以员工思想动态预测模型助推思想政治工作
2018-02-20文/吕坚梁樑林童
文 /吕 坚 梁 樑 林 童
利用当下最为流行的机器学习中的支持向量机算法(support vector machine, SVM),建立心理状态、心理风险和积极心理品质三个方面的预测模型,从不同的角度反映个体思想状况的积极、风险以及风险耐受性(自我调节性),能够有效分辨出高中低三个水平的心理状态和积极心理品质的人群,同时能够区分出高心理风险与低心理风险的人群。
研究背景
当前,人的思想活动的独立性、选择性、多变性和差异性进一步增强,导致思想政治工作面临许多新情况、新矛盾和新挑战。为更全面掌握基层员工的心理特点、工作感受及组织态度等动态,切实了解员工所思所想,国网浙江公司深入剖析当前员工思想动态分析工作中存在的不足,及时发现问题并提出具有价值的意见和建议,以进一步加强员工思想政治教育,增强员工关爱政策的针对性,进而为公司管理决策提供依据和参考。通过多范围、多层级地采集员工思想动态方面的数据,并借助大数据技术,架构全新的、符合新形势要求的思想动态分析模型,通过指数化分析及预警,创新了思想工作。
研究目标和方法
研究目标
实现科学有效地监测员工的心理状态、心理风险和积极心理品质(心理耐受、调整能力);依据测量结果更有针对性地开展工作,改善员工的心理健康,提高其生活质量和工作效率;让员工的思想状况保持良好水平,切实增强组织的绩效表现,提升组织的工作成效。
研究方法
行为数据测量。行为数据包含受测者所有活动足迹的数据资料,能够全面、实时、真实地记录全部数据,信息量丰富,有利于后期的数据挖掘和分析。这一技术不仅实现了对研究变量的在线测量,而且避免了传统方法中数据收集工作耗时费力的缺陷,可在大规模施测的同时无干扰地记录被试者的真实行为。
机器学习算法。心理测评领域亟需一种有效的数据分析方法来处理这些问题,以实现对个体能力和特质更为准确的评估。研究发现机器学习的不同算法均能够较为准确地识别情绪(快乐、中性、愤怒)。同时基于行为数据测量的优势,机器学习技术可以在这类研究中体现出独特的优势,能够通过充分利用行为数据信息,建立较为复杂的模型,实现更准确的预测。
研究过程
采用机器学习的模式对员工思想状况监测的预测模型进行科学和系统研究,通过收集的变量去建立心理状态、积极心理品质以及心理风险的预测模型,利用机器学习最常用的监督学习算法中的随机森林(Random Forest, RF)、支持向量机(Support Vector Machine, SVM)和朴素贝叶斯(Naive Bayesian Model,NBM)算法,利用R stido进行数据清理、统计分析与模型搭建。这三种算法经过前人验证,已经证明是最好的三种机器学习的分类算法,其中随机森林和支持向量机算法尤为出色(Cernadas, E., & Amorim, D,2014)。最后经过模型比对,选择了更为优秀的支持向量机作为我们最终使用的算法。研究具体过程包括数据采集、数据集清理、模型建设与验证三个核心步骤。
数据采集。本次研究主要使用了问卷收集的方式,对国网浙江省电力公司1 429名员工进行数据收集,排除疑似无效作答的作答者340人,最后有效作答数据为1 089份(男性729人,女性360人),年龄范围在21岁~57岁之间。问卷包含传统专业心理学问卷(如:大五人格、心理资本量表、心理健康连续量表、抑郁量表)以及员工生活行为的问题(人口学变量、生活、情感、家庭、工作、行为等)。问卷一共包含155个题,题目类型都为选择题,分为单选题和多选题两种。
数据集清理。在做机器学习之前最重要的工作是清理我们的数据集,对整个数据集的被试和预测变量进行严密的筛查,为的是能够提高最后的预测效果,并在此基础上进行数据分析。数据集清理主要包括无效数据清洗和变量处理两项内容,其整体概览图如图1所示。
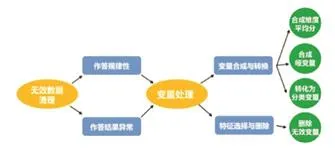
图1 数据集清理过程概览
模型训练与验证。清理好数据之后,我们就开始进行机器学习的模型建立,即模型的训练和验证,其机器学习流程图及部分机器学习计算机语言如图2所示。
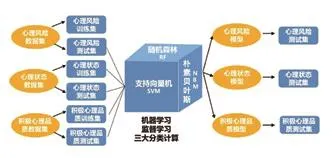
图2 机器学习流程图
对比随机森林(Random Forest, RF)、支持向量机(Support Vector Machine, SVM)和朴素贝叶斯(Naive Bayesian Model,NBM)算法,发现支持向量机的预测效果最好,最后使用支持向量机作为预测建模算法。
首先把样本分为80%的训练集(用做模型训练,得到最终模型)以及20%的测试集(用做模型效果的验证)。
支持向量机中有三个非常重要的超参数会对模型产生影响
核函数(kernel):有4个可选核函数,分别为线性核函数(linear)、多项式核函数(polynomial)、径向基核函数(radial basis)以及神经网络核函数(sigmoid)。识别率最高、性能最好的是径向基核函数,其次是多项式核函数,而最差的是神经网络核函数。
Cost超参数:允许支持向量存在软决策边界的惩罚项的系数,C越大表明越允许交叉项存在,但是容易发生过拟合。
Gama超参数:核函数一种的一个调和参数,目的也是为了避免发生过拟合。
在选择核函数和两个超参数的时候,需要不断地尝试最终达到最好的模型效果。
研究结果
超参数选择
通过穷举法搜索Cost和gama参数的值,使他们两个出现一个最优的搭配,当gama=0.01,C=10的时候模型能够得到最优的预测效果。
基础推荐模型变量选择
心理状态模型中基础推荐出46个变量,心理风险模型基础推荐出18个变量,积极心理品质模型基础推荐出25个变量。
模型预测结果
最终选择使用机器学的SVM算法进行建模。模型预测准确率良好,能够分辨出高中低三个水平的积极心理品质和心理状态的人群,同时也能够区分出高心理风险与低心理风险的人群。
模型应用
针对性地开发国网浙江省电力公司员工思想状况预测模型的分类器,包括心理状态、心理风险和积极心理品质三个分类器。通过该分类器,收集员工在本研究中所涉及到的预测自变量信息,利用计算机系统对模型分类器进行调用,即可自动化预测得到员工在心理状态、心理风险以及积极心理品质三个方面的思想状况水平,如图3所示。
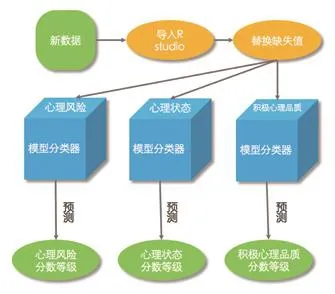
图3模型分类器使用流程图
研究结论
此次研究结果显示,员工心理状态、心理风险及积极心理品质模型预测准确率均超过7成,表明其已经达到了比较好的效果,也说明了通过员工行为数据对员工的思想状况进行预测是可行的,体现了我们此项研究工作的初步成果。我们同时也需要注意,在今后的工作中,在此模型的优化方面仍有改进空间,结合理论与经验,优化数据收集方式、优化变量的选取,逐渐对模型进行迭代升级,以使这项工作的整体效果不断优化。
