基于不同样本分区和模型参数的四川省粮食产量空间化研究*
2017-11-23林正雨景晓卫
何 鹏,林正雨,景晓卫,李 晓※
(1.四川省农业科学院农业信息与农村经济研究所,成都 610066;2.四川省农业科学院区域农业发展研究中心,成都 610066;3.四川省农业科学院大数据中心,成都 610066)
·粮食安全·
基于不同样本分区和模型参数的四川省粮食产量空间化研究*
何 鹏1, 2, 3,林正雨1, 2, 3,景晓卫1,李 晓1, 2, 3※
(1.四川省农业科学院农业信息与农村经济研究所,成都 610066;2.四川省农业科学院区域农业发展研究中心,成都 610066;3.四川省农业科学院大数据中心,成都 610066)
目的农业经济统计数据受多种自然条件因素和社会经济条件因素影响,数据空间化难度很大。通过省级尺度粮食产量数据空间化的研究,探索提高农业经济统计数据空间化精度的方法及经验。方法以四川省为例,按照不同分区方案(全省不分区、分为5个综合农业分区),选择不同样本数据(县级粮食总产、县级平均粮食产量)为因变量,对应2种耕地类型(水田、旱地)面积数据为自变量,考虑2种模型参数(常数为0和不为0)拟合多元回归模型,对粮食数据进行空间化研究,并选择误差评价因子对空间化结果进行评价。结果(1)不管采用县级粮食总产还是县平均粮食产量拟合,常数项设置为非0的,均是分区比不分区的结果精度要高; (2)不管采用县级粮食总产还是县平均粮食产量拟合,常数项设置为0的,均是分区比不分区的结果精度要高; (3)对比不分区和分区这2种方法,以县级粮食总产拟合的结果要比县级平均粮食产量拟合的结果精度要高。结论在省级粮食产量空间化时,以分县平均粮食产量为基础,划分土地利用类型、划分农业分区并且常数为0时拟合精度最高。在今后的研究中,有必要结合更多的影响因子进行粮食产量的空间化,以提高其数据重构精度。
粮食 模型 分区方案 多元回归 误差 空间化
0 引言
近年来社会科学的发展出现三大潮流,即“科学化”(强调借用自然科学的计量分析方法和模型)、“空间化”(关注社会经济现象的空间变化和相互作用)和“应用化”(侧重于政策性规划性强的实用课题)[1]。20世纪90年代以来,国内外学者对社会经济统计数据空间化问题进行了许多研究和探讨,包括基于土地利用、地形地貌、交通条件和夜间灯光指数等的人口数据空间化[2-6],基于土地利用和夜间灯光指数等的国内生产总值空间化[7-8],基于人口和土地利用的国内生产总值空间化,基于土地利用的森林蓄积量和草场载畜量调查数据空间化[9-11]等。农业生产活动受多种自然条件因素(海陆位置、气候特征、水文环境、土壤机理、自然灾害、地理变化等)和社会经济条件因素(人口、文化、经济、政治等)的影响,因此对农业经济统计数据空间化的难度很大,导致在很长一段时间内,国内外对于农业经济统计数据空间化的研究还比较少。
农业是一个国家国民经济的基础产业,而粮食则是人们日常生活的必需品,关系着一个国家的安全、稳定和发展。粮食生产是人类生存需求推动下的社会经济活动,是人与自然和谐相处的结果,粮食产量的空间格局变化有一定的规律性。影响粮食产量的主要因素有区域土壤、气候、水文、地形、区位、作物以及投入和管理措施等,分析上述因素对粮食产量的影响,从而将规律定量化,可达到粮食产量空间化的目的。但因素之间的关系较为复杂,找出定量化关系有很大的难度。
随着GIS技术的进步,国内已有不少学者对粮食产量空间化进行了研究,包括2012年,刘忠等[2]利用土地利用与人口密度数据对中国2000年粮食产量统计数据进行了空间化,并在省级、地市级和县级3个尺度上,对其空间化精度进行了一些分析; 2015年,廖顺宝、姬广兴等[14]利用不同农田类型面积与粮食产量拟合的方法对中国2005年粮食产量统计数据进行了空间化,并对不同样本尺度、不同分区方案和不同模型参数条件下的精度和误差修正进行了分析。但还未见有采用上述研究方法对省域尺度的粮食产量空间化及时空分布格局进行研究的文献,现有省域尺度粮食产量时空分布格局研究多局限于以县(区)域行政单元为研究单元[12],属于“伪”空间化。
因此,文章以全国粮食生产大省四川省为例,基于不同样本、分区方案和模型参数对粮食产量数据进行空间化研究,探寻省级尺度粮食产量数据空间化的经验,对提高农业经济统计数据空间化精度具有重要意义。
1 数据与分析
1.1 研究思路
粮食产量是典型的基于行政单元的统计型数据,这种数据的特点是一个行政区内只有一个产量值,或者是总产量,或者是单产,不能反映粮食产量在行政区内部空间上的差异。而粮食产量空间化正是解决这一问题的有效手段。
粮食产量空间化的基本思想是,用区域尺度(如地区、市县、乡镇)上构建的产量——面积模型来计算栅格单元尺度上的粮食产量,与气象气候研究领域中的降尺度问题相似。对于区域尺度的粮食空间化研究,可选择的行政区域有省级、地市级、县级和乡镇级,从已有的粮食空间化研究文献来看,全国尺度以地市级数据作为样本较好,再从农业统计数据的可获得性和土地利用数据分辨率的角度来看,省域尺度的粮食空间化研究以县级数据作为样本较好。
1.2 数据来源
该研究使用的数据主要包括3部分。
(1)2010年《四川省农业统计年鉴》。
(2)2010年四川省30m分辨率土地覆被类型数据集。该数据集包括6种一级土地覆被类型和25种二级土地覆被类型。
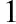
1.3 数据预处理
数据预处理主要包括以下内容。
(1)统计各县市不同农田类型的面积。在ArcGIS 10.1软件中,利用县级行政区划图,对不同农田类型的栅格图层进行区域统计运算,得到每个行政区划(县、市、区)的不同耕地类型(水田和旱地,其分类信息及依据见表1)的面积数据。
表1 土地利用分类系统

一级类型二级类型编码含义耕地水田11指有水源保证和灌溉设施,在一般年景能正常灌溉,用以种植水稻,莲藕等水生农作物的耕地,包括实行水稻和旱地作物轮种的耕地旱地12指无灌溉水源及设施,靠天然降水生长作物的耕地;有水源和浇灌设施,在一般年景下能正常灌溉的旱作物耕地;以种菜为主的耕地,正常轮作的休闲地和轮歇地
(2)将全省各县级粮食产量统计数据与其不同农田类型面积数据进行匹配(表2)。以名称和行政代码一致为标准进行匹配,然后对匹配结果进行检验。首先,由于有飞地的存在,以名称和行政代码一致为标准,删除数据的重复项,防止建模时对同一数据多次计算,影响模型精度; 其次,删除一些不合理的数据,包括以下3种情况: ①该县市有耕地面积却无粮食产量统计数据; ②该县市无耕地面积却有粮食产量统计数据; ③数据检查发现单产畸高的(一般为面积较小且行政驻地所在区县)。
通过上述方法检验和甄别,最终获得177条有效县级数据记录。
表2 分县粮食产量及耕地面积基础数据
市名称县(区、市)名称县级行政区划代码粮食总产量(万t)水田面积(万hm2)旱地面积(万hm2)雅安市雨城区5118026928514187552022537雅安市名山区5118039561213772711622320雅安市荥经县5118225387600440292429468雅安市汉源县51182311550311451093593895雅安市石棉县5118243285103886561597117雅安市天全县5118257442007887552101648—————— 注:因数据量庞大,不再一一列出。如有需要,可联系作者索取
1.4 建模及模型验证
在自然条件和农业生产技术条件基本一致的情况下,粮食产量与农田面积成正比例关系,而不同的农田类型(图1)对粮食产量的影响不同,同时统计分析建模是实现粮食产量数据空间化的一种常用方法,因此,该研究选用多元线性回归分析方法建模。结合已有研究文献,在建模时分别考虑分区方案和回归方程常数项设置(0与非0)对模型的影响。
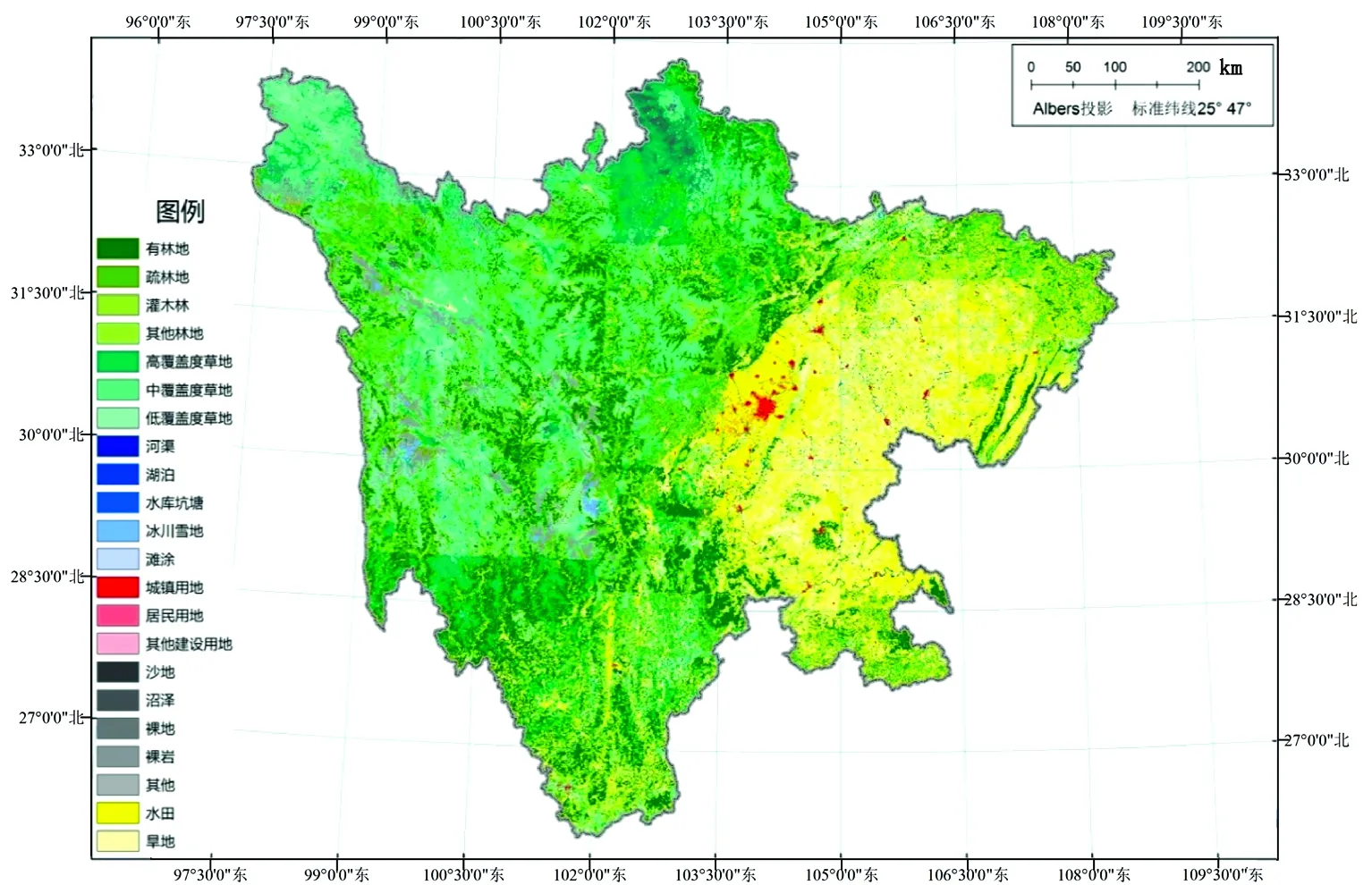
图1 2010年四川省30m栅格尺度土地利用覆被
基于获得的177条县级数据来建立粮食产量预测模型。粮食生产与自然资源禀赋有较大关系,温、光、水、土等自然条件对粮食产量影响较大,四川省自然条件比较复杂,所以根据综合农业区划资料,将181个县(区、市)分成5个区(图2)[13],以县级粮食总产量和平均产量为因变量,以其对应的耕地类型(水田、旱地)面积数据为自变量,在SPSS中,运用多元线性回归分析方法,建立8种模型、28个回归方程。分区中的川西高原区由于水田极少,耕地类型主要为旱地,导致做多元回归分析时出现较大误差,所以增加了一元回归方程拟合。5个区包括成都平原区(35个县)、川中丘陵区及川东平行岭谷区(62个县)、盆周丘陵山区(30个县)、攀西地区(23个县)、川西高原区(31个县)。

图2 四川省综合农业区划
表3 多元线性回归方程及常数项设置情况(2010年数据)

样本分区情况常数项设置线性回归方程相关系数/R变异系数/CV县级粮食总产不分区非0(1)y=476659x1+231133x2-10665190093302920(2)y=468172x1+221187x209690292分为5个区非0(1)y=646151x1+0059x2-163868809400226(2)y=307132x1+312809x2+2687075409070217(3)y=395351x1+151658x2-771685609150337(4)y=539162x1+119336x2+899285608260456(5)y=91674x2+2830395091203040(1)y=641874x1-0493x209830223(2)y=330295x1+329221x209820218(3)y=396546x1+138060x209680332(4)y=548159x1+133848x209400448(5)y=105960x209650328县平均粮食产量不分区非0(1)y=591697x1+236855x2-20370089904020(2)y=526536x1+206256x209540408分为5个区非0(1)y=696560x1+167204x2-6248708470325(2)y=849725x1+306031x2-11664505670241(3)y=285884x1+268888x2-1681508610370(4)y=488541x1+231028x2-1100707770384(5)y=124632x2-0052087203830(1)y=583898x1+93928x209600335(2)y=654318x1+188549x209600243(3)y=272993x1+211596x209540377(4)y=444280x1+161170x209470386(5)y=122544x209550377 注:表中y表示平均粮食产量;x1和x2分别表示水田和旱地的面积;分区时方程编号(1)表示成都平原区,(2)表示川中丘陵区和川东平行岭谷区;(3)表示盆周丘陵山区,(4)表示攀西地区,(5)表示川西高原区;变异系数是样本标准差与样本平均值的比值,无量纲,反映样本个体与样本平均值的偏离程度
图3 不同样本、变量尺度及常数项设置情况下模型计算结果
从表3可以看出,不管采用粮食总产还是平均粮食产量与耕地进行拟合,也不论拟合方程的常数为0还是不为0,粮食产量与耕地(水田、旱地)面积都具有很强的线性相关关系。8种模型24个方程中,相关系数大于0.80的有22个,变异系数全部小于0.50,小于0.40的有20个,小于0.30的有8个。
2 结果与分析
2.1 总体情况分析
从图3的8个制图结果来看,模型3以农业综合分区为界线形成了明显分区,主要原因是这个模型有常数项,又采用的是区域尺度(县级粮食总产量)进行回归,而制图应用是公里栅格网尺度的,所以导致区域尺度的常数项比栅格尺度的自变量大了很多,其结果就是无论耕地面积是多少,每个方程的计算结果都接近于常数项,因此出现分区的情况。模型1和模型7都出现了绝对值较大的产量负值,这是因为川西高原区耕地类型主要为旱地,水田极少,采用两个自变量拟合方程出现了较大误差的原因,由于川西高原区耕地面积本身较少,低值区在制图表达中显示不多,由于模型7有常数项,所以仍能看出部分以综合农业分区为界线形成的分区。从总体结果看有5个计算结果有负值,这是线性回归模型自身的问题,但是与粮食产量实际情况不符,需要对最大值和最小值进行修正,该文将在讨论模型精度后选择精度较高的模型进行分析。
2.2 模型精度比较
2.2.1 模型拟合精度
由于模型1和模型3是以县级粮食总产在有常数项设置的条件下拟合,通过公里栅格网制图表达的,根据廖顺宝等[14]样本尺度和常数项取值问题的研究结果可以去掉,不做讨论,所以最终仅对剩余6种粮食产量模型进行拟合精度的评价。如图4所示,由于模型2、模型5和模型6没有分区,所以直接以每个分区都是同样的相关系数和变异系数制图。可以看出,综合考虑两个系数的值及分区分布,以县级粮食总产量为样本分区且常数为0(模型4)时模型的拟合效果最优,其次是以县级粮食总产量为样本不分区且常数为0(模型2)时模型的拟合效果也较好。与已有研究类似,以县级粮食总产量为样本的模型拟合精度高于以县级平均粮食产量为样本的模型,这应该与县级平均粮食产量计算时对原有统计误差放大有关。但是以县级粮食总产量为样本不分区且常数为0(模型2)时模型的拟合效果较好,与全国尺度的研究结果不一致,全国的研究表明,无论是以行政区域尺度还是栅格尺度,均是分区比不分区好。这与四川省幅员面积仅占全国陆地面积的约4.85%,而该次研究同全国研究一样采用市县一级的行政尺度,而栅格大小也同样为1km,所以表现出不分区模型仍然有较高的拟合精度。这也说明,在省级尺度的粮食产量空间化模拟中,如果省域面积较小,且粮食生产的自然地理环境分异不大,完全可以采用不分区模型进行拟合。

图4 不同样本、变量尺度及常数项设置情况下模型相关系数(a)及变异系数(b)分布
2.2.2 空间化误差分析
根据建立的6种粮食产量模型(模型2、4、5、6、7、 8)最终得到6张粮食产量空间分布模拟图。采用负值栅格所占百分比、粮食总产量相对误差、栅格单元最大值与全省水稻单位面积产量的相对误差、平均绝对误差和决定系数5个误差评价因子对空间化结果进行评价,如表4所示。结果表明:(1)不管采用县级粮食总产还是县平均粮食产量拟合,常数项设置为非0的,均是分区比不分区的结果精度要高; (2)不管采用县级粮食总产还是县平均粮食产量拟合,常数项设置为0的,均是分区比不分区的结果精度要高; (3)对比不分区和分区这2种方法,以县级粮食总产拟合的结果要比县级平均粮食产量拟合的结果精度要高。
表4 6种粮食产量模型精度评价及其空间分布的误差评价

模型模型拟合评价空间化分布评价校正决定系数平均相对误差(%)负值栅格所占百分比(%)粮食总产量相对误差(%)栅格单元粮食产量最大值与水稻单位面积产量的相对误差(%)平均绝对误差(t)决定系数(R2)20932644404068519152704509394091327130890973507349363091450806342736025791517526476350808609046780054964662099335091070833247559402921827108776508358082524820475325018033550827
图4及表4的结果表明,以县级粮食总产为样本,全省分为5个区,常数项为0的模型精度最高,但其决定系数也仅为0.914,且空间化后负值栅格所占百分比仍有0.89%,空间化制图的精度和准确性有待进一步提高。
2.3 粮食产量空间化误差分析
以县级粮食总产为样本,全省分为5个区,常数项为0的模型制图,并对其模拟结果进行分析。
2.3.1 农业综合分区尺度空间化误差分析
从全省整体来看,粮食空间化后汇总的数据值低于统计数据,整体误差为-0.97%,这与刘忠等[2]对全国粮食产量拟合的误差结果-7.75%相比,同样是低估,但误差较小,由于刘忠是对全国粮食产量进行拟合,有较大误差也比较正常。按四川省综合农业区划的方案分区汇总空间化后粮食产量数据,并与粮食产量统计数据进行对比,制作相对误差条形图,从图中可以看出,仅川西高原区的粮食产量空间化结果误差绝对值大于5%,其他分区的粮食产量空间化结果误差绝对值都小于5%。其中高估的仅盆周丘陵山区,误差为4%。低估的4个分区中,成都平原区的误差绝对值最小,仅为-1%。以上结果可以从耕地面积占土地面积比例、农区与牧区的分类两方面来解释,误差较大的片区多为耕地面积较少,地形复杂,种植业并不占农业结构主体的区域,成都平原由于耕地面积广且集中连片,地形平缓,生产条件均一,所以模拟精度最高。

图5 综合农业分区单元粮食空间化汇总相对误差
2.3.2 地市州尺度空间化误差分析
将各地市州行政区空间化后汇总粮食产量数据和粮食产量统计数据的相对误差做条形图,从图中可以看出,大部分地市州的粮食产量空间化结果误差绝对值都小于15%,但攀枝花、广元、乐山3市的误差绝对值都大于了30%,攀枝花还大于了50%,误差较大。所有地市州中误差绝对值大于15%的有4个,其中高估的为攀枝花、广元、乐山,低估的为广安。所有地市州中误差绝对值小于15%的有17个,其中高估的为成都、绵阳、南充,低估的为自贡、泸州、德阳、遂宁、内江、南充、眉山、宜宾、达州、雅安、巴中、资阳、阿坝、甘孜、凉山。资阳的误差小于1%,为拟合精度最高的市。精度较差的地市州没有表现出很明显的地区特点,在5个分区内均有出现,但总的来说,精度最低的几个地市州都是耕地面积占幅员面积较小、山地比例较大,主要分布在盆周山区和高原山地区,仅德阳、广安例外,可能与其种植结构和生产条件有关。
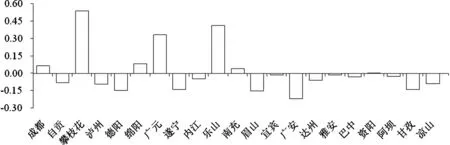
图6 地市州级行政单元粮食空间化汇总相对误差
2.3.3 县区尺度空间化误差分析
分别选择了成都平原区(4个)、川中丘陵区(11个)、盆周丘陵山区(3个)和攀西地区(3个)的21个县区进行县区级粮食产量空间化结果精度检验。选择的标准为粮食主产县、具有农业综合分区代表性和地市州级空间化误差较小者。由于川西高原区各县耕地面积都较小,所以未列入讨论范围。
将各县区级行政区空间化后汇总粮食产量数据和粮食产量统计数据的相对误差做柱状图,从图中可以看出,所有县区中误差绝对值大于10%的有10个,全部为低估,分别是崇州、广汉、泸县、合江、安县、三台、西充、仁寿、西昌、会理,所有县区中误差绝对值小于10%的有11个,其中高估的为富顺、宣汉、平昌、通江、安岳,低估的为邛崃、叙永、资中、仪陇、汉源、简阳。整体来看,低估的县区占了大部分,许多产粮大县的粮食产量被低估,应该是造成全省总产量估值偏低的原因。从四大分区抽样县区的误差绝对值来看,川中丘陵区拟合精度较高,大部分县区误差绝对值都小于10%,其次是盆周丘陵山区,成都平原区和攀西地区的拟合精度较低,误差绝对值大于20%的区县都出自这两个地区。这与全省五大分区的总体误差分布不一致,说明随着空间化单元的变小,其误差也随之增大。片区尺度上的空间化误差规律不适用于县级尺度。

图7 部分县区级行政单元粮食空间化汇总相对误差
3 结论与讨论
在综合考虑分区方案(全省不分区、全省分为5个区)和回归方程常数项(0与非0)等因素的情况下,以县级粮食总产、县平均粮食产量2种样本分别作为因变量,以对应的2种耕地类型(水田和旱地)面积数据为自变量,运用多元线性回归分析方法,建立了8种空间化模型,并获得12种粮食产量公里网格分布图(实际使用8种)。从模型拟合和空间化分布两种角度评价了结果误差,并按照农业综合分区、地市州、县区3个级别,对空间化结果的相对误差进行了分析。结果表明:
研究填补了省级粮食产量空间化研究的空白,通过探寻不同样本尺度和分区方案与空间化误差的关系,提高了空间化精度,同时对其他类型的社会经济统计数据空间化研究具有一定的参考意义。在今后的研究中,有必要考虑更多的方法和因子以进一步提高空间化结果的精度。可以从以下4个方面进行改进。
(1)进行更合理的地区分类。已有的研究表明,在空间化时根据一定指标将研究区进行分区,然后再在不同类型的区域内部进行粮食产量空间化,可以提高模拟结果精度。从研究讨论中看出,不分区与分区的模拟结果在空间分布上差异不大,但是在平均误差、负值栅格所占百分比、栅格单元粮食产量模拟最大值与水稻单位面积产量实际产量的相对误差等评价对比中,仍然是分区模拟结果经度更高。因此,在空间化时,首先根据种植业比重和其他相关指标将行政区分类,然后再在不同类型的区域内部进行粮食产量空间化,是提高模拟结果精度的有效手段。
(2)细化作物类型进行模拟。将耕地按水田和旱地进行区别对待,与已有的部分文献相比提高了模拟精度,但是由于种植结构对于粮食产量分配具有重要的影响,所以如果考虑细分不同农作物的产量,利用不同农作物的产量数据和对应的农田类型面积数据建模,进行空间化,能够进一步提高模拟精度。目前农业遥感的研究前沿之一是对农作物种植结构或农作物格局进行遥感识别[15-16],如果能利用此类数据,再结合目前省级农业农村统计年鉴中各类粮食作物的统计数据,可以将粮食产量空间化结果精度大大提高,并模拟未来的种植结构空间分布状况。
(3)利用不同的方法对空间化结果修正和表达。对于省级粮食产量空间化研究,可以采用更小的栅格单元尺度,比如500m、250m甚至更小的尺度,由于四川省丘陵、山区较多,没有北方地区大规模连片的平坦地块,所以较小的栅格单元尺度对于提高粮食产量空间分布格局的分辨率精度应该有改进。
(4)引入更多影响因素。信息是不确定性的消除,更多的信息来源会进一步提高信息的确定性,参考遥感解译中利用多源数据提高分类精度的思路,可以考虑将更多地影响粮食产量的因子纳入到空间化模型中来,包括耕地利用强度、复种指数、作物种植结构、农业生产条件、管理和投入水平、气候以及其他社会经济条件等。当然,并不是越多的数据越能提高模拟结果精度,需要对以上影响因子进行分析,选择数据容易获取、对粮食产量空间化模拟贡献率高的因子。
致谢:部分数据来源于中国科学院资源环境科学数据中心(http://www.resdc.cn)和寒区旱区科学数据中心(http://westdc.westgis.ac.cn)。
[1] 王法辉. 社会科学和公共政策的空间化和GIS的应用. 地理学报, 2011, 66(8): 1089~1100
[2] 刘忠, 李保国.基于土地利用和人口密度的中国粮食产量空间化. 农业工程学报, 2012, 28(9): 1~8
[3] 叶靖, 杨小唤,江东.乡镇级人口统计数据空间化的格网尺度效应分析——以义乌市为例. 地球信息科学学报, 2010, 12(1): 40~47
[4] 廖顺宝, 孙九林.基于GIS 的青藏高原人口统计数据空间化. 地理学报, 2003, 58(1): 25~33
[5] 廖顺宝, 李泽辉.基于人口分布与土地利用关系的人口数据空间化研究——以西藏自治区为例. 自然资源学报, 2003, 18(6): 659~665
[6] 廖顺宝, 李泽辉.四川省人口分布与土地利用的关系及人口数据空间化试验. 长江流域资源与环境, 2004, 13(6): 557~561
[7] 刘红辉, 江东,杨小唤,等.基于遥感的全国GDP 1km 格网的空间化表达. 地球信息科学, 2005, 7(2): 120~123
[8] 易玲, 熊利亚,杨小唤.基于GIS技术的GDP空间化处理方法. 甘肃科学学报, 2006, 18(2): 54~58
[9] 廖顺宝, 秦耀辰.草地理论载畜量调查数据空间化方法及应用. 地理研究, 2014, 33(1): 179~190
[10]廖顺宝, 许立民.森林蓄积量调查数据空间化的方法研究. 中南林业科技大学学报, 2013, 33(11): 1~7, 8
[11]刘学, 刘张霞.村镇区域规划中统计数据空间化研究初探.中国农业资源与区划, 2016, 37(5): 27~34
[12]柏林川, 武兰芳,宋小青.1995~2010年山东省粮食单产变化空间分异及均衡增产潜力. 地理科学进展, 2013, 32(8): 1257~1265
[13]石承苍, 刘定辉,四川省自然地理环境与农业分区.成都:四川科学技术出版社.2013: 48~55
[14]姬广兴, 廖顺宝,岳艳琳,等.不同样本尺度和分区方案的粮食产量空间化及误差修正. 农业工程学报, 2015, 31(15): 272~278
[15]吴文斌, 杨鹏,李正国,等.农作物空间格局变化研究进展评述. 中国农业资源与区划, 2014, 35(1): 12~20
[16]唐华俊, 吴文斌,杨鹏,等.农作物空间格局遥感监测研究进展. 中国农业科学, 2010, 43(14): 2879~2888
Vol.38,No.9,pp56-62
SPATIALDISTRIBUTIONOFGRAINYIELDOFSICHUANBASEDONDIFFERENTSAMPLESCALESANDPARTITIONINGSCHEMES*
HePeng1, 2, 3,LinZhengyu1, 2, 3,JingXiaowei1,LiXiao1, 2, 3※
(1.Agricultural Information and Rural Economy Institute, Sichuan Academy of Agricultural Sciences, Chengdu 610066, China;2.Regional Agricultural Research Center, Sichuan Academy of Agricultural Sciences, Chengdu 610066, China;3.Large Data Center, Sichuan Academy of Agricultural Sciences, Chengdu 610066, China)
The statistical data of agricultural economy are affected by various natural conditions and social and economic conditions. To improve the spatial accuracy of statistical data of agricultural economy, this paper explored the spatialization of grain output data at the provincial level. Taking Sichuan province as an example, according to the different partitioning schemes, it choses a different sample dat as the dependent variable, and the two types of cultivated land, paddy field, dry land area data as independent variables, and constructed a fitting multiple regression mode considering two kinds of model parameters. The results showed that the spatial accuracy of statistical data was higher in partition than that in no partition, no matter whether fitting by the average grain yield in county-level grain production or the average grain yield of county. Compared with the two methods of non-partitioning and partitioning, the fitting accuracy of the total output of the grain at the county level was higher than that of the average grain yield. It proposed that it was necessary to improve the accuracy of data reconstruction by combining more influence factors of the spatial distribution of grain yield.
grain; models; partitioning scheme; multiple variable regression; error; spatialization
10.7621/cjarrp.1005-9121.20170904
2017-07-11
何鹏(1978—),男,四川雅安人,副研究员。研究方向:农业资源与环境信息化研究。Email: 7203655@qq.com ※通讯作者:李晓(1960—),女,山西运城人,研究员。研究方向:农业信息与农村经济研究。Email:xiaolu3399@163.com *资助项目:四川省财政创新能力提升工程“大数据背景下主要农产品数量安全预警分析技术研究”(2016GYSH-004); 四川省科技支撑计划软科学项目“基于精细区划的农产品气候品质认证评价指标体系研究”(2017ZR0045)
F326.11;F224
A
1005-9121[2017]09023-10
