数据中心网络中多种TCP拥塞控制算法的性能研究
2017-12-13陈雷明颜金尧安站东
陈雷明,颜金尧,安站东
(1.中国传媒大学 信息工程学院,北京 100024;2.阳泉煤业集团机电动力部,山西阳泉 045000)
数据中心网络中多种TCP拥塞控制算法的性能研究
陈雷明1,颜金尧1,安站东2
(1.中国传媒大学 信息工程学院,北京 100024;2.阳泉煤业集团机电动力部,山西阳泉 045000)
数据中心网络中的TCP拥塞控制算法的研究一直是学术界的热点,大多数论文是在哑铃型拓扑中进行分析的,而数据中心中常用网络架构有:three-tier,Fat-tree、BCube、DCel和VL2。本文研究分析在Fat-tree拓扑中三种类型的TCP(基于ECN的DCTCP,基于丢包的Reno、NewReno、Cubic、Sclable和基于RTT的Vegas)的性能,从队列长度、丢弃的数据包数量、吞吐量和数据包的平均端到端时延等方面进行综合评估。本文结合ECN控制方法,来改善多种TCP在数据中心网络中出现的问题。经过大量实验分析得出ECN控制方法可以减少TCP的时延和丢包、减轻交换机队列拥挤,并且发现结合ECN的Cubic可以获得比DCTCP更好的综合性能。
数据中心网络;TCP拥塞控制算法;Fat-tree拓扑;显示拥塞通知
1 引言
传输控制协议(TCP)的可扩展性和鲁棒性通过其在网络中的主导作用已经得到证明,其拥塞控制算法有助于网络环境的稳定。然而,随着现代网络环境(诸如卫星网络和数据中心网络)的出现,每个具有不同特征的网络技术的发展已经对完善的TCP提出了挑战。
经过大量的测量显示,数据中心网络(DCN)内的绝大部分流量可以分成三种不同的类型。查询流的流量很小,通常小于100Kbytes,主要来自需要快速响应的应用程序,例如百度搜索和移动终端APP或电脑软件更新的提交。这种流容易在多条流同时经过某个交换机时因交换机缓存空间不足而导致分组部分或者完全丢弃,影响用户体验。第二种类型的TCP流是延迟敏感的短流量,其大小在100Kbytes到5Mbytes之间,例如由微博、微信等应用生成。第三种TCP流是由软件更新等应用程序生成的大小超过5Mbytes的吞吐量敏感的长流。数据中心还需要处理来自内部或者另一个数据中心的数据流,例如用户使用数据云业务时。
DCN中的一直存在丢包,队列拥挤和缓冲压力问题[1]。当很多业务流到达相同的输出端口时因队列溢出而出现数据包丢弃,而当贪婪的长流占据大部分瓶颈队列缓冲空间时,出现缓冲压力问题,对于查询流量几乎没有留下空间,导致分组被丢弃。 DCN中的TCP的众多缺点促使开发了多种TCP变体以解决TCP问题,包括DCTCP,ICTCP和D2TCP。然而,这些TCP变体是以一般广域网络中的缺点为对比来展示他们的优点。对于DCN的理想拥塞控制应该能够有效地利用可用的网络带宽,并且让数据包经过小缓存的交换机时具有较小的等待时间。还需要考虑其他设计约束,如可扩展性,鲁棒性和部署复杂性。此外,作为端到端算法,协议应能够在商品交换机的全部潜力下与商品交换机协作,而不需要修改网络设备。本文认为,需要在对现有TCP的全面理解的基础上对每个新的TCP变式进行研究,以便在不重复改进的情况下获得更好的解决方案。不幸的是,研究界仍然缺乏在现代网络环境中对常规TCP拥塞控制算法的这种全面的比较研究。
2 数据中心的拥塞控制算法
对于数据中心网络,之前被部署在其他网络环境中的成熟的TCP拥塞控制算法都表现平平,主要是数据中心网络使用具有非常小的缓存的商品交换机,高速链路和低往返时延。这种特殊的要求和数据中心应用程序的要求与广域网的差异很大;数据中心应用程序会产生突发查询流量,延迟的敏感短流量和吞吐密集型长流量,并且通常具有严格的流量完成时间的要求。
2.1 传统拥塞控制算法
本文研究的传统TCP主要分为两类:基于丢包反馈的Reno,NewReno,Cubic和Scalable,基于RTT反馈的Vegas。每种TCP都有不同的设计思想和适合它们的网络环境。
Reno是在Tahoe算法的基础之上加入了快速恢复阶段,但Reno只考虑了每次网络拥塞发生时只丢弃一个数据包的情况。NewReno是在Reno的基础之上对快速恢复算法进行了改进,增加了对恢复应答执行预先判断的功能,以增强发送端通过ACK分析数据包传输情况的能力。Cubic设计时使用了一个三次函数来调整拥塞窗口[2],Cubic的窗口增长函数仅仅取决于连续的两次拥塞丢包事件的时间间隔之差,这样Cubic窗口增长与网络中的时延RTT大小无关。Scalable TCP(STCP)是面向高带宽时延乘积的TCP新算法,以稳定性著称,其基本思想是网络中拥塞情况发生后快速恢复阶段所需要的时间与拥塞窗口值是相互独立的。Vegas是一种基于RTT的拥塞控制算法,基本思想是:首先设置一个阈值,计算当前网络中实际吞吐量的大小和网络所期望的吞吐量的大小,如果两者之差大于所设置的阈值就认为网络中出现拥塞,马上主动减小发送端的发送速率;如果两者之差小于这个阈值,就认为网络环境没有出现拥塞,拥塞窗口还可以继续增长。
2.2 DCTCP拥塞控制算法
DCTCP是为数据中心网络环境设计的新算法,是基于显示拥塞反馈和主动队列管理算法RED相结合的一种拥塞控制机制[3-4]。该算法的部署需要三方面的共同实现。
2.2.1 交换机标记。
在RED中设置一个阈值K,如果瞬时队列的长度超过K,则超过的数据包的IP头部的CE位都会被标记为1,否则不标记。发送端通过接收端反馈回来的ACK就可以知道交换机队列的占有率情况。现如今大部分商用交换机已经实现了RED算法,DCTCP正好利用了这一点,只需要在RED中同时设置高门限值和低门限值同时为K。
2.2.2 接收端ECN-Echo(ECE)
在接收端收到来自发送端的窗口减小确认信息(TCP头部的CWR位被置1)之前,接收端如果发现数据包的IP头部CE位为1,就继续将ACK数据包的ECE位标记为1,以此继续告诉发送端网络中出现了拥塞。
2.2.3 发送端的控制器
发送端不断更新一个用来评估被标记数据包比重的参数,每个RTT内更新一次,公式如下所示:
α=(1-g)*α+g*F
(1)
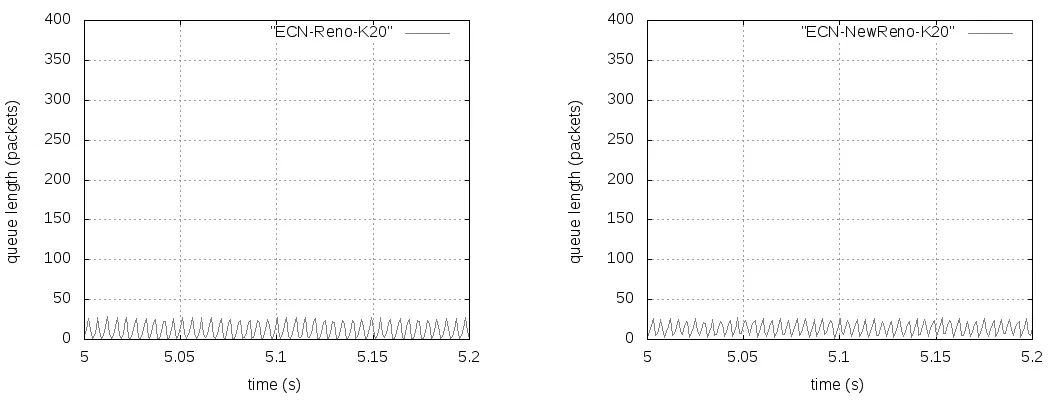
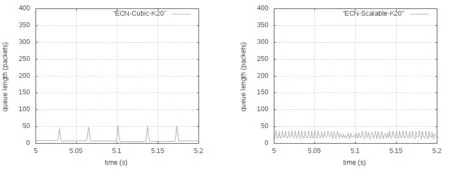
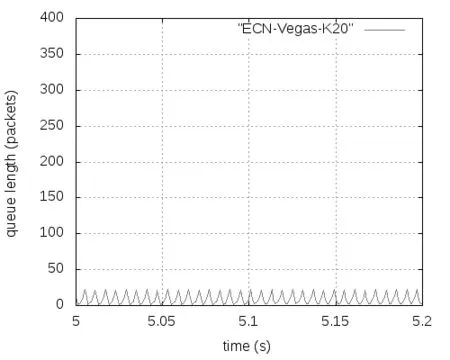
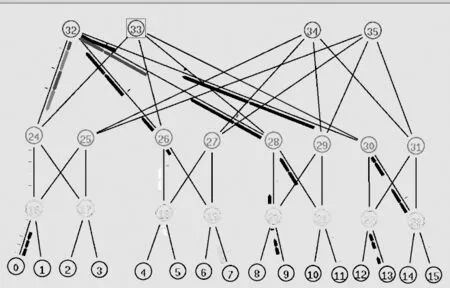
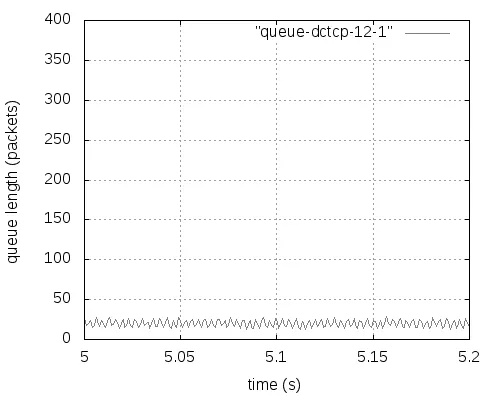
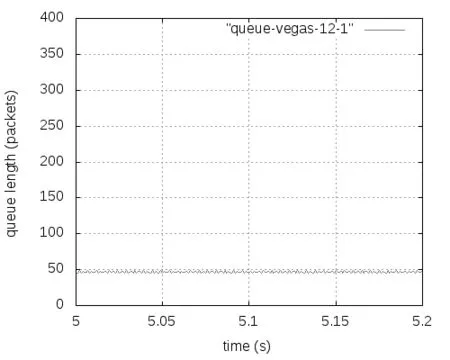
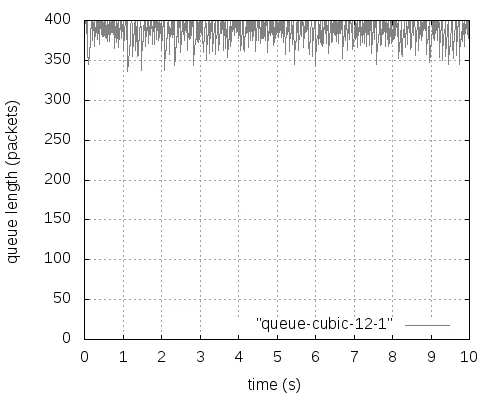
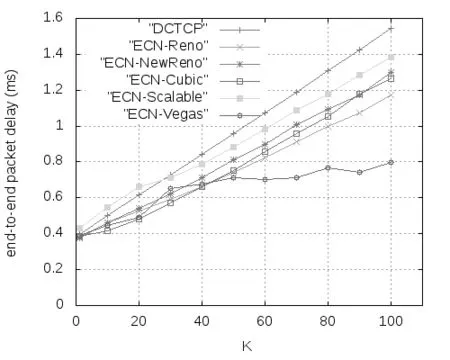
式中,F是最后一个数据窗口中被标记的数据包的比重,g(0 (2) Alizade等人的论文中表明,当K值大于时延带宽乘积的17%就能实现95%以上的吞吐量。 2.3 显示拥塞控制通知 显示拥塞控制通知(ECN)机制[5]的实现是需要和RED算法配合使用的,其控制的基本思想是:当路由器和交换机等网络设备出现早期拥塞情况时,不是按照RED的算法计算出丢包概率来丢弃数据包,而是尽量对数据包进行标记。 (1)IP对ECN的支持。IP头部一般有20个字节的空间,从IP头部的第8位开始到第15位为服务类型区域,共有8位,其中6-7位预留未使用。在RFC2481文档中建议使用这预留未用的两bit作为ECN区域。第一个bit为ECN-Capable Transport(ECT)位,表示该TCP协议支持ECN拥塞通知,第二个bit为Congestion Experience(CE)位,表示数据包正经历拥塞。RFC3168文档中提出,用组合形式“00”表示不支持ECN,用组合“01”和“10”表示支持ECN,使用“11”组合表示数据包正在经历拥塞。 (2)TCP对ECN的支持。ECN使用TCP头部的CWR(Congestion Window Reduced)和ECE(ECE-Echo)两位。根据RFC3168建议,如果发送端和接收端都需要使用ECN机制,则在TCP初始化时,发送端在发送的TCP头部设置ECE位和CWR位均为1,以表示TCP协议支持ECN机制。接收端收到这个TCP包后返回ECE=1、CWR=0的ACK确认信息。最后发送端再一次向接收端发送一个应答包,完成TCP链接的三次握手,支持ECN的TCP链接建立完成。 本章选用数据中心网络中的DCTCP和其他网络环境中的TCP(reno、newreno、cubic、scalable、vegas),通过多次实验详细分析它们各自在Fat-tree拓扑中的性能表现,根据实验获得的数据从四个方面进行比较评估它们的性能:丢包数量、数据包的平均端到端时延、网络中瓶颈链路总的吞吐量和处于网络链路瓶颈的核心交换机的瞬时队列长度。 然后,本章应用ECN控制方法来改善各类TCP在数据中心网络中的性能,并从队列长度、丢弃的数据包数量、吞吐量和数据包的平均端到端时延等方面对ECN-TCP进行综合评估。 3.1 实验拓扑和参数设置 本实验使用k=4的Fat-tree拓扑,使用网络模拟软件NS-2在Ubuntu14.04系统环境中进行模拟实验仿真,搭建的拓扑如图1所示,拓扑中编号为4-15的12个主机作为数据发送端,编号为0的主机作为数据接收端。图1为12条TCP流同时发送数据。 图1 12条TCP流的模拟仿真图 实验过程中没有设置固定的网络链路丢包率。由于试验中往返时延很短,所有的TCP流在很短的时间内即可达到稳定状态,设置的仿真时间为10秒。表1中展示了试验中的一些关键参数的设置。 表1 实验仿真参数 3.2 TCP性能分析 本次实验仿真六种不同的TCP,设置了六组实验,每一组都使用相同的TCP。为了了解不同数量的TCP流对TCP 性能的影响情况,每组实验等间隔设置四种不同数量的TCP流:3条TCP流、6条TCP流、9条TCP流和12条TCP流。每组试验我们都采取多次测量求组平均值作为最终的结果,以防止个别实验特殊情况的发生,减小实验误差。 1.端到端时延。六种TCP的数据包的平均端到端时延如图2所示,DCTCP的数据包的平均端到端时延一直很低,基本维持在0.5 ms左右;Vegas的数据包的平均端到端时延从3条TCP流时的0.5 ms逐渐增加到12条TCP流时的约1 ms,增长近一倍,而且在3条TCP流时还低于DCTCP;Reno和NewReno的数据包的平均端到端时延很接近,基本维持在4 ms,几乎是DCTCP的7倍、Vegas的4倍;Scalable的数据包的平均端到端时延基本在4.5—4.7 ms之间;Cubic是最高的,是DCTCP的近10倍。所有TCP的平均端到端时延随着TCP流的增加都有不同程度的增加。由于TCP流增多,但是链路资源有限,不同流之间的竞争就增加,各自争抢网络资源,网络出现丢包的概率就增加,TCP拥塞控制算法进入拥塞避免阶段、快速恢复阶段和快速重传阶段的次数就增多,每条流的平均吞吐量就会降低。从平均端到端时延可以看出,DCTCP拥塞控制算法的优势是很明显的。 图2 TCP数据包的平均端到端时延变化 2.吞吐量。不同数量TCP流的核心交换机的吞吐量变化,如图3所示。其中DCTCP、Cubic、Scalable、Vegas的吞吐量很接近,Reno的吞吐量稍微低一些,NewReno的吞吐量最低,但是值得称赞的是六种TCP的瓶颈处的吞吐量都能达到链路的95%以上。随着TCP流的增加,每种TCP的吞吐量都有少许的增加,但是每条流的平均吞吐量肯定是逐渐减小的。 图3 六种TCP的吞吐量变化 3.丢包数量。六种TCP的不同链接数量的丢包数量的变化,如图4所示。DCTCP和Vegas的丢包数量都为0。其他四种TCP都是基于丢包的拥塞控制算法,Scalable和Cubic的丢包最为严重,Reno和NewReno相对最少。随着TCP流的增加,瓶颈处交换机的队列更加拥挤,丢包数量也是逐渐增加的,这一点和端到端时延、吞吐量一样。 图4 六种TCP的丢包情况 4.核心交换机队列瞬时长度。图5-7分别展示了DCTCP、Vegas、Cubic在12条TCP流时的核心交换机瞬时队列的长度。其中DCTCP设置的K=20,从图5可以看出,其队列长度维持在20上下;Vegas的队列长度维持在50以下。DCTCP和Vegas在缓存空间为400个数据包的情况下都能保持较低的队列,零丢包,时延也很低,但是在TCP流数量增加到一定程度后队列长度就会很高,接近交换机缓存的空间大小,这时队列排队时延和丢包率都会很大。而Reno、NewReno、Cubic、Scalable的队列长度一直很高,因缓存空间溢出而出现大量丢包,图7给出了Cubic的队列长度。 图5 DCTCP在12条数据流时的队列长度 图6 Vegas在12条数据流时的队列长度 图7 Cubic在12条数据流时的队列长度 3.3 基于ECN的TCP性能改进 鉴于DCTCP在数据中心网络中的优点,本节把显示拥塞通知(ECN)机制应用在Reno、NewReno、Cubic、Scalable和Vegas上(分别称为ECN-Reno、ECN-NewReno、ECN-Cubic、ECN-Scalable和ECN-Vegas),以缓解瓶颈处核心交换机的队列拥挤和丢包问题。 本次实验的拓扑结构如图1所示。实验中12个主机连续的发送12条长TCP流到同一个接收端。实验中的TCP拥塞控制算法使用DCTCP、Reno、NewReno、Cubic、Scalable和Vegas,ECN阈值K选取1和10-100共11个不同值。 实验结果中六种TCP的丢包数量均为0,解决了网络中丢包的问题,下面从数据包的平均端到端时延、总的吞吐量和交换机瞬时队列长度三个角度进行性能分析。 1.数据包的平均端到端时延:如图8所示,K=1时除了ECN-Scalable高于0.4ms之外,其他五种ECN-TCP都低于0.4ms,而且大小很接近。随着阈值K的增加,各ECN-TCP的端到端时延逐渐增加。DCTCP几乎呈线性增加,且在K大于30以后,DCTCP的时延一直是最大的,主要是因为其队列维持在K±10左右,而其他TCP队列从接近于0到K+10幅度变化范围比较大,队列空闲比DCTCP多一些,时延也就小了一些。ECN-Vegas在阈值K大于30以后,时延增长幅度变缓,尤其在K大于50之后,时延是最低的,主要是ECN-Vegas队列在K大于30后,队列一直维持在30-40附近,这和Vegas基于RTT的拥塞控制机制是密不可分的[6]。和图2相比,ECN机制在降低时延方面的优势非常明显。 图8 DCTCP和ECN-TCP在不同K值时的时延 2.总的吞吐量:如图9所示,ECN-Scalable的吞吐量一直是最高的,吞吐率都在95%以上,这主要是因为Scalable在处理丢包时快速恢复阶段所需要的时间与拥塞窗口值是相互独立的[7],拥塞窗口很快就能恢复到丢包前的大小,实现高吞吐率。DCTCP在K为1时也能实现93%的链路利用率,K大于10以后就能实现95%的链路利用率。另外四种ECN-TCP在K=1时链路利用率都很低,直到K大于70时链路利用率才能达到95%。和非ECN相比,合适的阈值使得各TCP的最高吞吐量相差不多,所以,当选择合适的阈值K时,是否使用ECN机制对它们的吞吐量影响很小。 图9 DCTCP和ECN-TCP在不同K值时的吞吐量 3.交换机瞬时队列长度:图10-14展示了五种ECN-TCP在K=20时的交换机瞬时队列长度的变化情况,DCTCP见图5所示。ECN-Cubic的瞬时队列维持在K+30以内,且变化幅度较大,其他ECN-TCP的瞬时队列基本在K+10以下。在缓存空间在400个最大数据包情况下,各ECN-TCP都能保持较低的瞬时队列长度,缓解了队列拥挤,实现了零丢包,增加了应对突发TCP流的能力。 从以上三方面的综合分析可以看出,传统TCP结合ECN机制后,使用合适的阈值K(大约20),在丢包、时延、交换机队列拥挤等方面都具有很明显的改进,实现了零丢包、低时延、低队列,同时又能达到95%以上的链路利用率。综合时延和吞吐量特性,ECN-Cuibic时延相对DCTCP较低而吞吐量相近,因此本文认为结合ECN的Cubic可以获得比DCTCP更好的综合性能。 本文以应用于数据中心网络中的Fat-tree拓扑为架构,从丢包数量、数据包的平均端到端时延、总的吞吐量和核心交换机瞬时队列长度四个方面对DCTCP、Reno、NewReno、Cubic、Scalable、Vegas等六种TCP拥塞控制算法进行了综合性能评估。可以得出,基于ECN的DCTCP和基于RTT的Vegas在各方面的变现均很出色,而基于丢包的Reno、NewReno、Cubic和Scalable各自争夺网络资源而出现比较严重的丢包、队列拥挤和较高的端到端时延,不满足数据中心网络环境的特点和需求。 图10-14 ECN-TCP的核心交换机队列 为了改善传统TCP在数据中心网络中的性能,本文将DCTCP中的ECN机制应用到其他五种TCP来尝试解决传统TCP出现的问题,通过大量实验验证ECN-Reno、ECN-NewReno、ECN-Cubic和ECN-Scalable在处理丢包和时延方面都有很明显的改善,丢包问题解决,而且合适的阈值K也能使得端到端时延控制在1ms左右,同时还能达到95%左右的吞吐量,基本满足数据中心网络对TCP的各方面的要求,甚至综合性能可以超过DCTCP。 [1]Truck Anh N Nguyen,Siddharth Gangadhar. Performance Evaluation of TCP Congestion Control Algorithms in Data Center Networks [J]. CFI’16,June,15-17,ACM,2016. [2]S Ha,I Rhee,L Xu. CUBIC:A New TCP-friendly High-speed TCP Variant[J]. SIGOPS Oper Syst Rev,42(5):64-74,July,2008. [3]M Alizadeh,A Greenberg,D A Maltz,J Padhye,P Patel,B Prabhakar,S Sengupta,M Sridharan. Data center TCP(DCTCP)[J]. In Proceedings of SIGCOMM’10,63-74,New York,NY,USA,2010 ACM. [4]M Alizadeh,A Javanmard,B Prabhakar.Analysis of DCTCP:Stability,Convergence and Fairness [J].Proceedings of the ACM SIGMETRICS,Joint International Conference on Measurement and Modeling of Computer Systems,ser SIGMETRICS’11,New York,USA:ACM,2011,73-84. [5]K Ramakrishnan,S Floyd,D Black. RFC 3168:the addition of explicit congestion notification(ECN)to IP [S]. [6]L Brakmo,S O’Malley,L Peterson. TCP Vegas:New techniques for congestion detection and avoidance [J]. In SIGCOMM,1994. [7]T Kelly. Scalable TCP:Improving performance in highspeed wide area networks [J]. ACM SIGCOMM Computer Communication Review(CCR),33(2):83,2003. (责任编辑:宋金宝) ResearchonPerformanceofManyTCPCongestionControlAlgorithmsinDataCenterNetwork CHEN Lei-ming1,YAN Jin-yao1,AN Zhan-dong2 (1.School of Information Engineering,Communication University of China,Beijing 100024,China;2.Department of Electronic Mechanical and Power,Yangquan coal Industry Group,Shanxi Yangquan 045000,China) The study of TCP congestion control algorithm in data center network has always been a hot topic in academia. Most of the papers are analyzed in dumbbell topology. The common network architectures in the data center are:three-tier,Fat-tree,BCube,DCel and VL2. This paper investigates the performance of three types of TCP(ECN-based DCTCP,loss-based Reno,NewReno,Cubic,Sclable,and delay-based Vegas)in the Fat-tree topology,and evaluated in terms of queue length,number of dropped packet,throughput and average packet end-to-end delay. This paper combines ECN control methods to improve the various TCP in the data center network problems. After a large number of experimental analysis,ECN control method can reduce TCP delay and packet loss,reduce the switch queue congestion,and the combination of ECN Cubic can get better than DCTCP comprehensive performance. DCN;TCP congestion control algorithms;Fat-tree;ECN TP393.05 A 1673-4793(2017)05-0037-08 2017-06-20 陈雷明(1987 -),男(汉族),山东人,中国传媒大学硕士研究生.E-mail:chenlm28@163.com3 TCP拥塞控制算法的分析与改进
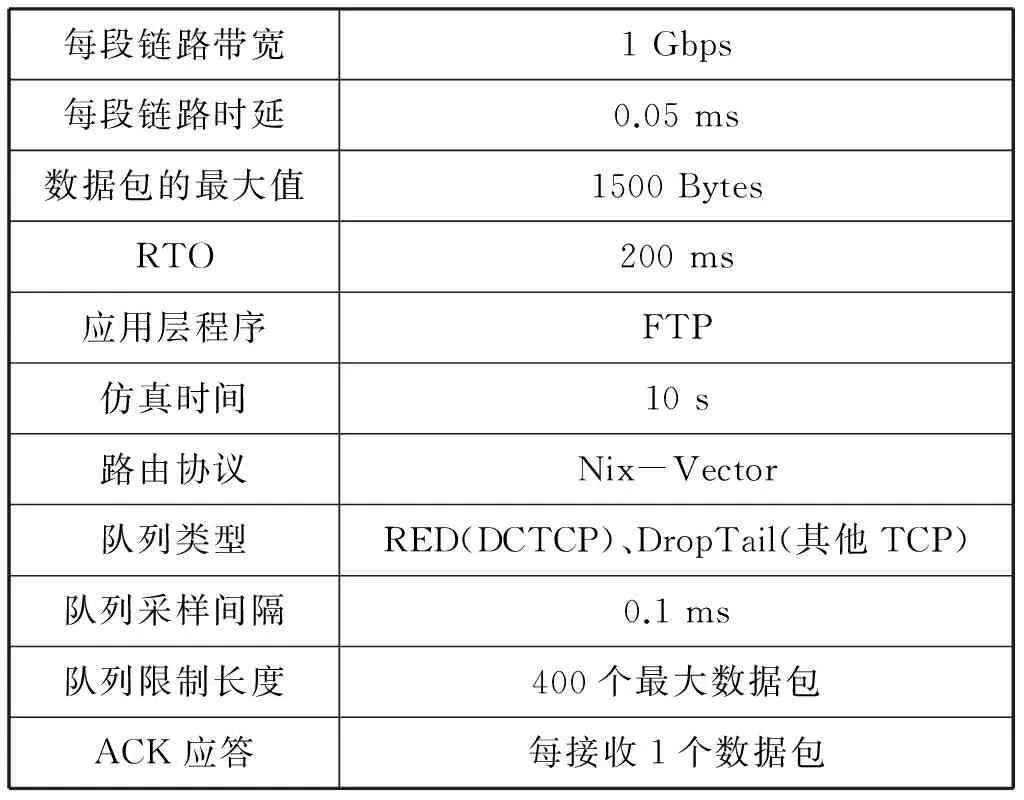
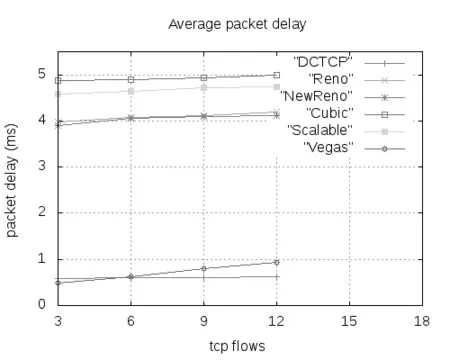
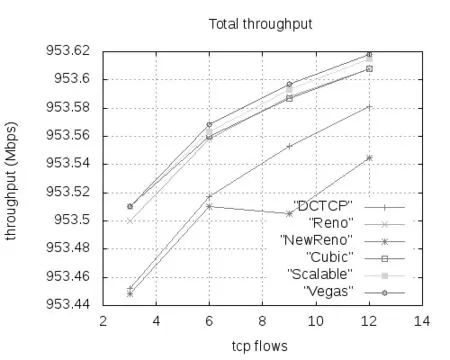
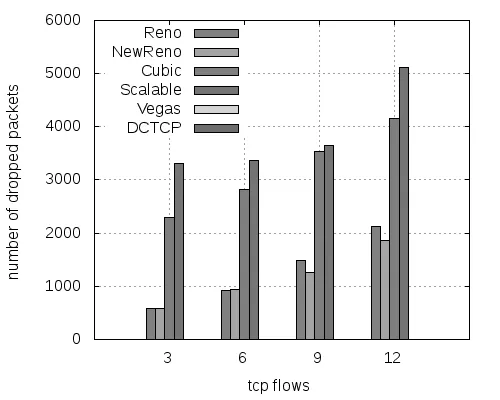

4 结论