一种改进型Q学习算法及其在行为树中的应用
2018-01-03刘洪星
涂 浩 刘洪星
(武汉理工大学计算机科学与技术学院 湖北 武汉 430063)
一种改进型Q学习算法及其在行为树中的应用
涂 浩 刘洪星
(武汉理工大学计算机科学与技术学院 湖北 武汉 430063)
游戏中的非玩家角色(NPC)通过学习获得智能,因此学习算法的设计是一个关键问题。提出一种改进型Q学习算法(SA-QL),它以模拟退火算法为基础,在状态空间、探索策略、报酬函数等方面改进了Q学习算法的不足。将该算法运用到行为树的设计中,使NPC能在游戏过程中实时学习,调整行为树中逻辑行为的最佳执行点,从而产生合适的行为响应。实验结果表明,SA-QL算法比传统Q学习算法效率更高,控制NPC的效果更好。
游戏人工智能 行为决策 Q学习 行为树
0 引 言
行为树由于其简单、灵活和模块化等优势,被广泛用于设计游戏中非玩家角色(NPC)的行为决策。然而,对于大多数行为树的设计,所有任务的控制细节通常都是手动编码的,因此开发过程往往花费大量的时间和精力。不好的行为树设计可能导致NPC行为异常,从而破坏玩家的体验。在行为树的设计过程中,需要根据NPC与游戏世界的反馈信号不断调整其结构,从而使NPC更好地适应环境。Q学习算法具有良好的在线自适应和对非线性系统的学习能力,采用试错的方式与环境进行交互,根据环境对动作的评价性反馈信号改进行动方案以适应环境。将Q学习算法运用于NPC的行为树设计是一种可行的方法。然而在具有大规模状态空间或连续状态空间的游戏任务中,该方法也面临着一些问题,其中之一就是在动作选择时的“探索和利用”问题:如果仅根据当前状态动作值选择最优动作,则容易陷入局部最优,而无法得到最优解;如果为了跳出局部最优而选择非最优的动作,获取更多的知识,又往往会降低了算法的性能。
目前将Q学习算法应用于游戏人工智能领域的研究还较少。Florez-Puga等[1]将案例推理应用到行为树中,使得NPC可以从知识库中动态获取行为。Ibrahim Mahmoud[2]将HTN应用于NPC的行为决策中,得到了较好的效果。但是这些方法往往过度依赖于经验数据,需要手动生成经验记录。为了减少对于经验数据的依赖,让NPC的行为更加智能,关键是赋予其学习能力,调节自身动作以更好地适应环境。针对以上问题,本文提出了一种改进型Q学习算法,它是基于模拟退火算法的Q学习算法SA-QL(Simulated Annealing-Q-Learning),从状态空间、探索策略、报酬函数等方面改进Q学习算法,利用模拟退火算法中的Metropolis准则控制NPC在学习进程中适当地减少探索次数。然后将SA-QL算法运用到行为树的设计,最后通过实验进一步对学习结果进行分析并优化行为树。实验结果表明:该方法可以提高Q学习算法的收敛速度,帮助游戏设计者减少在行为树设计中耗费的精力,实现自动化行为树设计,并使NPC在游戏过程中实时学习,更好地适应环境,提高了NPC的智能。
1 相关研究
1.1 行为树
行为树是由行为节点组成的树状结构。行为树处理周围游戏世界变化的任务是由条件节点来完成的,这相当于每次遍历行为树时,条件节点都向周围世界发出某种“询问”,以这种方式来监视游戏世界发生的事情。行为树中的每个节点表示一个行为,节点是有层次的,子节点由其父节点来控制,从而决定接下来做什么,父节点的类型决定了某种高级控制策略。节点不需要维护向其他节点的转换,节点的模块化被大大增强了。在大型的游戏逻辑设计当中,如果需要为多个NPC设计不同的行为树,可能这些NPC的行为树在某个子树处相同。为了避免重复的工作,可以复用这些子树,在行为树的某些位置增加单个行为节点或行为子树。行为树的选择器中包含随机选择节点和概率选择节点,若能合理地安排节点的权值,便能较好地实现合理的随机性[3-5]。模块化、可复用性、并发等特点使得行为树有效地降低了NPC行为设计的复杂性。
虽然已被大量的游戏和项目使用,行为树仍具有以下不足之处:1) 必须在每个行为节点处手动编码,随着游戏规模增大,行为树变得很复杂,并且调试比较困难;2) 缺乏学习机制,无法实现自动行为树设计。由于以上原因使得行为树的设计不够高效。
1.2 Q学习算法
Watkins提出的Q学习算法用于解决不确定环境下的学习问题,通过学习选择能达到目标的最优动作。Q学习的模型如图1所示。
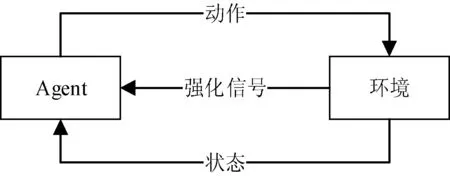
图1 Q学习模型图
定义Q(s,a)为Agent在状态s下执行动作a所返回强化信号的累计值函数。Agent通过观察环境得到状态s,Agent按策略π选择动作a并执行,在下一时刻,Agent 收到环境反馈的强化信号(报酬值)并作用于Q(s,a),更新策略π并达到新状态。当满足一定条件,Q(s,a)值会收敛到某一确定值。在做决策时只需要比较s下执行每个动作的Q值,即可明确s下的最优策略,无需考虑s的后续状态[6-7]。Q(s,a)值定义如下:
Q(s,a)=(1-α)Q(s,a)+α[r+γQ(s′)]
(1)
式中:r为状态s下执行a动作得到的瞬时报酬值;γ为折扣因子;α表示学习率,Q(s′)为s后续状态下的最大Q值。
在学习过程中,Agent采用试探的方式与环境交互,得到最优的控制策略。为了避免其动作选择时的“探索和利用”问题,通常给每个动作设定固定的执行概率,并按照概率对当前非最优动作进行探索,用贪心策略和随机探索策略相结合的方式分配探索和利用的时间。常用的方法是ε-贪心策略。ε-贪心策略设定具有最高Q值函数的动作被选中的概率为ε,如果该动作没有被选择,则从所有动作中随机地选择一个动作执行。这种方法在学习开始阶段主动探索非最优动作,能避免“局部最优”的问题,取得一定的效果。随着学习的不断深入,Agent所取得的知识趋于精确,应减少对非最优动作的探索,此时ε-贪心策略仍以不变的概率探索非最优动作,会造成不必要的探索,影响Q学习算法的收敛速度。
2 SA-QL算法
为了减少在学习知识趋于精确之后的探索次数,本文将模拟退火算法应用于Q学习的动作选择策略中,提出了SA-QL算法。模拟退火算法可以保证在追求全局最优解的同时,避免陷入局部最优[8]。该算法主要根据Metropolis准则对应的转移概率来决定是否接受从解到新解的局部变化。由于模拟退火算法不完全拒绝恶化解,使得它可以跳出局部最优解,避免陷入局部搜索。随着学习的深入,通过调整温度等参数的变化来自动减少Q学习中的探索次数,可有效平衡“探索-利用”问题。SA-QL算法描述如下:
输入:动作集合A(s),<状态-动作>的值函数Q(s,a);初始温度temperature;学习率α,报酬函数r,折扣因子γ。
输出:优化的<状态-动作>的值函数Q(s,a)。
处理过程:
1.选择待训练的状态s,当+前动作为ap;

3.执行下一步动作,更新Q(s,a)和状态动作:
Q(s,a)=(1-α)Q(s,a)+α[r+γQ(s′)];s=s′;ap=ar
4.若s不是终止状态,则转至第2步;
5.若Q(s,a)收敛,算法结束;否则,依等比降温策略重新计算temperature,转至第2步。
该算法改善了基于ε-贪心算法的Q学习算法中由于ε固定不变带来的收敛速度慢问题,在学习过程中,随着温度的降低,Agent探索次数将随之减少,最终几乎不存在探索,从而提高了算法的性能。
3 基于SA-QL算法的行为树
在行为树的设计中应用SA-QL算法,将经SA-QL算法优化的<状态-动作>的值函数Q(s,a)运用到行为树的设计中,可在构建行为树时,减少刚开始时需要设计的节点,特别是条件节点,并能调整逻辑行为的最佳执行点,从而对整个行为树进行重排和优化。
SA-QL算法应用在在行为树构建的预处理阶段。首先分析行为树并找到最深的顺序节点,这些节点将作为学习中的动作,在Q值表中建立对应的Q值。为了支持在线学习,将生成的Q值表根据动作划分为相应的Q值子表。子表根据Q值从大到小进行排序,进而得到Q条件节点(动作的状态允许列表)代替之前的条件节点。如图2所示。后续学习过程将根据报酬更新Q值,然后采用相应的动作选择策略。随着学习的深入,将Q条件节点中的状态过滤,只剩下部分高Q值的对应状态。

图2 将Q值信息整合到行为树中
在行为树的学习过程中还要用到Q条件节点中的最大Q值。如图3所示,以最大的Q值替换其父节点的Q值,并且重排行为树,使节点的子树从左至右按照子树的Q值从大到小排列。重排行为树使得行为节点之间的执行顺序更加合理,便于找到逻辑行为的最佳执行点。
按照上述方式递归至根节点,完成重排行为树。这里不必像一般行为树编辑器一样手动地去修改节点,SA-QL算法学习过程中会自动重排行为树,重排后的行为树的执行与原行为树的执行类似。只是在执行到Q条件节点的时候,需要在该动作节点的状态允许列表查找当前状态,如果列表中存在对应状态则执行后续子节点,否则返回失败状态。
4 实验与结果分析
4.1 实验过程
实验平台采用一款跨平台的专业游戏引擎Unity。在一个简单地图中进行五对五的NPC对战实验。 NPC的初始位置是随机分布在地图中,以一方NPC全部被消灭或执行超时作为实验结束标志。为了比较两种算法的收敛速度,在实验过程中分别采用传统Q学习算法(以ε-贪心算法作为动作选择策略)和SA-QL算法重排NPC的行为树。NPC的初始行为树如图4所示。
4.2 状态和动作
在理论上,Q学习以所有状态完全收敛,获得全状态空间的最优策略为学习目标。Q学习状态收敛所需的探索次数随状态空间和动作空间的增加呈指数增长。在实际控制中,Q学习不可能遍历系统所有状态,因为对连续的环境变量的遍历,会造成“维数灾难”的问题。
实验对状态空间和动作空间进行泛化,通过一定程度地牺牲控制精度来提高算法收敛速度。利用合适的知识表示设计状态聚类或状态空间离散化的方法,对环境因素进行模糊化和离散化处理,并通过建立Q值函数,状态-动作模型实现状态空间和动作空间的泛化,减少Q学习所需探索和学习的状态空间,从而加快学习过程的收敛速度。
在根据经验数据初始化Q值表时,考虑了以下几点规则:
1) 行为节点允许的状态对应的Q值必须大于0;
2) 同一行为节点允许的状态数目不易过多;
3) 尽量减小同一动作的允许状态的Q值的差距。
NPC的状态空间主要由血量HP,离最近加血处的距离Db,离最近敌人的距离De,是否正在被攻击IsAttacked四个方面环境因素构成。相应环境因素经模糊化和离散化处理后如下:
• 血量HP:(none,low,medium,high);
• 离最近加血处的距离Db:(none,near,medium,far);
• 离最近敌人的距离De:(none,near,medium,far);
• 是否正在被攻击IsAttacked:(yes,no)。
血量中的none表示Agent已被消灭,距离为none表示没有察觉或距离过远。
NPC的主要行为定义如下:
• 寻觅加血:寻找并移至加血处,获取加血效果;
• 群聚:朝着队友聚集的方向移动;
• 寻找敌人:如果没有找到敌人的位置,就调整方向以找到敌人的位置;
• 交战:与敌人交战;
• 漫步:在地图上一定范围随机移动;
• 逃跑:朝着一个远离敌人的方向逃跑。
4.3 报酬函数
Q学习状态收敛所需的探索次数与该状态报酬值距离收敛报酬值的步长呈指数关系。为了加快算法的收敛速度,实验减小动作的报酬函数边界,报酬信号将结合先验知识和学习更新过程中的效果,以加权的方式综合报酬函数。
为了让NPC的行为选择符合人类认知的行为逻辑,在设计报酬函数时,状态离目标状态越近,执行动作到达该状态的报酬值越高。表1是根据先验知识制定<状态-动作>报酬函数表。记NPC在状态s下执行动作a的报酬值为R1(s,a),未出现的情况默认报酬函数值为0。表1中符号定义为:L=low;M= medium;H=high;N=near;F=far。同时,报酬函数结合学习过程中的报酬R2(NPC血量增加,奖励;NPC血量减少,惩罚;NPC消灭敌人,奖励;NPC被消灭,惩罚)。

表1 先验知识<状态-动作>报酬函数表
综合考虑以上信息,以加权的方法得到报酬函数:R=ω1·R1+ω2·R2,其中:ω1、ω2为对应的加权系数,均大于或等于0且两者之和为1。
4.4 实验结果分析
重排后的行为树如图5所示。可以看出重排后的行为树与初始行为树的不同,学习的结果倾向于游荡和群聚对NPC生存下来的目标作用较小。另一个变化是攻击行为子树被赋予更高的优先级,撤退的优先级高于攻击,说明NPC更倾向于被动攻击。下面从对战结果中验证重排后行为树的合理性。

图5 重排后的行为树
图6显示了实验结果,每组实验进行5次对战,记录以下结果:生存下来的NPC数量、生存下来NPC的血量,实验得分由二者综合所得。根据实验结果可知,SA-QL算法的收敛速度明显比传统Q学习算法快。Q学习本身强调采用试错的方式与环境进行交互,根据环境对动作的评价性反馈信号改进行动方案以适应环境。SA-QL算法可以在与环境的不断交互中更新状态动作值函数,改进动作选择策略,随着学习的不断深入,该方法能有效地减少探索次数,加快学习的收敛速度。从实验结果中还可以看出行为树重排之后的合理性,将SA-QL算法应用于NPC的行为树设计中可实现行为树的自动重排,调整其逻辑行为的最佳执行点,使得NPC的行为更加智能、拟人化,这对于游戏中的NPC行为设计有一定的实用价值。
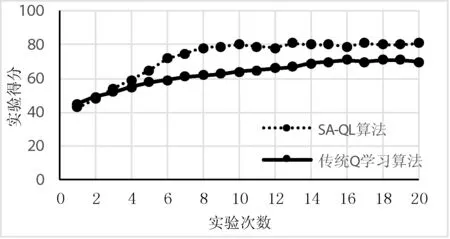
图6 两种算法的实验得分
5 结 语
本文研究了游戏人工智能中NPC的行为决策问题,以模拟退火算法为基础,提出了一种改进型Q学习算法,并将其应用到行为树的构建当中。实验结果表明,该方法在行为树的设计上为游戏设计者带来诸多方便,能帮助确定NPC逻辑行为的最佳执行点,提高Q学习算法的收敛速度,实现自动化的行为树设计,让NPC表现得更加智能。为了进一步优化Q学习算法在行为树中的效果,在结合模拟退火算法和Q学习算法的过程中,如何选择合理的降温策略以及Q学习算法的值函数,是下一步的研究方向。
[1] Puga G F,Gómez-Martín M A,Díaz-Agudo B,et al.Dynamic Expansion of Behaviour Trees[C]//Artificial Intelligence and Interactive Digital Entertainment Conference,October 22-24,2008,Stanford,California,USA.2008.
[2] Mahmoud I M,Li L,Wloka D,et al.Believable NPCs in serious games:HTN planning approach based on visual perception[C]//Computational Intelligence and Games.IEEE,2014:1-8.
[3] Kyaw A S,Peters C,Swe T N.Unity 4.x Game AI Programming[M].Packt Publishing,2013.
[4] Robertson G,Watson I.Building behavior trees from observations in real-time strategy games[C]//International Symposium on Innovations in Intelligent Systems and Applications.IEEE,2015:1-7.
[5] Dey R,Child C.QL-BT:Enhancing behaviour tree design and implementation with Q-learning[C]//Computational Intelligence in Games.IEEE,2013:1-8.
[6] 姜文军.网络游戏中人工智能的研究及应用[D].上海交通大学,2013.
[7] Nicolau M,Perez-Liebana D,O’Neill M,et al.Evolutionary Behavior Tree Approaches for Navigating Platform Games[J].IEEE Transactions on Computational Intelligence & Ai in Games,2016,9(3):227-238.
[8] 李炎武,陈渝,曾庆维.基于强化学习的非玩家角色行为改进[J].四川大学学报(自然科学版),2014,51(5):915-920.
ANIMPROVEDQ-LEARNINGALGORITHMANDITSAPPLICATIONINBEHAVIORTREE
Tu Hao Liu Hongxing
(CollegeofComputerScienceandTechnology,WuhanUniversityofTechnology,Wuhan430063,Hubei,China)
The non-player character (NPC) in a game gains intelligence by learning, so the design of the learning algorithm becomes the key issue. In this paper, an improved Q-learning algorithm (SA-QL) was proposed. Based on simulated annealing algorithm, the Q-learning algorithm was improved in the aspects of state space, exploration strategy and reward function. Then the algorithm was applied to the design of behaviour tree, so that the NPC could learn and adjust the best execution point of the logical behaviour in the process of the game in real time, and produced the appropriate behavior response. Experimental results showed that the SA-QL algorithm was more efficient than the traditional Q-learning algorithm, and had better control effect on NPC.
Game AI Behaviour decision Q-learning Behaviour tree
2016-12-06。国家自然科学基金项目(61472294);中央高校基本科研业务费基金项目(15521004)。涂浩,硕士,主研领域:机器学习,信息系统集成。刘洪星,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.12.045
