一种改进的Supervised-LDA文本模型及其应用
2018-01-18,
,
(兰州财经大学 统计学院,兰州 730020)
0 概述
随着计算机技术的不断发展,各式各样的文本数据大量产生。据相关统计资料显示,社交网站Twitter每天新出现推文数量达到5亿条[1]。传统的文本分析方法是基于词典对文档进行分类,但是在数据量庞大的现今社会,这种方法无法完成数据的降维和分析数据潜在的语意[2],因此不能满足人们的需求。随着大数据技术的发展,文本分类方法结合计算机技术开始逐渐受到广大学者的关注。如何从海量信息中提取有用的文本数据成为目前数据分析的迫切需求,这一现实问题也促使了文本分类技术的不断发展[3]。
目前,文本分析的主流方法主要有基于规则和基于统计这两大类[4-5]。但是,网络文本具有表达方式多样、表达形式不规范等特点,以及基于规则的分析方法在规则的总结和制定上成本高,耗时长,并且不具有良好的可扩展性。因此,在海量网络文本作为数据基础的背景下,越来越多的学者倾向于采用基于统计的方法。统计方法的基本思路是挖掘文本的主题信息,典型代表有隐语义索引(LSI)方法及其概率化的PLSI[6]。LSI方法在文本分类中的应用得到了深入的研究,尽管其降维作用较为显著,但是分类精度较低。另外,这类模型的参数空间和训练数据呈正比,不利于对大规模或动态增长的语料库进行建模。文献[7]提出的带标签的有监督LDA(sl-LDA)模型是基于L-LDA模型进行的改进,并对L-LDA模型存在的不足提出改进,提高了模型的分类精度。本文提出的带标签的有监督隐狄里克雷分配模型(sl-LDA)是在文献[8]提出有监督的LDA(s-LDA)主题模型基础上进行的改进。由于s-LDA模型存在特殊类别标记方式,在进行分类时不能够处理多标签问题[2],并且s-LDA模型在分类时还存在主题未正确分配的问题。
为解决s-LDA模型存在的上述问题,本文在s-LDA模型基础上加入类别标签,并对改进模型进行实验验证。
1 相关工作
LDA模型是文献[9]提出的一种概率生成模型,它的基本出发点是认为文档是一个词包(bag of word)的集合,即认为文档是词的集合,忽略任何语法或者词汇出现的顺序关系。而且LDA模型的参数空间不会随着训练文档数量增加而增加。因此,它具有优良的语义挖掘和主题分析能力,尤其适用于含有大量文档数据的挖掘分析。文献[10]的研究表明,在文本分类上面LDA模型的分类效果表现并不突出。因此,LDA模型在主题分类精度上有不足之处。
目前,人们对LDA模型提出较多改进的应用模型[11-17]。一些无监督LDA模型、有监督LDA模型相继被提出。
文献[18]提出基于带标签的LDA(L-LDA)模型,在传统的LDA模型基础上加入标签因素,从而解决LDA强制分配隐主题的问题。但是加入类别信息,必须考虑到标签与主题之间的联系,L-LDA模型定义了主题和类别标签之间一一对应的关系,并将每一个文档分配到预先定义的标签集合,这种方式使得该模型缺乏处理潜在类别标签以及含有共同语义文档的机制,同时在含有最小基数的文本集合中分类效果不佳[7]。为了改变主题和类别标签之间一一对应的关系,文献[2]提出用于多标签分类的改进Labeled LDA模型,对文档加入文档类别、作者等信息。该模型在文档类别判定过程中通过联合独享主题和共享主题对类别进行预测,从而提高了多标签主题分类的精度。从文档内容方面考虑,文献[19]提出连续的LDA(SeqLDA)模型,该模型基于文档内容的兴趣点等进行分析,此外采用分层双参数泊松-狄里克雷分布进行建模,表现出良好的分类精度。
为了提高LDA模型的分类精度,文献[8]提出有监督的LDA主题模型(s-LDA)。该模型通过对文档类别标记将对应的连续变量映射为由主题混合方式产生的响应变量来实现文档的类别判定和连续数据的回归分析,并构造响应变量分析潜在主题。
基于以上描述,考虑到对LDA模型改进主要是加入标签因素以及进行有监督或者无监督建模的优点和缺点,本文基于s-LDA模型提出带标签的有监督的隐狄里克雷分配(sl-LDA)模型。
2 sl-LDA主题模型
2.1 s-LDA主题模型存在的问题
文献[9]提出的s-LDA模型是一种有监督的主题模型分类方法。与传统LDA模型不同的是,s-LDA模型对LDA模型中的每一个文档加入响应变量,这个变量可以适应许多变量类型。举例来讲,变量是某部电影中明星的数量,也可以是论坛用户对某一篇文章中访问次数的统计[8]。而且s-LDA模型改进了lasso回归方法,可以进一步提高分类的精度。s-LDA图模型如图1所示。
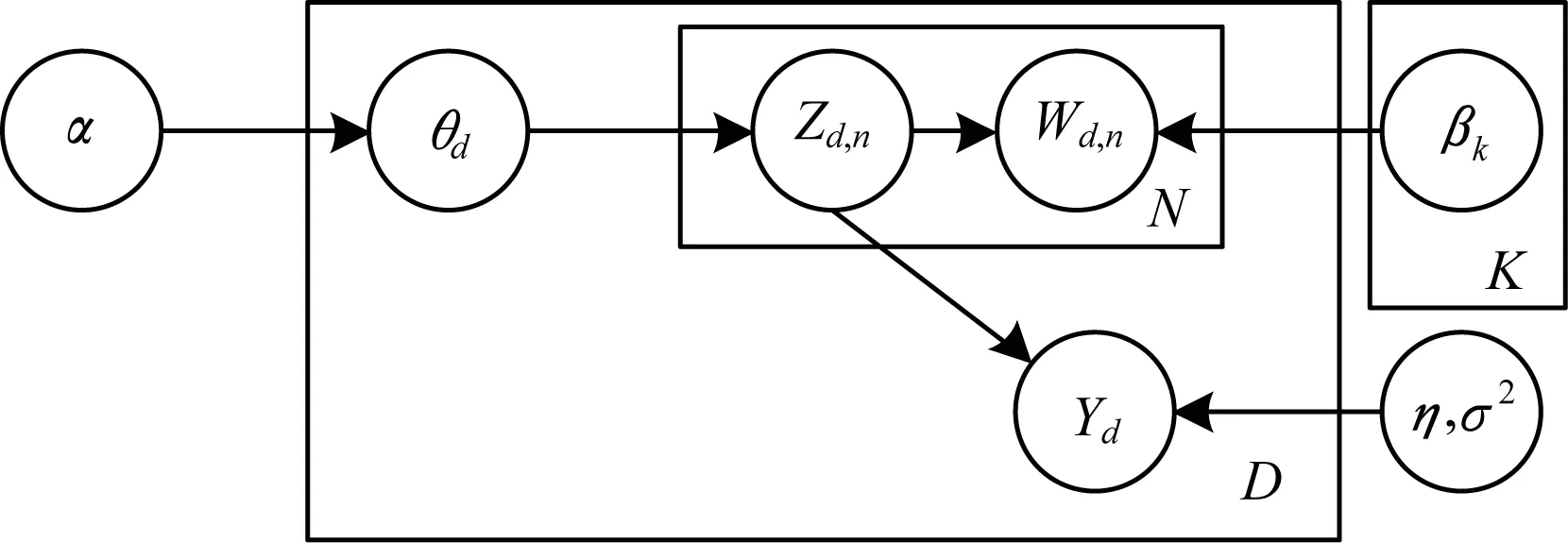
图1 s-LDA图模型
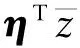
文献[9]提出的s-LDA模型在LDA模型的基础上加入响应变量,而且s-LDA模型改进了lasso回归方法。然而s-LDA模型对文档进行主题分配过程中存在一些问题:一方面,只能处理含有一个类别标记的文档[2];另一方面,从实验分析角度看,s-LDA模型在进行主题分配时,部分主题未进行正确分配,从而导致了文档分配主题精确度下降。
2.2 sl-LDA主题模型的改进
鉴于s-LDA模型存在的问题,本文对s-LDA模型进行改进,从而尝试解决s-LDA模型在进行主题分配时,部分主题未进行正确分配的问题。本文在s-LDA模型基础上加入标签因素,提出带标签的有监督的隐狄里克雷分配(sl-LDA)模型。该模型对s-LDA模型主题层与文档层的映射关系进行了改进,通过加入类别标签降低主题被错误分配的可能性,提高了分类的精确度。同时加入类别标签也可以提高文本分类的性能[18]。在第3节对本文的模型进行实例验证,并与s-LDA模型比较。从比较结果来看,本文的模型能够提高文本分类精确度。
具体来讲,在对文档中主题进行分类时,若所分配的主题存在于训练过程中所选择的主题,则保留该主题,否则抛弃。即在分配主题时加入狄拉克函数δ(x),该函数在x=0时函数值为1,在x≠0时函数值为0。为此,本文的sl-LDA图模型形式如图2所示。
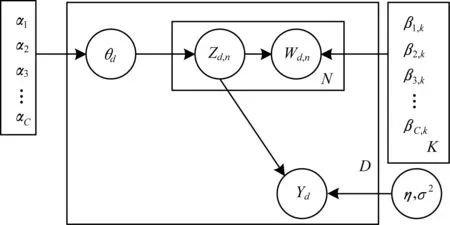
图2 sl-LDA图模型
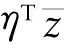
参数的分布表示形式如下:
1)对于每个主题θ有θ|αl~Dirichlet(αl)(l=1,2,…,C)。
2)对于每个词w中的主题z有zn|θ~Multnormal(θ)。
3)对于每个词w有wn|zn,βl,1∶K~Multnormal(β)(l=1,2,…,C)。
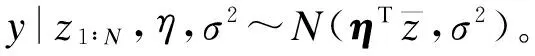
s-LDA模型的概率模型为:
(1)
通过最大化证据下界l(g)构造变分函数,对于每一个文档有:
logap(w,y|α,β)≥(γ,φ,α,β)=

E[logap(y|Z1∶N)]+H(q)
(2)
其中,q表示变分分布函数,且:
(3)
其中,γ为变分Dirichlet参数。
E步:
由式(1)~式(3)得到:
[logap(y|Z1∶N)]=
(4)
其中:
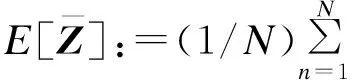
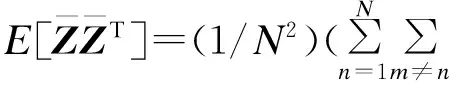
由式(2)可知,变分Dirichlet参数γ与响应变量y无关,对式(4)采用坐标上升法[8]得到:
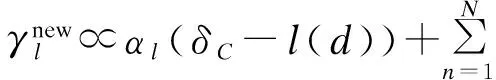
(5)

φl,j∝exp(E[logaθ|γ]+
E[logap(wj|βl,1∶K)(δC-l(d))]+
(6)
M步:
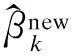
(7)
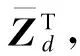
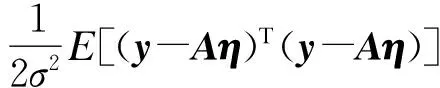
(8)
利用E步选择的变分分布参数,求矩阵A的期望,通过扩展内积,利用线性期望和η的一阶条件,可以得到:
E[ATA]=E[A]Ty⟹
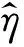
(9)
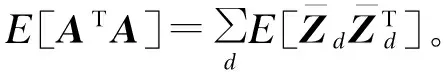
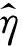
(10)
本文在参数估计E步中,在s-LDA模型参数估计的基础上对参数γnew和φj分别加入类别标签c,并使用狄拉克函数δ(x)。具体而言,当文档集合上隐主题与文档类别匹配时,δC-l(d)的值为1,否则为0,这使得s-LDA模型对训练主题进行分配时主题未正确分配这一问题得以改善。在M步估计中,由于β=(β1,β2,…,βC),则对β的估计与s-LDA模型也不同,加入类别标签后,文档中的词在进行主题选择时会有区别地选择主题。比如“引力波”这个词,它会倾向于选择“科技”这类主题。对“引力波”加入类别标签“科技”,可以使其更准确地选择正确的主题,从而改善文本主题分类的精度。
3 应用示例
3.1 实验
为验证sl-LDA模型的分类精度,本文使用复旦大学中文新闻语料库和英文新闻语料库进行实验。其中中文新闻语料库包含2 815篇文章,共10个主题;英文新闻语料库包含18 744篇文章,共20个主题。汇总结果如表1~表3所示。
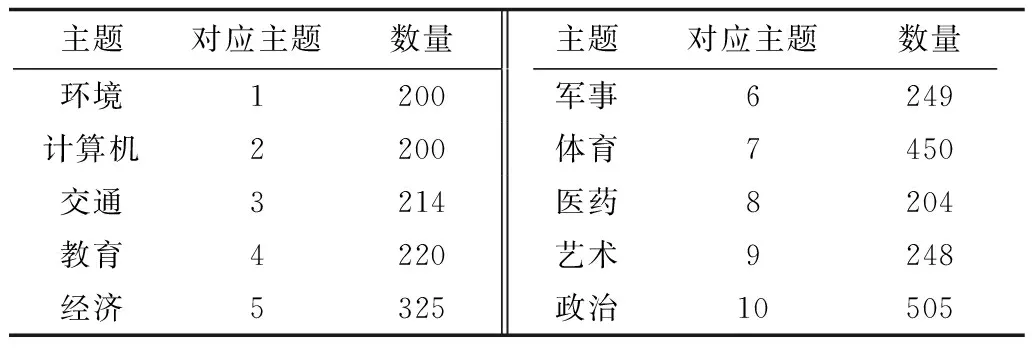
表1 中文新闻语料库
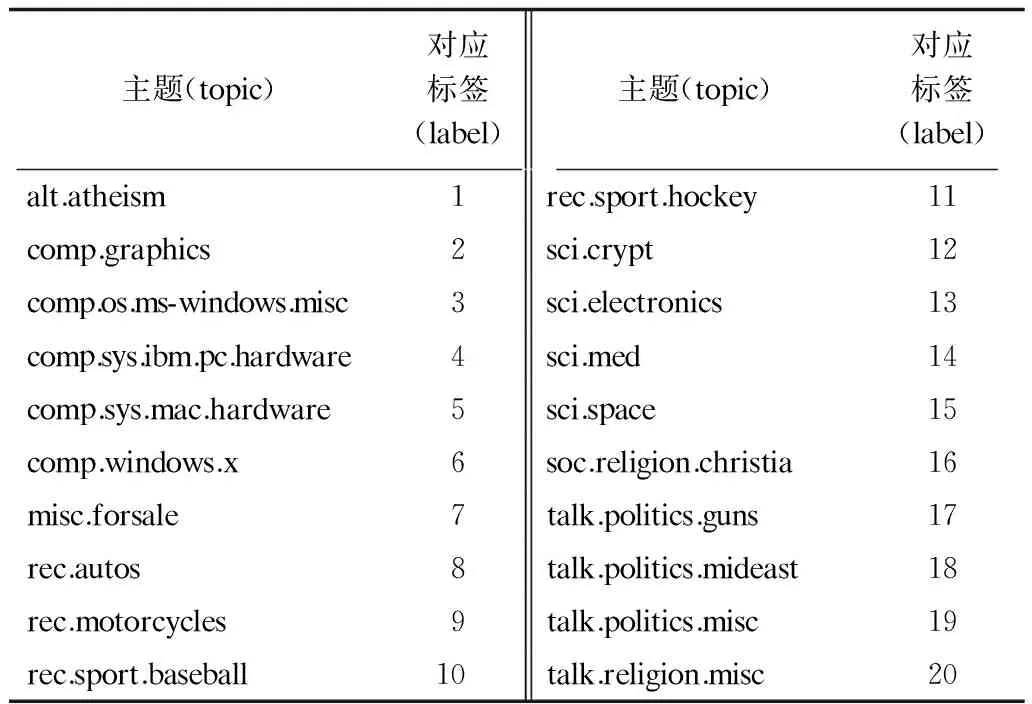
表2 英文新闻语料库
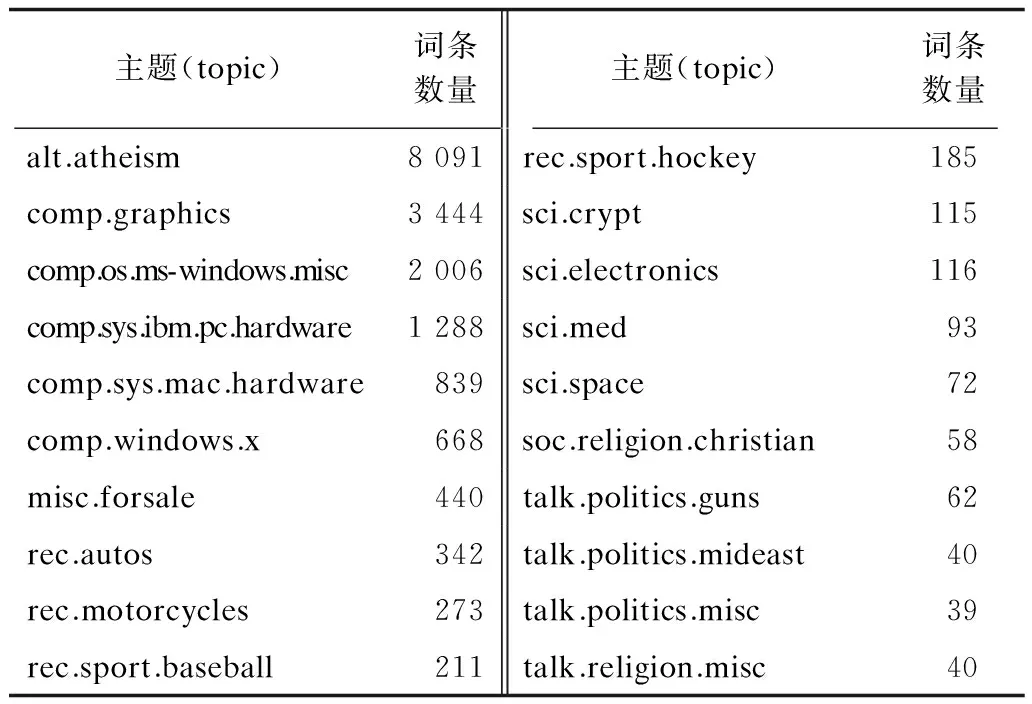
表3 英文新闻语料库词条统计
本文利用R语言中的LDA包和topicmodels包对数据进行建模。首先对原始语料库进行数据清洗,为了便于建模,本文在建模过程中利用正则表达式进行数据的预处理。数据清洗完成后,利用R语言中的rJava、Rwordseg包对每一篇文档进行分词和词频统计,统计部分结果见表4,最后依据新闻语料库中的主题类型对每个词进行分类。

表4 中文新闻词频统计结果(部分)
本文从中文新闻语料库抽取75%作为训练集,25%作为测试集进行实验。实验分两组进行,采用的模型分别是s-LDA模型和sl-LDA模型,参数估计方法采用变分EM算法。本文利用建立混淆矩阵(confused matrix)[20]的方法来计算s-LDA模型和sl-LDA模型的精确度。
3.2 实验结果
分词过程完成后,本文利用R语言对这2个模型进行编程,并改变迭代次数以分别统计每次迭代混淆矩阵计算的精确度。s-LDA模型与sl-LDA模型中文新闻语料库迭代次数对比结果见表5,模型迭代次数对比见图3,其中,横坐标表示迭代次数,纵坐标表示精确度。sl-LDA模型与sl-LDA模型英文新闻语料库迭代次数对比结果见表6,模型迭代次数对比见图4,其中,横坐标表示迭代次数,纵坐标表示精确度。从图3和图4的结果可以看出:在迭代次数相同情况下,sl-LDA模型的预测精确度高于s-LDA模型的预测结果,随着迭代次数的增加,两者的预测精度趋于近似。
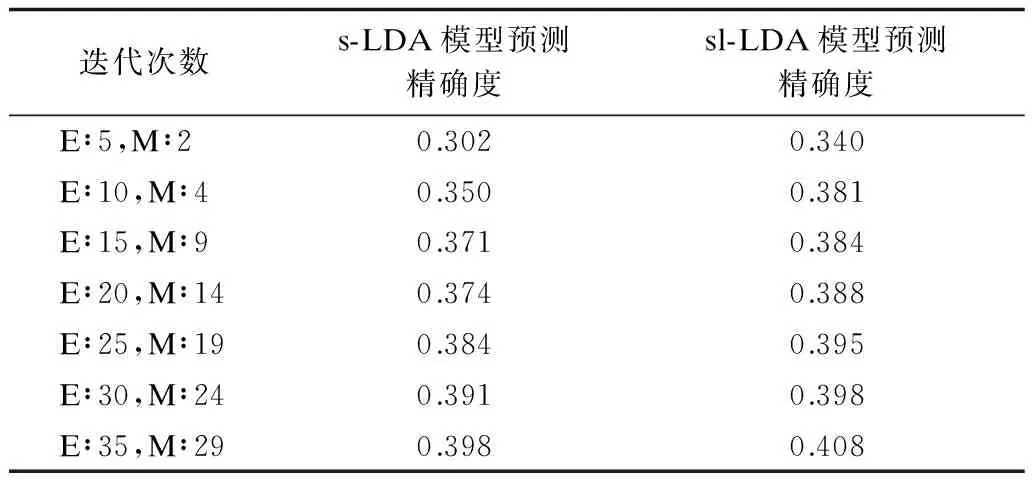
表5 中文新闻精确度对比
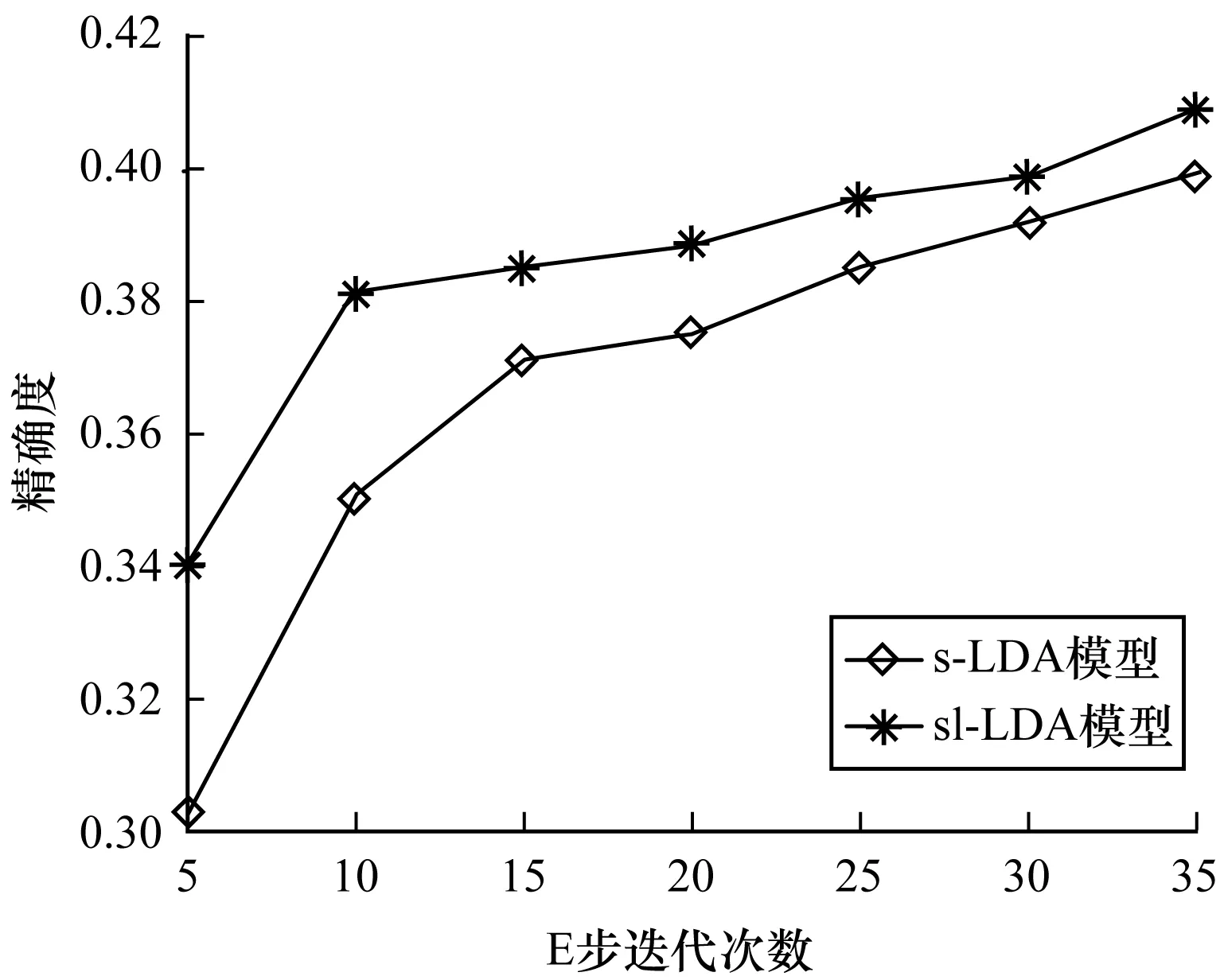
图3 中文新闻模型精确度对比
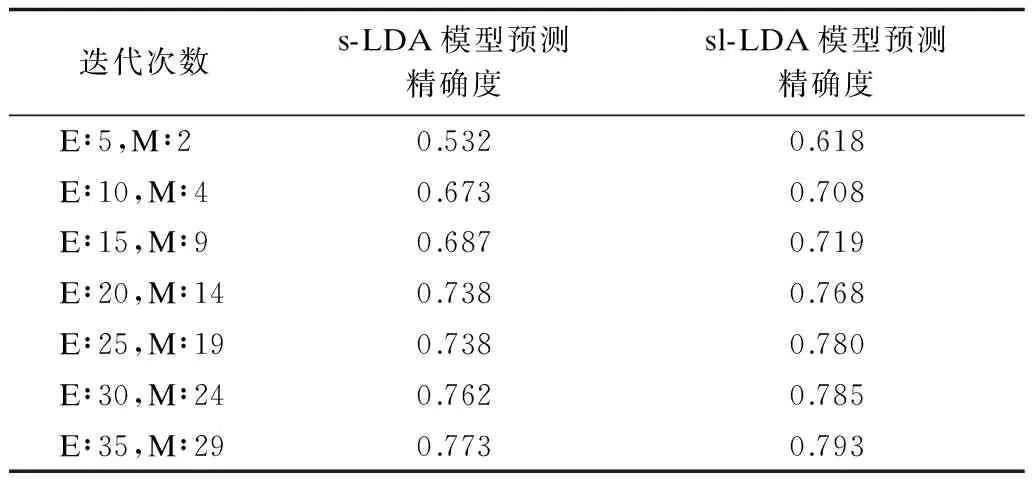
迭代次数s-LDA模型预测精确度sl-LDA模型预测精确度E∶5,M∶20.5320.618E∶10,M∶40.6730.708E∶15,M∶90.6870.719E∶20,M∶140.7380.768E∶25,M∶190.7380.780E∶30,M∶240.7620.785E∶35,M∶290.7730.793
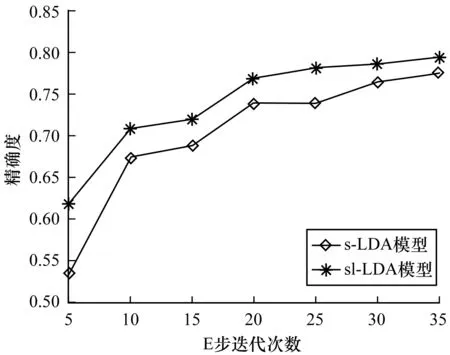
图4 英文新闻模型精确度对比
从图3中的中文新闻语料库和图4中的英文新闻语料库的对比分析看出,本文提出的sl-LDA模型与s-LDA模型相比,在迭代次数相同的情况下,精确度要优于s-LDA模型。随着迭代次数的增加,两者分配精度都有所提升,但是本文提出的sl-LDA模型依然保持较好的分配精度。这说明在有监督的情况下,相对于未加入标签因素,加入标签因素在模型分类精度上有所提升。针对s-LDA模型在对主题进行分配过程中只能处理含有一个类别标记的文档[2]及通过s-LDA模型分配的部分主题不存在于训练过程中所选择的主题,从而导致了对文档分配主题精确度下降等问题。本文提出的sl-LDA模型通过增加类别信息来解决这些问题。为了验证模型的主题分类精度,本文分别就中文新闻语料库和英文新闻语料库进行主题分类实验,并通过建立混淆矩阵来计算每次迭代下模型的分类精确性。从上文的实验结果来看,在中文和英文新闻语料库的对比实验中,英文新闻语料库分类精度提高了约3.80%,中文新闻语料库分类精度提高了约1.77%。
4 结束语
本文针对s-LDA模型在主题分配过程中只能处理含有一个类别标记的文档[2]及s-LDA模型部分主题未进行正确分配,从而导致文档分配主题精确度下降的问题,提出一种带标签的有监督的隐狄里克雷分配(sl-LDA)模型。首先介绍s-LDA主题模型的分类方法,随后分析了s-LDA主题模型存在只能处理含有一个类别标记文档等问题。为验证模型的主题分类精度,本文分别对中文新闻语料库和英文新闻语料库进行主题分类实验,并通过建立混淆矩阵计算每次迭代下模型的分类精确性。实验结果表明,在中文和英文新闻语料库的对比实验中,英文新闻语料库分类精度提高了约3.80%,中文新闻语料库分类精度提高了约1.77%。下一步将研究改进s-LDA模型对其他类型文本的分类效果,在无监督学习下,分析主题模型的分类精度并与本文的改进模型进行对比。
[1] SEBASTIANI F.Machine Learning in Automated Text Categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[2] 江雨燕,李 平,王 清.用于多标签分类的改进Labeled LDA模型[J].南京大学学报(自然科学版),2013,49(4):425-432.
[3] STEYVERS M,GRIFFITHS T.Probabilistic Topic Models[J].Handbook of Latent Semantic Analysis,2007,427(7):424-440.
[4] MEDHAT W,HASSAN A,KORASHY H.Sentiment Analysis Algorithms and Applications:A Survey[J].Ain Shams Engineering Journal,2014,5(4):1093-1113.
[5] TANEJA H,DHURIA S.A Survey on Sentiment Analysis and Opinion Mining[J].Journal of Emerging Technologies in Web Intelligence,2013,5(4):53-65.
[6] DEERWESTER S,DUMAIS S T,FURNAS G W,et al.Indexing by Latent Semantic Analysis[J].Journal of the American Society for Information Science,1990,41(6):391-407.
[7] LI Ximing,OUYANG Jihong,ZHOU Xiaotang,et al.Supervised Labeled Latent Dirichlet Allocation for Document Categorization[J].Applied Intelligence,2015,42(3):581-593.
[8] BLEI D M,MCAULIFFE J D.Supervised Topic Models[J].Advances in Neural Information Processing Systems,2010,3(1):327-332.
[9] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3(3):993-1022.
[10] LI W,MCCALLUM A.DAG-structured Mixture Models of Topic Correlations[C]//Proceedings of International Conference on Machine Learning.Washington D.C.,USA:IEEE Press,2006:577-584.
[11] TADDY M,GARDNER M,CHEN L,et al.A Nonparametric Bayesian Analysis of Heterogeneous Treatment Effects in Digital Experimentation[J].Journal of Business & Economic Statistics,2016,65(3):193-211.
[12] 宋钰婷,徐德华.基于LDA和SVM的中文文本分类研究[J].现代计算机,2016(5):18-23.
[13] 陈 攀,杨 浩,吕 品,等.基于LDA模型的文本相似度研究[J].计算机技术与发展,2016,26(4):82-85.
[14] 李 博,陈志刚,黄 瑞,等.基于LDA模型的音乐推荐算法[J].计算机工程,2016,42(6):175-179.
[15] 李 琮,袁 方,刘 宇,等.基于LDA模型和T-OPTICS算法的中文新闻话题检测[J].河北大学学报(自然科学版),2016,36(1):106-112.
[16] 张 亮.基于LDA主题模型的标签推荐方法研究[J].现代情报,2016,36(2):53-56.
[17] 石 晶,李万龙.基于LDA模型的主题词抽取方法[J].计算机工程,2010,36(19):81-83.
[18] 李文波,孙 乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620-627.
[19] DU L,BUNTINNE W,JIN H,et al.Sequential Latent Dirichlet Allocation[J].Knowledge & Information Systems,2012,31(3):475-503.
[20] FORBES A D.Classification-algorithm Evaluation:Five Performance Measures Based on Confusion Matrices[J].Journal of Clinical Monitoring and Computing,1995,11(3):189-206.
