链路预测方法与网络结构的相关性
2017-12-20李旗旗
李旗旗,徐 敏
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
链路预测方法与网络结构的相关性
李旗旗,徐 敏
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
作为数据挖掘的一个分支,链路预测经过多年研究,已经提出了多种链路预测方法。基于网络结构的链路预测方法因为在相似结构的网络中具有普适性,在近年来得到了广泛关注。然而,由于每个复杂网络的结构不同,链路预测方法的预测准确度差别较大,同一种链路预测方法不可能在所有网络中都获得理想的预测效果。研究链路预测方法的准确度和网络结构的相关性可以在已知一个复杂网络结构的情况下,选择合适的链路预测方法,也可以为链路预测的改进提供理论依据。通过实验计算出常见链路预测方法在每个网络上的预测准确度,发现链路预测方法的预测准确度在不同结构的网络中是不同的,结合网络的结构对实验结果进行分析,并据此提出了一种简单的链路预测方法选择方案。
复杂网络;链路预测;网络结构;相似性
0 引 言
自然界中大量的复杂系统都可以通过各种各样的网络表现出来。一个典型的网络包含了一定数量的节点和连接这些节点的边,其中节点表示的是一个真实系统中的个体,而边则代表了个体之间的某种关系。如果两个个体中存在某种关系,那么对应的两个节点之间就存在一条连边。
今天,在生活中存在各种各样的复杂网络,比如社交网络、生物网络、技术网络等,每一个网络都有自己独特的网络结构和属性。社交网络中著名的“六度分离”就是社交网络的一个独特网络结构。通过网络的结构和属性,可以尝试去预测网络在下一个时间段的变化,从而为实际生产提供正确的指导和建议。链路预测就是一个很好的选择。
复杂网络中的链路预测通过计算网络中尚未连边的两个节点之间在未来产生连边的概率达到预测的目的[1]。其研究思路和方法主要基于马尔可夫链和机器学习。Sarukkai使用马尔可夫链对网络进行了链路预测和路径分析[2]。之后学者对基于马尔可夫链的链路预测方法进行了扩展,但是在这其中的很多方法都用到了网络的节点信息。不少研究表明,使用节点信息进行链路预测可以获得比较好的结果[3],但是现实中很多网络都难以获得节点信息,而且即使获得了节点信息,也不能保证信息的可靠性。因此,国内外学者越来越关注基于网络结构的链路预测方法[4]。相比节点属性信息,网络的结构更加可靠。然而,链路预测方法在某种程度上都有自己的局限性,并不能在所有网络上都有很好的预测准确度,所以对于一个已知网络,如何寻找到一个合适的链路预测方法是很重要的。
1 链路预测方法
用G(V,E)表示一个无向网络,其中V表示节点集,E表示边集。G[t,t1]表示G在[t,t1]时间段的情况,那么在(t1,t2]时间段G的情况就是G(t1,t2]。链路预测关注的就是如何预测网络G从[t,t1]到(t1,t2]的变化。
链路预测经过多年的研究,提出了各种各样的方法。选择其中常用的10种方法,为了能更好地介绍这些方法,首先介绍一些在文章中使用的符号。其中,x,y表示节点,N表示网络中节点的数量。kx和ky表示节点x和y的度数,Γ(x)和Γ(y)分别表示节点x和y的邻居节点集合。
基于局部信息的相似性方法是指仅通过节点的局部信息(如节点的度和最近邻等)就可以计算出相似度的方法。这种方法的优势在于时间复杂度低,适用于大型的网络应用。
1.1 共同邻居(CN)
共同邻居是一种比较简单的链路预测方法,其基本假设为:如果两个尚未连边的节点有更多的共同邻居,那么它们更倾向于连边。这种假设很容易理解,比如在社交网络中,如果两个陌生人有很多共同的朋友,那么他们将来成为朋友的概率也很大[5]。又比如,Newman等发现在科学家合作网络中,如果两个科学家的共同合作伙伴很多,那么他们将来也很有可能会合作[6]。其定义为:
sxy=Γ(x)∩Γ(y)
(1)
1.2 Salton
该方法是基于CN方法并且考虑连边两个端点节点度的影响[7]。它的定义为:
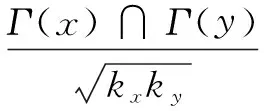
(2)
1.3 Jaccard
100多年前被提出,用于计算集合的相似度[8]。它的定义为:
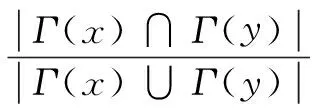
(3)
1.4 大度节点有利(Hub Promoted Index,HPI)
HPI方法[9]的定义为:
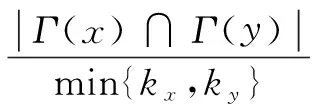
(4)
由于分母只有度比较小的节点决定,所以度比较大的节点更容易和其他节点形成较高的相似性。
1.5 大度节点不利(Hub Depressed Index,HDI)
其定义与HPI相似,只是分母取节点度数的较大值[10]。
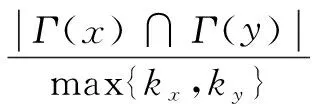
(5)
1.6 Adamic-Adar(AA)
其思想是度小的共同邻居节点的贡献大于度大的共同邻居节点[11]。例如,在微博网络中,受关注较多的人往往是某个领域的专家或者名人,因此共同关注他们的人之间可能并不拥有特别相似的兴趣。相反,如果两个人共同关注了一个粉丝很少的人(非专家),那么说明这两个人确实具有相同的兴趣爱好或者重叠的社交圈,因此有更高概率相连。
(6)
1.7 Resource-Allocation(RA)
考虑网络中没有直接相连的两个节点x和y,从x可以传递一些资源到y,而在此过程中,它们的共同邻居就成为传递的媒介[12]。
假设每个媒介都有一个单位的资源并且平均分配传给它的邻居,则y可以接收到的资源就可以定义为节点x和y的相似度,即:
(7)
当网络的平均度较小时,RA和AA区别不大;但是当平均度较大时,就有很大区别了。
1.8 局部路径(Local Path,LP)
LP方法在CN方法的基础上考虑了三阶路径的影响,其定义为:
(8)
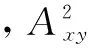
1.9 Katz
Katz方法考虑了网络的所有路径[13],其定义为:
(9)
其中,β用来调节高阶路径的贡献。当β值很小时,高阶路径的贡献也就很小了,此时Katz的预测结果接近于局部路径方法。
2 实验数据与评价方法
为了比较每一种方法的准确度,实验中选取了7组提取自真实网络的数据集,实验结果通过AUC值进行评价。
2.1 数据集
USAir:网络中的每个节点对应一个机场,如果在两个机场之间存在一条直达航线,那么两个机场之间存在一条连边。
NS:这个网络是由M.Newman在2006年收集的,其中包含了在网络科学领域的科学家发表的论文。网络中的节点表示科学家,两个节点之间存在连边说明两个科学家合作发表过论文。
Power:美国西部电网,是由Watts和Strogatz收集的。节点表示变电站或者换流站,连边表示它们之间有高压线。
Router:Internet路由层次网络,每个节点表示一个路由器,如果两个路由器之间可以直接进行数据包交换,则它们之间存在一条连边。
Yeast:蛋白质相互作用网络,节点表示蛋白质,边表示它们之间的相互作用。
Wiki-vote:维基百科中的活跃用户可以被提名为管理员,当一个用户被提名时,维基百科会组织选举,获得支持最多的用户晋升为管理员。用户表示节点,选举行为对应于网络中的边,如果用户A给用户B投票,那么就有一条边从A指向B。
Facebook:Facebook数据集是通过其应用从调查的参与者中收集到的,节点表示用户,边表示两个用户之间的好友关系。
2.2 评价方法
一个时间序列中的预测意味着要将数据集按照时间戳分为训练集和测试集,其中训练集视为已知的信息,测试集视为未知信息,这个集合中的所有信息都不能被用来预测[14]。为了保证在抽样后训练集仍然保持连通,实验中采用的划分策略是,在随机抽样的基础上加入网络连通性判断机制,即首先在给定的网络中选取一条边,然后判断这条边的两个节点在删除这条边之后是否仍然可以连通,如果可以则将该边加入测试集,否则放弃,然后重新随机抽取一条边。
使用AUC来衡量链路预测方法的准确度。AUC是指ROC曲线下的面积,在信号探测理论中,ROC曲线用来评价某种分类器的分类效果[15]。这种方法同样可以用来衡量链路预测方法的准确度。
对所有未观察到的连边进行排名,AUC的值可以理解为:在测试集中随机选择一条连边的得分高于随机选择的一条不存在的边的概率。在算法的实现中,通常是计算每个未观察到的连边的得分,而不是给出一个有序的列表,因为后者需要更大的时间复杂度。然后,每次从测试集中随机选取一条连边,再随机从不存在的连边中选取一条连边,比较它们的得分。如果在n次实验中,有n'次前者的分数更高,n''次两者分数相同,那么AUC的值为:
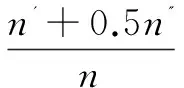
(10)
从表达式中可以看出,随机选择法的AUC值约为0.5,所以一个链路预测算法的AUC值大于0.5的程度就是该算法比随机算法精确的程度。在实验中,为了减少随机抽样对结果的影响,AUC的计算采取多次计算求平均值的方法。
3 实验结果与分析
实验中计算了每个链路预测方法在所有7个网络数据集上的预测准确度,结果显示为AUC值。表1是每种链路预测方法的准确度。

表1 链路预测方法的准确度(AUC值)
可以看出,10种链路预测方法基本上都给出了好于随机选择方法的预测效果,并且基于共同邻居的方法(CN、Salton、Jaccard、HPI、HDI、AA、RA)预测准确度相差不多,在CN基础上考虑连边的两个端点度的影响整体表现不如CN,AA和RA方法的准确度相比于其他方法有较小的提升。
但是也可以看出一些特例,比如在Power和Router网络中,除了Katz,其他方法的预测准确度都比较一般;在Facebook和Wiki-vote网络中,Katz方法在β=0.01时AUC值很低,在β=0.001时预测效果很好。
针对实验结果的一些现象,将根据网络结构分析这些现象的原因。表2是在实验中使用的网络的一些结构信息。
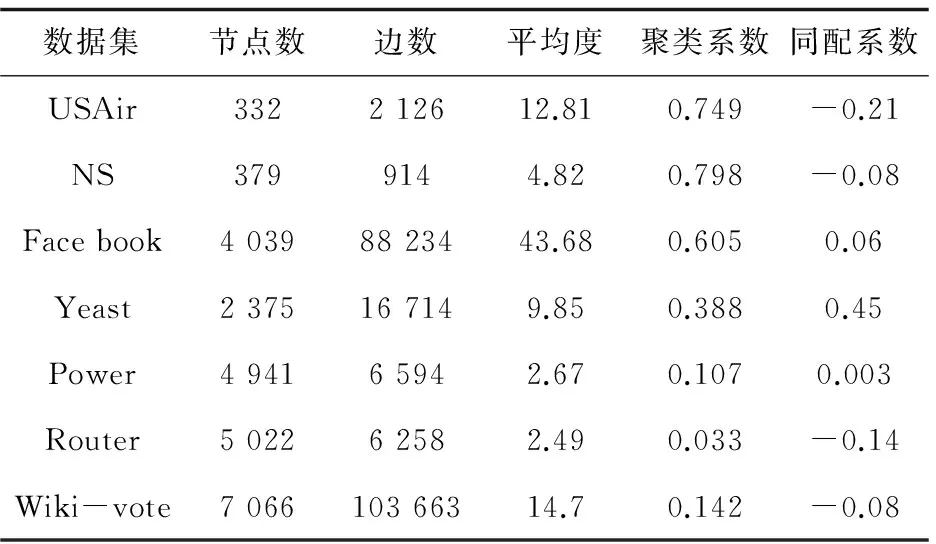
表2 网络结构信息
Salton、Jaccard等方法在USAir和Wiki-vote上的预测效果和CN有比较明显的差距,可能的原因是这两个网络中存在比较明显的“富人俱乐部现象”,即度数大的节点相对于度数小的节点更容易和其他度数大的节点形成连边,而Salton等方法惩罚了连边中两个端点的度数,在一定程度上对预测结果起到了消极作用。
Power和Router网络的聚类系数很小,说明节点之间的紧密程度很低,它们的平均度很小也说明了这一点。因此,这两个网络中的两个节点之间的共同邻居节点个数也很少,无法为这两个节点是否相似提供足够的证据,这也就是为什么基于共同邻居的方法预测结果都不好的原因。基于路径的预测算法受这个问题的影响较小,可以看到LP和Katz的预测结果都不错。唯一值得注意的是,LocalP对于Power的预测结果不是很好,这是因为LP只是考虑了三阶路径,而Power网络不仅稀疏而且直径很大,仅考虑三阶路径性能提升有限。
Katz由于考虑了全路径,所以它在所有的网络上都有比较好的表现,当然这也意味着Katz方法的时间复杂度远远高于其他方法。在Wiki-vote和Facebook中,Katz在参数β=0.01时出现了比较明显的异常情况,这恰好体现了Katz方法的一个明显问题。根据Katz的公式可以看到,其时间复杂度相当高,这对于稍微大型的网络都是无法接受的,但是在β小于邻接矩阵最大特征值的倒数的情况下,Katz的公式可以根据级数收敛转化为:
S=(I-βA)-1-I
(11)
而矩阵求逆的时间复杂度为O(N3)量级,从而大大减少了时间开支。Facebook和Wiki-vote的邻接矩阵的最大特征值均小于0.01而大于0.001,而实验中使用的是转化之后的公式,因此导致Katz预测结果的异常。
另外,Yeast网络的聚类系数同样很小,但是CN、AA等方法也得到了比较不错的预测效果,可能的原因有两个:
(1)Yeast和Power、Router相比平均度较大,根据聚类系数的定义,节点的度数会在一定程度上抑制包含该节点的三角形的个数对聚类系数的贡献。如果一个节点的度很大,即使包含它的三角形个数很多,也会表现出较低的聚类系数;
(2)Yeast网络中度数较小的节点都有比较大的聚类系数,由于度数较大的节点聚类系数较小,导致整体的聚类系数较小,但是节点对之间有足够的共同邻居节点来证明它们之间的相似性。
根据上述分析,对于一个结构已知的网络,一种简单的链路预测方法推荐方案描述如下:
(1)对于聚类系数和平均度较小的网络,采用基于路径的方法,其中Katz方法在大多数情况下获得了较好的效果。需要注意的是,Katz方法在使用之前要计算β的取值上限,LP方法虽然仅考虑了局部路径,但是没有参数的限制。
(2)对于聚类系数和平均度较大的网络,基于共同邻居的方法能够获得较好的结果,并且在时间复杂度上要优于基于路径的方法。
(3)在基于共同邻居的方法中,CN、AA和RA可以作为优先选择的方法,AA和RA在异配性比较强的网络中会显示出比CN更好的预测效果。
4 结束语
文中介绍了10种链路预测方法,并且在7个真实网络中比较了它们的预测准确度。实验结果表明,对于平均度和聚类系数较小的网络,基于共同邻居的方法往往不能给出一个很好的预测效果,但是Katz可以获得很好的预测准确度。
同时还发现,社交网络的邻接矩阵的最大特征值的倒数往往较小。在这种情况下,对Katz方法的参数值的选取有一定限制,此时可以考虑使用基于局部路径的方法。可以看到,在链路预测中,获得一个网络的结构对于寻找一个合适的链路预测方法很有帮助。
[1] 吕琳媛.复杂网络链路预测[J].电子科技大学学报,2010,39(5):651-661.
[2] Sarukkai R R.Link prediction and path analysis using Markov chains[J].Computer Networks,2000,33(1-6):377-386.
[3] 刘大伟,吕元娜,余智华.一种改进的复杂网络链路预测算法[J].小型微型计算机系统,2016,37(5):1071-1074.
[4] 傅颖斌,陈羽中.基于链路预测的微博用户关系分析[J].计算机科学,2014,41(2):201-205.
[5] 丁兆云,贾 焰,周 斌,等.社交网络影响力研究综述[J].计算机科学,2014,41(1):48-53.
[6] Newman M E J. Clustering and preferential attachment in growing networks[J].Physical Review E,2001,64(2):025102.
[7] Salton G,Mcgill M J.Introduction to modern information retrieval[M].[s.l.]:McGraw-Hill,1983.
[8] Jaccard P.Etude de la distribution florale dans une portion des Alpes et du Jura[J].Bulletin De La Societe Vaudoise Des Sciences Naturelles,1901,37(142):547-579.
[9] Ravasz E,Somera A L,Mongru D A,et al.Hierarchical organization of modularity in metabolic networks[J].Science,2002,297(5586):1551.
[10] Zhou T,Lu L,Zhang Y C.Predicting missing links via local information[J].Physics of Condensed Matter,2009,71(4):623-630.
[11] Adamic L A,Adar E.Friends and neighbors on the web[J].Social Networks,2003,25(3):211-230.
[12] Ou Q,Jin Y D,Zhou T,et al.Power-law strength-degree correlation from resource-allocation dynamics on weighted networks[J].Physical Review E,2007,75:021102.
[13] Katz L.A new status index derived from sociometric analysis[J].Psychometrika,1953,18(1):39-43.
[14] Lü L,Zhou T.Link prediction in complex networks:a survey[J].Physica A Statistical Mechanics & Its Applications,2011,390(6):1150-1170.
[15] Fawcett T.Introduction to ROC analysis[J].Pattern Recognition Letters,2006,27(8):861-874.
CorrelationbetweenLinkPredictionMethodandNetworkStructure
LI Qi-qi,XU Min
(School of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 211106,China)
As a branch of data mining,link prediction has been studied many years in the computer field,and a variety of link prediction methods are proposed.The link prediction method based on network structure has been widely concerned in recent years,because it is common in the network with similar structure.However,due to the different structure of complex networks,the prediction accuracy of the link prediction method is different,and the same link prediction method can’t get the desired results in all networks.Analyzing the correlation of network structure and the accuracy of link prediction method can help to choose a right link prediction method for a given network,and provide the theoretical basis for improving link prediction.The prediction accuracy of the link prediction method is calculated by the experiment,and the results show that it exists difference in the different network structure.Analyzing experimental results combined with the network structure,a simple selection of link prediction method is proposed.
complex networks;link prediction;network structure;similarity
TP393
A
1673-629X(2017)12-0057-04
10.3969/j.issn.1673-629X.2017.12.013
2016-12-11
2017-04-19 < class="emphasis_bold">网络出版时间
时间:2017-08-01
国家“973”重点基础研究发展计划项目(2014CB744900)
李旗旗(1991-),男,硕士研究生,CCF会员(E200041166G),研究方向为机器学习、链路预测;徐 敏,博士,副教授,研究方向为模式识别、机器学习。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170801.1557.078.html
