基于数据特性的Spark任务性能优化
2018-02-27吴毅坚赵文耘
柴 宁 吴毅坚 赵文耘
1(复旦大学软件学院 上海 201203) 2(复旦大学计算机科学技术学院 上海 201203) 3(上海市数据科学重点实验室 上海 200433)
0 引 言
近年来移动互联网和社交网络的发展迅速,互联网上的数据开始呈指数级的增长,如何高效而快速地对数据进行处理和分析逐渐成为了研究热点。Google公司作为拥有海量搜索数据的互联网公司,于2003年至2006年提出分布式文件系统HDFS和函数式编程模型Map-Reduce的概念[1]。Yahoo! 公司基于二者开发了可扩展的分布式计算框架Hadoop。由于Hadoop的基于硬盘存储数据的特点,在进行大数据集的多轮迭代运算时,硬盘的I/O和数据传输相对耗时,达不到相对实时的处理速度[2]。这一点在对日志监控,机器学习算法等领域,尤为明显。
Spark作为分布式数据处理框架,采用内存计算的方法引入弹性数据集RDD(Resilient Distributed Datasets)[3]的概念,将数据加载到内存里,降低了数据交换的访问延迟,达到了准实时分析大数据集的能力。Spark框架的推广和普及,极大地提升了分布式数据处理任务的运行效率。
然而,Spark框架本身也同样存在了运行效率的问题,存在可优化的空间。Spark运行大致有如下两个问题:(1) 弹性数据集RDD带来的内存不足的问题。出现内存不足的情况是因为Spark选择将数据持久化到机器内存中。这样设计的初衷是为了减少节点中的数据交换,可以加快数据任务的处理速度。但是当单个节点需要计算的数据超过机器内存的处理极限的时候,任务会因为内存不足而导致失败。(2) 数据倾斜问题导致的运行效率低下。数据集合具有不同的数据特性。如一篇文章中不同单词出现的次数是不相同的。我们把上述的数据分布不均的特性称之为数据倾斜。具有数据倾斜特性的数据在Spark框架中会导致数据在不同节点分布不均的问题。这不仅仅会影响数据处理效率,严重情况下也会导致任务失败。
针对上述问题,本文提出根据不同的数据特性自适应地对Spark代码进行优化的思路,从而达到对Spark数据处理任务进行调优的目的。Spark系统本身已具有优化不同数据集合特性的能力,但是程序员在编写代码时要了解所需要处理数据集的数据特性却并不容易。对于需要进行性能优化的任务,优化的步骤如下:(1) 程序自动分析代码片段[4],生成有向无环图(DAG);(2) 计算图中数据的倾斜度;(3) 根据不同的数据特性和场景自动选择生成相应的优化方案。
1 相关工作
目前针对Spark任务的优化研究的主要的思路有三点。一是针对数据对象的缓存进行优化,二是针对Spark任务的运行参数进行优化,三是针对任务调度中的资源分配进行优化。
通过对Spark框架内存计算模型的研究和分析,同时对Spark框架中内存使用行为进行建模,可以针对Spark的缓存系统实现不同程度的优化和改进。比如实现Spark系统的缓存策略自动化,通过代码语义分析自动识别有缓存意义的中间数据加载到缓存系统中。比如根据RDD的大小和权重信息,提出新的缓存算法,优化Spark系统的缓存模型等[5]。
Spark框架默认的参数配置不能使得所有数据分析任务都能够高效运行。因此可以针对不同的数据分析任务进行Spark框架的参数配置,可以优化Spark任务的运行效率。将Spark任务的运行数据和参数配置保存到数据库中,同时针对Spark任务进行特征工程提取任务特征,最后通过计算任务之间的相似度从数据库中选择合适的参数配置对任务进行优化[6]。
Spark框架在运行数据分析任务时需要结合当前集群的资源和任务所需要的资源进行动态分配。通过完整的分析Spark框架中任务执行过程以及资源调度分配的策略,可以根据任务运行数据提出资源调度分配优化模型,并针对调度资源优化提出了系统的解决方案[7]。
同时,目前已经有了较多技术文章针对数据倾斜问题提出了对应的优化策略。美团公司在技术文档中分享了如何利用Spark框架的调度机制处理具有数据倾斜特征的数据任务,可以对Spark任务增加分区数量或者对数据进行离散化操作,也可以利用广播变量将小数据集合分布到各个计算节点中。
此外针对Spark官网及Cloudera提供的任务调优方案上也有针对数据结构序列化、资源调度,以及任务运行时的参数设置的优化建议。
为此本文提出了针对具有不同的数据特性的数据源,进行代码的自动分析,尝试解决因数据倾斜带来的Spark任务运行的效率问题。
2 Spark数据倾斜问题
2.1 数据倾斜
数据倾斜意味着数据集合中不同属性的值出现的次数不是均匀分布的,在统计学中属于数据分配不均的问题。科学研究中的很多数据都是分布不均匀的。比如在天体物理学领域描述宇宙演化的数据集Millennium simulation,数据集中每个节点的质量分布如图1所示。超过75%的数值出现不超过十次,而出现频率最高的7个数值每一个的出现次数都超过了2 000万次[8]。
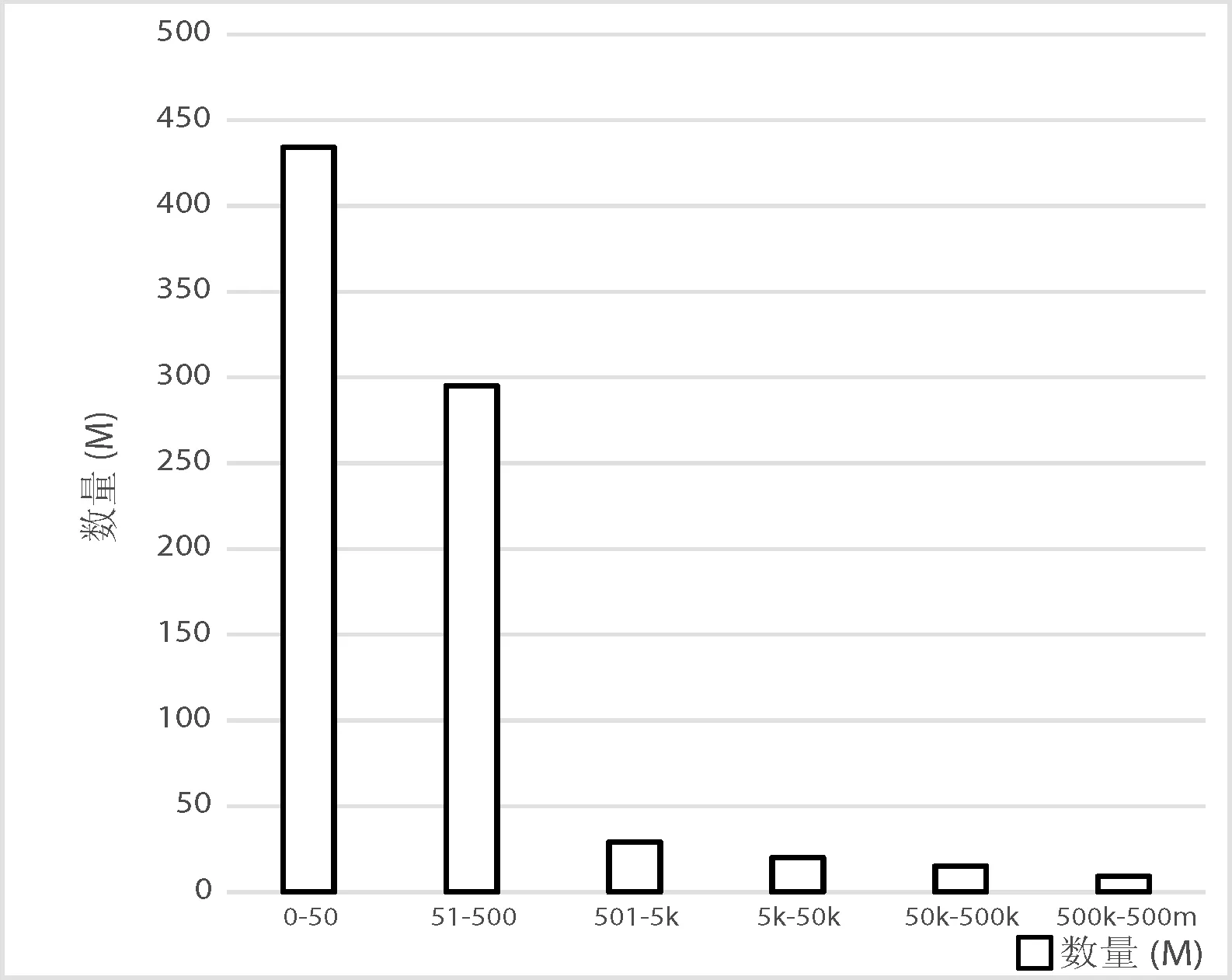
图1 数据集节点质量分布图
为了解释数据倾斜对Spark任务产生的影响。我们首基于MapReduce的高效粗糙集属性约简算法先以一个统计词频的例子介绍Spark框架的工作流程[9]。
在程序的map阶段,对输入的文章中的每一行执行map函数,并生成
因为Spark具有shuffle机制,所以在数据倾斜的情况下,shuffle操作将位于不同节点中具有相同key的大量的数据拉到同一个节点中执行reduce操作。而一个Spark 任务只能在一个partition中之行,所以某一些数据量异常巨大的key的任务运行时间就会非常缓慢。
以Word Count出现数据倾斜为例,在map阶段,每一篇文章都被划分为每个独立的单词,从而发现文中大量的单词都是hello,少部分的单词是world。在Shuffle阶段,我们需要将不同节点上具有相同key的键值对分配到相同的节点中。在Reduce阶段,有大量的带有单词hello的键值对被分配到了同一台机器上,而剩余的少量的world的key被分配到同一台机器。两个节点的机器配置和网络带宽都是相同的,但是其中一台机器处理的数据量是另一台机器的成百上千倍。整个任务的运行瓶颈就在执行reduce任务较多的节点上。当数据量上升到TB、PB级别时,就会出现运行时间长甚至内存不足的情况。
2.2 现有处理方法及问题
如何解决数据倾斜带来的问题,现有的方法是利用Spark本身的特性,缓解因为数据倾斜导致的分区不均的问题。根据3.1节的描述,数据倾斜的问题是出现在Spark任务处理的shuffle阶段,如果要处理数据倾斜的问题,我们可以在shuffle阶段进行优化。
优化的目标最终减少因为重新分配数据导致的某一个Reduce节点中数据过多的问题。处理方式有两种思路,第一种是通过增加任务处理分区数或者是按照Key的维度对数据进行离散化,尝试从shuffle阶段缓解数据倾斜的压力。第二种是利用Spark的广播变量的特性直接忽略shuffle阶段,从根本上解决数据倾斜的问题。具体的处理流程和分析在4.3节中介绍。
目前Spark将数据倾斜的优化策略交给程序员中利用代码手动完成,这就经常会导致程序运行的效率低下甚至产生程序报错。主要原因有:
(1) 程序员对数据特性本身不敏感,没有针对具有数据倾斜特性的Spark程序进行优化。
(2) 选择错误的优化方案。错误的优化策略会占用系统的额外内存和网络带宽。效果只会是适得其反,降低数据分析任务的性能。
随着项目复杂度和代码量的提高,优化策略的问题会变得越来越严重。如果可以使用自动分析的方法,自动根据数据的倾斜特性选择相应的代码优化策略,无疑会降低程序员的负担,避免上述的问题。下面将对这方面进行初步研究,通过分析与建模,目的对处理数据倾斜数据的spark任务进行智能优化,并加速任务的运行速度。
3 自适应数据倾斜优化方案
3.1 数据倾斜度
为了更好地衡量数据的倾斜程度,本文对数据集合中的数据分布的均匀程度进行了定义,提出了数据倾斜度的概念。数据倾斜度的计算借鉴了分类统计中的平均绝对偏差的概念,统计一个数据集合中每个Key出现的次数,然后计算每个观测值和算术平均值的偏差的绝对值的平均。同时为了对结果进行正则和标准划,我们引入了相对平均绝对偏差的计算方式,也就是用平均绝对偏差除以算数平均值。最后数据倾斜度的定义就取二分之一的相对平均绝对偏差[10]。如公式所示:
(1)
式中:G代表数据倾斜度,xi代表数据集合中每个key出现的次数。选取平均绝对偏差的作为计算数据倾斜度主要是考虑结果的通用性和高效性,在比较了多重分类统计中的度量之后,最终选择了绝对偏差方案。数据倾斜度G的范围在0~1之间,G越接近1表明数据的倾斜程度越大,G越接近0表明数据的分布平均。
3.2 有向无环图
为了对Spark代码进行静态分析,获取程序运行时中间数据的相互依赖,本文通过分析Spark程序运行时的日志信息,和各个中间数据之间的相互依赖及各项操作生成了一个有向无环图(DAG)。DAG代表了Spark代码的真正计算路径。
Spark任务 DAG 图上的每个节点表示一种 RDD类 型。在Spark代码中,程序员在RDD上定义了一系列操作。这些操作可以是map接着reduce,也可以是一系列的map和reduce的集合,都会被Spark记录下RDD之间的相互依赖,我们可以据此画出一张关于计算路径的有向无环图(DAG)。用DAG图可以从算法逻辑和数据规模大小两个方面来准确地刻画任务的特征。
为了便于理解,下面列出了统计词频任务的Spark代码。图2是任务对应的有向无环图。图的顶点(方框)表示系统中的数据类型RDD, 图的边代表不同操作之间的关系。图中表示的过程是首先读取文件,分别进行flatMap和map操作,然后再将map的结果执行reduceByKey的操作进行聚合,最后将结果输出到文件中。通过这样的DAG已经能够清楚地刻画任务执行的基本流程[11]。
1. val text_file = spark.textFile(″source_path″);
2. val word_count=text_file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b);
3. word_count.saveAsTextFile(′dest_path′)
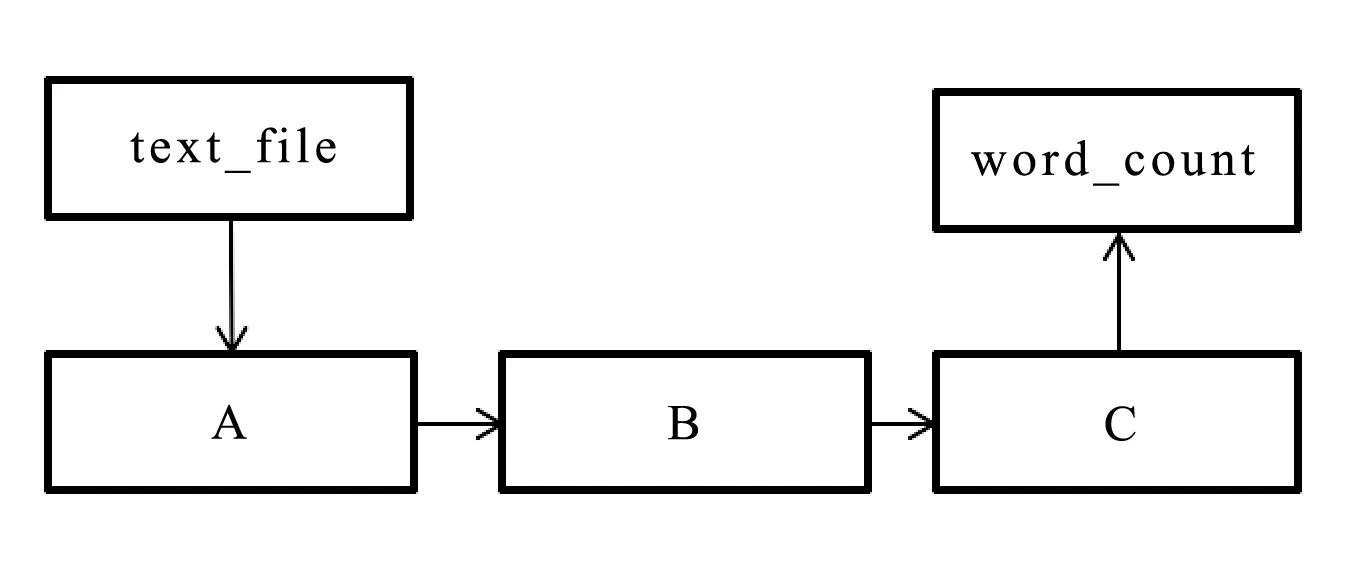
图2 统计词频任务的源代码和有向无环图
3.3 数据倾斜任务优化
首先我们把数据倾斜的任务分为两大类[12]:(1) 任务代码中直接调用Spark的Map-Reduce方法;(2) 任务代码中任务代码中调用更抽象的rdd.join(),再有Spark的解释器编编译成具体的Map-Reduce 任务代码。针对具体的任务分类,分别有不同的优化方案。
针对普通的Map-Reduce的任务,如果出现数据倾斜的情况,在执行reduce的任务时,不同节点执行的数据量的不同,导致了数据任务的迟缓。解决方案通常有两种思路。
1) 提高shuffle阶段任务的最大并行度,即Spark框架中对于用户设置的最大分区,具体的参数名字是 spark.sql.shuffle.partitions。Spark框架对该值的默认值是200,对于倾斜程度不同的数据处理任务需要动态的进行调整。如图3所示,增加分区数字之后,每个reduce节点执行的数据量变少,执行速度也更快。

图3 shuffle过程中增加分区数
2) 对shuffle阶段的
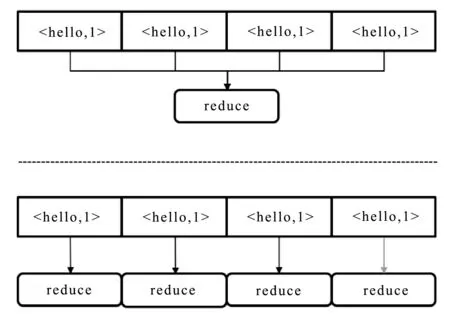
图4 shuffle过程中为key增加随机后缀
针对RDD之间需要Join的任务,如果出现数据倾斜的情况。也有如下两种处理方法:
1) 如果其中一个RDD数据量较小,使用广播变量方式减少shuffle阶段的数据交换。Spark允许程序员在不同机器之间缓存一个只读的变量,从而节省在不同的任务之间传递数据的消耗。这种变量被称为广播变量。广播变量的优势包括,利用一种高效的方式在每个集群节点上缓存一个大量的数据集合。同时,Spark也尝试利用高效的广播算法来分布式的广播变量,以期望降低数据交换的消耗,如图5所示。
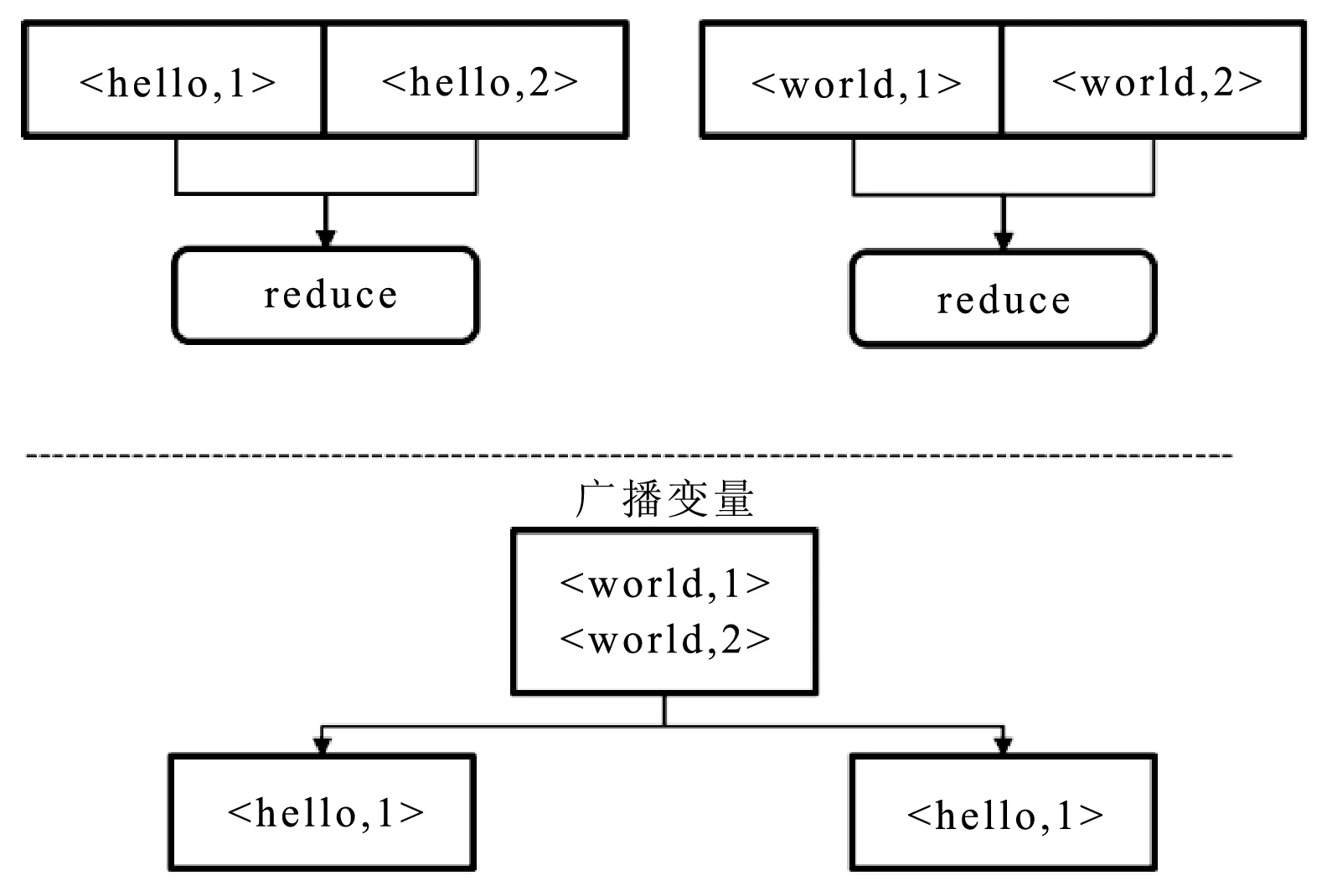
图5 将RDD转化为广播变量,避免shuffle过程
2) 分拆RDD。根据每个KEY的倾斜程度,将RDD分拆为倾斜的和分布均匀的两部分。可以将少数几个KEY导致的数据倾斜分拆出去,然后进行数据离散化操作,此时数据会分散到多个任务中执行。数据聚合操作之后,再使用Union方法将分拆的两个RDD进行合并。如图6所示。
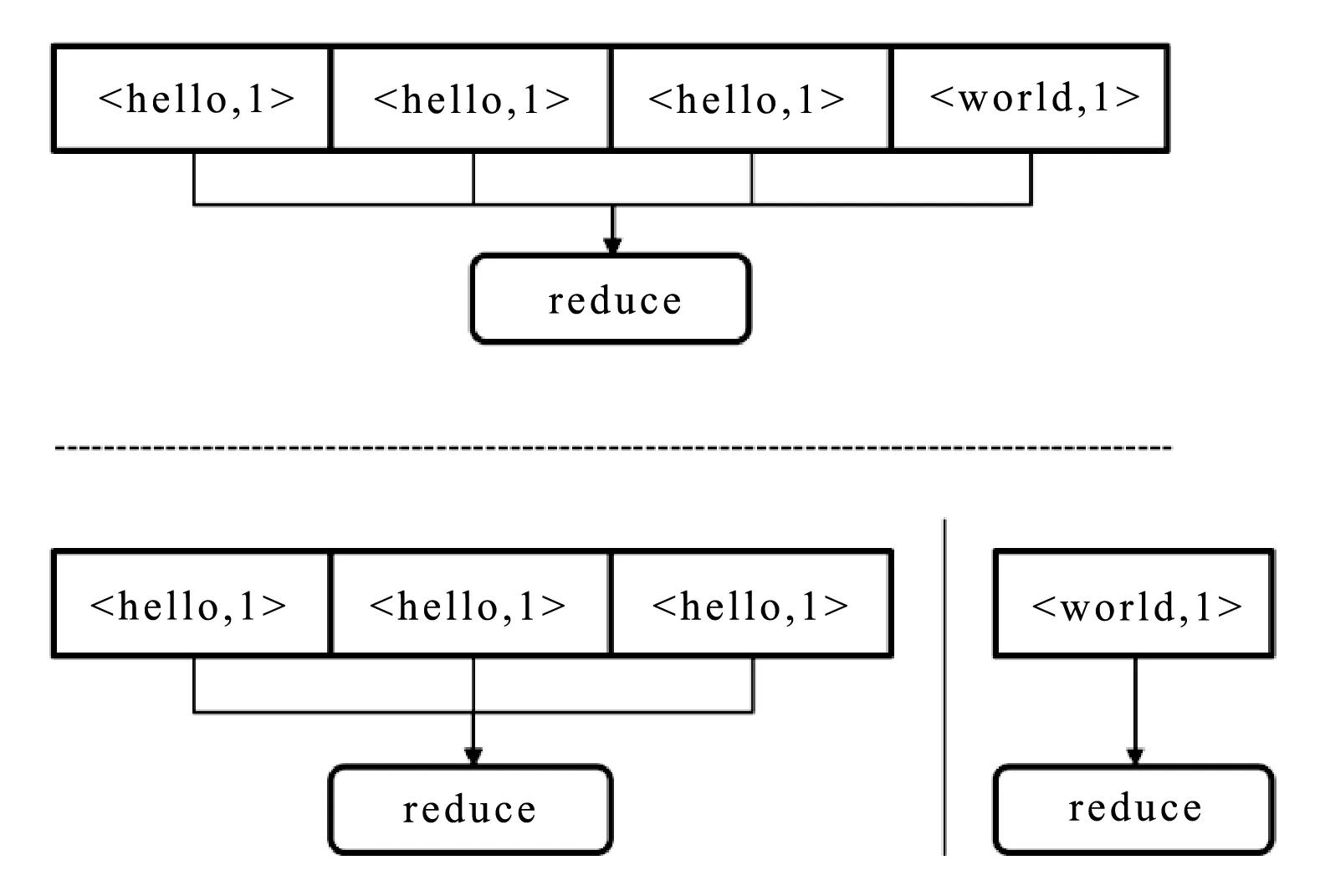
图6 根据key倾斜度将RDD分拆,reduce结束后再union
3.4 算法设计
针对Spark程序中经常出现的数据倾斜导致的运行效率的问题,通过程序的智能分析,针对数据倾斜的不同应用场景自动地对代码执行优化策略。针对策略的自动化,算法的实现思路如下:
(1) 分析Spark代码[13]。通过在Spark源码中植入监听代码,根据日志信息对数据结构RDD和相应的函数操作进行建模,即可以得到当前代码的有向无环图(DAG)。图中的每一个点都代表一个RDD,图中的每一个边都代表RDD执行的函数操作。
(2) 判断RDD是否出现数据倾斜。方法是对DAG图中的每一个点,也就是RDD依次进行采样分析,根据数据集合大小和数据分布计算出数据倾斜度,如果数据倾斜度大于一定的阈值则被判断为数据倾斜。
(3) 针对RDD的数据倾斜程度及RDD本身的数据场景,应用不同的代码优化策略。
本方法需要对代码执行两次。第一次是为了获取处于不同阶段的RDD,从中间分析出有数据倾斜的RDD。所以第一次运行的时候,可以在代码中对RDD进行数据采样,只运行少量的数据集合,这样在小数据集对代码和RDD进行分析,不会影响运行的性能。代码优化后,再进行代码的第二次运行。
方法的整体流程如图7所示。

图7 优化算法整体架构
下面是关于如何进行代码优化的具体操作:
(1) 增加随机后缀,并增加分区数。为数据集中分布不均匀的key分配一个随机的后缀或者前缀,力图将shuffle的key进行离散化,使数据的分布更加均匀。待每个新的key聚合完成以后,把添加的前缀或者后缀去掉,恢复成原本的key, 再重新计算一个reduce操作。
(2) 生成广播变量。针对两个RDD join的情况,将其中一个略小的RDD转化为broadcast对象,然后分发到执行任务的分布式集群的每个node中。最后在RDD的flatMapToPair的函数中利用map完成RDD之间的聚合操作。
(3) 分拆倾斜RDD。两个RDD Join,但是其中一个RDD存在数据倾斜的问题,我们对有数据倾斜的RDD进行随机前缀操作。对另一个RDD进行类似于数据膨胀的扩容操作。然后和第一种模式的流程一样,重新进行Map-Reduce操作。
4 实验验证
4.1 实验环境
实验采用的云计算集群是亚马逊公司的EMR(Elastic Map Reduce)集群。EMR是亚马逊公司提供的弹性Map-Reduce服务[13],服务内容包括用户可以自动配置分布式计算集群,集群上可以动态部署Hadoop、Hive、Spark等分布式计算框架,也可以动态部署Pig、Phoenix、Presto等分布式查询引擎,减少了数据开发人员大量的配置分布式开发环境的时间成本。同时,作为弹性分布式集群服务,用户可以按需求动态地启动集群服务,配置集群规模,提交数据分析任务,改善了整个数据分析流程的效率。同时,作为亚马逊的云服务,EMR可以使用亚马逊提供的其他云服务组件配合使用,比如分布式文件存储系统S3(Simple Storage Service)或者亚马逊EC2(Elastic Computer Cloud)[14]等。综上所述,EMR具有配置灵活,服务类型丰富,运维成本低等优势。因为,我们在实验中采用了亚马逊的EMR云服务作实验环境。
我们基于亚马逊的EMR服务分别进行了三组实验,使用的集群配置都是相同的。我们使用了20台节点配置的集群。配置如下:机器类型亚马逊EC2 m4.xlarge,4核CPU,16 GB内存,带宽450 Mbit/s。使用的软件及其版本为:EMR 4.7,Spark 2.1,Hadoop 1.7。
4.2 实验设计
实验目的是为了验证根据数据场景提出的代码优化策略是否可以减少程序的运行时间,优化任务运行效果。
为了保证数据集合和数据倾斜度的大小可控,实验采用了模拟数据。具体模拟方法是:针对每个数据集合的RDD大小以及数据倾斜度大小,采用扩充或者采样RDD的方式来控制数据集合大小,采用key分配随机前缀或者key进行归一化操作来控制数据倾斜度的大小。最终,利用现有的数据集合,我们就能模拟出合适的数据集合用于任务优化效率[16]的实验。
首先我们将任务优化效率定义为可量化的指标。通过对任务优化效率的分析,验证对于相同的数据分析任务,本文提出的方法是否可以自动选择数据场景并针对任务进行了优化,同时在运行效率上确实达到了任务优化的效果。
通过对比相同的Spark任务在算法优化前后的任务运行时间,我们对任务优化效率提出了定义。值得注意的是,在进行代码优化前后的运行时间对照实验的时候,针对优化后的程序运行时间,我们应当将第一部分试验中进行数据场景判断的时间也计算在内。也就是需要将数据场景判断所花费的时间和优化后程序的运行时间结合在一起才是优化方法的真正运行时间。关于任务优化效率如公式所示:
(2)
式中:E代表任务优化效率;ti表示优化前的任务运行时间;tj表示优化后的任务运行时间。针对相同的数据分析任务,通过优化前的任务运行时间减去优化后的运行时间,即得到总体任务的优化时间。再得到优化时间和优化前任务运行时间的比值,即是任务的优化效率。优化效率越接近于1,则表示优化效果越好。
针对任务优化效率的实验,本文设计了三种不同的任务优化实验。
第一个实验是为了验证在不同的数据场景下本文方法都能够达到一定的任务优化效率,缩短任务的运行时间。实验内容是针对三种不同的数据倾斜场景分别是用未优化的代码和优化后的代码进行数据分析,对比两个任务的运行时间,最后计算任务优化效率。同时,在实验过程中保证三种不同的场景下数据集合和数据倾斜度都保持相同。这里,数据集合的大小是10 GB,数据倾斜度是0.5。
第二个实验是为了验证在数据集合数据倾斜度相同的情况下,数据集合大小对任务运行时间和任务优化效率的影响。实验内容是在数据分析任务中采用的数据集合是数据集合大小不同但是数据倾斜程相同的数据,同样对比的是代码优化前后的程序运行时间。三组实验的数据集合大小都是100 GB。这里,所有数据集的数据倾斜度都是0.5,数据集合的大小从1 GB到1 TB不等。
第三个实验是为了验证在数据集合大小相同的情况下,数据倾斜程度对任务运行时间和任务优化效率的影响。实验内容是在数据分析任务中采用的数据集合是数据倾斜程度不同但是数据集大小相同的数据。同样对比的是代码优化前后的程序运行时间。这里,数据集合的大小都是100 GB,数据集合的数据倾斜度从0.1到0.9不等。
4.3 实验结果
第一个实验中,针对三种不同的数据场景,优化后的代码运行效率都要比优化前的代码片段有了不同程度的提升。实验结果如图8所示,横轴表示三种不同的数据场景,纵轴表示方法优化前后程序的运行时间,单位是分钟。横轴中每个数据场景对应两个柱状图,左边直方图代表优化前的任务运行时间,中间的直方图表示分析数据场景的时间,右侧的直方图表示优化后的任务运行时间。根据优化前后的任务运行时间以及任务运行效率的定义,可以计算出随机前缀、广播变量和分拆RDD的方法的优化效率分别提升了40%、47%和58%。从而证明本文方法对Spark数据倾斜任务具有一定的优化效果。同时,数据场景分析只占总体运行时间的小部分。因此可以得出结论,优化方法的前期数据采样工作对优化算法的运行效率没有影响。
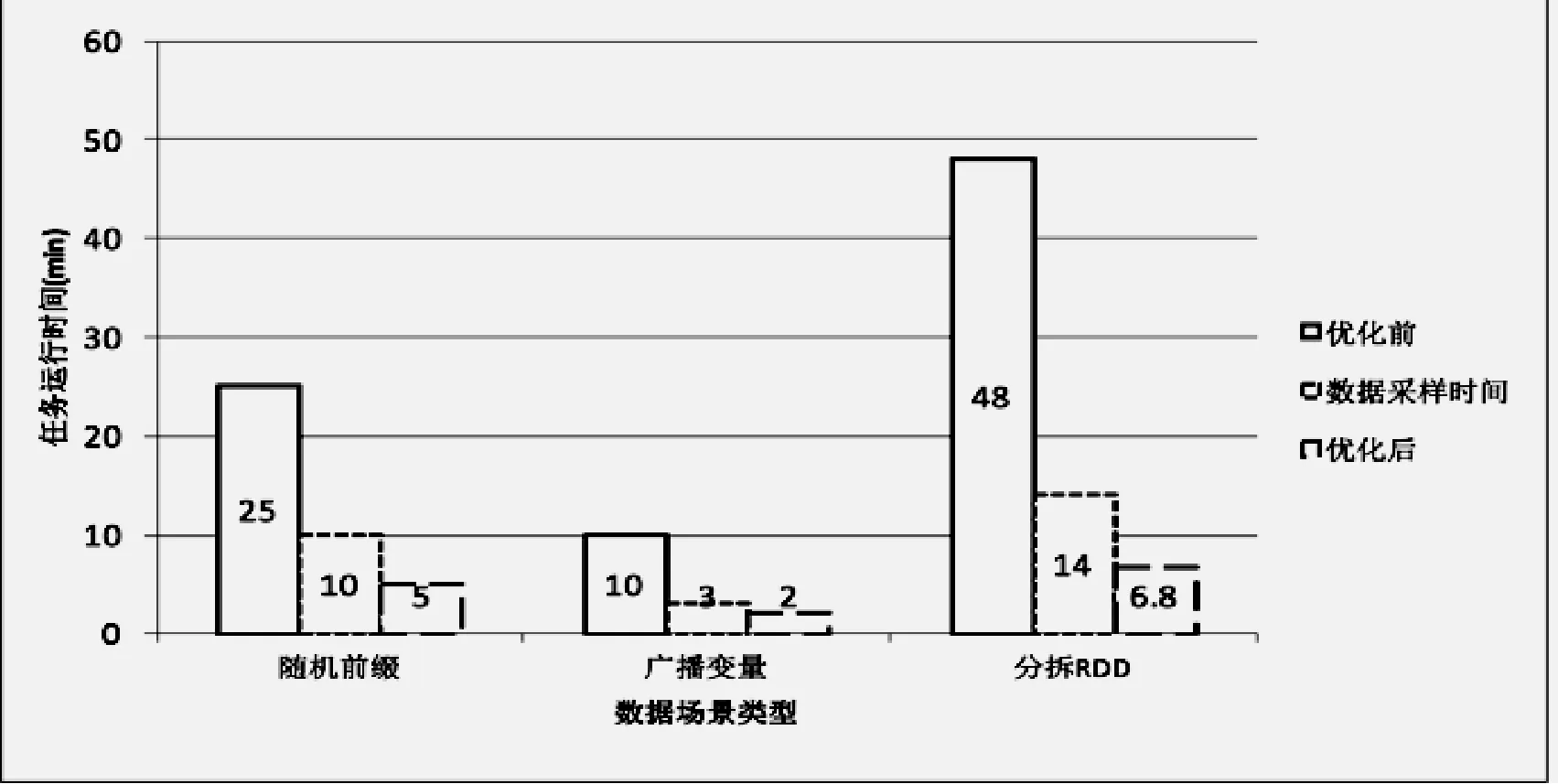
图8 不同数据场景下代码优化后运行效率有了大幅度提升
第二个实验,针对相同的数据倾斜度,在数据集合大小不同的情况下,对比本文方法的优化效率。其中图9是实验结果。其中X轴表示的是数据集合的大小,Y轴表示优化前后代码的优化效率。实验二的所有数据集的数据倾斜度都是0.5。实验结果表明,在数据倾斜度大小相等或者近似相等的情况下。优化后的代码相比优化前的代码,运行效率有了明显提升。同时,随着数据大小的增加,当数据集合达到100 GB以后,优化效率曲线开始保持平稳。
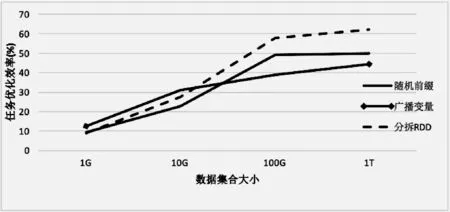
图9 实验结果
第三个实验是采用数据集大小相同但是数据倾斜程度不同的数据,同样对比的是优化前后的代码效率。三组实验的数据集合大小都是100 GB。图10是对应的结果。其中X轴表示的是数据倾斜度的变化,Y轴表示优化前后代码的优化效率。实验结果表明,在数据集合大小相等或者近似相等的情况下。优化后的代码相比较优化前的代码,运行效率有了大幅度提升。同时,随着数据倾斜度的增加,优化效率一直在不断提高。
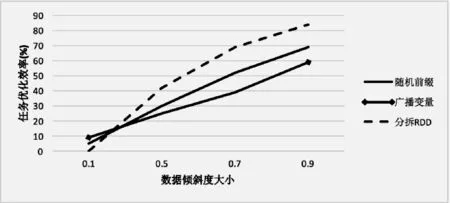
图10 随着数据倾斜程度增加,算法优化效率显著提升
5 结 语
场景选择代码优化策略。实验结果表明,这种调优方法具有一定的可行性。在接下来的研究中我们可以获取更多Spark运行时的数据,从调度策略和内存资源分配等不同的方向丰富数据模型,进一步提高算法的优化性能。
[1] Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[C]//Conference on Symposium on Opearting Systems Design & Implementation.DBLP,2004:137-150.
[2] 林海铭.基于Hadoop MapReduce的大规模线性有限元法并行实现[J].计算机应用与软件,2017,34(3):21-26.
[3] 倪丽萍,马驰宇,刘小军.社会化信息对股市波动影响分析—基于SparkR平台的实现[J].计算机应用与软件,2017,34(3):181-188,266.
[4] 余双双,曾一,刘慧君,等.基于UML模型的多态性与Java接口代码信息一致性检测的方法[J].计算机应用与软件,2017,34(2):8-13,47.
[5] 陈康,王彬,冯琳.Spark计算引擎的数据对象缓存优化研究[J].中兴通讯技术,2016,22(2):23-27.
[6] 陈侨安,李峰,曹越,等.基于运行数据分析的Spark任务参数优化[J].计算机工程与科学,2016,38(1):11-19.
[7] 韩海雯.MapReduce计算任务调度的资源配置优化研究[D].华南理工大学,2013.
[8] Gufler B,Augsten N,Reiser A,et al.Handling Data Skew in MapReduce[C]//Closer 2011-Proceedings of the,International Conference on Cloud Computing and Services Science,Noordwijkerhout,Netherlands,7-9 May.DBLP,2011:574-583.
[9] 李成,许胤龙,郭帆,等.基于MapReduce的内存并行Join算法研究[J].计算机应用与软件,2016,33(7):257-260,277.
[10] 裔传俊,刘亮.采用边缘分类和平均偏差比较的分形图像编码[J].计算机应用与软件,2015,32(2):211-214.
[11] 陈龙,苏厚勤.BPEL文档基于DAG自动生成框架的研究与实现[J].计算机应用与软件,2016,33(5):87-89,143.
[12] 李涛,刘斌.Spark平台下的高效Web文本分类系统的研究[J].计算机应用与软件,2016,33(11):33-36.
[13] 黄赛杰,陈铭松,金乃咏.一种基于约束求解的Verilog语言静态分析方法[J].计算机应用与软件,2015,32(12):1-3,87.
[14] Keshavjee K,Bosomworth J,Copen J,et al.Best Practices in EMR Implementation:A Systematic Review[J].AMIA.Annual Symposium proceedings/AMIA Symposium.AMIA Symposium,2006,2006(3):982.
[15] Simson L.Garfinkel.An Evaluation of Amazon’s Grid Computing Services:EC2,S3 and SQS[C]//Center for.2007.
[16] 程慧敏,李学俊,吴洋,等.云环境下基于多目标优化的科学工作流数据布局策略[J].计算机应用与软件,2017,34(3):1-6.
