高光谱目标表述的不均衡数据多示例学习方法
2018-02-23单嘉欣龚智强
单嘉欣,龚智强,钟 平
高光谱目标表述的不均衡数据多示例学习方法
单嘉欣,龚智强,钟 平
(国防科技大学电子科学学院,湖南 长沙 410073)
高光谱目标表述是高光谱目标检测中的核心问题。在众多高光谱目标表述方法中,多示例学习方法(MIL)由于不需要精确的像素级语义标签等因素,而成为研究高光谱目标表述的一个有效方法。但是,面向高光谱目标表述的多示例学习方法中,存在正包内目标示例远少于背景示例的示例级数据不均衡问题,导致学习到的目标表述性能不佳。为此,提出一种面向不均衡数据的多示例学习方法,提取每个包中最可能为正的示例组成正示例集,以此为基础合成新的正样本,增加正样本在正包中所占比例,改善高光谱目标表述能力。在真实高光谱数据上验证所提方法的有效性,结果表明该方法使正包样本组成更均衡,从而学习到更正确的目标表述,提高目标检测的性能。
高光谱;目标表述;多示例学习;不均衡
高光谱遥感图像目标检测在军事和民用领域中都有广阔的应用前景,是当前遥感信息处理研究中的一个热点问题。高光谱遥感目标检测主要利用目标与背景地物在光谱特性上的差异来进行检测识别。高光谱图像立方体数据具有高光谱分辨率、图谱合一的观测特性,数据中每个像元通过高分辨率光谱曲线表示[1],该像元光谱曲线包含目标的诊断性光谱特征,可用于目标的谱识别。然而,由于高光谱遥感图像的空间分辨率一般不是很高,有些目标在图像中可能只占一个像元甚至是亚像元。由于可利用的信息相对有限,检测这种亚像素目标是高光谱图像分析中的一个极具挑战性的任务。目前针对亚像素目标的检测方法,多数需要目标的表述光谱[2]。常见的目标表述方法包括实验室测定、手持光谱测量仪测量、直接从高光谱图像中获取。这些常见的目标表述方法应用到实际任务中存在以下难点[2]:①实验室和手持光谱仪测定的目标光谱曲线不能考虑大气等因素对成像的影响,与实际应用场景中的目标光谱曲线差异大;②结合现场标定和高光谱图像获取的目标表述,由于现有测量条件(如GPS)的定位精确度有限,不能精确获得目标的像素级语义标签,从而不能精确地从图像中提取出目标的表述光谱曲线;③通过手动从图像中选取目标的表述,也因为肉眼很难辨认出处于亚像素级的目标而无法得到良好的目标表述光谱。
近年来出现的多示例学习方法,只需要包级的训练样本,不需要精确的示例(像素)级标记样本。因此可以解决上述常见目标表述方法面临的问题。在多示例学习方法中,训练样本是一个个由多个示例组成的包,按照包中有无目标示例分为正包和负包。包中只要有一个目标示例,则该包为正包;包中若全部为非目标示例,则该包为负包[3]。不精确标签中估计目标类概念的多示例学习方法称为多示例概念学习(multiple instance concept learning,MICL)方法[2]。文献[4]提出的多样性密度(diversity density,DD)算法是第一个用于多示例学习的概率模型,本文方法则以该算法为基础。
DD算法寻找属性空间中多样性密度最大的点作为最佳正目标点。多样性密度最大的点应尽可能的与更多的正包距离相近,与更多的负包距离相远。多样性密度的一般定义为
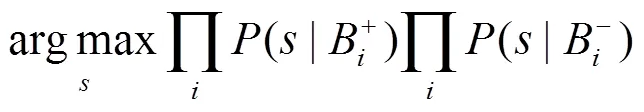
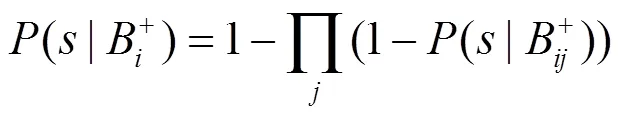

其中,(|B)为点B和目标点的亲近度估计,即一个示例为正的概率;相应地,1–(|B)为一个示例为负的概率。此外还有多样性密度算法与期望最大化方法结合形成的EM-DD算法[5]、基于字典的多示例学习方法[6-7]、多示例学习拓展函数[8-9]等多示例概念学习方法。
多示例学习用于高光谱图像目标表述的优势在于:①多示例学习的输入为实际的高光谱图像,可以在学习到的高光谱目标表述中充分考虑各种成像条件,解决通过实验室测定和手持光谱仪测定的目标光谱曲线与实际应用场景中目标光谱曲线差异大的问题;②多示例学习方法引入包的概念,将包作为训练数据,不需要示例级的目标语义标记,因此可以解决常见从图像中获取目标表述面临的不精确定位和不能分辨亚像素目标的问题。
基于多示例学习,一种实际可行的目标表述工作流程为:首先人工选定可能包含表述目标的图像块作为正包,然后选择若干确定不含目标的图像块作为负包,最后通过多示例学习方法得到目标的表述。这种工作流程中,由于考虑的目标可能尺寸很小,甚至是子像素目标,导致正包中目标示例较少,而大多是背景(负)样本,使多示例学习面临训练数据不均衡问题。针对传统的单示例学习方法面临的不均衡问题,已经提出很多解决方法[10];针对多示例分类学习方法面临的数据不均衡问题,有少量相关研究[11]。但在面向高光谱目标表述的多示例学习方法的数据不均衡问题上,仍缺乏相关解决方案。
本文在高光谱目标表述的多示例学习方法的基础上,提出示例级不均衡问题的解决方案,即不均衡数据多示例学习方法。通过为正包合成新的正示例,增大正示例在正包中所占比例,使得正包中正负样本均衡,从而改善高光谱目标表述能力,提高高光谱目标检测性能。本文在MUUFL Gulfport实测高光谱数据集的实验结果表明,该方法能均衡正负样本,并学习到性能优异的目标表述,进而改善检测性能。
1 不均衡数据多示例目标表述
1.1 不均衡数据多示例高光谱目标表述流程
本文提出的不均衡多示例高光谱目标表述工作流程如图1所示,首先专家从训练高光谱数据中提取出正包和负包样本;然后估计每个正包中最可能为正的示例,为每个正包合成新的正样本,将新的正样本分别加入相应正包中;再应用多示例学习方法对新组成的样本数据学习目标表述;最后将目标的表述光谱和对应的检测器对测试数据进行目标检测,所得结果经专家判断,若符合预期目标,则将得到该结果的目标表述光谱存入目标光谱数据集中。这种人机交互的不均衡数据多示例高光谱目标表述方法的优势在于:①可以创建特定场景下的目标表述光谱数据集;②可以学习到针对特定检测器检测性能最优的目标表述;③应用不均衡数据算法改善正包中正负样本不均衡问题。下面分别介绍本文提出的不均衡数据多示例学习目标表述方法中最重要的两个步骤:多示例目标表述和均衡数据方法。
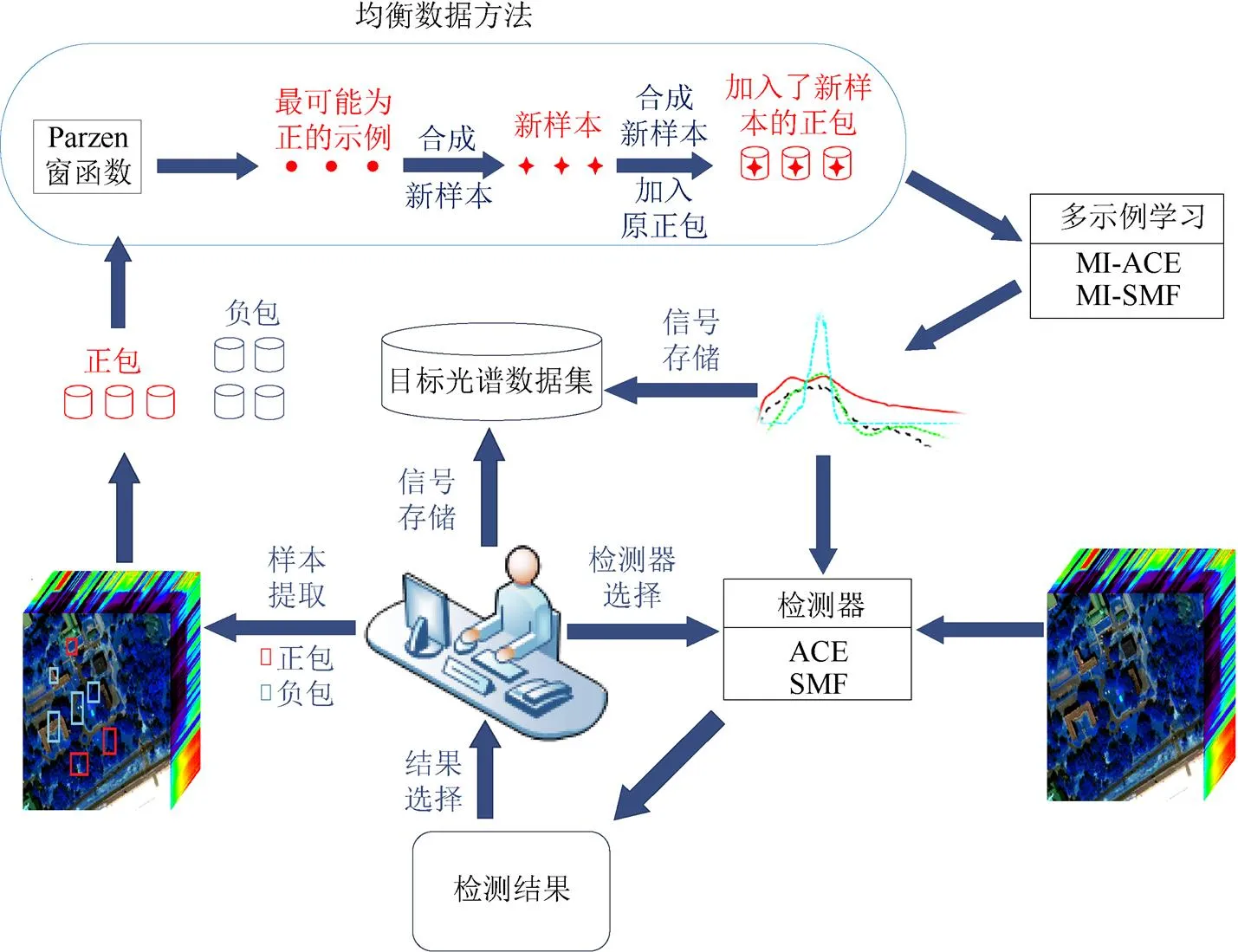
图1 不均衡多示例高光谱目标表述人机交互流程
1.2 多示例目标表述
本文主要采用最近针对光谱匹配滤波器(spectral matched filter,SMF)和自适应余弦估计器(adaptive cosine estimator,ACE)提出的多示例高光谱目标表述方法,即MI-ACE和MI-SMF算法[2]。与多样性密度算法相似,MI-ACE和MI-SMF都是估计目标概念的方法,但其不是用欧式距离来测量示例和所估计目标概念间的相似性,而是使用了余弦相似度,余弦相似度在目标特征为亚像素的情况下更具鲁棒性[2]。此外,该方法结合相应的高光谱目标检测器对目标进行表述,针对不同检测器的不同特点得到最适用于相应检测器的目标表述。
目标检测问题通常转化为假设检验问题来处理,然后通过广义似然比测试法[12]设计检测器。本文采用的SMF检测器表示为

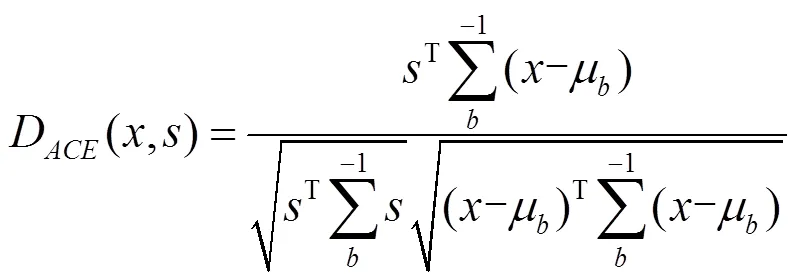



1.3 均衡数据方法
本文从高光谱数据预处理角度,提出一种基于数据过采样的不均衡数据多示例学习方法。其核心思想为:首先应用Parzen窗函数法求得正包中每个示例为正的概率,将每个包中最可能为正的示例取出组成一个正示例集;然后以此正示例集为基础合成新的正样本,并将新的正样本分别加入原有正包中形成新的正包,从而增大正包中正样本所占比例,改善由于数据不均衡而导致的高光谱目标表述不准确问题,进而提高光谱目标检测性能。均衡数据算法流程具体为:

1.3.1 Parzen窗函数法
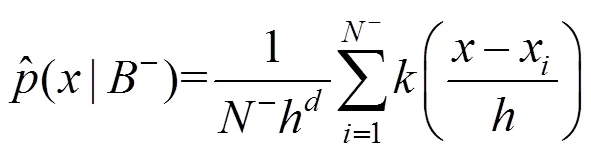
1.3.2 新样本合成
在求出正包中每个示例为正样本的概率后,可以通过式(9)找到正包中最有可能为正样本的示例


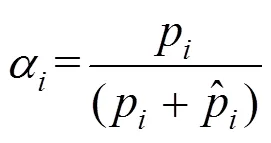
2 实验结果与分析
2.1 实验设置
本文实验选择的数据是MUUFL Gulfport高光谱数据集[13-14]。数据集测试地点为美国密西西比大学格尔夫波特校区。由于数据测试区域很多目标被遮挡、数据目标大小不一且含有大量亚像素目标,所以选择该数据集做高光谱目标表述与检测极具挑战性和代表性。高光谱图像包括325×337个像素,共有72个波段,波长范围为367.7~1043.4 nm且光谱样本间隔为9.5~9.6 nm,空间分辨率为1 m。数据库包含在两个不同时间段拍摄的两套高光谱图像数据(Gulfport Campus Flight1和Gulfport Campus Flight3)。拍摄区域RGB图像如图2所示。数据库的前4个波段和后4个波段作为噪声被去除。实验中的目标是4种不同颜色的布块,共放置了64个人造目标,其中棕色目标、黑绿色目标、淡绿色目标各15个,伪造件绿色目标12个,本文取前3种颜色的目标进行实验。数据集中的目标大小多种多样,区域中包含0.25 m2、1 m2、9 m2的目标,且处于亚像素级的0.25 m2目标数量最多。由于用于记录地表位置的GPS设备精确度为5 m,本文以所选3种颜色的每个目标为中心扩充大小为5×5的矩形正包。选取全部非目标样本为一个负包。实验采用normalized area under the receive operating characteristic curve (NAUC)衡量目标检测性能(间接衡量目标表述方法的性能),其中区域被归一化为1×10–3flase alarm/m2的虚警率(false alarm rate,FAR)。NAUC值为1对应于零误报率,即100%检测率。

图2 MUUFL Gulfport高光谱数据集RGB图像
2.2 实验结果分析
2.2.1 固定权值0.5
第一个实验中取权值为固定值0.5,通过式(10)均衡数据后的实验结果与原算法[15](不均衡数据)实验结果对比见表1 (效果好的数据已加粗)。

表1 本文方法同原始方法的NAUC值对比(固定权值0.5)
实验首先针对大小为0.25 m2、1 m2、9 m2的目标分别进行样本扩充,测试算法应用于不同大小目标的改进效果,结果表明:在棕色类型目标的测试中,大小为0.25 m2的亚像素级目标检测效果提升最大,MI-SMF算法检测率提高13%左右,MI-ACE算法从最初几乎无法检测,到合成样本后NAUC达到0.64。但黑绿色和淡绿色目标由于被遮挡较多等因素,未能有明显改善;大小为1 m2的全像素级目标的测试中,3种目标性能提升均很明显,其中棕色目标效果最佳,MI-SMF算法的NAUC从0.661提高到0.705,MI-ACE算法从0.098提高到0.704,其余两种目标也均有明显性能提高。以上两种情况说明合成的新样本有效,且通过提高正示例所占比例,亚像素级和大小为1 m2的像素级目标的检测效果明显增强。但大小为9 m2的目标实验中检测效果无显著变化,这是因为目标尺寸较大,本身在正包中占有较大比例,数据不均衡问题不明显。
进一步测试了提出的方法对不同尺寸目标组合训练样本的性能。首先同时选取大小为0.25 m2和1 m2的小目标进行测试,3种目标效果都较好;考虑到人工选取目标时一般只能看到像素级以上目标,同时选取大小为1 m2和9 m2的目标进行试验,由于含有的9 m2目标本身检测效果较好,该情况合成新样本没有使得检测效果有显著增强;最后选取大小为0.25 m2、1 m2和9 m2的目标进行测试时,棕色和黑绿色目标检测效果有5%左右的提升,这是因为棕色目标中含有的亚像素级目标使得合成新样本有效,黑绿色目标中大于亚像素级的目标未被完全遮挡使得合成新样本有效。淡绿色目标检测效果同原始多示例学习方法相似,这是由于淡绿色不同大小目标均被遮挡较多导致的,同本文理论分析一致。
图3所示为表1所示棕色目标6组实验的ROC曲线图,曲线下方面积值即为效果评估所用的NAUC值,其中MI-SMF/ACE-0代表不均衡数据的ROC曲线,MI-SMF/ACE-1代表均衡数据的ROC曲线,NAUC值相应标示在图中。由ROC曲线图可以看出,当目标大小为亚像素级和1 m2的单像素级时,通过合成新示例可使目标表述能力显著增强,目标检测效果显著提升;而当目标较大且跨越多个像素时,即使不合成新示例目标表述效果也较好,通过合成新示例没有明显提高目标表述能力,也没能明显提升目标检测效果。

图3 提出方法同原始方法的ROC曲线
2.2.2 自适应权值
第二个实验中取权值为自适应值,权值通过公式(11)计算得到,通过公式(10)均衡数据后的实验结果与原算法[15](不均衡数据)实验结果对比见表2 (效果好的数据已加粗)。

表2 本文方法同原始方法的NAUC值对比(自适应权值)
结合表1~2结果可知,自适应权值在多数情况下与固定权值的实验效果类似,少部分情况下自适应权值的实验效果略差,这可能是因为理论上选取的最可能为正的示例与实际正示例有偏差导致的,但自适应权值的方法在理论上更具容错性,在理论上和普适性上都更有价值。
综上,针对尺寸较大的目标,本文算法取得同原始方法相似的性能;针对大小为1个像素以及亚像素的目标,本文通过合成少数类样本,增大正包中正示例数量,可以显著提高目标表述效果,进而显著提高亚像素级高光谱目标检测性能。
3 结束语
本文从面向高光谱目标表述的多示例学习方法出发,提出了不均衡数据多示例学习方法。通过合成少数类样本来增加正包中正示例占所有示例的比重,解决多示例学习方法中示例级数据不均衡问题。真实数据上的实验结果表明,针对小目标尤其是亚像素级目标的高光谱表述,本文提出算法能够显著提高目标表述和检测的性能。
此外,多示例学习方法中,当正包数过少,负包数过多时,会出现包不均衡问题,今后将对多示例高光谱目标表述中的包不均衡问题做进一步研究。
[1] MANOLAKIS D, MARDEN D, SHAW G A. Hyperspectral image processing for automatic target detection applications [J]. Lincoln Laboratory Journal, 2003, 14(1): 79-116.
[2] ZARE A, JIAO C Z, GLENN T. Discriminative multiple instance hyperspectral target characterization [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018, 40(10): 2342-2354.
[3] DIETTERICH T G, LATHROP R H, LOZANO-PÉREZ T. Solving the multiple instance problem with axis-parallel rectangles [J]. Artificial Intelligence, 1997, 89(1-2): 31-71.
[4] MARON O, LOZANO-PÉREZ T. A framework for multiple-instance learning [C]//NIPS’97 Proceedings of the 1997 Conference on Advances in Neural Information Processing Systems.Cambridge: MIT Press, 1998: 570-576.
[5] ZHANG Q, GOLDMAN S A. EM-DD: an improved multiple-instance learning technique [C]//International Conference on Neural Information Processing Systems, Cambridge: MIT Press, 2001: 1073-1080.
[6] SHRIVASTAVA A, PILLAI J K, PATEL V M, et al. Dictionary-based multiple instance learning [C]//IEEE International Conference on Image Processing. New York: IEEE Press, 2015: 160-164.
[7] SHRIVASTAVA A, PATEL V M, PILLAI J K, et al. Generalized dictionaries for multiple instance learning [J]. International Journal of Computer Vision, 2015, 114(2-3): 288-305.
[8] ZARE A, GADER P. Pattern recognition using functions of multiple instances [C]//2010 20th International Conference on Pattern Recognition. New York: IEEE Press, 2010: 1092-1095.
[9] ZARE A, GADER P, BOLTON J, et al. Sub-pixel target spectra estimation and detection using functions of multiple instances [C]//2011 3rd Worshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing. New York: IEEE Press, 2011: 1-4.
[10] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique [J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-357.
[11] MERA C, OROZEO-ALZATE M, BRANCH J. Improving representation of the positive class in imbalanced multiple-instance-learning [C]// International Conference Image Analysis and Recognition. Berlin: Springer International Publishing, 2014: 266-273.
[12] KELLY E J. An adaptive detection algorithm [J]. IEEE Transactions on Aerospace & Electronic Systems, 2007, AES-22(2): 115-127.
[13] GADER P, ZARE A, CLOSE R, et al. MUUFL gulfport hyperspectral and LiDAR airborne data set. [EB/OL]. (2013-10-27) [2018-03-10]. http://engineers.missouri. edu/zarea/2013/10/muufl-gulfport-hyperspectral-and-lidar-data-collection/.
[14] DU X X, ZARE A. Scene label ground truth map for MUUFL gulfport data set [EB/OL]. (2017-04-17) [2018-03-11]. http://ufdc.ufl.edu/IR00009711/00001.
[15] GLENN T, ZARE A, GADER P. Bullwinkle: scoring code for sub-pixel targets [EB/OL]. (2016-05-21) [2018-03-11]. https://github.com/GatorSense/MUUFL Gulfport/.
Multiple Instance-Based Learning Method for Imbalanced Data in Hyperspectral Target Representation
SHAN Jiaxin, GONG Zhiqiang, ZHONG Ping
(College of Electrical Science and Engineering, National University of Defense Technology, Changsha Hunan 410073, China)
Target representation is the key process for hyperspectral target detection. Many methods have been proposed for better target representation. Among these methods, multiple instance-based learning method (MIL) is an effective one as it does not require pixel-level semantic labels. However, traditional MIL-based hyperspectral target representation methods usually cause the instance-level data imbalance because of the limited target instances and too many background instances in positive bags, leading to poor performance on hyperspectral target representation. To overcome this problem, a data imbalanced multiple instance learning-based method is proposed in this paper. First, a positive sample set with the most probably positive sample in each package will be constructed; then, new positive samples will be synthetized to increase the proportion of positive samples in the positive packages, balancing the positive and negative samples in positive packages, improving the representational ability. Experiments over real-world hyperspectral dataset validate the effectiveness of the proposed method and the experiment results show that the proposed method can enforce the balance of the positive packages and learn target representation more accurately which improves the target detection performance.
hyperspectral; target representation; multiple instance learning; imbalance
TP 391
10.11996/JG.j.2095-302X.2018061028
A
2095-302X(2018)06-1028-08
2018-04-16;
2018-06-14
国家自然科学基金项目(61671456)
单嘉欣(1995-),女,黑龙江哈尔滨人,硕士研究生。主要研究方向为图形与图像处理技术。E-mail:shanjiaxin123@126.com
钟 平(1970-),男,四川内江人,副教授,博士。主要研究方向为图形与图像处理技术。E-mail:zhongping@nudt.deu.cn
