数据挖掘技术在图情领域的应用研究
2018-02-11史晓康
史晓康

摘要:数据挖掘是近年来发展较为迅速的数据分析和知识发现方法。本文采用KMeans聚类算法,对近年数据挖掘技术在图书情报与数字图书馆领域的应用与研究的相关文献的关键词进行聚类,以便对数据挖掘在图书情报与数字图书馆领域的研究发展动态有一个直观和充分的认识。
关键词:数据挖掘;图书情报;数字图书馆;聚类
1.引言
数据挖掘是从海量数据中获取正确的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘结合了数据库的数据管理、机器学习与传统统计学的数据分析技术,是知识发现(KDD Knowledge Discovery in Database)中的重要环节,也是近年来发展较为迅速的领域之一,在模式识别、情报检索、专家系统等领域有着广泛的应用。
随着互联网的发展,传统的图书馆也在朝着数字图书馆的方向发展,传统的图书情报领域也经历着变革,研究也更为多元化。其中,采用数据挖掘的方法对图书情报领域相关问题研究,从中获取出正确的、新颖的、潜在有用的、最终可理解的知识是一种不错的尝试。本文使用数据挖掘中的相关聚类算法,对近年来数据挖掘技术在图书情报与数字图书馆领域的应用进行主题词聚类研究,以期望寻找到其内在联系。
2.数据来源与研究方法
本研究的数据来源为CNKI。在CNKI上进行检索,设置学科为“图书情报与数字图书馆”,篇名或关键词含“数据挖掘”,来源类别中选取了SCI、EI、CSSCI等核心期刊,并按照发表时间降序排列,选取了最新发表的200篇文献,提取关键词作为分析的数据源。
研究方法的选取,采用数据挖掘的方法对关键词进行聚类,期望寻找其内在联系。本文采用经典的KMeans算法。KMeans算法是原型聚类中最有代表性的方法,其基本思想是:先对原型进行初始化,随机选择k个样本作为初始均值向量,然后对原型进行迭代更新求解,直到当前均值向量均不再变化或达到最大迭代次数为止。
3.研究过程
3.1 文本预处理
从CNKI上下载到最新的200篇数据挖掘在图书情报与数字图书馆领域的应用的文献的元数据,保留关键词列,同时使用文本編辑软件Ultraedit统一关键词的间隔符,
同时,对论文中表达相同意思的不同词语(如同义词、英汉互译词等)进行统一,以寻求更好的聚类效果。具体如表1所示。
3.2向量空间模型表示
向量空间模型是由Gerard Salton 等人于1968 年提出的文本表示模型,目前已经被成功运用于文本分类、自动索引和信息检索等研究领域。由于向量空间模型的简单有效性,本文将使用向量空间模型对文献关键词进行线性化,将之转换成数学上可分析和处理的形式。该模型的主要思想是将每一文献都映射成由一组规范化正交词条矢量组成的向量空间中的一个点,各特征(关键词)表示空间中的维度。本文采用Python编程实现,同时设置min_df=2,即要求关键词出现的次数大于等于2,才进行保留。最终得到的是200*88的矩阵,即表明200篇文献中含有出现频率大于1的88个不同的关键词。
3.3TF-IDF加权表示
在传统的布尔代数值表示方法中,当在文献i中出现特征词j时,矩阵a[i][j]取1,否则取0。这种表示方法比较单调,忽视了特征词的很多优秀的内在性质,如词频、特征词对整个文献集合的影响。TF-IDF 相对词频计算公式是由Salton 和McGill 于1983 年提出的文本特征表示方法。它的主要思想是,如果某个词或短语在一篇文献中出现的频率比较高,并且在其他科技文献中很少出现,则认为此词或者短语具有很好的类别区分能力。TF-IDF 权重方法不仅改进了布尔权重法表示的单一性,还结合了特征词的词频并且体现了特征词对整个文献集的作用。其计算公式如下所示。
tfidf(w)=tf*log()
其中,tf表示词频,即一个单词在一个文档中出现的次数;df(w)表示在文档集合中,含有该单词的文档的数据;N表示文档集合中的总文档数;tfidf(w)表示一个单词在一个文档中的相对重要性。本文采用python编程对关键词进行加权处理。
3.4KMeans聚类
采用python的机器学习包scikit-learn对文档进行聚类,采用的是之前所介绍的KMeans算法。设置KMeans的n_clusters=4,即表明将200篇文档聚为4个簇。
3.5可视化
为了更直观地看到聚类效果,可以对数据进行可视化处理。但是,由于文本数据的特征比较多,维度比较高,无法直观地以图表形式展现。因此,笔者首先采用了主成分分析(PCA Principal Component Analysis)的方法进行降维。主成分分析是最常用的一种降维方法,其基本思想是:对于正交属性空间中的样本点,寻找一个超平面对所有样本进行恰当的表达,这个超平面具有这样的性质:
Ⅰ 最近重构性:样本点到这个超平面的距离都足够近;
Ⅱ 最大可分性:样本点在这个超平面上的投影能尽可能分开。
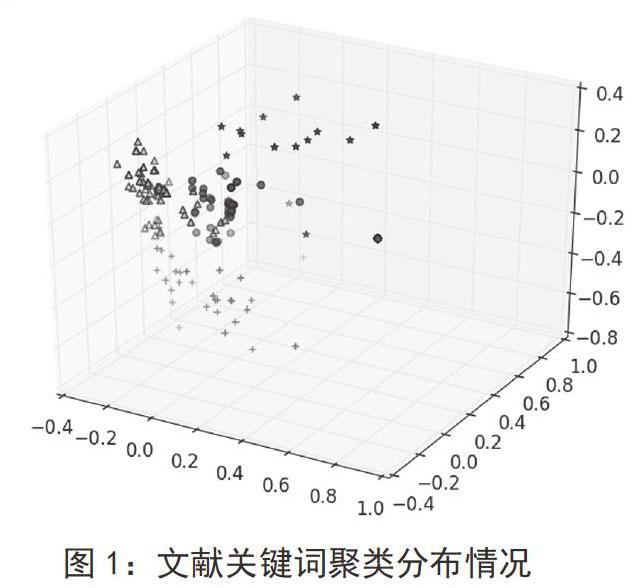
笔者在这里将原始特征空间降为三维空间。之后,采用python的matplotlib绘图库,绘制了降维之后的3D图,三维空间中的每一个点表示一篇文档,并为属于不同簇的文档用不同的颜色和标记进行区分,具体结果如图1所示。虽然在降维过程中丢失了一部分信息,但还是能够较好地反映出样本的分布情况。
4.结果讨论
由图1的输出结果可知,200篇关于数据挖掘在图书情报与数字图书馆领域的应用的文献被聚为4个簇,通过查看簇中心向量,可得到各簇的高频关键词分布如表2所示。
从表2可以看出,对文献关键词进行聚类,我们能了解到近年数据挖掘在图书情报与数字图书馆领域的研究发展动态。具体来说,主要有以下方面:
Ⅰ 数据挖掘与传统的图书馆、档案现代化、文献数字资源等相结合的研究;
Ⅱ单纯采用分类、聚类、关联规则等数据挖掘算法的知识发现;
Ⅲ 数据挖掘与其他数据分析方法如数据仓库、文献计量、知识图谱、社会网络分析等相结合,对图书情报领域相关问题进行分析的研究;
Ⅳ 数据挖掘技术在图书馆服务、智慧服务、知识服务等信息服务与应用领域的应用研究。
可见,随着近年来数据挖掘技术的不断发展,其在图书情报与数字图书馆领域也发挥着越来越重要的作用,采用数据挖掘的理念和方法进行研究分析,是图书情报领域未来的发展方向之一。
参考文献:
[1]周志华著.机器学习[M].北京:清华大学出版社.2016.
[2](美)韩家炜,(美)坎伯著.数据挖掘 概念与技术 英文版 原书第3版[M].北京:机械工业出版社.2012.
[3]刘勘,周丽红,陈譞.基于关键词的科技文献聚类研究[J].图书情报工作,2012,04:6-11.
[4]王富强,韩宇平,王朋,王静.水资源学研究的关键词共词聚类分析[J].水利水电科技进展,2014,04:29-33.
