基于Caffe网络模型的Faster R-CNN算法推理过程的解析
2018-02-09郭叶军汪敬华
郭叶军,汪敬华
(1.英特尔亚太研发有限公司,上海 200241;2.上海工程技术大学,上海 201620)
0 引言
Faster R-CNN是用深度学习来进行目标检测的算法[1],并在PASCAL VOC目标检测竞赛[2]中取得了很好的成绩。从理论研究的角度来解析这个算法,存在不易描述清楚的理论问题;而从源代码的角度来讲述该算法,则又拘泥于编程细节,因此,从算法对应的网络模型出发,明确网络模型中每一层的输入输出,并概述其功能,就能把握算法的整体思路,为后续的深入研究奠定基础。
众所周知,有监督的深度学习算法包括两个方面:一是前馈(forward)的推理过程(inference),根据输入和网络模型参数,得到输出;二是反馈(backward)的训练过程(train),根据输入和预期的输出,调整网络模型参数。本文仅关注推理过程,因为理解了推理过程,也就容易理解训练过程。提出Faster R-CNN算法的作者,在其GitHub主页[3]中提供了基于Caffe网络模型[4]的代码,其中也包括一个demo示例程序,其网址见文献[6],通过分析这个demo,来解析这个算法。
1 算法解析
1.1 算法的网络模型
目标检测,是指在一张图像上,找出所有的目标,以及这些目标的具体位置。由于无法预知目标在图像的具体位置,因此,最初始想法就是遍历图像中所有可能位置的候选区域,对每个候选区域(Region of Inter⁃est,简称RoI),通过特征提取等方法分析是否属于某个目标类别。但是,RoI过多会导致算法效率低而无法实用,因此,有很多后续研究关注如何减少候选区域[7]。Faster R-CNN算法的网络模型如图1所示,通过RPN(Region Proposal Network)来生成所有的候选区域RoI。
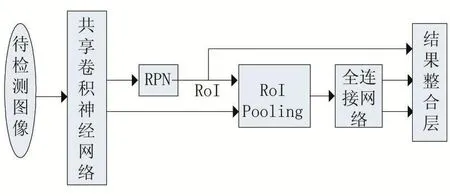
图1 Faster R-CNN算法的网络模型
在Faster R-CNN算法中,待检测图像没有固定的尺寸要求,作为输入图像只需要长宽等比例缩放到一定范围即可,因此可以避免失真。RoI Pooling层用来将一定范围内的尺寸转换为固定尺寸,以满足后续全连接网络层的要求。待检测图像首先通过深度神经网络来生成图像特征,这些特征既被候选的RPN使用,又被后续的检测过程使用,因此,实现了两个不同目的的特征共享,这就是图中被称为共享神经网络的原因。
1.2 目标位置(Bounding Box)
目标检测,需要确定目标所在的位置,因此神经网络的输出应包含目标的位置信息,被称为Bounding Box,简称BBox。在Faster R-CNN算法中,BBox被拆分成两部分:初始位置(矩形位置信息xa,ya,ha,wa共四个值,记为 PriorBox)和调整参数(tx,ty,tw 和 th四个参数,记为BoxDelta)。神经网络是如何知道Prior⁃Box和BoxDelta的物理意义呢?这是因为在训练网络时,训练数据就是建立在这些概念之上,网络经过训练后,这些物理意义就被内化在网络中了。结合PriorBox和BoxDelta,可以算出调整后的新矩形位置,这个新矩形就是目标所在的更精确的位置,即BBox。这个思路,在RPN和结果整合层都被用到。在文献[1]中用如下公式表示它们之间的关系:
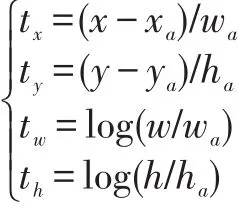
其中xa,ya,ha,wa表示PriorBox的中心点坐标和高宽,tx,ty,tw 和 th是调整参数,而 x,y,h和 w 则是BBox的中心点坐标和高宽。
在RPN生成RoIs时,PriorBox是预先定义的an⁃chor;在结果整合层,PriorBox是RoIs。而BoxDelta则是网络的中间输出。都将在后面详述。
1.3 共享卷积神经网络
卷积神经网络在图像识别中表现绝佳[8-9],已是非常基础的概念,这里需要强调的是,卷积神经网络对输入图像的尺寸没有要求,可以是任意大小。所以,虽然在Caffe网络模型[4]描述中,第一层接受的输入是1×3×224×224,实际上,也可输入 1×3×600×800的图像,其中,1表示一幅彩色图像,3表示图像中有三个通道(channel),分别是红绿蓝三色信号通道,而600×800则是图像的高和宽,这也是在demo[6]中作为Faster RCNN算法输入的图像尺寸。图1所示的共享卷积神经网络来源自VGG16模型[5],最后的输出数据维度是1×512×38×50,表示有 512个 feature map,每个 feature map的 size是 38×50。
1.4 生成候选区域的RPN(Region Proposal Net-work)
RPN的网络模型详细如图2所示,其输入数据是来自共享卷积网络的输出,维度是1×512×38×50,首先经过一个卷积层rpn_conv和一个relu层,然后,分为两条支路。这里的rpn_conv卷积层的kernel size是3,output number是512,对应文献[1]中图3的3×3的滑动窗口,只是输出的不是论文中的256-d数据,而是512维的数据。
下面一条支路经过rpn_bbox_pred卷积层后,变成的维度是 1×36×38×50,表示 feature map的 size是 38×50,一共36个feature map。考察任意一个feature map中的单个元素,其值最终可以对应着原始图像中的某个区域;正是原始图像中的这个区域中的像素,决定了feature map中的这个元素的值。将这个区域进行缩放和偏移,根据事先在训练之前就定义好的规则,我们得到了9个新的区域,这些新的区域就被称为anchor。所以,38×50大小的 feature map就对应着 9×38×50个anchor。由于每个anchor有四个调整参数,因此就对应着 4×9×38×50个调整参数,刚好和feature map的数量对应起来。因此,36个feature map在这里被赋予了具体的物理意义,对应着9个anchor的调整参数,而每个anchor有4个调整参数。
上面一条支路经过rpn_cls_score卷积层后,维度变成了 1×18×38×50,相同的,这里的 18个 feature map也被赋予了具体的物理意义,对应着9个anchor的得分,每个anchor有2个得分,分别是存在目标和不存在目标的得分,显然,这两个得分的概率之和应该是1,所以,后面加了rpn_cls_prob层做softmax。在rpn_cls_prob前后还各有一个Reshape层主要是为了使得数据格式符合相关层的要求,做简单的shape变化,并不涉及到具体的数据拷贝,为图示简洁,这两个Reshape层并没有画出。

图2 RPN的网络模型
最后,在proposal层中,首先根据调整参数来调整anchor得到新矩形位置,为了避免新区域过小,或者超过了原图范围,proposal层还有一个输入im_info用来传入原图尺寸。从这里我们可以看出,新矩形位置是基于原图坐标的,而不是基于某个feature map尺寸的。再结合 NMS(Non-Max Suppress)算法,根据得分概率和新矩形的重叠情况,给出最有可能性存在目标的160个候选区域,称为RoIs,每个候选区域除了矩形的四边坐标外,还有一个id(在这个demo中被置为0,并没有被实际用到),因此是5维的,所以,最后输出的RoI维度是160×5。其中,160是在确定网络结构模型参数的时候,事先确定的。
1.5 候选区域的池化层(RoIPooling)
RoI Pooling层如图3所示,有两个输入,分别是来自共享卷积网络的图像特征数据和来自RPN的RoIs。由于RPN产生的RoI是基于原图坐标,而RoI Pooling层处理的是卷积后的图像特征数据,其大小已经发生了变化,不再是原图分辨率,因此,通过层参数spatial_scale来调整RoI坐标,使之符合卷积后数据的尺寸要求。在网络模型参数确定后,这个参数可以事先计算得到。
RoI Pooling层的参数还包括pooled_w和pooled_h,指的是每个RoI区域应该分成pooled_w×pooled_h个子区域,对每个子区域采用max pooling。所以,在本例子中,对于输入的512个feature map,每个feature map中有160个RoI,一共会产生160×512×7×7个数据。一旦明确模型参数后,无论输入的图像尺寸如何变化,这些数字都不再变化。因此,RoI Pooling层的输出维度是固定的,所以,满足后续全连接网络的固定输入维度的要求。从这里输出的四个维度,我们还可以有一个推论,也就是faster rcnn在推理过程中,在Caffe框架下,每次只能处理一张图片,因为Caffe的数据结构最多就是四个维度,在这里都已经被使用,已经无法容纳诸如图片个数等额外信息了。

图3 RoI Pooling层
1.6 全连接网络
全连接网络如图4所示,输入来自RoI Pooling层,经过两个全连接层(Fully Connected)和RELU层(FC6,RELU6,FC7和 RELU7),演变为 160×4096的数据,然后分成两路。其中一路在经过全连接层bbox_pred,产生维度为160×84的输出,其中160还是对应着160个RoI,而84则对应着每个RoI的21个分类(本例子的识别目标分20类,再加上背景一共21类)的位置调整参数。另外一路经过全连接层cls_score产生维度为160×21的数据,表示160个ROI中每个ROI对应着21个分类的可能性得分,显然,所有可能性相加应该为1,所以,后续紧跟着cls_probe层做softmax。这里的输出,逻辑上和RPN网络中的rpn_cls_prob和rpn_bbox_pred是非常类似的。
1.7 结果整合层
结果整合层并不在Caffe网络模型文件中体现,而是在demo最后用Python代码完成,非常类似于RPN网络中的proposal层,只是初始位置从事先可以静态计算的anchor变成了动态计算得到的RoIs。首先根据调整参数bbox_pred来调整RoIs得到新矩形位置,再结合NMS算法,根据得分概率和新矩形的重叠情况,给出本图像中的目标位置和目标类别。
2 结语

图4 全连接网络
本文从Faster R-CNN算法的网络模型出发,针对重要的网络层,分析它们的输入输出,包括数据维度格式和对应的物理意义,也简单介绍了每一层的主要参数和功能。这样,更容易理解Faster R-CNN算法的关键技术,为后续的进一步研究打下坚实的基础。
[1]Shaoqing Ren,Kaiming He,Ross Girshick,Jian Sun.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,vol.39,no.6,1137-1149.
[2]Mark Everingham,S.M.Ali Eslami,Luc Van Gool,Christopher K.I.Williams,John Winn,Andrew Zisserman.The PASCAL Visual Object Classes Challenge:A Retrospective[J].International Journal of Computer Vision,2015,98-136.[3]https://github.com/rbgirshick/py-faster-rcnn.
[4]Y.Jia,E.Shelhamer,J.Donahue,S.Karayev,J.Long,R.Girshick,S.Guadarrama,T.Darrell.Caffe:Convolutional Architecture for Fast Feature embedding[J].Proceedings of the 22nd ACM International Conference on Multimedia,2014,675-678.
[5]K.Simonyan,A.Zisserman.Very Deep Convolutional Networks for Large-Scale Image Recognition[C].International Conference on Learning Representations,2015.
[6]https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt.
[7]R.Girshick.Fast R-CNN[J].Proceedings of IEEE International Conference on Computer Vision,2015,1440-1448.
[8]许可.卷积神经网络在图像识别上的应用的研究[D].杭州:浙江大学,2012.
[9]A.Krizhevsky,I.Sutskever,G.Hinton.Imagenet Classification with Deep Convolutional Neural Networks[J].Proceedings of Neural Information Processing Systems,2012,1097-1105.
