基于信息增益和随机森林分类器的入侵检测系统研究
2018-02-05魏金太
魏金太, 高 穹
(1. 河南林业职业学院 信息与艺术设计系, 河南 洛阳 471002; 2. 中国洛阳电子装备试验中心, 河南 洛阳 471003)
0 引 言
信息通信网络的发展为人们日常生活质量的改善做出了重要的贡献, 而且被视为社会和经济的基础架构. 然而, 对基础网络架构的安全威胁已经变得越来越严重, 现在有必要提高安全等级以确保众多组织间可信的通信网络. 但是, 互联网以及其他网络上的安全数据通信总是会受到入侵以及滥用等威胁, 所以入侵检测系统已成为计算机及网络安全的重要组成部分.
1 相关工作
入侵检测是一种用来保护计算机以及网络系统避免受到潜在威胁的安全方法, 基于检测信息源的不同, 入侵检测可以分为网络入侵检测系统和主机检测系统. 入侵检测机制通常也被分为两大类: 特征检测和异常检测.
特征检测试图通过已知的攻击信息去发现恶意事件, 如果事件与已知的攻击相似则检测完成. 特征检测在应对已知攻击时是非常有效的, 但是, 对于新的攻击是完全不起作用的. 而另一方面, 异常检测却在检测未知攻击方面相对有优势, 但会产生较高的误警率.
目前已提出了很多方法应用于入侵检测系统的设计, 例如, 有研究提出了结合特征检测和异常检测两种方法用于入侵检测系统, 对异常检测采用模糊逻辑, 对特征检测采用专家系统, 而特征选择使用遗传算法[1], 也有研究直接将遗传算法用于分类中[2].
曾经有研究将基于特征约减的信息增益应用于入侵检测中, 在KDDCUP’99数据集上进行了4种机器学习方法的对比后, 最终发现J48分类器比贝叶斯网络、 OneR以及NB分类器的效果都要好[3], 也有研究采用了KDDCUP’99数据集来评测用于入侵检测涉及的K均值以及朴素贝叶斯的方法[4].
支持向量机[5]以及主成分分析法[6]也被应用于入侵检测系统中. 有研究提出了基于支持向量机的入侵检测系统, 并采用投票的模式进行特征选择[7]. 也有学者对应用到入侵检测系统中的不同人工免疫算法进行了综述[8]. 有研究将随机森林应用到了网络入侵检测系统设计中, 提出的模型在KDD’99竞赛中获得了最好结果[9]. 然而在该系统中, 由于入侵检测审计数据具有较多的不相关属性, 随机森林选择属性时易出现过度随机现象, 导致误警率较高. 因此, 有研究在结合随机森林分类器的同时, 使用加权K均值算法的混合入侵检测系统, 通过加权K均值算法构建异常检测模块, 根据随机森林算法获得特征, 然后对入侵攻击进行决策判断[10]. 该方法虽然降低了误检率, 但是由于每个树状节点的随机特征数目设置和森林中树的数目都比较大, 导致检查速度变慢, 无法应用在真实网络中进行异常检测. 入侵检测研究的一个最大挑战就是分类器的设计, 采用网络模式对分类器进行训练, 准确地从正常事件中识别出攻击模式并使假阳性越低越好. 基于网络入侵检测的另一个挑战就是对数据集中多种多样攻击模式的选择以及预处理.
本文为了解决这两大挑战, 采用随机森林构建了一个入侵检测模型. 同时为了解决入侵检测事件与正常时间样本数目的不均衡, 在所提框架中, 采用信息增益进行特征约减, 合成少数过采样算法用于改善少数类的预测.
2 研究背景
2.1 随机森林
从随机森林的定义[11]来看, 它是众多由原始训练数据经过抽样后构成的树的集成. 为了对一个输入向量中新的对象进行分类, 将输入向量放到森林中的每棵树上. 每棵树都会对该对象做出决策, 对应该分到哪个类中分别进行投票. 最终, 森林选择所有树投票最多的那个类作为该对象的分类.
森林中每棵树的建立过程如下:
1) 令原始训练数据中的样本个数为N. 有放回地进行抽样N次形成一个新的训练数据集, 生成一颗新的树, 没有被抽到的原始数据集中的样本叫做out-of-bag数据.
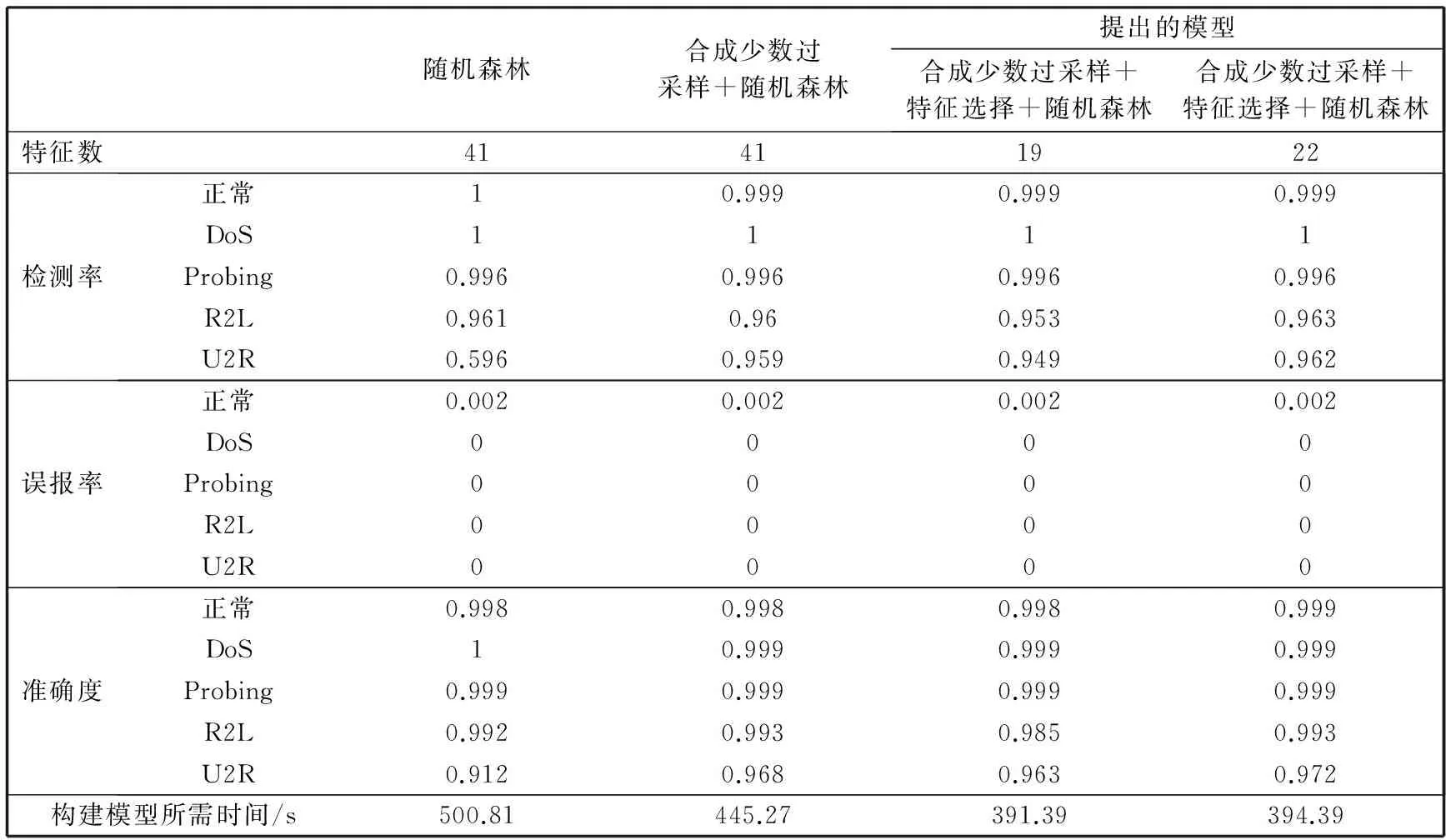
2) 令原始训练数据集中的输入特征总数定为M. 在有放回抽样过程中, 只有m个属性随机地被选进每棵树中, 其中m 森林中每棵树的准确度以及不同树之间的相关性, 决定着整个森林的错误率. 当相关性增大时错误率也随之增大, 当每棵树准确度增大时森林的错误率降低. 准确率和相关性都依赖于参数m的设定, 减小m则相关性和准确度都会降低. 与单一的决策树算法相比, 随机森林在大数据集上更加高效, 准确度更高. 随机森林可以处理标定数据并且不会出现过拟合, 最终的分类决策是由集成的决策树进行预测的多数投票结果. 如果分类的类别不是近似均匀分布的, 那么一个数据集会出现不平衡性. 网络数据由大量的合法流量以及小部分非法流量构成. 类似于大多数分类器, 随机森林在面对极不平衡训练数据集时也存在学习的问题. 随机森林算法主要是用来减小整体上分类的错误率, 对于不平衡的数据集进行抽样生成决策树的过程中, 大部分样本属于占绝大部分的合法流量的类. 显然, 随机森林分类器能够减小整体预测的错误率, 主要是因为其改善了大部分数据类的预测准确度, 而对于占小部分的非法流量类的预测准确度却比较差. 有两种重采样方法可以用来增加分类器对小部分类别的敏感度: 对大类别降采样以及对小类别过采样. 为了解决数据集的不平衡性问题, 我们采用合成少数过采样算法对训练数据进行预处理. 与前人采用的对小部分类别抽样进行替换[12]相比, 过采样方法是对原始数据执行一些操作然后生成新的合成样本, 而本文的合成抽样方法是结合线分割以及k近邻最小类的方法来生成新的样本数据. 其中过采样的样本数量由k近邻中随机选择的邻居决定, 生成的合成样本取不同的特征向量以及最近邻之间的差异, 然后从0到1中生成一个随机数去乘以这个差异, 最后将得到的乘积加到新生成的特征向量中. 特征选择是应用机器学习算法对数据处理之前的关键步骤, 需要衡量一个特征是否与特定的问题相关. 采用有效的特征来设计分类器不仅可以减小数据量的大小, 同时还可以提高分类器的性能, 并增强对数据的理解能力. 在特征约减中一个主要问题就是选择有效的属性以达到不同类之间最佳的区分效果. 有两种常用的特征约减方法: 过滤和打包. 打包是指根据机器学习算法的实际性能表现来选择特征子集, 很大程度上依赖于选用的机器学习算法. 而过滤是根据数据的统计特性来评估特征, 不涉及任何机器学习算法. 一般情况下, 打包与过滤相比较, 前者能够生成更好的特征子集, 但是运行速度较慢, 需要更多的计算资源. 本文在特征选择时引入了信息增益这个参数, 把信息增益应用到特征选择需要计算数据中每个属性的熵值. 熵值的大小用来表示特征对数据分类的影响, 如果一个特征对数据分类的影响很小, 那么其信息增益值就很小, 甚至对分类器准确度无影响的特征可以直接忽略掉. 令向量X和C分别表示样本属性(x1,x2,…,xm)以及类别属性(c1,c2,…,cn). 对于给定的属性X与相关联的类别属性C之间的信息增益可以由式(1)计算 IG(C;X)=H(C)-H(C|X), (1) 其中, (2) 式中:P(C=ci)是类别属性ci出现的概率, 而 (3) 式中:IG(C;X)为属性X对于类别C的信息增益,H(C)为C的熵,H(C|X)为c的平均条件熵. 本文中X表示训练数据集中独立的输入特征, 而C表示类别(正常, Dos攻击等). 本文提出的入侵检测系统(IDS)框架如图 1 所示. 在提出的框架中合成少数过采样用于增加分类器对占小部分的类的敏感性, 基于信息增益的特征选择用于特征约减. 框架中的另外一个主要模块就是随机森林分类器, 用它对数据进行分类. 各个组块整体上是按照流式的工作方式进行运行的. 图 1 开发的入侵检测系统框架Fig.1 Proposed IDS framework 合成少数过采样模块对占少数的类别进行过采样处理, 使训练数据达到需求的等级. 合成少数过采样生成了训练数据, 这个训练数据是相对平衡的数据, 可以直接用作之后的特征选择模块的输入. 使用特征选择模块中式(1)来计算上一模块生成的训练数据的特征, 然后按照特征的信息增益值对它们进行排序. 为了选择最优的特征子集, 采用如下算法: Step 1 依特征信息增益进行排序(从高到低). Step4 选取前n个特征的极小值, 这些特征权重的总和要大于指定的阈值T. 从i=1开始(具有最高信息增益的特征) Wn=Wn+W(xi), 如果 Wn≥T, 跳转到Step5, 否则 i++ 并重复Step4. Step5 n=i (选择前n个特征作为一个新的特征集). T是用于选择最优特征子集的阈值, 由用于分类的训练数据所决定. 框架中的特征选择模块将新的特征约减后的数据转发到随机森林分类器, 同时也会向测试数据预处理器发送一份约减后的特征列表. 本文采用NSL-KDD数据集, 它是KDDCup’99上入侵检测数据集的一个增强版本. 对于KDDCup’99数据集最大的限制是它的冗余记录非常多, 78%的训练记录以及75%的测试记录都是重复的, 这导致学习算法将会偏向于出现频率更高的记录, 因此会影响对少数类别(U2R和R2L攻击)的识别. 即使是NSL-KDD数据集也不能够非常完美地去表示真正的网络数据, 它只是一种用于检测网络入侵的有效的基准数据集[13]. 在NSL-KDD数据集中, 模拟的攻击可以分为以下四类. DoS攻击: 拒绝服务攻击是攻击者通过消耗目标网络带宽以及计算资源来阻止对网络资源的合法请求. 探测攻击: 探测攻击是一系列攻击, 攻击者在发起攻击之前对目标网络进行扫描以获得目标系统信息. 获取root权限攻击(U2R): 这种情况下, 攻击者以正常用户的身份接入到系统, 并利用系统的弱点获取系统的root权限. 获取访问权限攻击(R2L): 攻击者在远程主机上没有账号, 通过向目标主机网络发送数据包并利用系统的漏洞来获取本地的访问权限成为目标主机的一个用户. NSL-KDD训练集包括22种训练攻击类型, 不同的攻击类型以及他们相应的类别如表 1 所示. 表 1 NSL-KDD训练数据集中的攻击类型以及所属类别 表 2 展示了NSL-KDD训练数据集的整体分布情况, NSL-KDD入侵检测数据集总共包含了41个特征. 表 2 NSL-KDD训练数据分布 之前的很多研究都把对记录的分类集中在两大类上, 即: 正常和攻击. 在我们的入侵检测系统中考虑了5种分类情况: 正常, DoS攻击, 探测攻击, R2L攻击以及U2R攻击. 入侵检测系统的性能对比通常包括两方面: 特征选择算法选择的特征数目以及机器学习算法分类的准确度. 为了评估本文提出框架的性能, 我们使用以下性能指标: 混淆矩阵, 检测率, 误警率, 准确度以及建立模型所需时间. 混淆矩阵主要是用来总结测试数据上分类器的预测性能, 分类器做出的预测包含4种可能的结果, 如表 3 所示. 表 3 混淆矩阵 真阳性: 数据本身所属的类别为阳性而分类器判定的结果为正确. 假阴性: 数据本身所属类别为阳性而分类器判定的结果为错误. 假阳性: 数据本身所属类别为阴性而分类器判定结果为正确. 真阴性: 数据本身所属类别为阴性而分类器判定结果为错误. 其他的性能指标可以依据混淆矩阵利用式(4)~(6)进行计算 (4) (5) (6) 本文提出的架构的实验环境为inteli5-2430M处理器2.4GHz, 4GB内存. 使用版本为3.6.9 的WEKA机器学习工具构建入侵检测模型. 在提出的模型中, 采用了NSL-KDD全训练集10份交叉验证测试集. 10份交叉验证指的是将数据集随机地分割成10个不相连的大小近似的子集, 其中1份用作测试集而另外9份用作分类器的构建. 测试集用于评估准确性, 用10份不同的子集重复10次后, 每个子集都进行了测试. 最终的预测准确度取这10个模型的预测准确度的均值, 当数据量不足时互验证起到很好的补充作用. 在实验中, 为了解决之前提到的原始NSL-KDD训练数据不平衡问题, 利用合成少数过采样的方法将少数过采样到800%, 而对于基于信息增益的特征选择, 将阈值设为T=0.9. 经过合成少数过采样后的新的训练数据集的分布情况如表 4 所示. 训练数据集中的少数类(U2R)由原来的52增加到了468. 表 4 合成少数过采样生成的NSL-KDD训练数据分布 在应用了基于信息增益的特征选择方法后, 合成少数过采样生成的新的NSL-KDD训练数据集中的41个特征, 根据其相应的信息增益值约减到如下19个特征: 3, 4, 5, 6, 12, 23, 24, 25, 26, 29, 30, 32, 33, 34, 35, 36, 37, 38, 39. 为了验证少数类(R2L, U2R)上的特征约减效果, 将基于信息增益的特征选择方法应用到一个只包含三类的训练数据集上, 并利用合成少数过采样对该数据集进行扩充. 这里的3个类别分别为R2L, U2R和大多数类, 大多数类是正常, Dos攻击以及探测攻击的合并类. 我们把这个数据集称作少数类攻击模式数据集, 对于这个数据集我们发现3种额外的特征: 1,10和14. 所以与其对应的新的特征集合为如下22种有效的特征: 1, 3, 4, 5, 6, 10, 12, 14, 23, 24, 25, 26, 29, 30, 32, 33, 34, 35, 36, 37, 38 和 39. 为了对比实验结果, 表 5 进行了汇总. 所提模型对于所有类别的检测率都有所改善, 尤其是对于少数类(U2R)检测率从原来的0.596增加到0.962. 建立模型所需的时间也有大幅度减少, 主要是因为训练的数据集是相对平衡的数据集, 而且特征进行了约减. 表 5 性能对比结果 本文采用随机森林分类器开发了一个高效的有效的入侵检测系统. 为了改善在不平衡训练数据集中少数类(R2L和U2R)的检测率, 使用了合成少数过采样技术, 并选取了少数类所有的重要特征构建了少数类攻击模式. 实验结果显示本文提出的方法减少了模型构建所需的时间, 同时大幅提高了少数类的检测率. 下一步的研究计划是将本文所提方法与其他机器学习技术相结合来开发一个实时的自适应入侵检测系统, 这样就可以有效地检测出新的攻击类别. [1]Eid H F, Azar A T, Hassanien A E. Improved real-time discretize network intrusion detection system[C]. Proceedings of Seventh International Conference on Bio-Inspired Computing: Theories and Applications, 2013: 99-109. [2]Jarrah O Y, Siddiqui A, Elsalamouny M, et al. Machine-learning-based feature selection techniques for large-scale network intrusion detection[C]. IEEE 34th International Conference on Distributed Computing Systems Workshops (Icdcsw), 2014: 177-181. [3]陈友, 沈华伟, 李洋, 等. 一种高效的面向轻量级入侵检测系统的特征选择算法[J]. 计算机学报, 2007, 30(8): 1398-1408. Chen You, Shen Huawei, Li Yang, et al. An efficient feature selection algorithm toward building lightweight intrusion detection system[J]. Chinese Journal of Computers, 2007, 30(8): 1398-1408. (in Chinese) [4]赵新星, 姜青山, 陈路莹, 等. 一种面向网络入侵检测的特征选择方法[J]. 计算机研究与发展, 2009, 46(Z2): 69-78. Zhao Xinxing, Jiang Qingshan, Chen Luying, et al. A feature selection method for network intrusion detection[J]. Journal of Computer Research and Development, 2009, 46(Z2): 69-78. (in Chinese) [5]饶鲜, 董春曦, 杨绍全, 等. 基于支持向量机的入侵检测系统[J]. 软件学报, 2003, 14(4): 798-803. Rao Xian, Dong Chunxi, Yang Shaoquan, et al. An intrusion detection system based on support vector machine[J]. Journal of Software, 2003, 14(4): 798-803. (in Chinese) [6]Damopoulos D, Menesidou S A, Kambourakis G, et al. Evaluation of anomaly-based IDS for mobile devices using machine learning classifiers[J]. Security and Communication Networks, 2012, 5(1): 3-14. [7]张振海, 李士宁, 李志刚, 等. 一类基于信息熵的多标签特征选择算法[J]. 计算机研究与发展, 2013, 50(6): 1177-1184. Zhang Zhenhai, Li Shining, Li Zhigang, et al. Multi-label feature selection algorithm based on information entropy[J]. Journal of Computer Research and Development, 2013, 50(6): 1177-1184. (in Chinese) [8]Kim D S, Lee S M, Kim T H, et al. Quantitative intrusion intensity assessment for intrusion detection systems[J]. Security and Communication Networks, 2012, 5(10): 1199-1208. [9]Sivatha Sindhu S S, Geetha S, Kannan A. Evolving optimised decision rules for intrusion detection using particle swarm paradigm[J]. International Journal of Systems Science, 2012, 43(12): 2334-2350. [10]任晓芳, 赵德群, 秦健勇. 基于随机森林和加权K均值聚类的网络入侵检测系统[J]. 微型电脑应用, 2016, 32(7): 21-24. Ren Xiaofang, Zhao Dequn, Qin jianyong. Network intrusion detection system based on random forests and K-means clustering aigorithm[J]. Microcomputer Applications, 2016, 32(7): 21-24. (in Chinese) [11]Zhong S H, Huang H J, Chen A B. An effective intrusion detection model based on random forest and neural networks[C]. Manufacturing Systems and Industry Applications, 2011: 308-313. [12]崔振, 山世光, 陈熙霖. 结构化稀疏线性判别分析[J]. 计算机研究与发展, 2014, 51(10): 2295-2301. Cui Zhen, Shan Shiguang, Chen Xilin. Structured sparse linear discriminant analysis[J]. Journal of Computer Research and Development, 2014, 51(10): 2295-2301. (in Chinese) [13]徐培, 赵雪专, 唐红强, 等. 基于两阶段投票的小样本目标检测方法[J]. 计算机应用, 2014, 4(4): 1126-1129. Xu Pei, Zhao Xuezhuan, Tang Hongqiang, et al. Object detection method of few samples based on two-stage voting[J]. Journal of Computer Applications, 2014, 4(4): 1126-1129. (in Chinese)2.2 合成少数过采样算法
2.3 特征选择
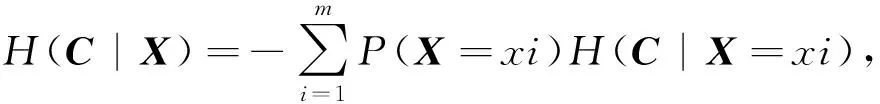
3 入侵检测系统开发
3.1 整体框架


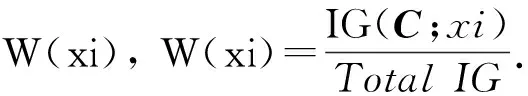
3.2 数据集描述


3.3 评测指标

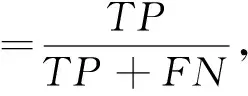
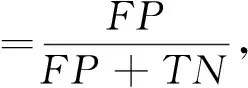
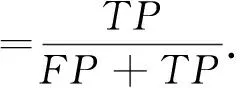
4 实验及结果分析

5 结 论
