基于社交网络分析和XGBoost算法的互联网客户流失预测研究*
2017-12-18王重仁韩冬梅
王重仁,韩冬梅
(上海财经大学 信息管理与工程学院,上海 200433)
基于社交网络分析和XGBoost算法的互联网客户流失预测研究*
王重仁,韩冬梅
(上海财经大学 信息管理与工程学院,上海 200433)
针对互联网行业的客户流失预测问题,提出了一种社交网络分析和机器学习相结合的客户流失预测方法。考虑到社交活动对用户流失的影响,首先采用社交网络分析方法从用户社交数据中提取特征,然后使用XGBoost(Extreme Gradient Boosting)算法来进行客户流失预测,最后将该方法与其他机器学习算法(Logistic回归、支持向量机和随机森林)进行比较。实验结果表明,所提出的社交网络分析和XGBoost相结合的客户流失预测方法优于传统方法。
客户流失预测;社交网络分析;机器学习;XGBoost
0 引言
近年来,国内互联网行业发展迅速,市场竞争越来越激烈,同时,随着市场的逐渐饱和,获取新客户变得越来越困难。因为获取一个新客户的成本远远大于留存一个现有客户的成本[1],因此,越来越多的企业关注客户留存,客户留存可以维系客户关系,有效延长客户生命周期[2]。
客户留存的关键点在于防止客户流失,客户流失是指客户终止或者显著减少使用企业提供的产品或服务,而转向了其他企业[1]。客户流失模型的实质是基于客户的人口统计特征、历史行为等信息,建立流失预测模型,计算客户的流失概率。进行潜在流失客户的预测分析并制定有针对性的挽留策略,能够减少企业客户流失率和利润损失[3]。
目前客户流失预测研究中,大多专注于研究客户个体行为,没有考虑用户之间关系的影响。近几年,在一些研究中,社交网络分析方法开始应用于客户流失预测模型,并且研究表明,考虑社交网络影响后模型预测能力得到了提升[4]。这种方法是从社交网络中提取特征作为变量,然后结合其他的特征,使用机器学习分类算法来进行预测。比如,Benedek等人[5]利用社交网络分析来进行电信行业客户流失预测研究。
随着经济与社会的发展,数据挖掘技术广泛应用到各个领域[6]。近年来,陈天奇[7]对GBDT(Gradient Boosting Decision Tree)算法进行改进,提出了一种设计高效、灵活并且可移植性强的最优分布式决策梯度提升库(Extreme Gradient Boosting,XGBoost),该算法曾经在国外数据竞赛平台Kaggle的比赛中多次取得了最好的成绩。目前该算法已被用于银行破产预测[8]、网络入侵检测[9]等领域,然而目前尚未有研究将该算法用于用户流失预测。
本文以国内一家互联网金融平台为研究对象。在互联网金融行业,为更好地吸引新用户注册,一般都会建立一套好友推荐奖励机制,这种好友推荐行为就构成一个复杂的社交网络。随着互联网行业中好友推荐数据的不断积累,这部分数据中隐藏了大量有价值的信息,因此如何深入挖掘这部分信息的价值,以此来提升流失模型的预测能力,是一个值得研究的问题。
1 方法
1.1 变量
本文将变量分为两类:个体变量和社会网络变量。个体变量包括用户的基本信息和用户行为变量,这些变量描述用户的个体特征,未考虑个体之间的关联信息。相反,社会网络变量考虑了用户之间的关联信息。
个体变量分为用户基本信息变量和用户行为变量。用户基本信息变量包括:性别、年龄和地区。行为变量是从用户的交易行为数据中提取的变量,包括:时间长度、频率、金额、间隔时间4类,共计12个变量。变量如表1所示。
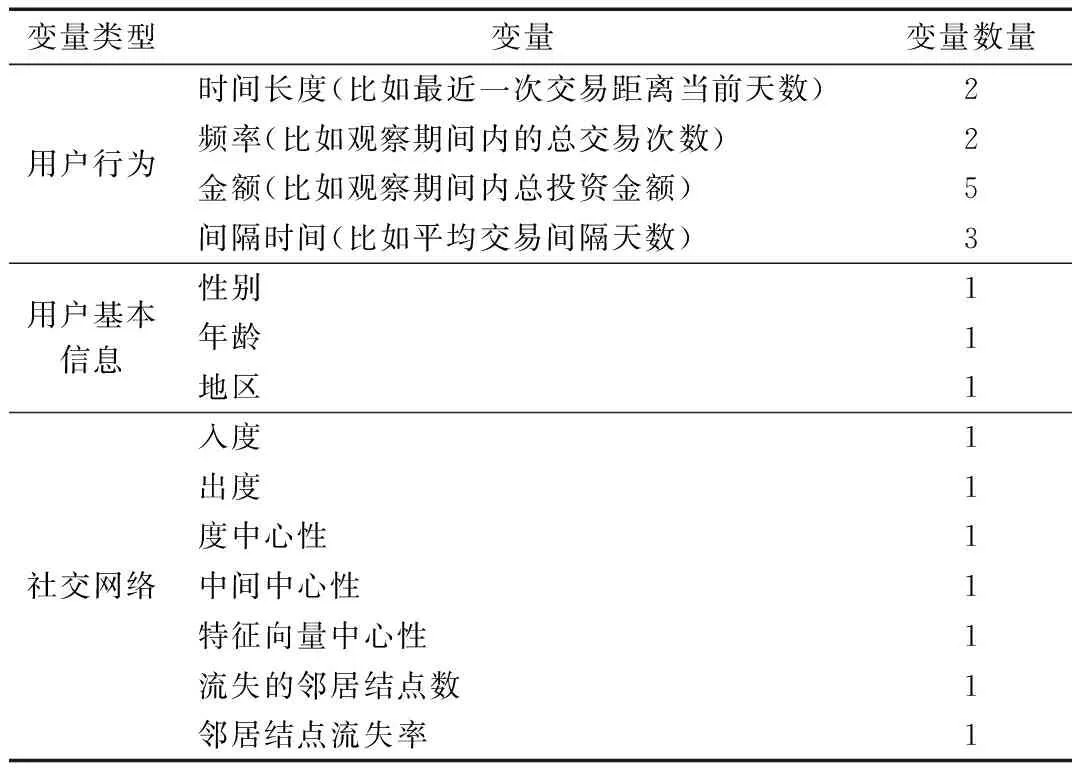
表1 变量列表
社交网络变量对于模型的预测效果的提升可以解释为社交网络同质性。同质性是指人们倾向于与自己具有相似特征的个体成为朋友,它可以用来预测互动频繁的人之间的相似性或者预测具有相似行为的人之间的交互行为[10]。
社交网络结构由结点和边组成,其中结点表示用户,而边(结点之间的连接)则表示用户之间建立的关系,社交网络的拓扑结构用图G=(V,E)表示,其中n=|V|表示结点数;vi表示结点i;eij表示结点i和j之间的边;A表示图的邻接矩阵。

中心性定义了网络中一个结点的重要性。本文选择常用的度中心性、特征向量中心性和中间中心性作为变量。最直接的中心性度量方式是度中心性,是在网络分析中刻画结点中心性的最直接度量指标。一个结点的结点度越大就意味着这个结点的度中心性越高,该结点在网络中就越重要。
结点vi的度中心性Cd为:

(1)
其中n代表结点数。
本文使用图的邻接矩阵A记录邻居结点,设Ce(vi)表示结点vi的特征向量中心性,该值是其邻居结点中心性的函数,并且在它的邻居结点中心性的总和中占一定的比例:
(2)
其中,ρ是某个固定的常量。
中间中心性考虑结点在连接其他结点时所表现出的重要性。首先计算其他结点通过结点vi的最短路径数目:
(3)
其中σst代表从结点s到结点t的最短路径的数目,σst(vi)是从结点s到t经过vi的最短路径数目,这种度量方法称为中间中心性。
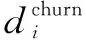

(4)
最后共选择了7个社交网络变量,社交网络变量如表1所示。
1.2 算法
GBDT是2001年Friedman等人提出的一种Boosting算法。它是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论加起来作为最终答案。XGBoost是一种改进的GBDT算法[7],该算法与GBDT有很大的区别[9]。GBDT在优化时只用到一阶导数,XGBoost则同时用到了一阶导数和二阶导数,同时算法在目标函数里将树模型复杂度作为正则项,用以避免过拟合。
XGBoost算法目标函数:
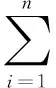
(5)
根据泰勒展开式:

(6)
同时令:

(7)
决策树复杂度计算公式:
(8)
将式(6)、 (7)、 (8)代入式(5),求得目标函数:

(9)
(10)
(11)
利用式(11)来寻找出一个最优结构的树,加入到模型中,通常情况下枚举出所有可能的树结构是不可能的,因此使用贪心算法来寻找最优树结构。
决策树分割时,增益计算公式如下:
Gain(φ)=
(12)
在树的学习中一个关键问题是根据式(12)找到最优的分割方案,也就是一种分割寻找算法,这个算法称为精确贪心算法。
在本文中,为了证明XGBoost在用户流失预测问题上的优越性,选择了三个在客户流失预测研究中常用的算法进行对比:Logistic回归(LR)、支持向量机(SVM)、随机森林(RF)。
1.3 评价指标
样本实际状态和预测状态对比如表2所示。

表2 分类结果混淆矩阵
准确率和提升系数计算公式:
(13)

(14)
提升系数是指使用模型的预测能力与不用模型相比,预测能力提高的倍数。因互联网用户较多,在企业资源有限的情况,企业只能选择流失率最高的一部分用户来进行客户挽留措施,因此本文选择客户流失研究领域中常用的Lift(10%)作为本文的一个评价指标,该指标侧重衡量流失风险最高的那一部分用户。该指标首先将用户按照算法预测的流失概率进行排序,然后选择概率前10%用户,计算这部分用户的实际命中率(TP/(TP+FP)),最后用命中率除以总数据中的流失人数比例即得到Lift(10%)值。
ROC(Receiver Operating Characteristic)和AUC(Area under Curve)指标。首先计算真阳性率(TPR)和假阳性率(FPR)的值,然后以FPR和TPR为坐标形成折线图,即ROC曲线。

(15)
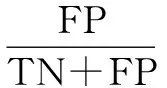
(16)
ROC曲线越靠近左上角,分类模型的准确性就越高。AUC是ROC曲线下方的面积,AUC越大,代表模型分类性能越好。
2 结果
2.1 数据预处理
本文数据来源于国内一家互联网金融平台,本文获得的数据共包含4 143条用户数据信息。数据包含用户的基本信息、交易行为数据和社交数据。
将数据分为观察期和预测期两个时间段,最后选定了10个月的数据来进行流失预测研究,前7个月为观察期,接下来的3个月作为预测期。利用观察期的数据进行模型训练,预测期的数据只用于建立目标变量标签。根据公司业务的实际情况,将流失用户定义为:用户预测期内无任何交易记录并且用户账户内无余额。
本文首先基于用户邀请关系,使用社交网络分析软件构建社交网络,然后计算网络指标并输出,从用户交易行为数据中提取行为变量,最后将所有的变量进行合并。将类别型变量,如性别,转换为One-hot编码,同时将连续型变量进行了Z-score标准化处理。
为了对比网络变量对于模型的预测能力的提升,本文将数据集划分为两类,一类为不包含网络变量的数据集,另一类为包含所有变量的数据集。在这两类不同的数据集上分别运行模型。
2.2 结果分析
实验结果如表3和表4所示,表中显示了4种模型在不同数据集上实验结果的准确率、AUC值、提升系数。从表中可以看到,对于两类数据集,XGBoost都具有最高的准确率、AUC值和提升系数,随机森林次之,SVM和逻辑回归效果较差。同时从图1和图2可以看到,XGBoost的ROC曲线始终处于最左上方,这表明XGBoost具有最好的客户流失预测性能。
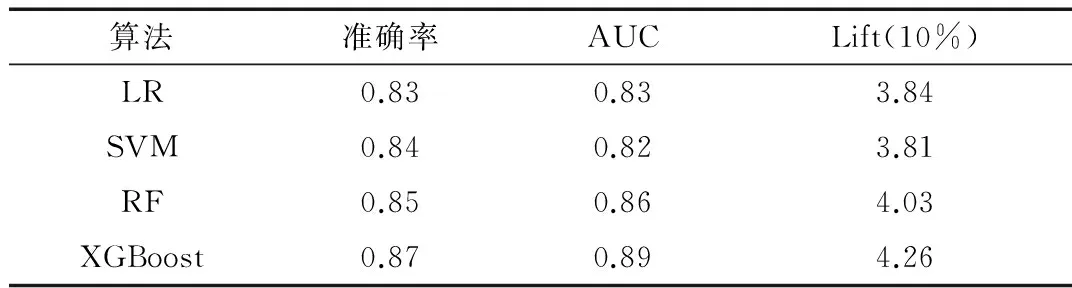
表3 算法运行结果(不包含网络变量数据集)
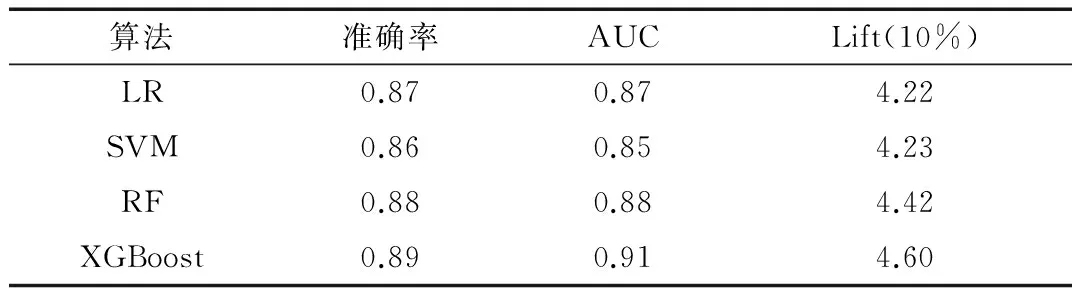
表4 算法运行结果(包含所有变量数据集)
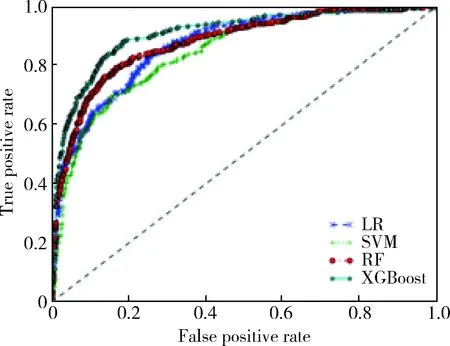
图1 ROC曲线(不包含网络变量数据集)
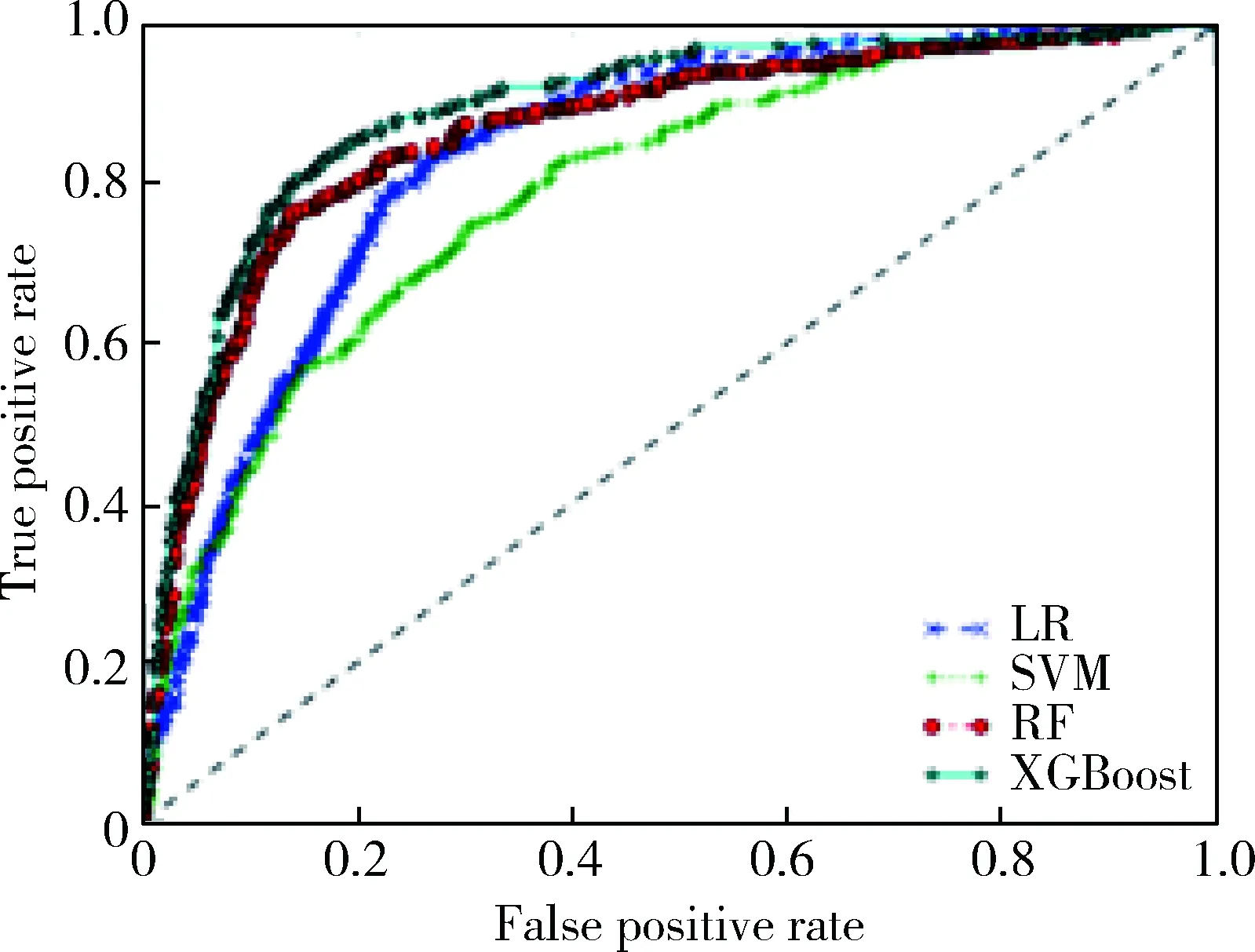
图2 ROC曲线(包含所有变量数据集)
对于两个数据集而言,不同分类算法在包含网络变量的数据集上的表现普遍优于不包含网络变量数据集上的表现,其中准确率提升2.5%~5.3%,AUC提升2.1%~4.4%,Lift(10%)提升8.1%~9.8%。对于所有模型而言,包含网络变量的XGBoost模型预测效果最佳。
3 结论
本文针对互联网行业的客户流失预测问题,提出了一种社交网络分析和机器学习相结合的客户流失预测方法,首先采用社交网络分析方法从用户社交数据中提取特征,将社交网络特征作为用户流失预测的输入变量,然后使用XGBoost算法来对客户流失进行预测,最后将该方法与其他机器学习算法进行比较。
实验结果表明,XGBoost模型的客户流失预测性能要优于其他模型的预测性能。进一步而言,包含网络变量的模型表现性能均优于不包含网络变量的模型表现性能,从而说明,社交网络分析和XGBoost相结合的客户流失预测方法优于传统方法。本文提出的客户流失模型有助于互联网企业开发不同的留存策略,针对流失用户采取措施,以更好地挽留用户。
[1] HADDEN J, TIWARI A, ROY R, et al. Computer assisted customer churn management: State-of-the-art and future trends[J]. Computers & Operations Research, 2007, 34(10): 2902-2917.
[2] 文笃石. 基于数据仓库的客户挽留系统[J]. 微型机与应用, 2015, 34(18): 11-13.
[3] 徐子伟,王传启,王鹏,等.基于分步特征提取和组合分类器的电信客户流失预测模型[J].微型机与应用,2016,35(13):51-54.
[4] OSKARSDOTTIR M, BRAVO C, VERBEKE W, et al. A comparative study of social network classifiers for predicting churn in the telecommunication industry[C].IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 2016: 1151-1158.
[5] BENEDEK G, LUBLY, VASTAG G. The importance of social embeddedness: churn models at mobile providers[J]. Decision Sciences, 2014, 45(1): 175-201.
[6] 黄海新, 吴迪, 文峰. 决策森林研究综述[J]. 电子技术应用, 2016, 42(12): 5-9.
[7] CHEN T, GUESTRIN C. XGBoost: a scalable tree boosting system[C]. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016: 785-794.
[8] ZIEBA M, TOMCZAK S K, TOMCZAK J M. Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction[M].Pergamon Press,Inc.,2016.
[9] 封化民, 李明伟, 侯晓莲,等. 基于SMOTE和GBDT的网络入侵检测方法研究 [J/OL].(2017-01-23)[2017-04-30].http://www.cnki.net/kcms/detail/51.1196.TP.20170123.1559.090.html
[10] OSKARSDOTTIR M, BRAVO C, VERBEKE W, et al. A comparative study of social network classifiers for predicting churn in the telecommunication industry[C]. IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. IEEE, 2016: 1151-1158.
A study on Internet customer churn prediction based on social network analysis and XGBoost
Wang Chongren, Han Dongmei
(Department of Information Management and Engineering, Shanghai University of Finance and Economics, Shanghai 200433, China)
In this paper, a method of customer churn prediction in the Internet industry is proposed, which is based on the combination of social network analysis and machine learning. Considering the influence of social activities for churn, firstly, social network analysis is used to extract features from the user's social data, then XGBoost (Extreme Gradient Boosting) is used to predict customer churn. Finally, the proposed method is compared with other machine learning algorithms (suoh as Logistic regression, support vector machine, and random forest). The experimental results show that the combination of social network analysis and XGBoost is better than the traditional method of customer churn prediction.
customer churn prediction; social network analysis; machine learning; extreme gradient boosting
TP391
A
10.19358/j.issn.1674- 7720.2017.23.017
王重仁,韩冬梅.基于社交网络分析和XGBoost算法的互联网客户流失预测研究[J].微型机与应用,2017,36(23):58-61.
上海财经大学研究生教育创新计划项目(2015111101)
2017-05-09)
王重仁(1984-),男,博士研究生,主要研究方向:数据挖掘。
韩冬梅(1961-),女,博士生导师,教授,主要研究方向:经济分析与预测。
