基于用户行为反馈的云资源调度机制
2018-01-15艾丽华罗四维徐保民
丁 丁, 艾丽华, 罗四维, 徐保民
(北京交通大学计算机与信息技术学院, 北京 100044)
0 引 言
作为一种新兴的并行计算技术,云计算[1-3]是分布式处理、并行处理、网格计算的发展和延伸,是这些计算机科学概念的商业实现,适应当今巨型信息化处理的需求。云计算的优势在于平台能够实现资源的整合,并且可以为用户按需提供规模可变的资源,这给用户带来了极大的方便,同时也减少了资源的浪费[4-5]。如今,云计算的商业应用已成为现实。如Amazon的EC2(Elastic Compute Cloud)[6],Google的App Engine[7],IBM的Blue Cloud[8],Microsoft的Windows Azure[9]等云计算平台都已出现在市场之上。学术界也纷纷从提高物理资源利用率、优化平台和应用性能等诸多方面对云计算进行了深层次的研究。
资源调度是云计算技术的一个重要组成部分,其效率直接影响整个云计算环境的工作性能,同时也决定了云计算用户的参与和接受程度。围绕着云计算中的资源调度问题,国内外开展了一系列的研究工作,先后提出了各种调度算法。
在目前常见的开源云平台中,实现和使用的调度策略多为传统算法,如贪心算法、轮循算法、加权轮循算法等。此外,还有最小连接度及其改进算法、目标地址散列算法、源址散列算法等[10]。传统算法普遍比较简洁,通常只是单纯的寻找满足要求的物理结点运行虚拟机,一般不考虑整体的服务质量(quality of service, QoS)和资源利用率。
启发式智能算法是云计算资源调度主要采用的一类调度策略。目前,广泛应用的有基于遗传算法、模拟退火算法、粒子群算法、蚁群算法的资源调度算法,以及这些算法的改进算法[11-14]。启发式智能算法的优点是自适应并且能够较好地为NP难的资源调度问题寻找最优或近似最优解,一定程度上提高了算法的性能和资源利用率,但是算法本身和建模过程往往比较复杂,而且对于不同的问题,收敛性也会有所不同。
关于云计算环境中资源调度策略的另外一类研究来自于文献[15-16],提出了基于市场的资源定位的云计算架构和基于市场的资源调度策略,以支持服务级协商(service-level agreement, SLA)的资源定位。这种基于经济学模型的资源调度的基本思想是在资源消费者和资源提供者之间建立市场机制,并把宏观经济学和微观经济学的各种模型应用到资源调度过程中,利用价格杠杆对用户需求和资源分配进行调节,从而优化系统和提高效率。主要的调度方法包括基于一般经济模型的调度策略和用户效用驱动的调度策略[17-18]。
除以上介绍的资源调度算法之外,还有一些综合和改进的调度算法,例如,在原有的调度算法中加入优先级、QoS、信任机制等约束的算法。也有在原有算法之上改进,以提高算法的负载均衡性能,或者降低算法的能耗开销等[19]。
以上研究通过不同的方法实现云计算环境下的资源调度,即接受来自于云计算用户的资源请求,将资源池或云中满足要求的资源分配给请求者。然而,随着云计算的发展和广泛应用,云计算环境中用户的需求不断地变化,资源的种类、数量等也持续地增加,并以各种不同形式出现。面对种类日新月异、数量日益巨大的云计算资源,用户的需求表达越来越难以得到满足。除此之外,在现实的云计算环境中,当用户对云计算平台进行资源请求时,由于所面对的信息常常是不完整的、不确定的,甚至是模糊的,往往也无法精确地给出资源的种类、数量等需求,或者只能在最关注的某一方面或某几个方面提出详细的需求说明,而忽略了其他方面。这些都对云计算环境下的资源调度提出了更高、更新的要求,即如何根据当前有限的用户需求信息,探索更加有效的信息提取、过滤和分析技术以获取用户的真实目的,从而在资源调度中反馈给用户更加准确的资源。基于此,本文尝试从用户的角度出发,从用户行为的全新角度着手,运用用户本身的行为信息,挖掘出更多的用户需求信息,支持资源调度完成。具体的做法是通过结合相关反馈机制将用户调度等行为信息融入到资源调度过程中,利用用户行为所体现出的相关性和稳定性,建立资源调度的主动发现网络和反馈网络,深层挖掘用户的真实意图,研究面向用户需求的调度机制,从而为具有不同需求的用户提供有保障的服务,从根本上提高云计算的服务水平,实现对云计算环境的规范化和高效管理。
1 调度模型及相关定义
1.1 调度模型
为简化问题,不考虑任务的跨节点执行,假设用户向系统提交的任务就是资源调度器进行任务分配的最小单位,大型任务的分解由用户来完成。任务集由m个相互独立的元任务组成,记为T={t1,t2,…,tm}。用到的云系统可抽象为n个异构资源,记为R={r1,r2,…,rn}。每个资源节点都可以将数据传输到其他任意一个资源节点上,当任务被调度到不同地理位置的资源节点上运行时,存取所需数据的花费有可能相差很大。
1.1.1 相关定义
为了从用户的角度研究云计算环境下的资源调度问题,对用户需求的分析就显得至关重要。考虑到云计算运行过程中用户的实际需求,从最低需求和用户偏好两个方面对用户的差异性需求进行建模,使用二元组对用户提交的任务ti(ti∈T,1≤i≤m)表示为
ti=(tri,tpi)
式中,tri为用户任务ti的最低需求;tpi为用户任务ti的偏好。tri、tpi均可在用户提交任务时得到。
事实上,用户的需求往往是多方面的,可以包括时间性需求、安全性需求、可靠性需求、可信性需求、费用需求等。不失一般性,假设用户需求的维度是d,则用户任务的最低需求tri定义为
tri=[tri1,tri2,…,trid]

同理,用户任务的偏好tpi定义为
tpi=[tpi1,tpi2,…,tpid]

本文研究的重点是基础设施即服务(infrastructure-as-a-service,IaaS)层的资源调度,即对底层硬件资源进行分配,每个系统资源由多个资源特征进行描述。不失一般性,假设资源特征的个数为f,则资源rj(rj∈R,1≤j≤n)的特征向量rfj定义为
rfj=[rfj1,rfj2,…,rfjf]
所有n个系统资源的特征矩阵可以表示为
1.1.2 数据预处理
在实际应用中,不同的任务需求往往具有不同的表达形式和数值范围,因此,为了进行综合评价,首先需要对各个任务需求的值进行归一化处理,使得所有任务需求的值具有可比性。可以采用最小-最大规格化等方法对任务需求矩阵TR中任务需求的取值进行线性变换,消除不同量纲对调度结果的影响。
归一化处理后,任务需求矩阵TR中的每一个trik(1≤i≤m,1≤k≤d)都将满足
0≤trik≤1
(1)
对于用户的偏好,简单地说,其本质是用户对不同任务需求的重视程度存在差异。根据自己的实际需要,用户可能更关注其中的某些任务需求而不重视其他需求,这是实际应用中的常态。因此,需要用户综合考虑任务需求的所有维度,对各个任务需求的重视程度进行衡量。本文考虑采用层次分析法(analytic hierarchy process, AHP)[20]对各个任务需求偏好进行两两对比,尽可能降低由于主观判断不一致造成的影响,使用户的偏好信息通过量化比较得以体现和传递,从而实现对用户的按需服务。经过AHP的处理,任务偏好矩阵TP中的每一个tpik(1≤i≤m,1≤k≤d)都将满足
(2)
对于资源的特征矩阵RF中资源特征的取值进行归一化处理,使RF中每一个rfjk(1≤j≤n,1≤k≤f)都满足
0≤rfjk≤1
(3)
此外,由于RF中的特征向量往往是基于低层次的特征信息进行描述的,如硬件平台、操作系统、最小内存或磁盘空间需求等。而用户习惯用一些高层次概念对任务需求进行描述,这就使得用户的需求和资源的特征常常不在一个层次上,因此,对资源的特征矩阵RF中的数据进行进一步的预处理,将低层次的资源特征信息映射到高层次的用户需求信息上,同时去掉资源的特征矩阵RF中多余的特征信息,使特征矩阵RF与任务需求矩阵TR保持在相同的维度d上,即
rfj=[rfj1,rfj2,…,rfjf]
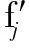

2 基于用户行为反馈的云资源调度
2.1 算法基本思想
在云计算环境中,不同的用户对资源的需求虽然各不相同,但是有研究表明[21-22],对于同一个用户来说,他/她的行为方式在一段时间内是比较稳定的,也就是说,用户未来请求的资源和其之前使用过的资源极可能是相似的、甚至是相同的。例如,如果之前用户在Amzon上购买了一些商品,那么Amzon就会“记住”用户购物历史,并且在用户再次回来购物时试图推荐类似的东西。这恰恰正是基于用户过去的需求和未来需求之间相对稳定的关系。在其他一些更加正式的应用中,一些基于趋势、或者季节性和周期性数据的预测也是使用用户历史记录来预测用户未来行为的例子。本文正是从用户行为所体现出的这种稳定性出发,结合相关反馈技术,建立用户需求的主动发现网络和反馈网络,基于用户行为反馈实现面向用户需求的资源调度。
相关反馈是信息检索系统中一种用户指导性学习的技术,通过与用户的交互来优化查询。按照用户最初给定的查询条件,系统返回给用户查询结果,用户可以人为地或者由系统自动地选择最符合用户查询意图的返回结果作为正反馈,或者最不符合用户查询意图的返回结果作为负反馈,系统根据这些不断变化的反馈信息来更新查询条件,重新进行查询,从而使随后的搜索更符合查询者的真实意图。根据相关反馈的思想,将云计算环境下的资源调度也看作是一个分类问题,将用户交互过程作为一种训练过程,把用户的历史调度信息作为正向训练数据对资源调度过程进行反馈控制,使资源调度的结果与用户的主观感知更加接近,确保用户任务按照其期望值更好地被执行。
2.2 算法描述
本文从用户的角度着手,基于用户行为对云资源调度问题进行研究,提出了基于用户行为反馈的资源调度机制(user behavior-based resource scheduling mechanism with feedback control, UBRSM-FC)。UBRSM-FC将用户调度等行为信息融入到资源调度过程中,并引入相关反馈机制对调度过程不断微调和优化,因此,是一个逐步求精的过程。具体过程如算法1所示。
算法1基于用户行为反馈的资源调度机制
输入TR,TP和RF
匹配阈值θ
最大循环次数γ
输出为每一个用户任务分配合适的资源
01 fori:=1 tomdo
02 do
03t=0
04 forj:=1 tondo
05 计算tri、rfj之间的相似性
06 if sim(tri,rfj)≥θthen
07ARi←rj
08 endif
09 endfor
10 ifARi=∅ then
11 ift=0 then
12 return “无满足用户需求的资源”
13 endif
14 break;
15 endif
16 ifARi中只有一个满足用户需求的资源then
17 将这个唯一满足条件的资源分配给当前的用户任务ti
18 endif
19 ifARi中存在多个满足用户需求的资源then
20 forj:=1 tondo
21 计算用户任务在每个可用资源rj上运行的效益
22 endfor
23 将效益最大的资源分配给当前的用户任务ti
24 endif
25 更新用户任务ti的TR和TP
26t=t+1
27 untilt>γ
28 endfor
整个调度算法在一个for循环的控制下完成,每次循环处理一个用户任务。每个用户任务的调度过程分为资源匹配、资源选择和基于用户行为的反馈3个阶段,这3个阶段循环完成,循环由参数t控制,循环的次数设为γ,一般取经验值。
2.2.1 资源匹配
首先是资源匹配阶段(算法1第4~9步)。资源匹配的主要功能是按照用户需求查找资源,获得所有符合条件的资源列表的过程。因此,需要根据用户的需求(调度初始时只包括用户提交的资源请求中的最低需求,之后还包括经过反馈网络反馈回来的用户需求信息),按照一定的算法与资源集内的所有资源进行相似性匹配。
给定用户任务ti(ti∈T,1≤i≤m),则该用户任务的资源需求与资源集内任一资源rj(rj∈R,1≤j≤n)特征的相似性可通过余弦相似度计算方法得到,表示为

(4)
式中,sim(tri,rfj)即为用户任务ti的资源需求和资源rj在特征描述上的相似度;trik为用户任务ti第k维的资源需求,trik与rfjk对应。如果计算出的相似度大于给定的匹配阈值θ,就认为资源rj的特征与用户任务ti的资源需求相似,重复计算资源集R中的所有资源,最终返回给用户任务ti一个候选资源集ARi,表示为
ARi={rj|sim(tri,rfj)≥θ,rj∈R,j=1,2,…,n}
(5)
2.2.2 资源选择
接下来是资源选择阶段,资源选择主要负责在资源匹配得到的候选资源集中根据资源调度策略选择适合的资源,比如使用户费用最低,或者系统性能最高等,并将资源分配到相应的请求中。
算法1第10~24步对候选资源集ARi所有可能的结果分情况进行处理:当ARi=∅时,表示本次循环没有满足用户需求的资源可用,此时即使没有达到指定的循环次数γ,循环也会被终止;当ARi中只有1个满足用户需求的资源时,按照尽量保证用户任务能够完成的原则,不计较运行的效益,直接将这个唯一满足条件的资源分配给该任务;算法1第19~24步对ARi中存在多个可用资源的情况进行处理,此时有多个满足用户需求的资源可供选择,调度算法需要计算用户任务在各个资源上运行的效益来决定任务的分配。
不失一般性,假设给定用户任务ti(ti∈T,1≤i≤m),则该用户任务运行在资源rj(rj∈R,1≤j≤n)上的效益函数为
(6)

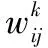
(7)
在这种“差距”的计算中,直接用rfjk和trik相减。如果rfjk-trik>0,代表资源能够满足用户任务的资源需求,“差距”直接体现为两个数的差值,即rfjk-trik;如果rfjk-trik<0,代表资源不能满足用户任务的资源需求,此时如果存在其他可以满足用户需求的资源(差值为正数的资源),则首先应考虑那些资源。因此将这些为负数的差值取绝对值后加上这一维度上差值绝对值的最大值,使处理后的数值一定大于原有的差值为正的资源的差值,保证差值为负的资源的优先级低于差值为正的资源优先级。而且在没有满足用户需求的资源存在的情况下,同样都是差值为负的数值经过这样的处理后,仍然保持差值越小,优先级越大,被选中运行的可能性越大;在rfjk-trik=0的特殊情况下,为了避免式(6)中效益函数的分母为0,取这一维度上所有差值绝对值的最小值,以保证这种情况的优先级最高。
最后,式(6)取处理后数值的倒数,与用户偏好矩阵TP中相应的元素相乘,目的是体现用户在不同需求维度上的偏好程度。处理后元素取倒数使得原来越小的数得到的结果越大,这样,计算用户任务在所有满足条件的资源上的效益,取获得效益最大的资源进行分配。
2.2.3 基于用户行为的反馈
在资源选择阶段,根据已得到的候选资源集,用户会最终选取能最大化某种评价标准的资源。这种资源选择的结果实际上反映的就是用户需求与对应资源之间的关系,这本身也包含了大量的用户行为信息,而且起着重要的导向作用。如果能将这些资源选择结果的相关信息进行反馈,如哪些资源是用户已经调用的,或者可以调用的,那么就可以通过对这些信息的分析进而获得用户的行为信息,帮助云系统主动发现和收集用户潜在的需求,进一步挖掘出用户的真实需求。正是基于这样的想法,把用户这种资源调用作为用户行为的体现,结合相关反馈机制,将最终选取资源的相关信息作为正反馈对调度过程进行微调和优化,实现基于用户行为的反馈。一方面对任务需求矩阵TR进行更新,利用这种交互行为所反馈回来的行为信息辅助完成资源的匹配;另一方面对任务偏好矩阵TP进行更新,辅助完成最终资源的选择。
给定用户任务ti(ti∈T,1≤i≤m),假设rs是用户在资源选择阶段选取的资源,根据rs被用作正反馈的概率,可以得到任务ti用户需求和偏好的更新公式分别为
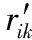
(8)

(9)
式中,p(rs)即为rs被用作正反馈的概率,可以从用户的历史调度信息中计算得到。
这种基于用户行为的反馈会在资源选择后自动完成,更新后的任务需求矩阵和任务偏好矩阵将作为下一个调度循环的初始条件,实现用户需求信息的主动发现和收集。而且这个反馈过程会反复进行,使随后的调度过程更加符合查询者的真实意图,实现用户需求的自动调节。
达到指定的循环次数γ后,反馈过程终止,一个用户任务的调度结束。上述过程重复执行m次可以完成全部m个用户任务的资源调度过程。
2.3 算法性能分析
基于用户行为反馈的资源调度算法UBRSM-FC通过循环的方式为每一个用户任务寻找效益最大的资源进行分配,而每一次分配都要对资源在各个需求维度上的表现进行比较和处理,因此,算法的时间复杂度与用户任务的数目m、资源的数目n以及用户需求维度d都有密切的关系。同时,由于算法加入了反馈的环节,因此,算法的时间复杂度与反馈的循环次数γ也息息相关。最差情况下,整个算法的时间复杂度为O(mγ(nd+nd+d))=O(mγnd),这比传统调度算法的时间复杂度O(mnd)[23]要高一些,与一些涉及迭代次数的调度算法(例如一些利用遗传算法进行调度的策略)的时间复杂度差不多。
3 实验与结果
3.1 实验环境与设置
本文采用仿真工具CloudSim(版本3.0.3)模拟实验云环境,实验硬件配置为HP Elitedesk800计算机,i7-4790 CPU,主频3.6GHz,内存4 GB。实验设置了2个数据中心,分别对应300个虚拟机和700个虚拟机。不同虚拟机的计算能力、存储能力、带宽等性能可能相差很大,用来模拟总共1 000个高异构的系统资源。随机生成了300个云任务代表用户的资源请求。用户请求的到达符合泊松分布。除此之外,实验中扩展了云任务的属性,使每个用户请求具有4个在实际应用中常用的需求维度,包括时间性需求、安全性需求、可靠性需求以及花费需求。用户请求的时间性需求定义为用户任务的最迟完成时间,可靠性需求定义为用户要求的最小成功完成概率,安全性需求定义为用户要求的安全保障等级,花费需求定义为用户可以承担的最高花费。同样,也扩展了虚拟机的属性,使每个资源的特征向量也可以经过预处理映射到这4个维度上。具体的映射方法可参考文献[24]。
3.2 实验结果与分析
通过3组实验对基于用户行为反馈的资源调度算法UBRSM-FC的性能进行说明。第1组实验考察算法本身的运行时间,第2组实验从用户角度出发衡量算法的用户满意度,第3组实验从系统的角度出发衡量算法的资源利用率。对每种情况实验100次,然后统计平均值。
3.2.1 运行时间
运行时间是算法产生给定任务集的调度结果所经过的时间跨度。通常,运行时间越小,算法越实用。表1是具有反馈控制的调度算法UBRSM-FC与不进行反馈控制的调度算法(简写为UBRSM)的运行时间对比。

表1 调度算法运行时间比较
如表1所示,具有反馈控制的调度算法UBRSM-FC的运行时间比不进行反馈控制的调度算法UBRSM的运行时间要高一些。这是因为UBRSM-FC算法需要花费一些额外的时间在资源选择之后对任务需求矩阵和任务偏好矩阵进行更新。当然,从表1中最后一列的数据可以看出,随着用户数量的增加,这些时间花费在总的时间成本中所占的比重会越来越小,甚至可以忽略不计。
但是,表1中记录的是UBRSM-FC没有进行反馈循环之前的运行时间,反馈循环开始后,运行时间将会随着反馈循环的次数成比例增长。然而,这些代价通常是可以接受的。这是因为,在实际情况中,相对于用户任务的数目和系统资源的数目,反馈的循环次数一般都小得多,可能只是个位数。而且,反馈循环结束后,最终的任务需求矩阵和任务偏好矩阵将会存储在系统中,并作为同一用户下一次任务请求的初始条件,直到该用户明确修改其用户需求和用户偏好的参数值。这在一定程度上可以帮助系统主动发现用户的潜在需求,降低用户使用云系统的难度。事实上,从长远的角度来看,基于用户行为反馈的资源调度算法就是通过增加一些反馈循环上的开销来挖掘用户的真实需求,提高用户使用云系统的满意程度。
3.2.2 用户满意度
用户满意度是用户对调度结果的满意程度。在本文中,用调度结果与用户需求之间的匹配程度来衡量用户满意度。给定用户ti(ti∈T,1≤i≤m),用户满意度USDi具体定义为
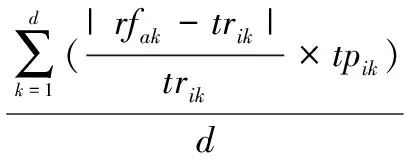
(10)
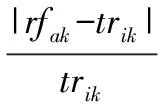
图1展示了匹配阈值θ分别取0.2,0.5,0.8三种情况中不同反馈循环次数下用户满意度的变化。

图1 UBRSM-FC的用户满意度Fig.1 User satisfaction degree of UBRSM-FC
从图1可以看出,只要匹配阈值θ设置在合理范围内(这里综合考虑用户满意度和时间成本两方面,取平衡值0.5),2次反馈循环后,基于用户行为反馈的资源调度算法UBRSM-FC就可以取得超过80%的用户满意度,而且,随着反馈循环次数的不断增加,4次反馈循环后,算法的用户满意度可以达到将近90%的用户满意度。这样的结果主要得益于基于用户行为的反馈机制的引入,通过反馈循环对调度过程不断微调和优化,使得随后的调度过程更加符合查询者的真实意图,提高了用户的满意度。
同样注意到,6次反馈循环后,算法用户满意度的变化不再明显,此时算法的用户满意度已达到近95%。这比不进行反馈控制的调度算法70%多的用户满意度,即图1中反馈次数为0的数据,要高出近20%。这也意味着,算法通过有限的反馈循环就可以达到一个比较有效和稳定的状态。
3.2.3 资源利用率
系统资源利用率是以系统的角度衡量调度算法的一个重要指标。在本文中,资源的利用率可以用被使用的资源负载容量总和与系统资源可使用负载容量总和的比值来计算。在这一部分,将本文提出的基于用户行为反馈的资源调度算法UBRSM-FC与传统的先来先服务算法(first come first serve,FCFS)的资源利用率进行对比。采用先来先服务算法FCFS的主要原因是该算法是CloudSim自带的调度算法,同时也是用来与优化算法进行性能比较最常见的调度算法。图2展示了不同用户任务数量下两种算法系统资源利用率的变化。

图2 资源利用率比较Fig.2 Resource utilization rate comparision
从图2可以看出,随着用户任务数从50增加到300,两种算法的资源利用率都在不断提高。原因很明显,因为更多的用户任务意味着将有更多的系统资源将被占用。但是无论用户任务数目如何变化,相对于FCFS算法,UBRSM-FC算法的系统资源利用率总是要高一些。这是因为UBRSM-FC算法能够筛选出与用户任务需求最接近的资源,而不是性能最优的资源,避免将能力过高的资源分配给需求过低的任务,使系统资源的利用率得到提高。因此,UBRSM-FC算法更能够体现云平台充分利用系统空闲资源的特点。
4 结束语
作为互联网资源利用的新模式,云计算的商业性使其调度机制更加关注用户的需求。然而,云计算中的资源具有异构性、自治性的特点,而且往往是分布式的,云计算中用户的需求也千差万别,这些都使得云计算环境下的资源调度问题更加复杂。因此,如何在云计算资源中获取用户真实所需的资源,实现高效、经济、准确的资源调度是当前迫切需要解决的问题,这就要求研究人员根据云计算的发展趋势,做出准确分析提出新的方法。
针对这一问题,从用户的角度着手,基于用户行为对资源调度问题进行深入的研究:通过引入相关反馈机制,将用户行为信息融入到资源调度过程中,在此基础上,提出了基于用户行为反馈的资源调度机制,深层挖掘用户的真实意图,实现面向用户需求的资源调度,从而为具有不同需求的用户提供有保障的服务。总体来说,这种基于用户行为反馈的资源调度机制具有以下优点:
首先,用户作为云计算的最终使用者,对云计算的发展起着重要的作用。因此,从用户的角度出发,根据用户的不同兴趣、爱好和领域等用户行为信息对云计算环境下的资源调度问题进行研究,符合云计算的发展方向;
其次,这种方法是面向用户的,可以针对每个用户的特点进行个性化的资源反馈分析,实现用户需求的主动发现和收集;
再次,这种方法具备学习的功能,通过多次反馈,可以对用户需求进行自动的调节,使结果更加符合用户的真实需求。
模拟实验进一步证明,这种基于用户行为反馈的资源调度机制能够在最大程度满足用户需求的同时,兼顾系统资源的利用率,更加符合开放、复杂的云计算环境。
今后,将进一步尝试更加简单有效的方法,对用户需求矩阵和用户偏好矩阵进行更新,在充分考虑时间成本和空间成本的基础上,关注如何让用户的调度行为信息更好地为挖掘用户的真实需求服务。除此之外,考虑到用户的行为方式往往在一段时间内是比较稳定的,因此,在下一步的工作中,将关注用户行为相关性和稳定性的时效性。
[1] FOSTER I, ZHAO Y, RAICU I, et al. Cloud computing and grid computing 360-degree compared[C]∥Proc.of the Grid Computing Environments Workshop, 2008: 1-10.
[2] ARMBRUST M, FOX A, GRIFFITH R, et al. A view of cloud computing[J].Communications of the ACM,2010,53(4):50-58.
[3] MELL P, GRANCE T. The NIST definition of cloud computing, NIST SP 800-145 [R]. Gaithersburg, MD, United States: National Institute of Standards and Technology, 2011.
[4] BUYYA R, YEO C S, VENUGOPAL S, et al. Cloud computing and emerging IT platforms: vision, hype, and reality for delivering computing as the 5th utility [J]. Future Generation Computer Systems, 2009, 25(6): 599-616.
[5] 陈赓, 郑纬民. 云计算:系统实例与研究现状[J]. 软件学报, 2009, 20(5): 1337-1348.
CHEN G, ZHENG W M. Cloud computing: system instances and current research [J]. Journal of Software, 2009, 20(5): 1337-1348.
[6] Amazon elastic compute cloud (EC2) [EB/OL]. [2016-10-30]. http:∥www.amazon.com/ec2/.
[7] Google app engine [EB/OL]. [2016-10-30]. http:∥appengine.google.com.
[8] SIMS K. IBM introduces ready-to-use cloud computing-collaboration services get clients started with cloud computing [EB/OL]. [2016-10-30]. http:∥www-03.ibm.com/press/us/en/pressrelease/22613.wss.
[9] Microsoft azure [EB/OL]. [2016-10-30]. http:∥www.microsoft.com/azure/.
[10] 钟海.面向云计算环境的应用迁移策略及资源管理技术研究[D].云南: 云南大学, 2011.
ZHONG H. Research on applications migration strategy and resources management technology towards cloud environment [D]. Yunnan: Yunnan University, 2011.
[11] MITTAL A, KAUR P D. Genetic based QoS task scheduling in cloud-upgrade genetic algorithm [J]. International Journal of Grid and Distributed Computing, 2015, 8(4): 145-152.
[12] PANDIT D, CHATTOPADHYAY S, CHATTOPADHYAY M, et al. Resource allocation in cloud using simulated annealing[C]∥Proc.of the International Conference on Applications and Innovations in Mobile Computing, 2014: 21-27.
[13] 张永强, 徐宗昌, 呼凯凯, 等. 基于私有云和改进粒子群算法的约束优化求解[J]. 系统工程与电子技术, 2016, 38(5): 1086-1092.
ZHANG Y Q, XU Z C, HU K K, et al. Constrained optimization problems solving based on private cloud and improved particle swarm optimization [J]. Systems Engineering and Electronics, 2016, 38(5): 1086-1092.
[14] SINGH J, MISHRA S. Improved ant colony load balancing algorithm in cloud computing[J]. International Journal of Computers and Technology, 2015, 4(3): 5636-5644.
[15] BUYYA R, YEO C S, VENUGOPAL S. Market-oriented cloud computing: vision, hype, and reality for delivering IT services as computing utilities[C]∥Proc.of the 10th IEEE International Conference on High Performance Computing and Communications, 2008: 5-13.
[16] BUYYA R. Market-oriented cloud computing: opportunities and challenges[C]∥Proc.of the 17th IEEE International Enterprise Distributed Object Computing Conference, 2013: 3.
[17] 丁丁, 罗四维, 艾丽华. 基于双向拍卖的适应性云计算资源分配机制[J]. 通信学报, 2012, 33(Z1): 132-140.
DING D, LUO S W, AI L H. An adaptive double auction mechanism for cloud resource allocation [J]. Journal on Communications, 2012, 33(Z1): 132-140.
[18] ZHANG R, WU K, LI M, et al. Online resource scheduling under concave pricing for cloud computing [J]. IEEE Trans.on Parallel and Distributed System, 2015, 27(4): 1131-1145.
[19] 李智勇, 陈少淼, 杨波, 等. 异构云环境多目标Memetic优化任务调度方法[J]. 计算机学报, 2016, 39(2): 377-390.
LI Z Y, CHEN S M, YANG B, et al. Multi-objective memetic algorithm for task scheduling on heterogeneous cloud [J]. Chinese Journal of Computers, 2016, 39(2): 377-390.
[20] SAATY T L. Analytic hierarchy process [M]. New York: Wiley, 2014.
[21] ASVANUND A, KRISHNAN R, SMITH M, et al. Interest-based self-organizing peer-to-peer networks: a club economics approach [EB/OL]. [2016-10-30]. Ssrn Electronic Journal, http:∥ssrn.com/abstract=657403.
[22] CRESPO A, Garcia-Molina H. Semantic overlay networks for P2P system[C]∥Proc.of the 3rd International Workshop on Agents and Peer-to-Peer Computing, 2005: 1-13.
[23] SINGH S, CHANA I. A survey on resource scheduling in cloud computing: issues and challenges [J]. Journal of Grid Computing, 2016, 14(2): 217-264.
[24] DING D, LUO S W, AI L H, et al. A user preference driven approach for multi-QoS constrained task scheduling in grid[C]∥Proc.of the 13th International Conference on Parallel and Distributed Computing, Application, and Technologies, 2012: 493-498.
