面向产品开发的评论挖掘方法研究
2018-02-09许祥军魏红芹
许祥军,魏红芹
(东华大学旭日工商管理学院,上海 200051)
0 引言
近年来,互联网的兴起与快速发展拓宽了传统的的商品销售渠道,越来越多的消费者选择通过网络来购买日常用品,甚至一些贵重物品。大量购物行为的产生在网上留下了成千上万的评论数据,并且这些评论信息在影响消费者购买决定中占有很重要作用[1]。主要原因是评论数据中,蕴含有大量的用户对产品的体验和需求信息,这些信息对于生产商来说具有很大的利用价值。但由于评论信息数据量大,并且杂乱无章,生产商很难获得消费者对于该产品较为系统的评价以及用户需求。如何行之有效的从评论中挖掘信息,成为近年来的研究热点。
产品评论挖掘的应用能够快速有效地从大量网络评论中,获取有效的信息。产品评论挖掘主要涉及产品特征的提取,情感倾向判断,评论挖掘结果汇总以及按用户观点排序等[2]。
产品特征提取与情感倾向判断,既是评论挖掘的重点又是其难点。由于,本文研究目的是从评论中挖掘出产品开发所需信息,包括两个方面:一是产品本身信息,主要是产品现有各特征的优点和缺点等;二是顾客相关信息,主要是顾客需求和顾客喜好等。因此,准确而全面的产品特征提取以及情感倾向判断是产品开发成败的决定性因素。
1 相关研究介绍
Hu和Liu[3]首先采用关联规则算法抽取英文评论产品特征,并对手机、数码相机等产品评论进行特征提取,查准率与查全率分别达到72%,80%;随后,对情感词进行抽取与分析,判断用户的情感倾向[4]。
李实等[5]针对中文的特点,提出了面向中文的客户评论挖掘方法,该方法是基于改进的关联规则算法,通过对5种产品的评论语料为例,实现了针对中文产品评论的产品特征信息挖掘。
林钦和等[6]基于关联规则算法与依存关系提取产品特征,采用HowNet情感词语库和依存关系来挖掘极性词与产品特征的关系,并结合词汇相似度计算和同义词词林识别未收录词的情感极性,最后,考虑程度词强度差距、以及程度词和否定词共现语序引起的语义差异,逐级计算情感倾向程度。
杜嘉忠等[7]提出一种基于领域专用情感词的情感分析方法,通过计算机辅助与手工结合的方式获取特征;通过使用改进的TF-IDF算法来区分通用情感词与专用情感词,构建带有情感的本体,然后构建特征-情感词本体,利用本体对评论进行情感分析。
前者研究[3,5-6]在产品特征提取时,并未考虑低频词,随着评论数据的增长,低频词数量也会增大;文献[6]在情感分析时,未考虑了情感词描述不同产品特征表达不同倾向的问题;文献[7]解决了此问题,但依赖人工方式工作量大且可移植性差。本文将主要通过对产品开发中的技术特征需求以及这些需求对应的用户需求进行分析,对常规的评论挖掘算法进行优化,提出了一套可帮助产品研发人员从海量网络评论中有效获取有价值信息的方法。
2 面向产品开发的评论挖掘方法
由于本文主要面向产品开发,故只考虑产品本身特征,不考虑网店服务质量,快递服务质量等与产品开发无关信息;此外,在结果分析上,主要是进行产品优缺点分析,尤其是注重缺点分析,同时包括对用户需求的分析。
基于评论挖掘的产品开发内容包括:评论文本预处理、面向产品开发的特征提取、基于产品特征的情感倾向和强度分析。
2.1 产品评论文本预处理
首先对用户评论进行文本预处理,其主要作用是为了分词与词性标注的准确,便于下一步工作的顺利进行。
(1)评论处理
为了便于情感分析与数据的挖掘,首先将用户评论按照句子为单位进行分割,得到句子级的客户评论。
(2)面向产品开发的用户自定义字典处理
自定义字典的作用是为了提高分词,从而促进产品特征提取的准确性,因而本文针对产品开发评论挖掘,从以下两方面进行用户自定义词典设计:
(1)生产商的说明书中包含大量的规范化产品特征名词;
(2)评论文本中单词长度大于等于3的英文词汇,例如“cpu”、“wifi”等。
将两部分词汇放入用户自定义字典中,并将词性标注为“n”。
2.2 面向产品开发的特征提取
由于产品特征是开发时所针对的主要决策对象,故应尽可能准确而全面的覆盖用户评论,将其提取出来。因此,在文本预处理之后,需要提取产品特征。
产品特征主要是以大量的名词形式存在的,首先,依据词性标注提取名词,根据词频来过滤掉低频词,得到非低频词,再利用点互信息算法(Pointwise Mutual In⁃formation,PMI)进行词语关联度分析,对非低频词中与手机和手机属性信息关联度低的名词进行删除。PMI算法公式如下:
其中word1表示手机以及手机属性信息,word2表示产品特征,P(word1word2)表示 word1与 word2共同出现的概率,P(word1)、P(word2)分别表示 word1,word2单独出现的概率。
低频词,大部分是描述形式不规范的词,部分词是因为在文档中很少被使用。针对低频词,可以使用TF-IDF(Term Frequency-Inverse Document Frequency)算法,其中逆向文件频率IDF是一个词语普遍重要性的度量,包含词条的文档越少,IDF越大。因此,对于低频词有着较好的区分。但TF-IDF算法依然有着明显的不足之处:处理低频词时,该方法没有考虑低频词在整个文本中分布情况,部分含有大量信息的低频词由于权重低于阈值而被删除[8]。因此,本文对TF-IDF算法做出改进,使之能够通过改进将低频词中产品特征的权重提升。改进有如下几点:
(1)在原基础上考虑产品特征的在句中位置,分布在句首以及句尾的名词权重增加;
(2)长度越长的名词包含的信息越多,权重同样需要增加;
(3)组合名词(例:数字与英文、中文与数字等)大多数往往表示产品特征,对此也相应的增加权重。
综上,形成新的改进TF-IDF算法公式为:
其中tfi表示名词i在文档中频率,idfi表示名词i逆向文件频率,pi表示表示名词i在评论句中的位置权重表示名词i的长度,N表示名词集合,以名词长度除以最长名词长度作为长度权重,g表示组合名词权重,当名词不为组合名词时g为1。
最后将经词频以及PMI算法过滤提取出的产品特征与用改进TF-IDF算法提取结果合并,得到最终产品特征集合。
2.3 基于产品特征的情感倾向与强度分析
网络评论中的语句,其中短评论语句占多数,如:“1600像素绝对够劲”、“音质非常清晰,听的很清楚”等。但其中仍有数量可观的长评论语句,如:“外观挺漂亮,物流超快,手机功能也挺多,充电挺快,目前感觉还不错!”等。长评论语句中的特征属性有2个及以上,单纯的进行产品特征的情感倾向与强度分析是不适合的,从评论语句可以看出,对含有产品特征的语句按“,”分割,可以将长评论分成若干有效的短评论,本文依据短评论首先基于判断产品特征的情感倾向,然后进行情感强度计算。
Turney[9]在PMI算法的基础上提出情感倾向点互信息算法(Semantic Orientation Pointwise Mutual Infor⁃mation,SOPMI),通过计算评论文本中情感词组的语义倾向来区分情感倾向。公示如下:
其中word为情感词,pword为正向基准词,nword为负向基准词,Pset为正向基准词集合,Nset为负向基准词集合。
但SOPMI算法并不能区分情感词描述对象,如:单独的情感词“高”与“价格”、“像素”一起出现,情感倾向相反;此外,否定词的数量也会进一步影响情感倾向。因此,本文在SOPMI算法基础上增加产品特征与否定词,计算<产品特征,情感词,否定词数量>与基准词词组PMI值,输出结果<产品特征,情感倾向>。新的SOPMI算法公式如下:
其中f表示产品特征,N表示否定词数量,(N%2)表示取余数,其他符号同公式(3)。
获取<产品特征,情感倾向>之后,进行产品特征的情感强度计算。情感强度需要引入程度词,并且程度词与否定词的位置关系会对情感强度产生影响,例如:“手机屏幕不是很清晰”,“手机屏幕很不清晰”,前者在强度上明显小于后者。因此,在情感强度计算时,构建<产品特征,情感倾向,程度词,程度词位置>,输出结果<产品特征,情感强度>。
基于产品特征的情感倾向与强度分析步骤为:
步骤1:提取情感词,构建<产品特征,情感词>;
步骤2:天猫购物平台获取11万条产品评论,经过文本预处理后,提取形容词,选取词频较高且观点鲜明的正向基准词与负向基准词各5个;
步骤3:从网络与文献中获取否定词,构建否定词词典;
步骤4:依据用户评论构建<产品特征,情感词,否定词>;
步骤5:运用改进SOPMI算法进行情感倾向判断,输出<产品特征,情感倾向>;
步骤6:利用知网中的程度词,并按照程度不同分为5类,构建程度词词典;
步骤7:依据用户评论构建<产品特征,情感倾向,程度词,程度词位置>;
步骤8:情感词倾向为正,则情感值+1;反之,则情感值-1,初始值为0;
步骤9:程度词在否定词与产品特征中间,则情感强度值*0.5;其他位置,则情感强度值乘以相应的程度词权重;
步骤10:若短评论末尾标点符号为“!”,则情感值*1.5;
步骤11:输出结果<产品特征,情感强度值>;
步骤12:将相同属性的产品特征合并,得到其正向总值,负向总值以及零分结果数量。
3 实验数据分析
3.1 原始实验数据获取
运用爬虫技术从购物平台上获取用户评论,实验数据来源包含两部分:
(1)天猫商城关于小米5手机的评论,共1000条评论;
(2)天猫商城各品牌智能手机评论语句,共约11万条评论。
3.2 性能评价指标
在评论挖掘中,常用的性能评价指标为查准率P(Precision)、查全率 R(Recall)以及综合值 F-score。

其中在产品特征提取与情感分析中,A表示识别正确(产品特征或情感句)的数量,B表示识别错误(产品特征或情感句)的数量,C表示未识别(产品特征或情感句)的数量。
3.3 产品特征抽取结果分析
根据词频过滤(阈值>=3)以及词语关联度过滤,得到产品特征118个;采用改进TF-IDF方法抽取特征词得到17个,最后得到产品特征集135个,查准率、查全率以及F-值分别为:84%,82%,83%。表1为手机产品特征集合(选取用户关注度前15的属性)。
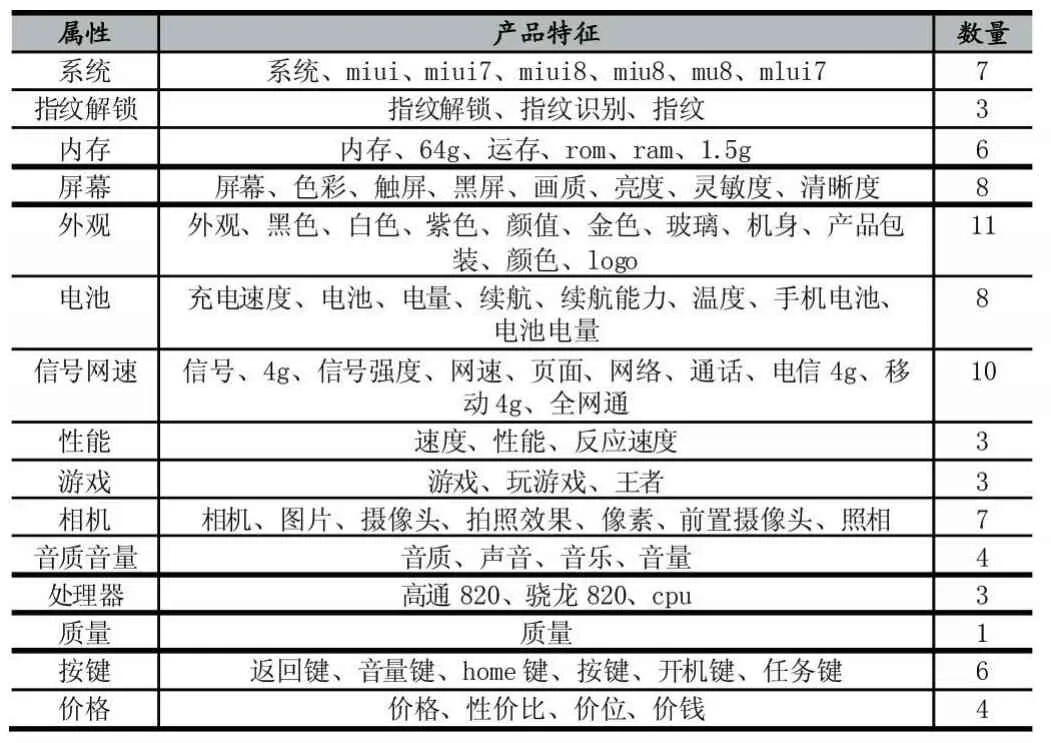
表1 手机产品特征集合
3.4 观点句倾向及强度结果分析
对于基于产品特征的情感倾向判断结果。本文对前200条观点短评论进行人工分析,查准率、查全率以及F-值分别为:80%,85%,82%。
3.5 面向产品开发的评论挖掘结果分析
将观点句结果按照手机属性进行汇总,可得各属性的情感得分情况。本文选取具有代表性6个产品属性进行分析,如图1所示。
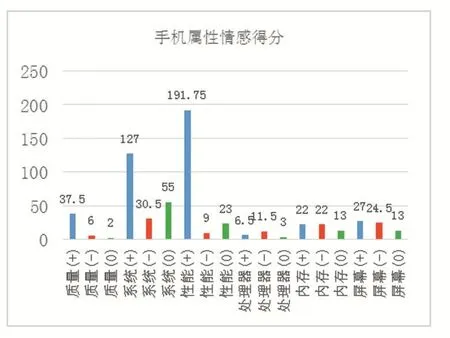
图1 手机属性情感得分
根据用户评论,统计各手机属性中产品特征被提及次数,再除以不同属性下产品特征名词数量,获得手机属性平均提及次数,将均值定义为用户对该手机属性的平均关注度,从中可以发现受用户关注的手机属性。图1中6个产品特征,消费者关注度依次降低。从图中可以看出;质量、系统和性能不仅关注度高,正面评价得分依旧很高,处理器、内存和屏幕的负向评价得分超过或接近正向得分。同时,系统的负向得分和零分数量很高。为了进一步了解处理器、内存、屏幕和系统缺陷在何处,本文对其的评价词进行提取并按词频排序,发现消费者对于处理器、内存、屏幕、系统主要评价分别为:卡顿、占用、失灵、发热。
从消费者评论中不仅能够发现产品的缺点和消费者的关注点,更能发现不同消费者需求信息。例如:根据游戏类产品特征,提取用户评论,可以发现用户的需求主要是系统流畅、电池续航能力高等;针对照相机类,可以发现用户需求主要是像素高、不发烫等。
因此,挖掘用户评论时,可以发现产品优缺点以及用户线需求等信息,生产商可以进行针对性的产品开发,从而设计出满足客户需求的产品,提高客户满意度,提升手机销售量。
4 结语
本文针对生产商研发产品的特殊需求进行了网络评论挖掘方法的研究,设计了完整的挖掘过程模型和各子任务的具体挖掘算法。首先采用考虑低频词的产品特征提取方法,取得了较理想的结果;然后根据情感词描述不同产品特征表达不同倾向的问题,提出基于产品特征的情感倾向与情感强度分析的方法。最后,通过数据实验表明本文方法的有效性,且本文所述方法对于完全创新型产品以及改进型产品的开发均有一定的参考意义。
[1]Utz S,Kerkhof P,van den Bos J.Consumers Rule:How Consumer Reviews Influence Perceived Trustworthiness of Online Stores[J].Electronic Commerce Research and Applications,2012,11(1):49-58.
[2]郗亚辉,张明,袁方,王煜.产品评论挖掘研究综述[J].山东大学学报(理学版),2011,46(5):16-23+38.
[3]Hu M,Liu B.Mining and Summarizing Customer Reviews[C].Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2004:168-177.
[4]Liu B,Hu M,Cheng J.Opinion Observer:Analyzing and Comparing Opinions on the Web[C].Proceedings of the 14th International Con⁃ference on World Wide Web.ACM,2005:342-351.
[5]李实,叶强,李一军.中文网络客户评论的产品特征挖掘方法研究[J].管理科学学报,2009.
[6]林钦和,刘钢,陈荣华.基于情感计算的商品评论分析系统[J].计算机应用与软件,2014,31(12):39-44.
[7]杜嘉忠,徐健,刘颖.网络商品评论的特征-情感词本体构建与情感分析方法研究[J].现代图书情报技术,2014,30(5):74-82.
[8]Lewis D D.Feature Selection and Feature Extraction for Text Categorization[C].Proceedings of the Workshop on Speech and Natural Language.Association for Computational Linguistics,1992:212-217.
[9]Turney P D.Thumbs up or Thumbs down?:Semantic Orientation Applied to Unsupervised Classification of Reviews[C].Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2002:417-424.
