面向对象软件的测试用例自动再生成方法∗
2018-01-04陈双徐望
陈 双 徐 望
1 引言
对于一些开发和维护周期较长的软件项目来说,测试人员会持续不断地为被测软件设计和开发新的测试用例。随着软件测试工作的开展,一定时间后会积累下许多测试用例。软件研发团队通常会建立并维护一个测试用例库将已有测试用例通过合理的分类有效地管理起来,以方便开发和测试人员查询、执行、共享和复用这些测试用例。
对面向对象软件而言,每个测试用例由一个方法调用序列构成。因此,面向对象软件的测试用例库可以提供大量的方法调用序列[1]。如果能从如此众多的方法调用序列中发现一些规律性信息,就可以利用这些信息为新的测试用例生成提供指导[2]。
现有的测试用例自动生成方法通常隐含地假定没有现成的测试用例可供参考。然而,当该假定与实际情况不符时,就会错过从现有测试用例(特别是人工创建的测试用例)中获取有用信息的机会。最近,Yoo等提出了一种旨在利用现有测试数据,生成新测试数据的测试数据再生成(test data regeneration)技术[3]。
目前,大量软件项目采用面向对象软件开发范型。对面向对象软件而言,测试用例不再是一组简单的测试输入值,而是一系列有序执行的方法调用序列[4]。为此,本文受现有测试数据再生成研究的启发,提出了一种基于序列模式挖掘技术的面向对象软件测试用例自动再生成策略,利用面向对象软件测试用例库所提供的大量已有测试用例资源,为面向对象软件生成新的测试用例。
2 面向对象软件的测试用例自动再生成方法
面向对象软件的每个测试用例都是一个方法调用序列。如果被测面向对象软件已有测试用例库,就可以采用序列模式挖掘技术,从测试用例库的大量方法调用序列中识别出所蕴含的序列模式。这些序列模式通常揭示了相关方法的重要用法或是惯用形式,可以用于构建新的测试用例[5~6]。
假设已知被测面向对象软件、覆盖准则以及用以测试的测试用例库,其中每个测试用例是一个方法调用序列,则基于序列模式挖掘的测试用例再生成可以描述为:
1)从测试用例库T中识别出满足最小支持度θ的序列模式集合S,其中,每个序列模式s∈S是一个mcs子序列并且在T中出现不少于θ ||T次( ||T为测试用例库T中含有的全部测试用例数);
2)以S为基础,利用遗传算法为被测软件p生成满足指定覆盖准则c的新测试用例集T'。
下面将分别描述基于序列模式挖掘的测试用例再生成策略。
2.1 测试用例库的序列模式挖掘算法
本文提出采用BIDE序列模式挖掘策略[5~6],从给定的测试用例库T中获取频繁序列模式S。为此,首先定义前缀序列和后缀序列如下。
定义1:前缀序列(prefix sequence)。假设给定面向对象软件的方法调用序列 α= <m1,m2,…,mi,…,mn> ,那么 α 的子序列 β=<m1,m2,…,mi-1> 称为α关于mi方法的前缀序列。
定义2:后缀序列(suffix sequence)。假设给定面向对象软件的方法调用序列 α= <m1,m2,…,mi,…,mn> ,那么 α 的子序列 γ=<mi+1,mi+2,…,mn>称为α关于mi方法的后缀序列。
扫描测试用例库T中的所有方法调用序列,可识别出方法调用序列包含的频繁1-序列集合S1(即长度为1且出现频率不小于最小支持度θ的子序列)。对于S1中的每个频繁1-序列s1而言,由于s1在T中出现至少θ ||T次,因此从T中能够找到不止一个关于s1的前缀序列和后缀序列。由此可以得到关于s1的前缀序列集合以及后缀序列集合,分别记为Ps1和Ss1。
对于每个频繁1-序列s1而言,尝试在s1前逐个插入其前缀序列中的方法,以求反向扩展s1得到更长的频繁序列。具体来说,首先将前缀序列ps1=< m1,…ml-1,ml> ∈ Ps1的最后一个方法ml插入到s1之前,如果所得序列<ml,s1>在T中出现至少θ ||T 次,那么就到了一个频繁2-序列<ml,s1>,记为s2。然后尝试将ml-1方法插入到s2之前,从而反向扩展s2以得到一个频繁3-序列。通过这种迭代操作不断扩展序列的长度,直到结果序列在T中出现的次数少于θ ||T次。于是,便得到了反向扩展s1后的频繁序列s'。
然后,尝试在s'后逐个添加s1后缀序列中的方法,正向扩展s'以得到更长的频繁序列。将后缀序列 ss1=<mf,mf+1,…,mn>∈Ss1的第一个方法mf添加到s'之后,如果所得序列<s',mf>在T中仍然出现至少θ ||T次,那么就尝试将mf+1方法添加到<s',mf>之后。依此迭代,直到结果序列在T中出现次数不足θ ||T次,便得到了一个完整的频繁序列s。
如上文所述,对于每个频繁1-序列来说,都有若干个前缀序列和后缀序列。因此,最终能够从中得到一批完整的频繁序列,即频繁序列模式集合S。算法1给出了由测试用例库T得到频繁序列模式集合S的伪代码描述。
需要说明的是,挖掘测试用例库T得到频繁序列模式的过程中,最小支持度θ是一个关键参数。为根据T的特点选取适当的θ值,本文定义平均方法调用频率如下。
定义3:平均方法调用频率(Averaged Method Invocation Frequency,AMIF)。假设测试用例库T包含 ||T个测试用例,其共调用了n个不同的方法并且每个方法mi被调用了 ||mi次,那么该测试用例库的平均方法调用频率可以表示为
AMIF值反映了测试用例库中各方法被调用的平均频度。如果一个测试用例库的AMIF值较小,就意味着该测试用例库中各方法被调用的平均频度比较低,因而该测试用例库中包含的频繁序列模式相对较少。与之相反,对于一个AMIF值较大的测试用例库而言,其方法被调用的平均频度较高,因此通常会包含大量的频繁序列模式。
为以合理的花费从测试用例库中得到数量适当的序列模式,我们根据测试用例库的AMIF值设定不同的最小支持度θ。具体来说,如果一个测试用例库的AMIF较低,那么就选取一个比较小的θ值;若一个测试用例库的AMIF较高时,则采用一个比较大的θ值。
2.2 基于序列模式的测试用例再生成算法
对于面向对象软件 p而言,利用上述方法从测试用例库中获得频繁序列模式集合S后,就能够以S为基础,利用遗传算法再生成新的测试用例。换言之,就是以被测软件 p以及频繁序列模式集合S作为输入,根据指定的测试覆盖准则c,采用遗传算法寻找一批新的方法调用序列作为p的测试用例。
具体来说,首先通过静态分析得到被测软件p包含的方法集合M以及分支集合B,并且在程序中的分支语句前后插装测试探针代码,以记录 p的动态执行路径。然后,以分支集合B中的任意一个尚未覆盖的分支b作为目标,根据序列模式集合S构建初始种群P,其中每个个体i是一个以序列模式s∈S为基础构建的可执行方法调用序列。
为确保i是可执行的,需要为s中的参数赋值。如果需要赋值的arg参数是一个基本类型变量(例如整型变量),那么就为其赋一个随机值;如果arg参数是一个对象类型变量,则搜索M集合以求找到一个m*方法,其返回类型Tm*与arg参数的声明类型Targ相同或者是Targ的子类(即),然后将m*方法返回的对象赋给arg。如果m*方法仍然含有需要赋值的参数,同样采用上述方式为m*的参数赋值。以此类推,直到不再需要为参数赋值为止,这样就生成了一个可执行方法调用序列个体。算法2描述了为个体所需参数赋值的伪代码。
初始种群P构建完毕后,动态执行P中的每个个体i并利用测试探针代码记录个体的执行路径。如果i达到了b分支,那么就生成了一个新的测试用例,继续以分支集合B中尚未覆盖的分支b'作为目标生成新的测试用例。如果b没有被P中的任何个体覆盖到,则计算P中每个个体的执行路径与目标分支b的距离:
其中,“approach_level”表示个体实际执行路径距离到达目标分支仍相差的控制流节点数;“branch_distance”则表示在首个造成实际执行路径偏离目标分支的条件谓词处距离满足该条件谓词的差值,采用如下公式进行归一化:
然后从P中选出两个适应度值最高的优秀个体i1和i2,执行交叉和变异操作以产生子代个体。其中单点交叉操作(将i1的一段子序列与i2的一段子序列互换)的概率为 pc、替换变异操作(从频繁序列模式集合S中随机选择两个频繁序列模式1和2,并分别将 i1和 i2的一段子序列替换为1和2)的概率为概率为 pm。执行替换变异操作后,根据算法2分别为子代个体i1'和i2'的参数赋值,这样便得到两个可执行的子代个体。
最后,将P中两个适应度值较低的个体替换为i1'和i2',从而产生一个新种群P',并评估P'中每个个体的适应度值。依此循环执行种群再生和适应度评估过程,直到满足指定的终止条件(全部目标分支都被覆盖或者时间预算耗尽),退出循环,这样便生成了一批新的测试用例T'。算法3以伪代码形式描述了上述基于频繁序列模式的测试用例再生成流程。
3 测试用例自动再生成实验及结果分析
本文以上述测试用例再生成策略为基础,实现了SPM-RGN原型工具,并通过实验为4个具有不同特点和用途的Java开源项目(总计包含超过4万行代码)生成测试用例,以评估该策略的有效性。
实验中首先检验了从测试用例库挖掘序列模式集合的效果,包括:
1)挖掘测试用例库获得序列模式的数量;
2)序列模式挖掘的时间开销和空间开销。
然后,对比分析了SPM-RGN与现有随机测试生成工具Randoop[7]和演化测试生成工具EvoSuite[8]以及本研究开发的基于搜索的测试用例再生成工具RND-RGN(直接随机选取现有测试用例作为初始种群)的测试生成效果。具体而言,主要从两个方面比较这4种工具的测试生成效果:
1)取得的分支覆盖率;
2)所生成测试用例的长度。
*实验对象
实验中以4个著名的Java开源项目作为被测软件:
其中CC和CP来自Apache Commons Proper库,该库主要用于提供各种可复用的Java组件;JT和NX来自Software-artifact Infrastructure Repository库,该库主要用于提供各种Java对比实验程序。这4个Java项目中,程序实现最为复杂的CC有超过2万行代码、近400个类、超过3千个方法以及6千多个分支。4个项目合计近4万5千行代码。此外,实验中采用随这4个项目发布的人工测试用例集作为相应的测试用例库。
被测软件的基本统计特征如表1所示,包括各被测软件所含的类数(#Classes)、方法数(#Methods)、分支数(#Branches)、非注释代码行数(LOC)、测试用例库中包含的测试用例个数(#Tests)及测试用例库的AMIF值。

表1 被测软件的基本信息
*实验参数设置
如第2节所述,基于序列模式挖掘的测试用例再生成策略主要分2个阶段实现,即:1)序列模式挖掘阶段,2)测试用例再生成阶段。在这2个阶段中,都有一些参数需要设置。
在序列模式挖掘阶段,最小支持度θ是一个关键参数。由于不同被测软件的测试用例库彼此之间特点各不相同,因此没有通用的最小支持度。为此,实验中根据相应测试用例库的AMIF值选取最小支持度,以合理的时间和空间开销挖掘出适量的序列模式。
由表1可见,本文选取的4个实验对象中,第一个被测软件CC的测试用例库AMIF值不到0.5%,因此采用1%到5%这样较低的最小支持度来挖掘测试用例库。第二个被测软件CP的测试用例库AMIF值同样较低(0.4%),因此同样采用1%~5%的最小支持度来挖掘测试用例库。与前两个被测软件的测试用例库不同,第三个被测软件JT的测试用例库AMIF值高达7.6%,较前两个测试用例库提高了一个数量级,于是实验中采用10%到50%这样较高的最小支持度来挖掘测试用例库。最后一个被测软件NX的测试用例库AMIF值适中(2.4%),实验中分别将最小支持度设置为1%~50%不等,以更为全面地考察从测试用例库挖掘序列模式集合的效果。
在测试用例再生成阶段,EvoSuite、RND-RGN以及本研究提出的SPM-RGN原型工具均采用了文献[12]推荐的演化测试参数设置。具体来说,每个类的测试生成时间上限为600秒,种群中共包括100个体,采用轮盘赌选择策略、单点交叉重组策略(交叉概率为0.75)以及替换变异策略(变异概率为0.3)。
3.1 挖掘测试用例库获得序列模式的数量
图1给出了采用不同最小支持度时,从测试用例库挖掘出的序列模式的数量。由图1可见,从这些测试用例库中可以挖掘出大量的序列模式。最小支持度取值增加时,从各测试用例库挖掘出的序列模式数量呈对数级减少。
具体来说,对于方法使用频率较低的测试用例集,如CC的测试用例集和CP的测试用例集,以比较低的最小支持度才能挖掘出序列模式。例如,最小支持度设置为1%时,从CC的测试用例集可以挖掘得到3181个序列模式。然而,对于方法使用频率较高的测试用例集,如JT的测试用例集,以比较高的最小支持度也能挖掘出大量序列模式。例如,最小支持度设置为10%时,从JT的测试用例集挖掘出了48603个序列模式。对于方法使用频率相对适中的测试用例集,比如NX的测试用例集,最小支持度分别设置为1%到20%时,都能挖掘得到序列模式。
3.2 序列模式挖掘的时间开销和空间消耗
图2和图3分别给出了采用不同最小支持度时,从测试用例库挖掘序列模式集合的相应时间开销和空间开销。
由图2和图3可以看出,最小支持度取值增加时,从各测试用例库挖掘序列模式集合的时间开销和空间开销同样呈对数级减少。此外,最小支持度取值相同时,从方法使用频率较低的测试用例库比从方法使用频率较高的测试用例库挖掘频繁方法调用序列模式集合的开销更小。
通常来说,最小支持度取值越小,从测试用例库挖掘出的序列模式越多,而进行序列模式挖掘所需的时间和空间开销也就越大。因此,需要根据AMIF指标来针对测试用例库的方法使用特点,选择合适的最小支持度取值,从而在所挖掘出的序列模式的数量以及进行序列模式挖掘的开销间做出一个良好的折衷。
3.3 再生成测试用例的分支覆盖效果
对于每个被测面向对象软件,表2给出了上述测试生成工具分别取得的分支覆盖率(重复实验30次取平均值),其中粗体数值表示对每个被测软件取得的最大分支覆盖率。表2底部给出了每个测试生成工具所取得的平均分支覆盖率。

表2 不同自动测试生成工具取得的分支覆盖率(%)
由表2可见,对于全部4个被测软件,SPM-RGN工具都比Randoop、EvoSuite和RND-RGN取得了更高的分支覆盖率。SPM-RGN所取得的分支覆盖率高达70%~95%,平均而言,较Randoop、EvoSuite和RND-RGN取得的分支覆盖率分别提高了47%、11%以及4%。并且单边Mann-Whitney U检验结果表明:在95%置信水平上,SPM-RGN较Randoop、Evo-Suite和RND-RGN取得的分支覆盖率提升显著。
具体来说,在30次重复实验中,Randoop,Evo-Suite,RND-RGN和SPM-RGN这4个自动测试生成工具对于被测软件所取得的分支覆盖率分布情况如图4所示。由图4可以发现,Randoop在30次重复实验中取得的分支覆盖率波动很大,而EvoSuite、RND-RGN以及本研究提出的SPM-RGN在30次重复实验中取得的分支覆盖率相对稳定得多。
3.4 再生成测试用例的可读性
对比分析上述测试生成工具所生成测试用例的平均长度,实验结果如表3所示。其中对于每个被测软件,所生成的测试用例平均长度最短的用粗体表示。
由表3可以发现,在上述测试生成工具中,本研究提出的SPM-RGN生成的测试用例平均长度最短。SPM-RGN生成的测试用例平均包含大约20行代码,比Randoop生成的测试用例平均缩短了大约85%,比EvoSuite和RND-RGN生成的测试用例分别平均缩短了大约28%。
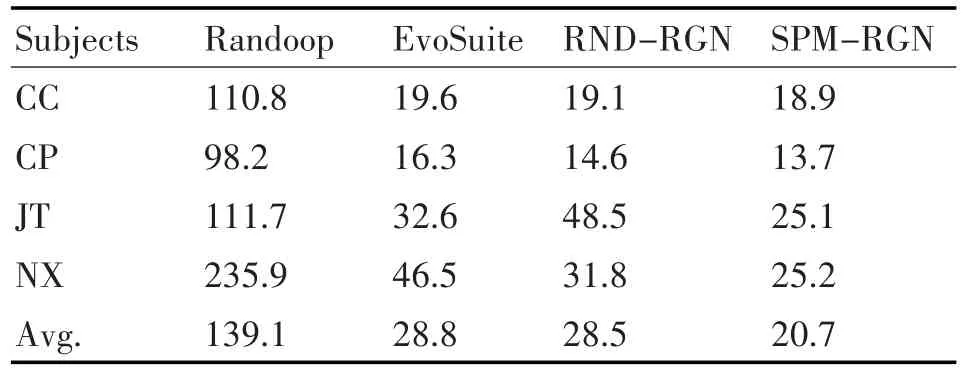
表3 不同测试生成工具所生成测试用例的平均长度
具体来说,图5显示了在30次重复实验中,每个测试生成工具所生成测试用例平均长度的分布情况。由此可以看出,在30次重复实验中,Randoop生成的测试用例其长度变化最大,而SPM-RGN生成的测试用例其长度变化最小。
上述实验结果表明,SPM-RGN可以实现基于序列模式挖掘的测试用例再生成。总体而言,SPM-RGN可以取得比较良好的分支覆盖率,并且SPM-RGN生成的测试用例相对比较短,更有利于测试人员理解。
4 结语
面向对象软件的测试用例自动生成极具挑战。与现有完全从被测软件出发生成测试用例的方法不同,本文提出了一种基于序列模式挖掘技术的测试用例再生成方法,通过挖掘测试用例库中的方法调用序列模式,为面向对象软件搜索高质量的新测试用例。如果测试用例库为人工创建的测试用例集,则该方法生成的新测试用例与完全从被测软件出发生成的测试用例相比,更易于测试人员理解。后续研究工作可以考虑针对软件中涉及多线程特性的代码探讨如何自动生成测试用例,以进一步提高测试的有效性。
[1]郭滔.面向对象软件测试技术研究[J],科技信息,2011,3:3945-3947.
[2]贾冀婷.软件测试中测试用例自动生成方法研究[J],电脑知识与技术,499-500.
[3]Yoo S,Harman M.Test data regeneration:generating new test data from existing test data[J].Software Testing Verification and Reliability.2012,22(3):171-201.
[4]Arcuri A,Yao X.On test data generation of object-oriented software[C]//In:Proceedings of the Testing:Academic and Industrial Conference Practice and Research Techniques-MUTATION.Los Alamitos,CA:IEEE Computer Society,2007,72-76.
[5]俞东进,郑苏杭,李万清,等.基于BIDE的多核并行闭合序列模式挖掘[J]. 计算机工程,2012,38(12):55-59.
[6]管恩政.序列模式挖掘算法研究[D].长春:吉林大学,2005.
[7]Pacheco C,Lahiri S K,Ernst M D,Ball T.Feedback-directed random test generation[C]//In:Proceedings of the 29thInternational Conference on Software Engineering.Los Alamitos,CA:IEEE Computer Society,2007,75-84.
[8]Fraser G,Arcuri A.EvoSuite:automatic test suite generation for object-oriented software[C]//In:Proceedings of the 19thACM SIGSOFT Symposium and the 13thEuropean Conference on Foundations of Software Engineering.New York,NY:ACM,2011,416-419.
[9]Commons Collections.[CP/OL].http://commons.apache.org/proper/commons-collections/.
[10]Commons Primitives.[CP/OL].http://commons.apache.org/proper/commons-primitives/.
[11]Do H,Elbaum S G,Rothermel G.Supporting controlled experimentation with testing techniques:An infrastructure and its potential impact[J].Empirical Software Engineering,2005,10(4):405-435.
[12]Arcuri A,Fraser G.On parameter tuning in search based software engineering[C]//In:Proceedings of the 3rdInternational Conference on Search Based Software Engineering.Berlin,Germany:Springer,2011,33-47.
