基于K-means的用户分群分析
2017-11-22简宋全李青海秦于钦
简宋全,李青海,秦于钦
(广东精点数据科技股份有限公司,广州510630)
基于K-means的用户分群分析
简宋全,李青海,秦于钦
(广东精点数据科技股份有限公司,广州510630)
对于各行各业来说,对客户的精准分群行为可以将大众营销的方式转换为精准营销方式从而得到更好的回报率,针对电信行业进行研究,采用K-means的聚类方法对电信用户数据进行用户分群,同时采用图像法的方式对分群个数以及分群准确程度进行分析,并从分析结果中挖掘出有用信息辅佐于运营商的业务需求。
0 引言
对于用户的分析对于各行各业都是十分重要的一环,能准确地将自己用户分为各个群体进行挖掘分析是十分重要。
对用户进行分群管理对于企业来说是一种降低成本提高效率的方法,通过群体分类,可以归结出该群体的特点、行为偏好等信息,从而推出针对性的管理方法和营销方案,已达到各个企业对成本控制以及营销召回率的需求。
然而对于用户的分群通常存在许多问题,数据的杂乱程度、量级的大小,以及类别的界定,种种原因导致了该过程难以实现。因此,本文采用K-means聚类的数据挖掘方法对用户进行聚类处理,k聚类为无监督式的数据挖掘算法,可以更具数据中的各个特征将数据分为k个群体,这样只需要分析每个群体中的特性就可以对该群体实行相应的对策和营销方案。
在本文案例中我们采用的是电信行业的用户行为数据,该数据中包含用户基本信息,如年龄、性别、在网时长、套餐手机品牌等,用户行为信息包含用户不同时间段的通话时长,缴费记录,以及一些衍生的变量,例如,用户话费方案是否合理等。该数据中包含1.8万条用户数据,经过一系列计算,我们将k值设定为3,将其分为3个群体,然后对每个群体进行统计分析,以得到最后的结果。
1 K-means聚类算法解析
聚类分析简称聚类,是一种无监督的机器学习算法,其主要作用为将一数据集分为多个不想交的数据集,且在这些数据集中的数据特征彼此相似,但与其他数据集中的数据特征中会存在明显差异。
对于聚类分析的算法解释我们可以理解为,假设存在一个数据集,该数据集可以根据数据的特征划分为k个不相交子集,且k的数量大于1,所有的子集的集合为原始数据集。并且在每个子集中,其中的数据与同子集中数据特征相似性,与其他子集中数据特征具有差异性。
K-means聚类分析是聚类分析中最常用到的一种聚类方法,该方法采用离中心点距离最短的方式进行聚类,同时指定聚类中的k值,也就是聚类后子集的个数。从数据语言上描述即可描述为存在一个数据集D,该数据集由n个对象组成,我们通过聚类分析的方式将这n个对象划分到k个子集C1,C2,…,Ck中,假设1≥i,j≥k且i≠j,使得Ci⊂D且Ci∩Cj=∅。
对于具体实现过程,我们首先要对簇心得概念进行理解。K-means聚类中,我们将k个子集称为k个簇,每个簇都具有一个簇心,该簇心为簇中所有对象的特征均值组成,而对于某个对象是否为该簇的判断条件为该对象与该簇中心的距离,这里的距离采用欧氏距离进行计算。
对于聚类分析来说,首先要确定簇心才能判断一个对象最终归属于那个簇,但是在实际生活中,我们无法直接确定簇心,故在本方法中采用无监督式的K-means算法来完成聚类,该算法迭代算法,首先在欧氏空间中随机取k个点作为簇心,然后根据簇心对所有对象进行聚类,从而产生k个簇,在利用均值特征的方式产生一个新的簇心,与原簇心进行对比,迭代,直至最后簇心不会发生变化则完成整个聚类过程。
上述描述过程,其流程算法如下:
①随机取k个种子点
②然后求数据中每个点分别到这些种子点的欧氏距离,并将这些数据点归于其欧氏距离最短的种子点下,形成k个簇。
③然后移动种子点值其簇的中心。
④然后重复②、③步,直至第③步中种子点不会在移动,也就是种子点的原始位置为该簇的中心。
2 实验过程及结果
在对该份数据进行实验之前需要对该份数据进数据预处理,由于聚类分析只支持对数值型变量的计算,故需要对数据中的字符型变量进行0/1化处理,对于某些多分类字符型变量则采取去除占比较少分类后在做0/1化处理。
处理结束后,则采用R语言进行K-means聚类分析,在分析中我们对k值分别选择了2、3、4、5进行分析,得出的结果分别为:

图1
上图从左上到右下分别为k值为2、3、4、5时的K-means聚类图,从途中可以看出,无论取k为几,都具有将类别聚为3类的趋势,故将k设定为3,进行聚类分析,将数据进行聚类。
我们分别对3个类进行研究:
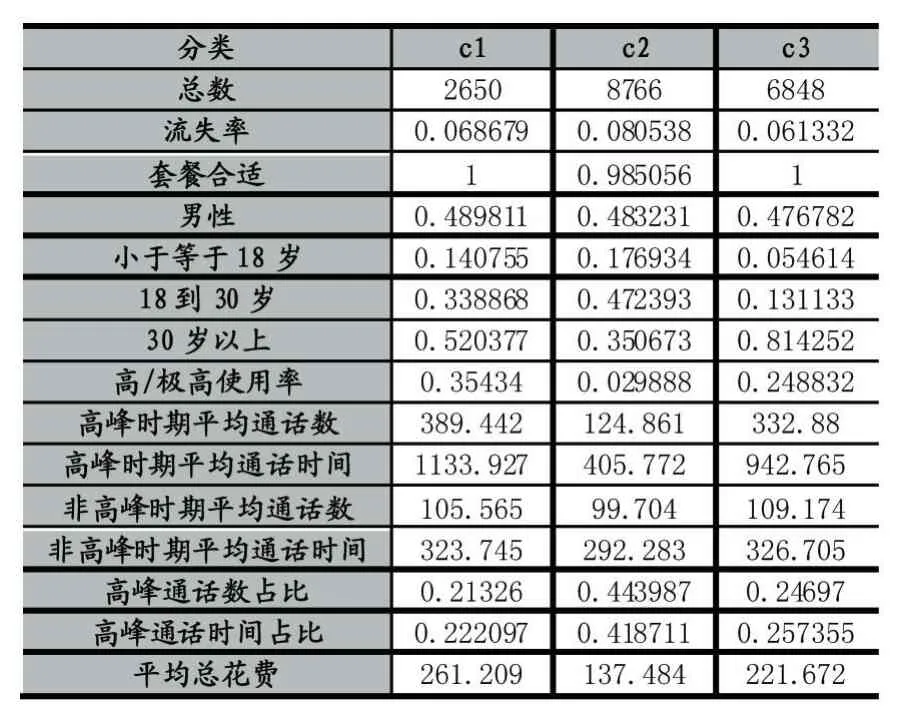
表1
从聚类后的统计结果可以看出,用户被分为了三个类,分别包含2650、8766和6848个用户。
从寻找流失原因角度看,其中c2类包含最多的8766个用户,同事其流失率也是最高的,同比其他两给类高出30%,在对c2类进行进一步研究可以发现,该类中18至30岁用户最多,也就说明在这个年龄段中的人最容易流失,而小于18岁和大于30岁的用户流失的可能性不大。同时从使用率上也可以看出,在该类用户中高/极高使用率只有3%,相较于其他两个分类的35%和24%都低了很多。可以发现该原因也是导致用户流失的重要原因。
再从用户管理角度可以看出,c1和c3主要为30岁以上客户,切c3类中的18岁一下客户较少,c2主要为18到30岁客户。同时c1和c3的通话主要产生于非高峰时段,而c2再高峰时段通话占比高达44%,故可以看作该类用户打多为上班族,通常采用该号码进行工作上的联系。
同样的方法还可以提取到很多信息,在本问中就不再赘述,可由读者自行开发。
3 结果评估
该模型在聚类中采用图像法对聚类数目,该方法简单易理解,得出结果也具有一定的研究价值,但是在聚类上可能会存在一定的不稳定性,例如在上述试验中c1类和c2类的区别就不是很明显,同时部分特征如男女分布情况等没有明显体现出来,故还有改进的余地例如利用轮廓系数对聚类k值进行判断等,同时对于该聚类结果进行进一步的聚类分析也可以对分析结果有一定的帮助。
4 结语
本模型致力于简单的完成聚类分析过程,同时可以让该过程产生一定有价值的结果,同时该模型还有很多方面可以改进或深入,已达到更好的效果。
简宋全(1971-),男,广东广州人,硕士研究生,工程师,研究方向为机器学习算法
李青海(1980-),男,广东广州人,硕士研究生,工程师,研究方向为机器学习算法
秦于钦(1993-),男,广东广州人,本科,助理工程师,研究方向为机器学习算法
2017-07-11
2017-09-28
K-means;Telecom;Industry;Precision;Marketing
User Group Analysis Based on K-means
JIAN Song-quan,LI Qing-hai,QIN Yu-qin
(Guangdong Fine Point Data Polytron Technologies Inc,Guangzhou 510630)
It is necessary to cluster customers accurately in every walk of life so that we can change a popular marketing program into an accurate mar⁃keting program for better return on equity.Studies the telecom industry,adopts clustering method of K-means to cluster telecom users,and uses a method based on imaging processing to analyze the number and the accuracy of clustering at the same time,to search for useful mes⁃sages for operator's business requirements.
K-means;电信行业;精准营销
天河区科技计划项目(No.201502YH019)
1007-1423(2017)29-0029-03
10.3969/j.issn.1007-1423.2017.29.007
