基于循序I型删失数据的广义Pareto分布最优删失计划
2018-01-22程从华程丽娟
程从华,程丽娟
(1. 肇庆学院 数学与统计学院,广东 肇庆 526061;2. 岭南师范学院 数学与统计学院,广东 湛江524048)
广义Paretto分布最早由Pickands提出[1].随机变量X服从广义Pareto分布,如果它的概率密度函数(PDF)为
(1)
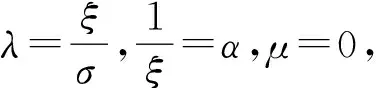
f(x;α,λ)=αλ(1+λx)-(α+1).
(2)
对应的分布函数为:
F(x;α,λ)=1-(1+λx)-α,x,α,λ>0.
(3)
广义Pareto模型在极端事件分析中有着广泛的应用.比如,保险分析中的大额报单索赔问题以及可靠性分析中的失效时间建模问题都可以利用广义Pareto模型来进行建模分析. Harris研究了保修服务时间决策问题[2]. Davis和Feldstein利用广义Pareto模型研究了循序删失情形下的等效元件失效时间问题[3]. Hosking和Wallis研究了广义Pareto模型的参数和分位数估计问题[4]. Smith研究了非正则条件下的分布族参数最大似然估计问题[5]. Liang基于非参数经验贝叶斯方法讨论了广义Pareto分布的尺度参数估计问题[6]. Nigm等在两样本和随机样本容量条件下讨论了广义Pareto分布未知参数的贝叶斯区间估计问题[7].Wu等在循序删失数据情形下研究了广义Pareto分布参数的区间估计问题[8].
寻找最优删失计划是一个近年来受到广泛关注的问题.在循序删失情形下,本文首先讨论广义Pareto分布未知参数的最大似然估计问题,并且给出广义Pareto模型在循序删失条件下的期望Fisher信息矩阵.其次利用期望Fisher信息矩阵,在三种不同准则下,讨论最优删失计划的设计问题.在寿命分析实验中,大多数寿命实验还会受到实验经费预算的约束.近几年来许多学者也对此进行了研究,比如:Tse等[9],Chen等[10]和 Wu等[11]. 在实验经费不超过给定数额条件下,讨论循序删失计划的最优设计问题. 针对循序I型区间删失特点,主要考虑三个问题,分别是如何确定参与寿命分析实验的元件个数,观测区间个数以及实验检测区间长度.最后给出完成寿命测试实验的一个具体算法,并且通过一个具体实例来演示本文的方法.
1 期望信息矩阵
为了计算未知参数的Fisher信息,需要以下的一些预备知识[12].
Xi|Xi-1,Xi-2,…,X1,Ri-1,Ri-2,…,R1~B(Mi,qi),
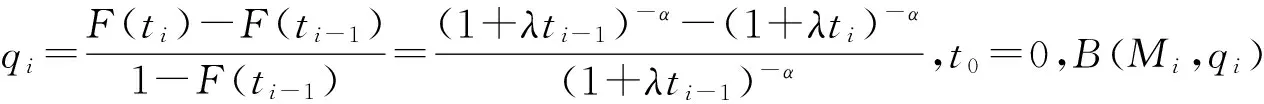
E(M1)=n,E(R1)=np1(1-q1),E(Xi)=E(Mi)qi,i=1,2,…,m,
利用以上结论,可以得到期望Fisher信息矩阵E,且E可以表示为:
(4)
这里
(5)
2 最优删失计划设计
2.1 算法设计
在实验成本约束条件下,这一小节讨论最优的实验设计问题.利用Ng等定义的如下三个最优准则来进行实验设计[13].
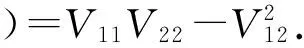
(2)T-最优:最小化协方差矩阵的迹,tr(V(α,λ))=V11+V22.
(3)F-最优:最大化参数最大似然估计期望Fisher矩阵的迹,tr(E(α,λ))=E11+E22.
假定相邻的观测区间长度差都等于给定的长度t,同时假定有n个元件投入寿命测试实验,有m个观测时刻点,第i个观测区间的时间长度为it,i=1,2,…,m.同时假设以下实验设计参数.
(a) 样本成本:令Cs是每一个参与测试的元件价格,则样本总成本为nCs.
(b) 检测成本:令Ci是每一个参与测试的元件检测成本,则总检测成本为mCi.

因此,寿命测试实验的总成本是:
显而易见的是,每个实验准则都是n,m,t的函数,记为G(n,m,t).当实验总成本是给定参数Cb时,则约束条件变为:
(6)
因此,这个实验的最优设计可以表述为:
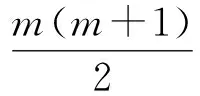
(7)
其中,N是正整数.
可以看到目标函数和约束条件都是非线性函数. 下面将利用非线性混合规划方法求解上述目标函数.非线性规划问题由Kamat和 Mesquita首先提出[14].关于非线性混合规划方法比较全面的知识可以参考Grossmann的介绍[15]. 对本文涉及的目标函数和具体问题,主要参考Taha的方法[16]. 基于上述介绍,给出如下算法.
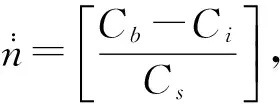
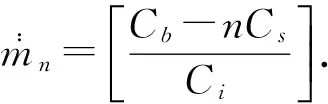
(Ⅳ)对于给定的n,计算函数G(n,m,tmn)的值.
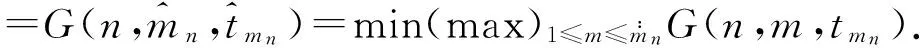

(Ⅶ)计算最优函数G(n,m,tmn)的值,这里的

则(n*,m*,t*)就是我们寻找的最优删失计划.
2.2 演示实例
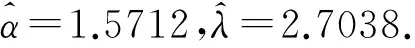
min imize(max imize)G(n,m,t),
subject to 10n+5m+m(m+1)t≤600,n,m∈N,andt>0.
利用上节给出的算法,可以获得最优删失计划如下.
D-最优:n*=55,m*=9,t*=0.0556.
T-最优:n*=54,m*=11,t*=0.0379.
F-最优:n*=56,m*=6,t*=0.2381.
通过数值实验结果,可以发现无论是D-最优,T-最优还是F-最优,本文给出的方法均是可以实现的.但各方案实现的具体结果有所差异,其中D-最优方案和T-最优方案在结果上更为相近,F-最优方案则有较大差异.这一结果并不令人意外,因为F-最优方案利用的是期望Fisher信息矩阵,而D-最优方案和T-最优方案使用同一个协方差矩阵.因此在实践中,在小样本情形时,建议使用D-最优方案和T-最优方案,反之使用F-最优方案.
[1] Pickands J. Statistical inference using extreme order statistics[J]. The Annals of Statistics, 1975, 3(1): 119-131.
[2] Harris C M. The Pareto distribution as a queue discipline[J]. Operations Research, 1968.16(2): 307-313.
[3] Davis H T, Feldstein M L. The generalized Pareto law as a model for progroressively censored survival data[J]. Biometrika, 1979, 66(2): 299-306.
[4] Hosking J R M,Wallis J R. Parameter and quantile estimation for the generalized Pareto distribution[J]. Technometrics, 1987, 29(3): 339-349.
[5] Smith R L. Maximum likelihood estimation in a class of nonregular cases[J].Bimetrika, 1985, 72(1): 67-90.
[6] Liang T C.Convergence rates for empirical Bayes estimation of the scaleparameter in a Pareto distribution[J]. Computational Statistics & Data Analysis , 1993, 16(1): 35-45.
[7] Nigm A M, Al-Hussaini E K, Jaheen Z F. Bayesian two-sample predictionunder the Lomax model with fixed and random sample size[J]. Journal of Applied Statistics, 2003, 37(6): 527-536.
[8] Wu S F. Interval estimation for the Pareto distribution based on the progressive type II censored sample[J]. Journal of Statistical Computation and Simulation, 2010, 80(4):463-474.
[9] Tse S K, Yang C, Yuen H K. Design and analysis of survival data underan integrated type II interval censoring scheme[J]. Journal of Biopharmaceutical Statistics, 2002, 12(3): 333-345.
[10] Chen J W, Li K H, Lam Y. Bayesian single and double variable sampling plans forthe Weibull distribution with censoring[J]. European Journal of Operational Research, 2007, 177(2): 1062-1073.
[11] Wu S J, Huang S R. Optimal progressive group-censoring pans for exponential distribution in presence of cost constraint[J]. Statistical Papers, 2010, 51(2):4 31-443.
[12] Aggarwala R. Progressive interval censoring: some mathematical results with applications to inference[J]. Communications in Statistics-Theory and Methods, 2001, 30(8): 1921-1935.
[13] Ng H K T, Chan P S, Balakrishnan N. Optimal progressive censoring plan for the Weibull distribution[J]. Technometrics, 2004, 46(6): 470-481.
[14] Kamat M P, Mesquita L.Nonlinear mixed integer programming[M]// Adeli H.Advanced in design optimization. London:Chapman & Hall Press, 1994.
[15] Grossmann I E. Review of nonlinear mixed-integer and disjunctive programming techniques[J]. Optimization and Engineering, 1965, 3(3): 227-252.
[16] Taha H A. Operations research: an introduction[M]. 5th ed.New York:Macmillan Press, 1992.
[17] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society:Series B, 1977, 39(1): 1- 38.
