第十九讲“基于均匀设计的类Fenton's体系去除污染土壤中蒽和芘的研究”三种数据处理技术讨论
2018-01-25徐静安李森张杨吴芳
徐静安 李森 张杨 吴芳
前几个月,李森、张杨给我送来《环境科学学报》2015年4月发表的题为“基于均匀设计的类Fenton's体系去除污染土壤中蒽和芘的研究”文章,该文章作者为李森、张杨、罗勇、商照聪、徐静安。笔者作了认真阅读,全文有6.5个页面,内容充实。
按照我的工作摘录,2013年8月21日开始多次讨论李森博士(海归)进上海化工研究院后的第一个立项——污染土壤中挥发性有机物脱除研究。2013年10月15日,实验方案主体由正交设计修改为均匀设计。2014年2月15日—3月18日,与李森、张杨先后讨论采用二次多项式逐步回归建模、模型修整、模型验证。2015年8月7日起又对已发表的论文进行数据核实等,还由吴芳硕士用不同方法进行计算比对。
一项研究工作,一篇科技论文,在相当长的时段内,从试验设计和数据处理方法的角度反复推敲、计算比对、合作讨论、共同提高,实属难得。现把共性技术方法的应用归纳成文供参考。
一、原文均匀设计方案及结果
多环芳烃(PAHs)是指具有两个以上苯环的芳香烃,是一类持久性的环境污染物,因其低生物降解性、疏水性及缓慢的脱附作用,成为土壤修复的难点之一。在以往的Fenton's体系去除土壤中有机污染物的研究中,常用无机酸调节土壤的pH,原文专业上研究筛选出有机酸——柠檬酸代替无机酸,可经微生物降解,从而避免土壤的酸化。
研究考察H2O2用量、FeSO4用量、反应温度、反应时间、水土比、柠檬酸用量及土壤中PAHs含量(质量分数)等7个因素,响应值为PAHs去除率。由于实际土壤染毒PAHs含量范围较广,取值90~585 mg/kg,应安排多水平实验,使水平间步长不致过大,这样研究对象就是多因素、多水平问题,采用均匀设计较为合理。
在现有数理统计专著中均匀设计表中最多可安排7个因素,如果因素M>7,就要利用软件设计新的均匀表。原文选用U*12(1210)表,安排7个因素,不均匀度D=0.276 8,训练集样本量N1=12。
需要指出的是,均匀设计采用二次多项式逐步回归建模,一般要求样本率N1/M=2~2.5。虽然没查到专著讨论,这是笔者基于数理统计基础知识,从阅读的案例中归纳的概念,有利于建模(见《上海化工》2016年第10期刊登的第六讲“均匀设计应用案例解读”)。由于本案例N1/M=12/7=1.71,所以:一要有思想准备需补充实验修整模型;二是在精心实验的基础上每组实验进行2次(n=2),取平均值作为响应值,提高数据的稳定性。
实验中PAHs染毒量用蒽和芘1:1配制。表1为均匀设计实验方案及结果。
二、原文数据处理
在DPS7.05数据处理系统中,使用二次多项式逐步回归法对表中的实验数据进行处理,得到回归方程:

可决系数R2=0.995 2,剩余标准差S=1.839 3,p=0.000 2<0.01,F=119.355>F0.05(7,4)=6.09,通过 F 检验。调整后可决系数Ra2=0.986 8,Durbin-Watson统计量d=1.302 209 50。
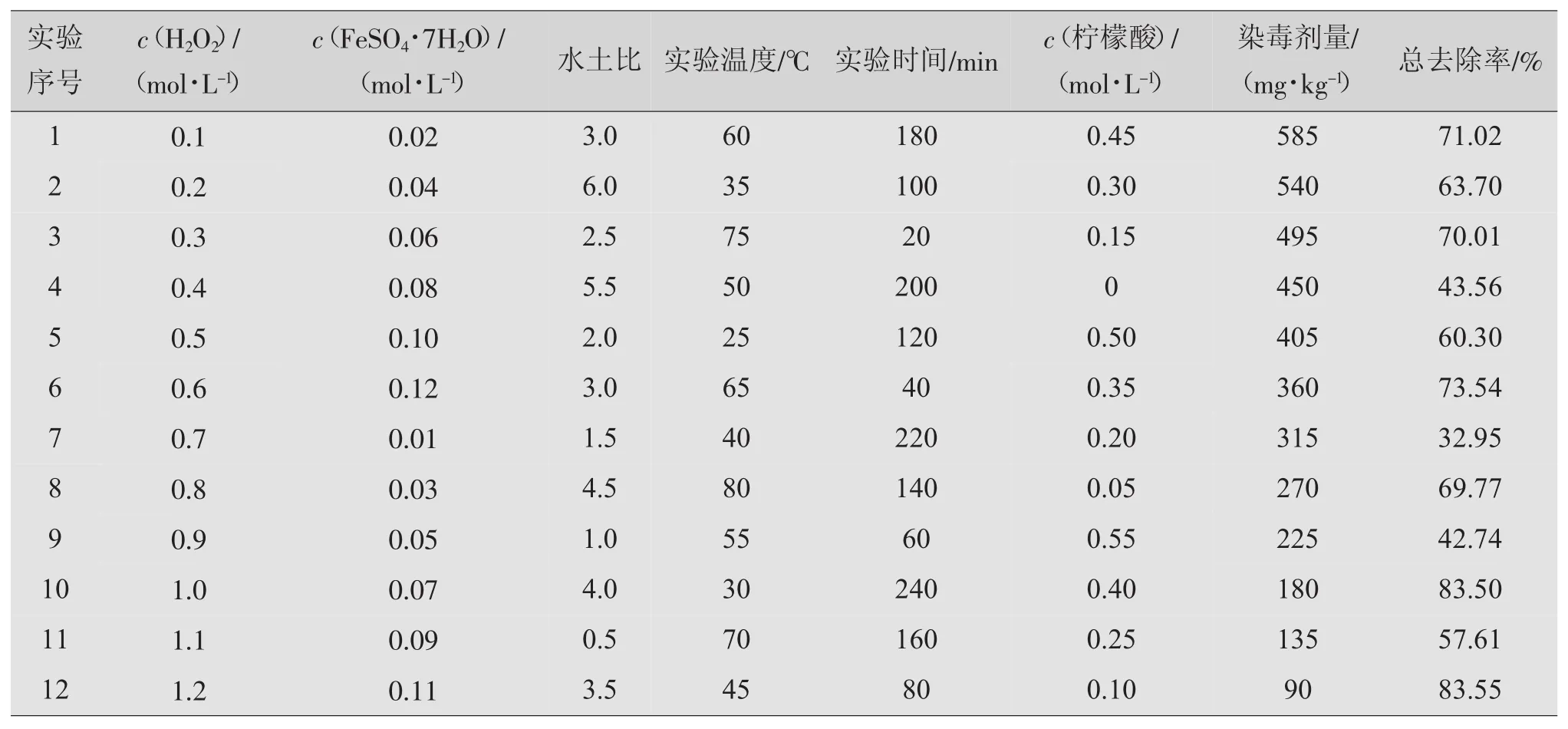
表1 均匀设计实验方案及结果
表2为最高指标时各个因素的组合。
从上述计算软件输出的统计模型最优预报值为去除率Y=145.86%,显然违背常识,不可接受,模型需要修整。关于模型修整,笔者若干藏书及所阅论文中均未涉及,引用案例似乎都是一次建模成功。但在应用实践中,却是不能回避修整。
补充修整实验2组,直观选择“好点”、“差点”工艺条件修整模型,并使样本率达到(12+2)/7=2。修整点的选择可按随机性原则,但笔者从应用角度推荐从“好点”、“差点”范围内选点,修整效率比较高。

表2 最高指标时各个因素组合
表3为回归方程修整实验及结果。
对14组实验数据进行二次多项式逐步回归分析,得到回归模型:

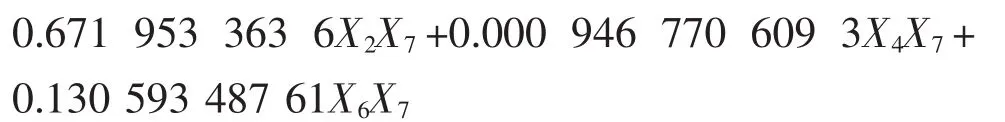
可决系数R2=0.991 2,剩余标准差S=2.600 8,p=0.000 1<0.01,F=70.509 4>F0.05(8,5)=4.82,通过 F检验。调整后可决系数Ra2=0.977 1,Durbin-Watson统计量d=2.315 646 42。

表3 回归方程修整实验及结果
表4为修整后最高指标时各个因素的组合。
模型各项统计量显著、正常,进一步应对模型预报功能验证、检验。
由于原文研究对象土壤中染毒剂量在工程实施时是现场取样检测所得,所以在实验室研究时验证一个点的最优工艺条件没有工程意义,而应对模型在考察范围内的预报功能进行验证。

表4 修整后最高指标时各个因素组合
那么应该对统计模型验证几个点呢?
这又是一个专著中没有查到,而在应用中需要解决的实际问题。这个问题的本质涉及统计模型的稳定性和预报质量。笔者认为其与建模过程的训练集N1和测试集N2的比例N2/N1以及建模时训练集样本量N1和变量数M的比例(即样本率N1/M)有关;还与训练集、测试集的均匀性有关,当然,与实验的误差控制更有关联。
对于试验研究,笔者推荐训练集采用均匀设计,尽可能选用不均匀性D≤0.3的UD表,如原文选U*12(1210),对于测试集(如原文预报测试集),采用Matlab的Rand函数构成随机性验证实验方案。对于不同的试验设计和数据处理方法,尽可能保证相应的样本率N1/M[如原文修整后(12+2)/7=2]。对于训练集N1和测试集N2的比例,从应用角度出发,应保证 N2/N1≥1/3~1/4,且 N2≥3。误差控制根据不同专业每组实验重复次数n=1~5(原文n=2)。由此,原文由Matlab的Rand函数构成随机验证实验方案,验证集N2=4。表5为随机验证实验方案及结果。
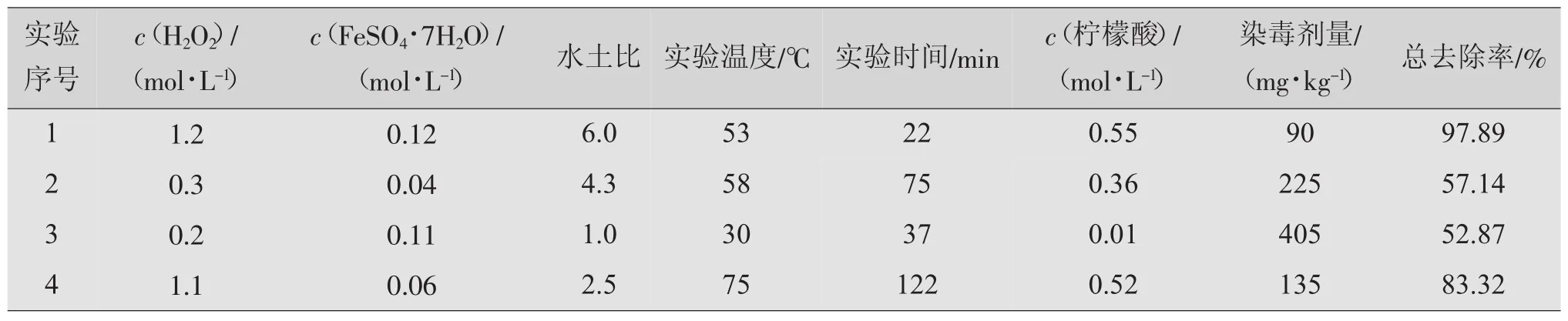
表5 随机验证实验方案及结果
二次多项式逐步回归模型对随机验证试验的预报结果及误差见表6。
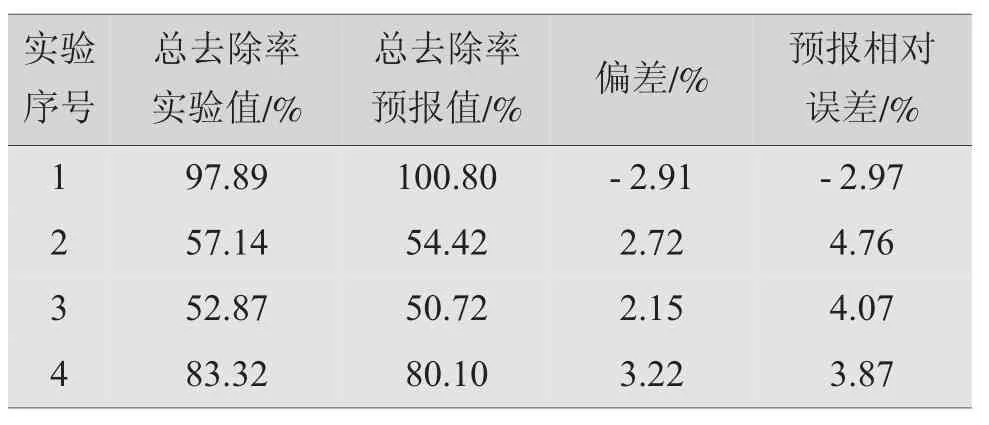
表6 随机验证试验的预报结果及误差
由表6中的预报偏差δ可以求得预报的标准误差:
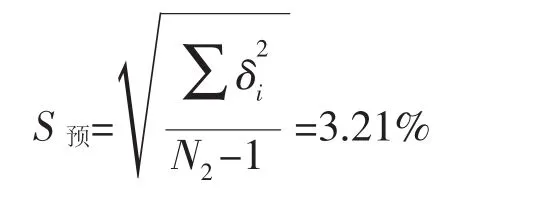
从工程应用的角度来说,表5中预报相对误差小于5%,可以接受。模型各项统计量均表明模型具有显著的统计意义。
三、Logistic转换处理
在第十八讲“关于统计模型稳定性的分析评估”一文中,结合甲醇汽油腐蚀抑制剂配方筛选案例,介绍了Logistic转换处理的成功应用。详细的转换、逆转换过程可参见该文。
在DPS软件中,对实验测定的响应值是0~100的百分数,在直接用响应值建模时,可能出现预报优化极大值大于100%、极小值小于0%的现象,这是明显不合理、违背常识的。对此,DPS作者建议,对百分率资料进行建模、优化分析前应对响应值Y进行Logistic转换,公式是:
Y'=ln[Y/(1-Y)]
DPS软件提供了专用的Logistic转换函数lgic(Y)及逆转换函数algic(Y')。应用了此转换处理,建模优化就不会出现大于100%或小于0%的现象。
《DPS数据处理系统——实验设计、统计分析及数据挖掘》专著中没有展开讨论,为什么经过Logistic变换后,建模优化就不会出现大于100%或小于0%的反常现象呢?
主要原因是逆转换algic(Y')函数是在Y为0~100%之间的曲线,Y=0与Y=100%是平行的两条渐近线。所以转换后,根据Yi'拟合得到的统计模型,预报Ymax'或Ymin'逆变换后的Ymax或Ymin受到两条渐近线约束。
对Y'进行algic变换得到Y,在DPS上计算结果如下所示:
Y' Y
-8 0.000 335
-6 0.002 473
-4 0.017 986
-2 0.119 203
-1 0.268 941
0 0.500 000
1 0.731 059
2 0.880 797
3 0.952 574
4 0.982 014
5 0.992 207
6 0.997 527
8 0.999 665
在Excel表格中画图得到如图1所示的曲线。
采用Logistic转换的方法对实验结果进行转换,见表7。
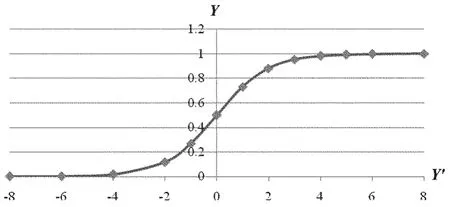
图1 algic变换曲线图
再采用二次多项式逐步回归计算对12组均匀实验数据建立回归方程,结果如下:
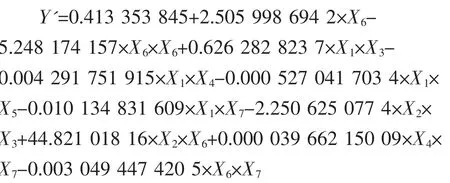
方差分析结果如下:
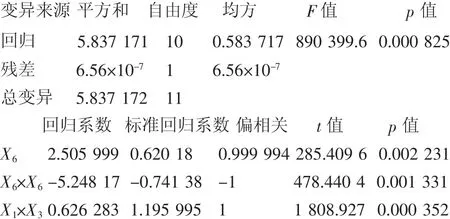
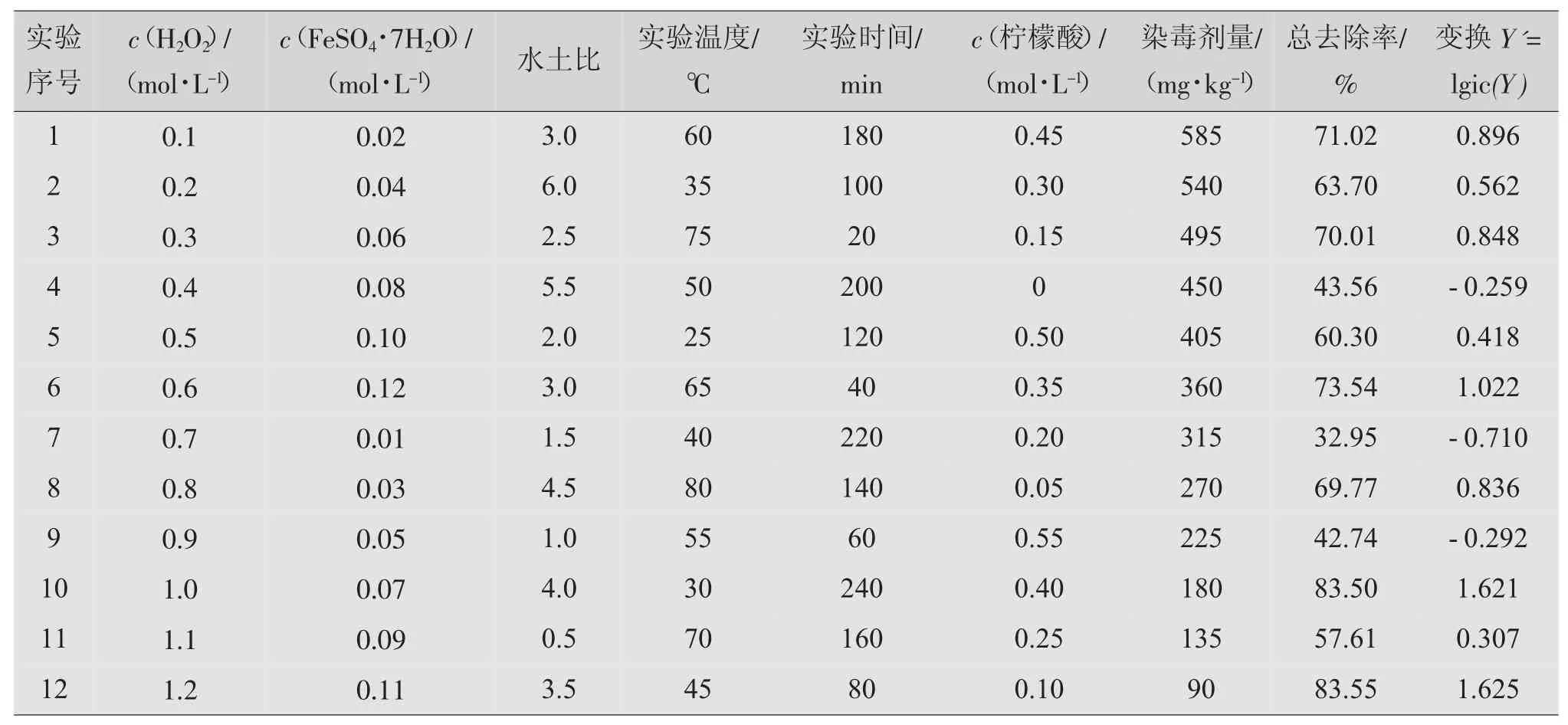
表7 12组均匀设计实验结果及变换
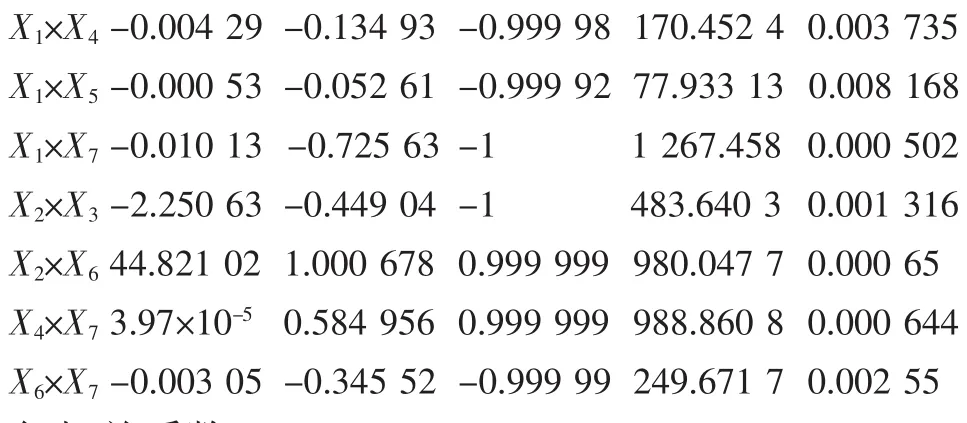
复相关系数R=0.999 999
决定系数R2=0.999 998
剩余标准差SSE=0.000 8
Durbin-Watson统计量d=2.333 0
调整相关系数Ra=0.999 989
调整决定系数Ra2=0.999 978
样本观察值 拟合值 拟合偏差 相对误差/%
1 0.896 0.895 784 0.000 216 0.024 105
2 0.562 0.562 519 -0.000 52 0.092 279
3 0.848 0.847 964 3.61×10-50.004 252
4 -0.259 -0.258 97 -3.1×10-5-0.012 1
5 0.418 0.418 012 -1.2×10-50.002 807
6 1.022 1.021 832 0.000 168 0.016 452
7 -0.71 -0.710 33 0.000 33 -0.046 44
8 0.836 0.836 259 -0.000 26 0.030 997
9 -0.292 -0.291 97 -2.6×10-5-0.009 02
10 1.621 1.621 093 -9.3×10-50.005 761
11 0.307 0.307 135 -0.000 13 0.043 878
12 1.625 1.624 675 0.000 325 0.020 022
最高指标时各个因素组合:
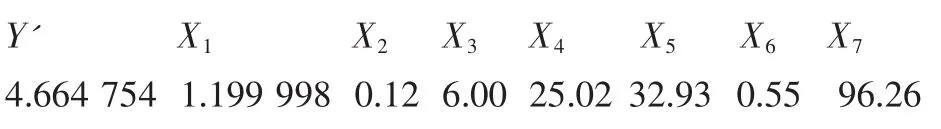
对响应值逆变换为algic(4.664 754)=99.067 1%,结果正常。
对2组补做实验和4组随机试验的预测结果如表8所示。
模型的各项统计量均表明模型具有显著统计意义。
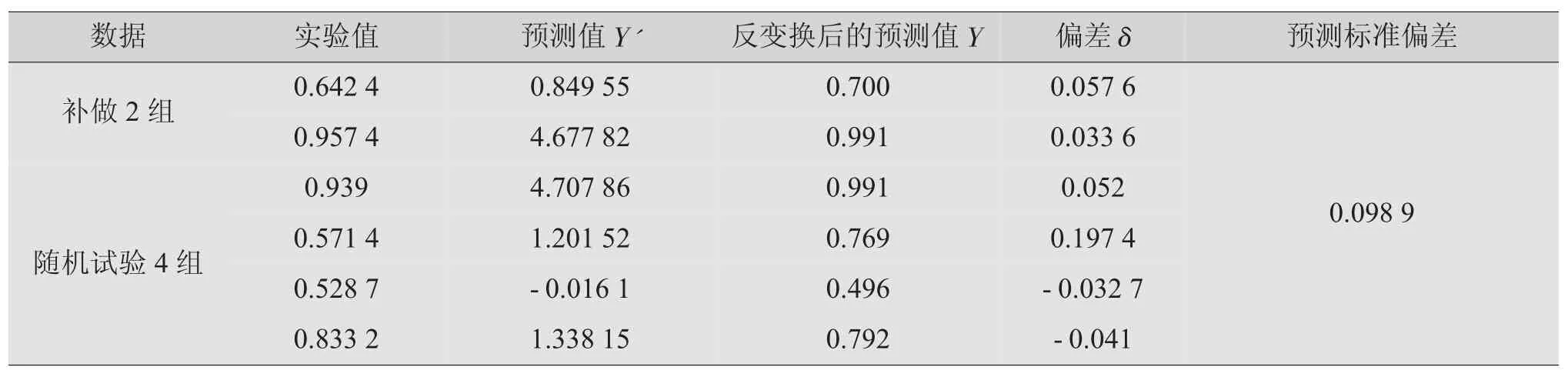
表8 对补做实验和随机试验的预测结果
四、支持向量回归(SVR)处理
原文样本率N1/M=12/7=1.71,属于小样本问题,讲义“支持向量机SVM简介及DPS应用操作”和“SVR对小样本缺失数据的挖掘处理”将作相应介绍,此处限于篇幅不再展开。
采用支持向量回归算法对12组均匀实验数据(作为训练集)进行建模,预测2组补做实验和4组随机试验(作为测试集)。计算时默认ε-SVR回归,核函数类型默认RBF核函数,设置参数取Gamma=0.04(σ=3.7),Cost=5,计算结果如下:
支持向量机类型:EPSILON-SVR
核函数类型:RBF
参数设置:
Degree=3
Gamma=0.04
Coef0=0.001
Eps=0.001
C=5
nu=0.5
shrinking=1
p=0.01
probability=1
支持向量机系数:
项目 rho Prob.
Const -0.875 4 0.362 51
α15.000 0 …… 4.012 7
SV1-1.000 0……1.000 0
SV2-0.818 2……0.818 2
SV3-0.090 9……0.090 9
SV40.272 7 ……-0.272 7
SV50.454 5 ……-0.454 5
SV60.636 4 ……-0.636 4
SV71.000 0 ……-1.000 0
样本序号 观察值 拟合值 拟合偏差
1
0.710 2 0.676 9 0.033 3
2 0.637 0 0.642 1 -0.005 1
3
0.700 1 0.694 9 0.005 2
4
0.435 6 0.591 0 -0.155 4
5
0.603 0 0.597 8 0.005 2
6
0.735 4 0.740 6 -0.005 2
7
0.329 5 0.375 9 -0.046 4
8
0.697 7 0.692 5 0.005 2
9
0.427 4 0.487 8 -0.060 4
10 0.835 0 0.731 8 0.103 2
11 0.576 1 0.581 4 -0.005 3
五、处理结果汇总分析
原文案例响应值为PAHs去除率,对应采取Logistic转换处理;原文案例的样本率N1/M=12/7=12 0.835 5 0.830 5 0.005 0
相关指数R=0.944 58
决定系数=0.892 23
支持向量机预测结果见表9。
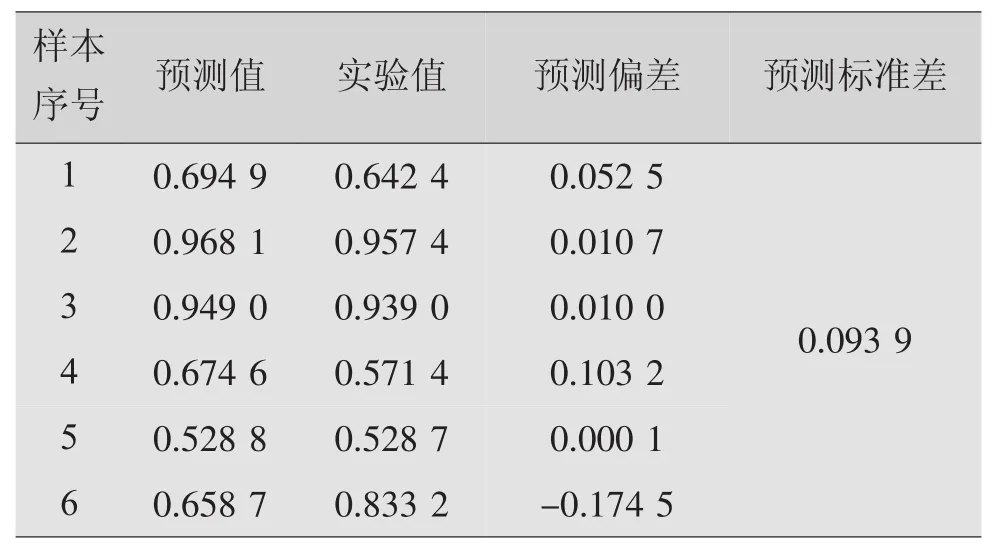
表9 支持向量机预测结果
1.71,属于小样本问题,又对应采取SVR处理,结合原文采取的二次多项式逐步回归处理进行预报质量的汇总比对,结果见表10。

表10 三种方法处理结果汇总及对比
(1)对于同一批实验数据,应用不同的数据处理方法,获得不同的统计模型及预报质量,都是对研究对象探寻真实规律的近似逼近,可根据研究目的评估选择相应的处理方法。
(2)Logistic转换主要用于Y为百分数统计建模后求取响应值Ymax或Ymin,本案例的开发目的是求取预报功能好的统计模型,该处理方法在本案例中没有显示优势。
(3)SVR主要用于低样本率的小样本、二次多项式拟合效果不够好的统计建模,在本案例的应用中,也没有显示其优势。
(4)二次多项式逐步回归是当前统计建模、优化、预报控制的主体处理技术之一,但对样本率相对要求较高,在本案例应用中,修整补充实验后,统计模型有显著意义,预报功能也是好的。
后记:
李森博士、张杨硕士进入上海化工研究院后的第一个研发项目就勇敢地学习探索新知识、新方法,研发项目顺利验收,相关项目又获市纵向支持,论文在学报上发表得到社会认可。而吴芳硕士又用不同处理方法进行了比对计算,探索了不同方法的特点、优势。
对此,笔者重抄1981年2月在《实验误差估计与数据处理》藏书上对于自学新知识的自勉词:成功的可能固然难以预测,但如果不去探索,成功的可能却就是零。
