配一个分枝。取报警记录的信息增量作为其分类标准,目的是让报警条数最多的记录首先被处理。
步骤3:当训练集所有样本都存在于某个节点,则分割停止,决策树分类完成。
训练样本格式参考目前主流的监控后台报警格式,主要属性为告警时间、信息等级、告警类型以及告警对象。考虑到各厂家的监控系统报警数据上传间隔不同,本文取最大周期值的3倍,即6 s为一个时间窗,计算信息增量。若信息增量小于等于1条,该信息在3个周期内仅发送一次,视为误报信息,等待运行人员复位即可消除;若信息增量在1条至4条之间,视为间发性报警,将信息暂存后等待下一个时间窗叠加分析;若信息增量在4条以上,则每个周期至少发送一次,按照附录A图A3—图A5所示的监督模型生成决策树。例如,直供电源故障引起的保护拒动决策树如附录A图A6所示。
通过分类步骤可以看出,在监督模型确定的情况下,训练集中的样本数越多,生成的决策树越完善,分类越精确。例如,某些系统对TV/电流互感器(TA)采样失败产生的报警信息为“电压/电流采样异常”,与监督模型提供的“TA/TV采样异常”同意不同名。若该信息多次出现,根据信息增量最大原则,会另外形成一个新节点,避免分类错误。
进入大数据平台HDFS的数据经过决策树分类,会剔除保护启动、保护动作、断路器跳闸、录波完成、变压器监测等与故障追踪无关信息,通过决策树过滤后的数据按照监督模型分为三大类。
2.2 分布式决策树故障追踪算法
决策树对训练样本的分类算法完成之后,就可以对未知类别的数据集进行预测。对应于电网故障追踪的过程,即对变电站层的各种数据进行分析,给出保护或断路器拒动原因。
本文依据经典的ID3算法[21]提出了一种大数据平台下的分布式决策树故障追踪算法,该分布式算法底层由运行在各厂站端的局部决策树归纳算法组成,该算法负责提取本厂站内部的各种报警信号,通过监督模型将其递归分割为决策树的一枝子树;上层为运行在调度中心的最终决策树,该算法汇集故障区域内各变电站的监督模型以及决策子树,取全局信息增量最大的决策子树作为优先判断的子树,并形成最终决策树预测模型。这种变电站端分布式数据划分与调度端决策树集中生成相结合的方法,不仅避免了数据在调度端的大量堆积,而且能够和大数据平台的Spark Streaming紧密结合,使真正有故障的变电站被优先诊断,将运行效率最大化。
电网故障追踪算法具体过程如下:调度端故障诊断程序判断出有保护或断路器拒动,调用分布式决策树生成算法。首先,故障区域内各变电站内调用局部算法,对站内报警信息进行预处理,形成训练样本集,按监督模型对局部报警信息进行分类。厂站在选择当前监督模型的同时,将当前样本集按照监督模型传给调度端全局算法。全局算法综合各厂站传来的监督模型及样本增益,依次求出全局最大信息增量值返回给各厂站的局部算法。局部算法根据返回的信息增量值建立报警记录的一个节点,继续分割各自的报警信息,进而形成局部决策树。该局部决策树根节点为信息增量值,树枝节点为报警记录,叶子节点为故障性质。当各厂站的样本被划分完毕后,形成的局部决策树被传送至全局算法,具有最大信息增量的子树放在最右端优先被决策。最终决策树根据输入的分类数据以及增益数值,给出预测结果。算法流程图如图3所示。
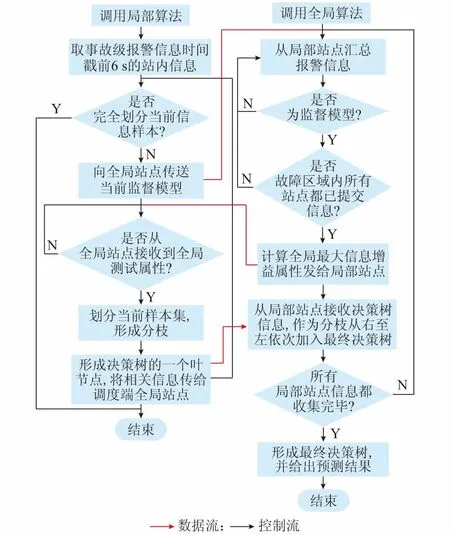
图3 分布式决策树故障追踪算法Fig.3 Fault trace method of distributed decision tree
2.3 决策树模型在Spark架构中的实现
通过决策树完成的电网故障追踪模型由Spark Streaming实现。首先Spark Streaming将局部决策树所划分的故障数据存储为弹性分布式数据集(resilient distributed datasets,RDD)格式。每个 RDD 的数据都以 block 的形式存储在各节点中,例如,可以设定每隔2 s的告警信息对应一个RDD。故障数据分配的同时,分布式决策树故障追踪程序将以Dstream的形式运行,同样每一个信息增量下面的分枝判断程序会对应一个Dstream内部RDD上的操作,每个分枝的判断结果由全局算法经过Spark批处理系统输出诊断结果。由于决策树每个分枝的操作方式类似,因此各RDD的大小较为均衡,能够最大限度发挥Spark Streaming小批量计算优点,两者的结合能够起到很好的效果。具体实现框图如附录A图A7所示。
3 实验分析
3.1 实验环境
实验室大数据平台配置5台物理工作站,使用CentOS 6.4作为系统环境,并行计算框架根据Hadoop 2.6.0环境搭建,安装Spark-1.2.0集群组件。1台工作站作为调度中心故障诊断服务器,4台工作站搭载Oracle数据库模拟变电站服务器。
实验数据取自智能变电站综合仿真实训系统。该系统可收集相邻5座220 kV变电站的各类数据,这些数据均由实际保护及在线监测系统产生,然后经模拟通信系统汇集至调度中心服务器。
3.2 数据分析
本文对仿真实验室内故障涉及的3座变电站进行了故障设置后信息抽样统计。故障设置为甲、乙两座变电站之间的线路发生永久性接地短路故障,甲变电站保护拒动,由下级丙变电站零序过流Ⅲ段切除故障。3座变电站约7千万条信息中由Spark SQL查询出相关事故级报警信息168条,一般级报警信息143条,预告级报警信息122条。设置信号通道故障后,甲变电站故障后6 s内查询出的信息增量统计如表1所示。乙、丙两座变电站信息增量最大值均为对端保护装置告警,分别为8条和6条,其他为局放在线监测、复归等信息。

表1 信息增量统计表Table 1 Statistical table of information gain
调度端诊断模型采用目前上线的诊断算法[22],可根据各站的事故级信息判断出故障线路及甲变电站的不正确动作情况,然后启动图3所示的故障追踪程序。首先三个变电站按照报警信息样本,将对应监督模型传送至调度端的全局算法,其中甲变电站根据表1,将传送保护拒动以及信号通道故障监督模型,同时全局算法利用Spark Streaming搜集所有变电站的报警信息,求出信息增量并排序。其次全局算法将信息增量从高到低返回局部算法,其中甲变电站电流电压采样异常报警信息首先被选中并根据保护监督模型形成一个分枝加入最终决策树。最后按信息增量依次将故障信息对应的监督模型形成分枝添加入决策树,形成的最终决策树如图4所示。
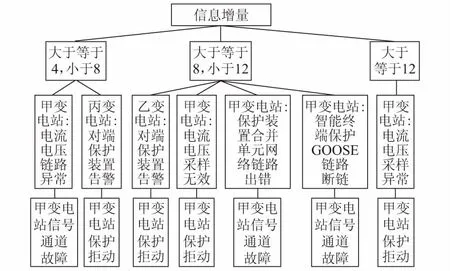
图4 实验形成的最终决策树Fig.4 Final decision tree formed by experimental data
最终决策树给出的追踪结果为甲变电站信号通道故障导致保护拒动,其中最大信息增量为电流电压采样异常,其次为智能终端保护GOOSE链路断链、保护装置合并单元网络链路出错以及电流电压采样无效。相比于目前只给出故障元件的故障简报,增加了故障追踪的简报,给出了变电站层二次侧的故障诊断内容,替代了目前电话咨询及汇报的方式。
3.3 实验评价
本文提出的故障追踪方法与现行的故障处理流程对比如附录A图A8所示。
两者的故障诊断及追踪时间对比如表2所示。单从诊断时间上看,t1~t3阶段Spark系统对故障分析并不占优势,但在t4阶段能够利用其强大的数据分析能力代替变电站运维人员进行拒动原因查找工作,形成更加详细的故障简报。而目前的电话汇报制度在t4阶段至少需要5 min,可见本文提出的方法相比目前的故障诊断系统在效率上有一定的提高。在t2~t3时间段涉及的大数据与单机关系数据的查询效率对比如附录A图A9所示。从图A9中的查询用时可以看出,Spark数据管理随着查询记录的增多,无论是查询时间还是趋势线的增长速度都低于关系数据库。由于t3时间段包括了决策树的分类算法,才导致该时间段Spark用时多于单机运行时间。

表2 系统运行用时对比Table 2 Operation time comparison of system
实验所用的训练样本与诊断结果关系如附录A表A1所示。
通过追踪结果准确率可以看出,由于断路器拒动监督模型中的树叶节点少于保护拒动监督模型中的树叶节点,所以在训练样本个数相同的情况下,追踪结果准确率要小于保护拒动模型。随着越来越多智能设备监测系统的上线,模型可依赖的监测数据源会逐渐增多,本文所提模型将会得到进一步完善。
4 结论
随着智能变电站内监控系统的逐步增加,越来越多的设备监测数据涌现在信息平台上。如何管理好这些海量数据,并从中挖掘出有用的知识,是必须直面的问题。本文根据电网信息采集系统的结构特点,按照Hadoop 2.0协议框架,提出了电网故障大数据的平台架构,在该架构上按照实时、准实时以及批处理三级系统对故障诊断及追踪程序进行了设计。最后,利用数据挖掘对变电站内的监测数据进行提取,利用决策树对保护及断路器不正确动作进行分析,追踪结果为电网故障诊断提供了有力支撑。另外,由于不同电压等级变电站故障后,故障信息数量不一致,本文下一步工作将针对更高电压等级的变电站进行故障追踪方法研究。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx)。
[1] 郭创新,朱传柏,曹一家,等.电力系统故障诊断的研究现状与发展趋势[J].电力系统自动化,2006,30(8):98-103.
GUO Chuangxin, ZHU Chuanbai, CAO Yijia, et al. State of arts of fault diagnosis of power system[J]. Automation of Electric Power Systems, 2006, 30(8): 98-103.
[2] 钟锦源,张岩,文福拴,等.基于时间序列相似性匹配的输电系统故障诊断方法[J].电力系统自动化,2015,39(6):60-67.DOI:10.7500/AEPS20140815001.
ZHONG Jinyuan, ZHANG Yan, WEN Fushuan, et al. A fault diagnosing method in power transmission system based on time series similarity matching[J]. Automation of Electric Power Systems, 2015, 39(6): 60-67. DOI: 10.7500/AEPS20140815001.
[3] GUO Wenxin, WEN Fushuan, LEDWICH G, et al. An analytic model for fault diagnosis in power systems considering malfunctions of protective relays and circuit breakers [J]. IEEE Transactions on Power Delivery, 2010, 25(3): 1393-1401.
[4] 张楠,冯琳,杨镜非,等.基于推理链的输电网故障诊断[J].电力系统自动化,2014,38(22):78-84.DOI:10.7500/AEPS20131126007.
ZHANG Nan, FENG Lin, YANG Jingfei, et al. Transmission grid fault diagnosis based on reasoning chain[J]. Automation of Electric Power Systems, 2014, 38(22): 78-84. DOI: 10.7500/AEPS20131126007.
[5] 夏可青,陈根军,李力.基于多数据源融合的实时电网故障分析及实现[J].电力系统自动化,2013,37(24):81-88.
XIA Keqing, CHEN Genjun, LI Li. Real-time analysis of power grid fault based on multi-source information fusion and its application[J]. Automation of Electric Power Systems, 2013, 37(24): 81-88.
[6] 王磊,陈青,高洪雨.输电网故障的与或树诊断模型[J].电力系统自动化,2016,40(2):100-106.DOI:10.7500/AEPS20150521004.
WANG Lei, CHEN Qing, GAO Hongyu. Model for and/or tree in power system fault diagnosis[J]. Automation of Electric Power Systems, 2016, 40(2): 100-106. DOI: 10.7500/AEPS20150521004.
[7] IBM. Managing big data for smart grids and smart meters[R/OL]. [2017-05-01].http://www.smartgridnews.com/artman/publish/Business_Strategy/Managing-big-data-for-smart-grids-and-smart-meters-5248.html.
[8] 彭小圣,邓迪元,程时杰,等.面向智能电网应用的电力大数据关键技术[J].中国电机工程学报,2015,35(3):503-511.
PENG Xiaosheng, DENG Diyuan, CHENG Shijie, et al. Key technologies of electric power big data and its application prospects in smart grid[J]. Proceedings of the CSEE, 2015, 35(3): 503-511.
[9] 中国电机工程学会电力信息化专委会.中国电力大数据发展白皮书[M].北京:中国电力出版社,2013.
[10] Big data [EB/OL].[2012-10-02]. http://en.wikipedia.org/wiki/Big_data.
[11] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4):927-935.
SONG Yaqi, ZHOU Guoliang, ZHU Yongli. Present status and challenges of big data processing in smart grid[J]. Power System Technology, 2013, 37(4): 927-935.
[12] 张东霞,苗新,刘丽平,等.智能电网大数据技术发展研究[J].中国电机工程学报,2015,35(1):2-12.
ZHANG Dongxia, MIAO Xin, LIU Liping, et al. Research on development strategy for smart grid big data[J]. Proceedings of the CSEE, 2015, 35(1): 2-12.
[13] 王磊,陈青,高湛军.基于网格平台的电网故障诊断架构[J].电力系统自动化,2013,37(3):70-76.
WANG Lei, CHEN Qing, GAO Zhanjun. A framework of power grid fault diagnosis based on grid platform[J]. Automation of Electric Power Systems, 2013, 37(3): 70-76.
[14] 韩笑,狄方春,刘广一.应用智能电网统一数据模型的大数据应用架构及其实践[J].电网技术,2016,40(10):3206-3212.
HAN Xiao, DI Fangchun, LIU Guangyi. A big data application structure based on smart grid data model and its practice[J]. Power System Technology, 2016, 40(10): 3206-3212.
[15] LAM C, WARREN J. Hadoop in action[M]. NY, USA: Manning Publications, 2009.
[16] MEHRAGHDAM S, KELLER M, KARL H. Specifying and placing chains of virtual network functions[C]// 2014 IEEE 3rd International Conference on Cloud Networking (Cloud Net), October 8-10, 2014, Luxembourg: 7-13.
[17] MATEI Z, CHOWDHURY M, FRANKLIN M J, et al. Spark: cluster computing with working sets[R]. 2010.
[18] WU Xingdong, ZHU Xingquan, WU Gongqing, et al. Data mining with big data[J]. IEEE Transactions on Knowledge & Data Engineering, 2014, 26(1): 97-107.
[19] LIU W Z, WHITE A P. The importance of attribute selection measures in decision tree[J]. Machine Learning, 1994, 15(1): 25-41.
[20] 栾丽华,吉根林.决策树分类技术研究[J].计算机工程,2004,30(9):94-96.
LUAN Lihua, JI Genlin. The study on decision tree classification techniques[J]. Computer Engineering, 2004, 30(9): 94-96.
[21] SQUIRE D M. CSE5230 tutorial: the ID3 decision tree algorithm[R]. Australia: Monash University, 2004.
[22] 赵冬梅,王守鹏.电网故障诊断的研究综述与前景展望[J].电力系统自动化,2017,41(1):1-12.DOI:10.7500/AEPS20170126001.
ZHAO Dongmei, WANG Shoupeng. Research review and prospects for power grid fault diagnosis[J]. Automation of Electric Power Systems, 2017, 41(1): 1-12. DOI: 10.7500/AEPS20170126001.
王 磊(1979—),男,通信作者,博士,高级技师,主要研究方向:电力系统故障诊断及其软件实现。E-mail: 37601391@qq.com
陈 青(1963—),女,教授,博士生导师,主要研究方向:电力系统继电保护及安全自动装置。
高洪雨(1967—),男,副教授,主要研究方向:电力系统继电保护及配电自动化故障检测。
