皇帝柑分类系统的目标提取
2018-02-13邹小林
邹小林
(肇庆学院数学与统计学院,广东肇庆 526061)
1993年,我国水果产量跃居世界第一。2010年,我国水果总产量约占世界总产量的30%[1]。然而我国水果在售价只有国际平均售价一半的情况下,水果出口量却不足产量的5%[1],原因是国内水果在采摘后,进行处理的技术偏低[2],没有根据水果的形状、大小、色泽等进行检测和分类。因此销售水果前,应对水果进行等级分拣。为了减少分拣过程中的工人工作时间和工人的经验技术限制等,基于图像处理[3]的计算机分拣技术是实现水果等级分类的有效方法。该方法的关键步骤是提取水果图像中的目标。蔡健荣等分别采用色差分量、邻差和、支持向量机、对数相似度约束等理论结合Otsu阈值算法分割水果图像[4-10]。黄辰等采用改进的3层Canny边缘检测算法提取苹果轮廓[11]。Deb等提出一种新的框架检测并删除图像的阴影[12]。皇帝柑是由于特殊原因形成的一种柑橘品种,因被唐宋明清这些朝代列为朝廷贡品而得名[13]。关于柑橘的图像分割与识别的研究主要如下:蔡建荣等采用色差分量结合Otsu阈值算法分割图像,再对分割结果进行处理[4]。周志宇等利用Otsu方法计算canny算子的高低阈值,从而实现柑橘边缘的自动检测[14-15]。廉世彬等采用多项式函数对图像的亮度进行转换,再2次使用Otsu算法分割图像获得图像的阴影区域[16]。本研究针对含有高光、阴影和叶片的皇帝柑图像提出了融合去除阴影和高光的谱聚类阈值图像分割算法。
1 高光去除
光源照射到物体表面的光被反射到人眼时,物体上最亮的那个点称为高光。当光线照射到非均匀物质表面时,一部分光反射到物体表面与空气之间的界面上,称为镜面反射或高光。图像的高光点表示具有最高亮度值的图像区域。皇帝柑图像的高光改变了皇帝柑的本色,须要去除皇帝柑图像中的高光,作为图像分割的预处理步骤之一。
Gòrny先把图像从RGB(红、绿、蓝)颜色空间转换为YUV(Y表示明亮度,U表示色度,V表示浓度)颜色空间,再对亮度通道Y进行归一化、均衡化处理和多项式函数转换[17]。廉世彬等提出的去除高光的算法步骤[16]具体为:
(1)将图像读入R、G、B3个通道。(2)将图像从RGB颜色空间转换为YUV颜色空间。(3)对亮度通道Y进行归一化处理。(4)对Y进行直方图均衡化处理。(5)对Y进行多项式转换。
2 基于熵最小化的阴影去除算法
在光照无关图中,一个物体表面的灰度值被认为是相同(或相似)的。根据该原理,只要找到最优投影方向,就可以消除图像阴影。
研究结果显示,在不同的光照条件下,一个物体表面的对数色度波段比近似在一条直线上,而不同物体表面之间的对数色度波段比近似平行[18]。根据该原理,提出去除阴影的算法步骤如下。
(1)根据公式(1)计算色度波段比向量:
(1)
其中:IR、IG、IB分别表示图像I的3个波段向量,即IR=I(:,:,1),IG=I(:,:,2),IB=(:,:,3)。
(2)根据公式(2)计算对数色度波段比三维向量ρ:
ρm=ln(cm),m=R、G、B。
(2)
式中:ρm由ρR、ρG、ρB构成的三维向量。
(3)根据公式(3)计算二维的对数色度波段比:
χ=Uρ。
(3)

(4)计算最佳投影方向。根据公式(4)计算每个角度θ投影后的一维灰度图像,再根据公式(5)计算每个一维灰度图像的熵,熵最小的方向即为最佳投影方向θwpt。
Iθ=χ1cosθ+χ2sinθ,θ∈[0,180];
(4)
(5)
(5)根据公式(6)计算光照无关图:
Iθwpt=χ1cosθwpt+χ2sinθwpt。
(6)
3 Ncut谱聚类算法
Ncut谱聚类算法[20]克服了K-means等聚类算法的缺点,对非凸分布的数据具有很好的分类能力,适合解决一些实际应用问题。
Ncut算法的步骤:
输入:点集V=(v1,v2,…,vn),vi∈Rd,Rd为d维实数空间,k和σ为参数。
输出:数据分成的k个类。
(1)根据定义的相似度函数,计算相似矩阵S=(sij)∈Rn×n。
(2)计算度矩阵D和拉普拉斯矩阵Lsym=I-D-1/2AD-1/2。
(3)求矩阵Lsym的k个最大特征值对应的特征向量u1,u2,…,uk,设U0=[u1,u2,…,uk],并对矩阵U0进行归一化处理,得矩阵U。
(4)矩阵U的每行元素构成k维空间中的1个点,作为1个样本,用K均值算法将这些样本分为k类。
(5)U的第i行分在第j类,即数据点vi分在第j类。
4 研究思想和算法步骤
本研究的基本思想分为2部分:第1部分是图像预处理,去掉图像中的高光和阴影,第2部分是图像分割。本研究的图像预处理分为先采用文献[17]提供的算法去除高光,再采用文献[18]提供的算法去除阴影。最后根据文献[19]提出的Ncut谱聚类算法,提出基于Ncut的阈值图像分割算法分割去除高光和阴影的皇帝柑图像。
本研究的算法步骤如下:
(1)将图像读入R、G、B3个通道。
(2)根据公式(7)将RGB颜色空间转换为YUV颜色空间:

(7)
(3)对亮度通道Y进行归一化处理。
(4)对通道Y进行直方图均衡化处理。
(5)根据公式(8)对通道Y进行多项式转换,Y变换后的值仍用Y表示。
Y=1.54Y4-3.426Y3+1.773Y2+0.743 5Y+0.004 36E。
(8)
其中:E是元素全为1的矩阵。
(6)根据公式(9)将YUV颜色空间转换为RGB颜色空间:

(9)
(7)根据公式(1)和公式(2)计算对数色度波段比三维向量ρ。
(8)根据公式(3)计算二维的对数色度波段比χ=[χ1χ2]T。
(9)根据公式(4)~公式(6)计算最佳投影方向和光照无关图。
(10)定义去除高光和阴影的图像直方图为H=[h(i)](i=0,1,…,255),定义图G的顶点集合为V={v(i)=[i,h(i)|i=0,1,…,255]},根据公式(10)计算图G中连接2个顶点v(i)和v(j)的边的权值,并获得相似矩阵S=(sij)∈Rn×n。
s[v(i),v(j)]=exp{-min [h(i),h(j)]×(i-j)2/σ2}。
(10)
其中:σ2为参数。
(11)计算度矩阵D和拉普拉斯矩阵L=I-D-1/2AD-1/2。
(12)求L的k个最大特征值对应的特征向量u1,u2,…,uk,设U0=[u1,u2,…,uk],并对矩阵U0进行归一化处理,得矩阵U。
(13)矩阵U的每行元素构成k维空间中的1个点,即作为一个样本,用K均值算法将这些样本分为k类。
(14)U的第i行分在第j类,即数据点vi分在第j类。
5 结果与分析
5.1 分割质量评价准则
本研究采用分类误差(ME)[21]、假阳性率(FPR)[22]和叠加系数(OI)[23]作为分割效果评价标准。
分类误差[21]的定义如下:
(11)
假阳性率[22]的定义如下:
(12)
叠加系数[23]的定义如下:
(13)
式中:BO和FO分别表示人工分割图像的背景和目标;BT和FT分别是根据算法分割图像的背景与目标。
5.2 试验结果分析
本试验分割3幅带叶片且成熟度不一样的皇帝柑图像,且有2幅图像中含有2个皇帝柑。将本研究方法与文献[23]和Matlab软件中提供的Otsu算法作对比试验。试验都采用分类误差[20]、假阳性率[21]和假阴性率[22]3个指标检验分割效果。
试验的分割结果如图1和表1~表3所示,其中图1-a为原始的带阴影和高光的皇帝柑图像,其人工分割图像见图1-b;图1-c是本研究算法分割的结果;图1-d是文献[23]算法分割的结果;图1-e是Otsu分割的结果。表1的数据显示,本研究算法的平均分类误差是4.6%,而文献[23]和Otsu算法的平均分类误差分别为14.9%和16.8%。表2显示,本研究算法的平均假阳性率是2.1%,而文献[23]和Otsu算法的平均假阳性率分别为23.5%和26.2%。表3显示,本研究算法的平均叠加系数是94.9%,而文献[23]和Otsu算法的平均叠加系数分别为76.9%和 71.5%。试验结果显示,提出算法能够很好地提取含有阴影、高光和叶片的皇帝柑图像中的目标,说明提出算法具有很好的分割性能。

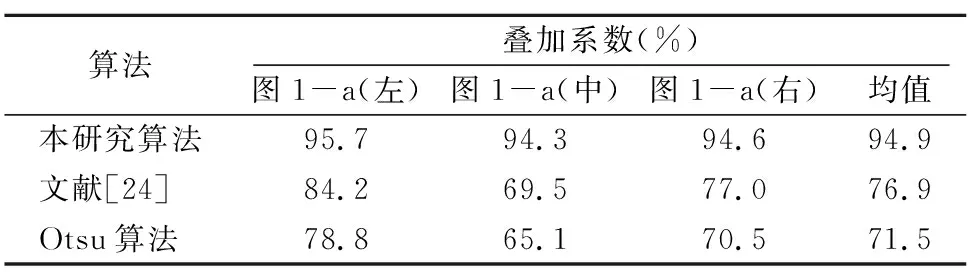
表3 图像分类的叠加系数OI
6 结论
针对含有高光、阴影和叶片的皇帝柑图像在分割时,难以准确提取图像中的目标这一问题,本研究引入了去高光和去阴影2种图像预处理,有效消除了皇帝柑图像中的高光、阴影,再采用谱聚类阈值图像分割算法分割去除高光和阴影后的皇帝柑图像,可以在含有高光、阴影和叶片的皇帝柑图像中,很好地提取图像中的目标。
