基于小波包分析的玻璃破碎声音识别系统设计
2018-02-05,,
,,
(电气与信息工程学院,西安 710021)
0 引言
近年来,随着物联网、云计算等技术不断发展,计算机、通信和控制技术已逐步应用到家庭生活中[1]。现代家居一般使用防盗网和防盗窗实现安防功能,但若出现例如火灾这类突发事件时,这类家庭无法及时做好逃生工作,存在着较大的安全隐患。所以在家庭装修设计时,一般会预留几个窗户不安装防盗网,这也为家庭留下了极大的安全隐患。
目前有相关学者在安防系统中利用视频采集玻璃破碎的图像并处理、单技术振动式传感器检测玻璃破碎等家居安防方面进行了相关研究,并已实现相关功能,但振动式传感器体积大,安装时需紧贴玻璃,不美观[2]。国内对于家居的综合安防比较少,并未涉及整个家居安防系统中玻璃破碎的检测和管理。
玻璃破碎声音包含了较多的信息量,且易于获取,但它的识别存在着家居内背景声音的干扰。由实验可知,玻璃撞击时的声音无噪声干扰的低频段范围在0~1 kHz,破碎时声音高频段范围在5~15 kHz,它的声音信号的频谱包含相对丰富的高频成分。家居内的背景声音(酒瓶摔碎、敲门、闭门、拖鞋走路等)离玻璃较近,存在着背景声音的干扰,酒瓶摔碎声音频段范围在50 Hz~16 kHz,敲门的声音频段范围在0~1 kHz,闭门的声音频段范围在3~11 kHz,拖鞋走路声音低频段范围在1~200 Hz,高频段范围在500 Hz~3 kHz。
针对玻璃破碎声音和背景声音时频特性进行分析。传统的声音信号处理采用傅里叶变换,提取Mel频率倒谱系数(MFCC)作为特征参数[3]。一般假设声音信号是短时平稳的,用固定的傅里叶窗得到的,会使声音的频谱细节特征模糊,丢失一定的信息,且傅里叶变换揭示了信号在频域的特征,但不能显示出这些频率出现的时刻[4]。此外,玻璃破碎声音和酒瓶摔碎的声音频域上体现出较难区分的特征参数,而在时域上平均过零率、短时平均幅度分布等特征参数体现出较为明显的差异。
小波变换通过有限个基函数在尺度-频率域上对信号进行分析,在控制分辨率的同时,保留了时域信息,适合于时域和频域相结合的信号分析系统,并且小波变换在分析频段的恒Q(品质因数)特性与人耳听觉对信号的加工特点相一致。而玻璃破碎声音既同时包含低频段和高频段声音频谱。小波包分析是在小波变换的基础上对高频信号进行进一步的分析,得到小波能量系数[5]。
针对以上问题,文中设计了一个基于小波包分析的玻璃破碎声音识别系统。采用小波包分析对家居内的声音进行检测与识别,从而更准确的判断家居内声音的类型和玻璃破碎的声音,提高玻璃破碎声音识别系统的识别率。
1 系统方案设计
考虑到识别系统安放的位置与玻璃之间的远近对幅值和功率的影响,玻璃破碎声音识别系统以长为7米,宽7米,高3米的家居为研究对象。识别系统安放在家居内窗户的玻璃前,主要实现玻璃破碎声音信号的采集、识别和报警功能。它的基本原理是从实时采集的家居内的玻璃破碎声音中,提取能反映其特征的参数,建立模板匹配,与家居内的典型声音(如酒瓶摔碎、敲门、闭门、走路等)进行分辨,得出识别结果。声音采集模块在实时监测家居内的声音,如果家居内发生玻璃破碎,则在LCD触摸屏上出现报警信息,若5秒内未在LCD触摸屏上撤防,则判断为非法入侵,系统自动通过GSM模块向主人发送报警信息。利用此系统能够实现家居内玻璃破碎的自动检测,避免因非法入侵窗户造成的财产损失,实现家居内安防系统管理的信息化。玻璃破碎声音识别系统总体框图如图1。

图1 玻璃破碎声音识别系统总体框
2 系统硬件设计
玻璃破碎声音识别系统以DSP C5402为主控器,玻璃破碎声音识别系统硬件组成原理图如图2所示。

图2 玻璃破碎声音识别系统硬件组成原理图
2.1 声音采集模块设计
针对玻璃破碎声音和背景噪声的频段差异,本文拟采用拾音器获取玻璃破碎的声音,通过声音放大器(MAX9814)进行放大,放大后的信号进入抗混叠滤波器(MAX7425)进行滤波,采集到声音经过放大和抗混叠滤波后,通过A/D转换,将数字信号送入DSP处理器中。
2.2 声音处理模块设计
声音处理模块由DSP处理器、存储器、JTAG接口和串口组成。DSP处理器采用的是C5402定点低功耗系列,处理速度在80~400 MIPS,双电源供电,提供扩展存储器接口和A/D采样接口。
2.3 通信模块设计
国内的无线通讯方式主要有Zigbee、WIFI、蓝牙和GSM(global system for mobile communication)等,考虑到现代人们使用手机较为广泛,且利用手机短信方式传输信息非常方便,本文选用了安全性较高、抗干扰性较好、不受全球地理位置限制的GSM全球移动通信系统,满足系统通信实时性的要求。GSM根据提供的数据传输速率又可以分为GPRS模块、EDGE模块、3 G模块和短信模块。本系统所使用的是纯短信模块,短信模块只支持短信服务。
3 系统算法设计
玻璃破碎声音识别算法分为声音前端信号处理、模板训练、特征系数提取和模板匹配4个阶段。系统算法图如图3所示。

图3 DSP处理声音处理原理图
3.1 声音前端信号处理
在DSP声音信号处理中,有一些共同的声音信号需进行预加重、分帧、加窗等前端处理[6]。根据香农定理中所要求的,为了完全地表示采样的模拟信号,声音信号的采样频率至少为固有频率的2 倍,背景声音信号的频率范围在0~15 Hz内,玻璃撞击时的声音无噪声干扰的低频段范围在0~1 kHz,破碎时声音高频段范围在5~15 kHz,因此拟定采样频率为30 kHz。随后进行A/D转换,将模拟的声音信号转化为数字信号,再进行预加重,预加重可以充分提高玻璃破碎声音信号的高频特征,从而保持在整个频带中,低频到高频均可以用同样的信噪比得到频谱。预加重数字滤波器公式为:
H(z)=1-αz-1
(1)
其中:α指的是预加重系数,一般情况下接近数值1。
玻璃破碎的声音信号是非平稳性的时域信号,但具有短时平稳特性,在对声音处理的过程中,需对信号进行分帧,帧长取10~30 ms,得到声音帧。声音信号在分帧处理后,为了减少分帧处理所带来的频谱泄露,对分帧后的信号进行加窗处理。本文采用汉宁窗,一个N点的汉宁窗函数在时域表现形式如下:
(2)
其中:k=1,2,…,N。
3.2 特征系数提取
考虑到玻璃破碎信号的非平稳性瞬时间变化的特点,既想了解信号的频谱特征,又想获取这些频率出现的时刻,因此,特征系数的提取需从时域和频域两个方面进行。
在时域分析中,系统对声音信号的波形进行分析,选取短时平均幅度和短时过零率确定两个门限。短时平均幅度是表示声音信号一帧能量的多少。短时过零率是个比较低的门限,其数值比较小,对信号的变化比较敏感,它可以从背景声音中找出声音信号,判断声音的起始点和结束点。
(3)

(4)
(5)
在实验中发现,家居内背景噪声小时,用短时平均幅度识别较为有效,背景噪声大时,用短时过零率有更加显著地效果。
在频域分析中,理论上可以采用任何形式的小波函数对玻璃破碎声音信号进行分解[7]。小波包系数分解后尺度空间的能量分布是玻璃破碎声音的本质特征,可用于系统识别分类。
由于变换域是离散有限长,家居内背景噪声范围集中在5 kHz以下,玻璃破碎的声音主要集中在高频部分,因此,需要对玻璃声音高频处和低频处的细节信息进行划分,同时为了减少特征维数便于计算方便和处理,本文采用离散小波包分析来提取尺度空间上的能量分布特征。首先对每一帧声音信号进行离散小波包分析,根据变换后的小波包系数计算信号的高频能量,确定当前帧的动态阈值。当检测到当前帧为玻璃破碎声音的起始点时,取一段时间较长的声音段信号(通常取2 s时间长度的声音),将该段声音信号在时间轴反转,再施以起始点检测的算法确定终点,提取有效的声音段。

(6)
设ψ0,0(t)=ψ(t)由上述离散小波分析定义信号s(t)的离散小波变换为:
Ws(m,n)=DWT[s(t)]=
(7)
玻璃破碎声音信号的特征系数提取过程如图4所示。
小波包分析提取特征信息的基本步骤为:
1)对声音信号进行N层小波分解,重构出第N层的小波包系数S(N,0)、S(N,1)...S(N,2N-1)。即S(i,j),i=0,1,2…N,j=0,1,…2N-1。
2)求各频带下的总能量。第N层的各重构分解信号的能量定义为:
(8)
信号的总能量为:
ENj=EN0+EN1+EN2+...+EN2N-1
(9)
3)构建特征向量。当能量较大时,可以用第M层各分解信号的能量百分比Ej/E来构成能量特征向量,即:
T=[EN0/E+EN1/E+...+EN2N-1/E]
(10)
最后选择部分尺度空间能量组成玻璃破碎声音的特征向量,主要是选择那些能量相对集中的尺度空间,这样既能充分利用频谱信息,使玻璃破碎声音信号的主要能量特征得以增强,又能减小特征维数,加快分类速度。
3.3 模板训练
在提取到声音的特征参数后,需进行模板训练,建立一个模板库,所有作为模板的特征都应该保存在这个模板库中,以便进行匹配。在模板训练阶段,首先确定训练的玻璃破碎信号的样本。系统对这些训练样本进行预处理,估计玻璃破碎声音的最初模型参数,进行模型训练,通过反复训练迭代,确定玻璃破碎声音信号的模型参数,建立玻璃破碎声音信号的模板库。
隐马尔科夫模型(HMM)是处理声音信号中广泛应用的一种训练和统计模型,由于玻璃破碎声音信号是一种时变信号,而HMM能够很好地表征时变信号[8],因此,利用HMM对玻璃破碎声音进行建立模型。
HMM是一个双内嵌式随机过程,其中,一个随机过程描述状态的转移,另一个随机过程描述观察值和状态之间的统计对应关系[9]。HMM可以用一个五元数组:λ=(P,Q,a,M,A)描述,其中,P为模型中的状态数目,Q为每个状态可能的观察值数目,a表示初始状态概率,M表示状态转移概率矩阵,A=[aij]表示观察概率矩阵。由于在算法识别过程中状态数目和观察值数目不变,HMM简写为:λ=(a,M,A)。
隐马尔科夫有3种算法:前向-后向算法、Viterbi算法和Baum-Welch算法[10]。
Baum-Welch算法可以描述为:给定一个观察值序列O=O1,O2,O3...OT和初始参数λ=(a,M,A),使观察序列O相对于λ的的概率P=(O|λ)最大。
Viterbi算法可描述为:给定一个观察值序列O=O1,O2,O3...OT和初始参数λ=(a,M,A),如何确定未知序列K=K1,K2,K3...KT的P=(K,O|λ)最大时的最佳状态序列K*=K1*,K2*,K3*...KT*。
因此,在玻璃破碎声音识别系统的隐马尔科夫模型(HMM)训练中采用Baum-Welch算法,HMM识别中采用Viterbi算法。对于要识别的玻璃破碎声音信号,可算出玻璃破碎声音特征通过每个HMM模型的概率P=(K,O|λt),其中输出概率最大的模型作为识别结果。
3.4 模板识别
采用HMM的声音检测系统对玻璃破碎声音进行模板匹配。采集到一段声音,对它进行预处理,然后提取特征参数, 随后将提取的每一帧玻璃破碎声音信号的特征参数带入HMM识别系统,利用Viterbi算法与已经建立的玻璃破碎声音模板库中的模板进行逐一的匹配比较,计算出匹配概率,通过匹配概率确定是否为玻璃破碎信号,输出识别的结果。
4 实验分析
4.1 实验条件
本文实验样本一部分为家居内现场录制,一部分为网上标准声音下载,样本精度为16 bit/ms,采样频率为30 kHz,使用MATLAB作为仿真平台。采集的家居内的声音包括玻璃破碎声音和非玻璃破碎声音,非玻璃破碎声音包括家居内其他声音(酒瓶 摔碎、敲门、闭门、走路、咳嗽等)。其中玻璃破碎声音有100个样本,非玻璃破碎声音有200个样本。玻璃破碎的原始信号图如图5所示,对该信号进行去噪处理如图6所示。

图5 玻璃破碎的时域信号图

图6 玻璃破碎的去噪图
本来分别提取了3种参数(LPCC、MFCC和小波参数)进行对比实验。LPCC参数采用递推求解得到22阶LPCC系数的方法,帧长25 ms。MFCC参数提取时数字滤波器组选24个,对处理过的声音信号反离散余弦变换后得到12个小波包能量系数再计算其一阶差分12个共24维。
在时域上对玻璃破碎声音进行短时能量和短时过零率分析如图7所示。
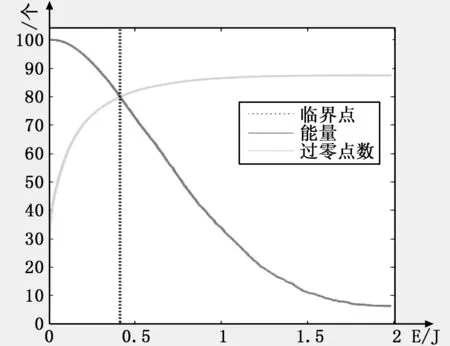
图7 玻璃破碎声音时域分析
可看出,家居内监测有异常声音时短时能量大,没有异常声音时短时能量很小近似于零;当玻璃破碎时过零率大,玻璃破碎前过零率小。
小波包能量系数提取时将传感器采集到的玻璃破碎声音信号进行分帧处理,信号的分帧长度为25 ms,帧移为8 ms。通过实验测试,划分到5层的小波信号细节信息较为清晰,可达到精度16 bit/ms。因此,本实验采用5层小波包分解,将声音信号分解到高频和低频空间,再将高频空间a1(n)和低频空间d1(n)继续分解低频空间a2(n),一直分解到5层后得到d1(n)-d5(n)和a1(n)-a5(n)10个不同的频率信号,得到小波在低频和高频处的细节信息,其中d1(n)-d5(n)和a1(n)-a5(n)可表征原信号所有的频率信号。
设eNj为第j级尺度细节空间的能量,则5级尺度下能量组成的特征向量可表示为:
T=(EN0,EN1,EN2,EN3,EN4)
(11)
在HMM识别阶段,一段声音的每个音段都对应了一些状态,每个状态又代表了不同的声音特征序列,玻璃破碎声音特征序列用状态图如图8所示。

图8 玻璃破碎识别中的HMM图
由图可看出,声音信号下一帧处于何种状态的概率只取决于当前的状态,而与以前的状态无关。从一个状态进入下一个状态的概率为P,保留在本状态的概率为1-P,将每帧所属的状态标明,就可将声音特征序列转化成为一个状态的排列。用这个排列匹配一个特定的声音段,得到一个观察序列概率,最后选择一个概率最大的观察序列,即为家居内声音识别的结果。
4.2 实验结果
将实验样本分为训练样本和测试样本:训练为总数的90%,测试样本为剩余10%的样本。每组实验做10次,列出每类声音的平均识别率,最后对不同特征组合下的识别率进行比较。不同特征参数的识别结果如表1所示。

表1 不同特征参数的识别结果
由表1可知,对于相同的样本,选取小波包系数作为特征时的正确率比选取MFCC作为特征的正碎声音信号的非平稳性。从玻璃破碎声音和家居内其他声音的总识别率可以看出,选取小波包系数作特征参数时,用HMM模型能够准确地分辨玻璃破碎声音和非玻璃破碎声音,说明玻璃破碎声音和非玻璃破碎声音信号的小波包系数存在较大的差异。
由以上实验可得结论:利用特征参数小波包系数和隐马尔科夫模型HMM对于玻璃破碎声音的识别是可行的,识别率达93%。
5 总结
经过实验测试表明:该系统能够对家居内的玻璃破碎声音进行采集和识别,系统易于安装,灵活性好,且能够有效、准确地监测家居内玻璃破碎声音的信息,切实保障家居内财产安全,同时为国内非语音识别提供技术支持,具有一定的推广价值。
[1]Zhu Qinghua.Analysis of Security Monitoring Technology in the Era of Internet of Things[J]. Value Engineering,2016,3(1):113-114.
[2]Rogers J.ADT Raising Old Allegations in New Suit against Vision Security[J].Enterprise/salt Lake City,2013,43 (15):4-8.
[3]李伟红,田真真,龚卫国,等.改进的ESMD用于公共场所异常声音特征提取[J].仪器仪表学报,2016,37(11):2429-2437.
[4]常 飞,乔 欣,张 申,等.基于MFCC特征提取的故障预测与评价方法[J].计算机应用研究,2015,32(6):1716-1719.
[5]张文霞,杨 元.小波包分析在故障特征提取与识别中的应用[J]. 信息通信,2012,11(03):14-15.
[6]郭莉莉.智能家居中语音识别系统的算法研究[A].中共沈阳市委、沈阳市人民政府、中国农学会.第十三届沈阳科学学术年会论文集(理工农医)[C].中共沈阳市委、沈阳市人民政府、中国农学会,2016:5.
[7]蒋翠清,李天翼.基于小波MFCC与HMM的列车鸣笛识别算法研究[J].中国管理信息化,2015,2(06):72-73.
[8]张芝旖,姚恩涛,石 玉.小波分析和MFCC融合的声音信号端点检测算法[J].电子测量技术,2016,39(07):62-66.
[9]韩宝珠.基于小波分析和在线极限学习机的滚动轴承故障诊断方法研究[D].北京:北京交通大学,2016.
[10]陈贵亮,周晓晨,李 晨,等.基于HMM的下肢表面肌电信号模式识别的研究[J].机械设计与制造,2015,4(1):39-42.
