基于C均值聚类和图转导的半监督分类算法
2017-11-15王小凤耿国华宋倩楠
王 娜,王小凤,耿国华,宋倩楠
(西北大学 信息科学与技术学院,西安 710000)(*通信作者电子邮箱xfwang@nwu.edu.cn)
基于C均值聚类和图转导的半监督分类算法
王 娜,王小凤*,耿国华,宋倩楠
(西北大学 信息科学与技术学院,西安 710000)(*通信作者电子邮箱xfwang@nwu.edu.cn)
针对传统图转导(GT)算法计算量大并且准确率不高的问题,提出一个基于C均值聚类和图转导的半监督分类算法。首先,采用模糊C均值(FCM)聚类算法先对未标记样本预选取,缩小图转导算法构图数据集的范围;然后,构建k近邻稀疏图,减少相似度矩阵的虚假连接,进而缩减了构图的时间,通过标记传播的方式得出初选未标记样本的标记信息;最后,结合半监督流形假设模型利用扩充的标记数据集以及剩余未标记数据集进行分类器的训练,进而得出最终的分类结果。在Weizmann Horse数据集下,所提算法分类准确率均达到96%以上,和传统仅使用图转导的分类方法相比,解决了对初始标记集的依赖性问题,将准确率至少提高了10%;将所提算法直接运用到兵马俑数据集,分类准确度也达到95%以上,明显高于传统的图转导算法。实验结果表明,基于C均值聚类和图转导的半监督分类算法,在图像分类方面有较好的分类效果,对图像的精准分类具有研究意义。
C均值聚类;图转导;半监督分类;相似度矩阵;稀疏图
0 引言
目前,监督学习、无监督学习以及半监督学习算法为三大热门学习算法。基于现实中图像、模型等领域具有的海量数据中只有小部分标记样本的现状,充分利用标记数据以及无标记数据进行分类学习,成为更主流的研究方式,这也造就了半监督学习算法在分类算法中炙手可热的地位。半监督学习算法拥有两个分支,即归纳学习算法和转导学习算法,其中,是否生成分类器是两种算法最大的区别。具体而言,归纳学习是利用标记数据和未标记数据学习得到分类器,进而通过分类器进行数据分类的方法,而图转导(Graph Transduction,GT)学习并不需要形成分类器,直接利用整个数据集便可以进行分类。相比而言,图转导算法更为经济。在图转导算法中,聚类假设、流形假设以及局部和全局一致性假设是比较常用的假设方法,其中,聚类假设保障了图转导算法中,数据在相邻位置上相似度较高时,对应节点趋于相似的标记。因此,本文重点研究基于聚类假设的图转导学习方法,使用图结构来表示输入的数据集,图的每个顶点分别对应数据集中的一个样本数据信息,每条边的权重代表样本数据之间的相似程度,并且在进行构图前,提前进行无标记样本的预选取,结合半监督算法实现大量未标记样本的分类。
1 相关工作
目前,国内外已有很多学者对图转导算法进行研究,并提出诸多算法。标签传播(Label Propagation, LP)算法[1]是图转导算法的基础,通过图的边将标记信息传播到未标记节点,由于图转导算法是基于聚类假设,所以权重大的边比权重小的边标记传播更容易一些,在权重为0的边终止标记传播。在此基础上衍生出调和高斯场(Harmonic Gaussian Field, HGF)[2]、局部与全局一致性(Learning with Local and Global Consistency, LLGC)[3]、极大极小标签传播(MiniMax Label Propagation, MMLP)算法[4]、最小代价路径标签传播(Label Propagation through Minimum Cost Path, LPMCP)算法[5]等方法。不论是HGF还是LLGC算法都过于依赖初始标记集,若图中含有噪声,或者因为其他因素使得输入数据集不可划分类别时,通过图转导方法得到的分类结果缺乏准确性。
实际中并不是所有的无标记样本都能对分类提供帮助,因此挑选出对分类有用的无标记样本会提高分类准确性,也会提高构图的效率。文献[6]中采用主动学习人工标注的方式初选未标记样本,但是人工标注样本会增加时间开销。为了解决该问题本文利用模糊C均值(Fuzzy C-means, FCM)聚类算法对无标记样本进行聚类,然后在聚类结果基础上进行无标记样本的选取,得出最好的选取方式;将无标记样本中部分含有对分类有用信息的样本加入到训练样本集[7],避免了人工参与标注。
传统图转导(GT)算法构建全相连图,需要将所有的边都存储计算,而本文构建k近邻稀疏图,可以自适应样本特征空间中的密度,得到真实的权重,不仅阻止了相似度低节点信息的传递,也提高了算法运算速度。为了能更进一步提高分类的精度,本文进一步利用半监督学习(Semi-Supervised Learning, SSL)算法[8-9]得出最后的分类结果。具体的思路如图1所示。

图1 本文算法思路
2 算法描述
假设有n个样本点的数据集参与分类,即X={x1,x2,…,xn},已标记数据集Xl={x1,x2,…,xl},未标记数据集为Xu={xl+1,xl+2,…,xn},其中n=l+u,且l≪u,类别数量已知为c。Yl={y1,y2,…,yl},yi∈{1,2,…,c}为已标记数据集Xl所对应的标记集,并且假设Yl中包含所有的类别标记。
在此定义的基础之上,本文算法主要分为3步:
步骤1 使用FCM聚类算法对未标记样本进行聚类,根据聚类结果选取聚类的边界点作为训练集的未标记样本集;
步骤2 对训练集样本使用GT算法进行构图,得出训练集中未标记样本类别信息;
步骤3 采用半监督流形学习框架[10]对步骤1中没有选入训练集的未标记样本进行分类。
2.1 FCM聚类算法
参与FCM聚类的数据为Xu中的所有样本数据,c为预定类别数,ui(i=1,2,…,c)为每一个聚类的中心,准则函数定义为:

(1)
其中:‖xj-ui‖表示样本点xj与ui之间的欧氏距离,模糊加权幂指数m,依据经验取m=2,U是样本集Xu的隶属度矩阵;uij代表样本xj对于ui的隶属度;V是样本集Xu的ui组成的聚类中心集合;通过使J(U,V)达到最小来获得U和V。

(2)
i=1,2,…,c,j=l+1,l+2,…,n
(3)
依据迭代的方法得到最终的聚类结果。由于不能保证FCM聚类得到的解是全局最优解,需要运行多次,来选择最优解[11]。
这里yi∈{+1,-1},选取聚类边界的未标记样本,具体选取步骤如下:
第1步 所有未标记样本进行FCM聚类;
第2步 根据第1步得到的聚类结果,计算每一个样本到聚类中心的距离,存储于数组A中,并将数组A进行排序,由大到小存储;另外计算这些样本到另一聚类中心的距离,并存储于数组B,并将数组B按从小到大的顺序存储。
第3步 选择数组A和数组B中前m个共同的样本作为预选样本集合Xu′中的元素。
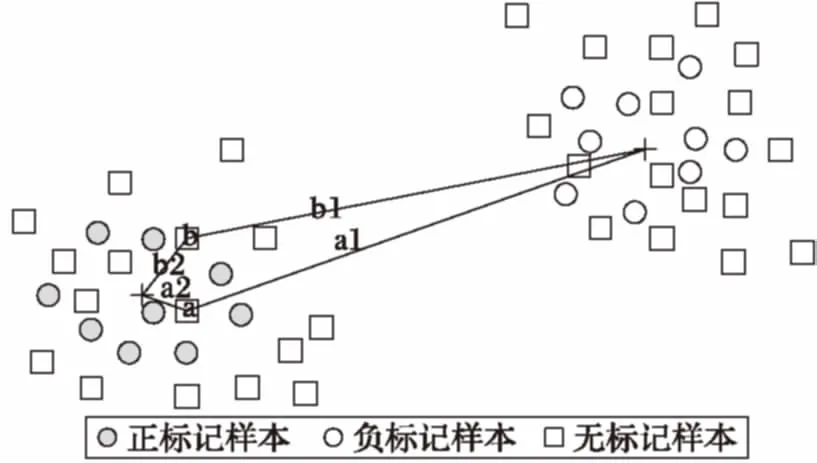
图2 无标记样本预选图
如图2以正标记样本聚类中心附近的无标记样本为例,其一无标记样本a,距离正标记样本聚类中心的距离为a2,距离负聚类中心的距离为a1,将a2存储于数组A,a1存储于数组B;无标记样本b,距离正标记样本聚类中心的距离为b2,距离负标记样本聚类中心的距离为b1,将b2存储于数组A,b1存储于数组B。依次计算出所有未标记样本到达正、负聚类中心的距离,依据第2步、第3步的步骤选择聚类边界的无标记样本,作为初选未标记样本集中的元素。
2.2 图转导算法
图转导算法定义了一个无向图G={X′,E},图中的节点为数据集X′={Xl,Xu′},节点间通过E={(xi,xj)}连接。X′代表一个新组合的集合,其中包含原已标记集合Xl和预选出的未标记集合Xu′,则剩余的未标记样本集为{Xu-Xu′} 。由于稀疏图得到的稀疏相似度矩阵中节点间的虚假连接较少,更利于真实权重的获得,所以文中采用稀疏的k近邻图来构建图[12],生成的相似度矩阵为W={wij}。使用高斯核函数来计算得到W,即:
wij=exp(-‖xi-xj‖2/σ2)
(4)
其中,σ为带宽参数,且满足σ>0。
建立图结构后,利用已有样本标记信息预测出未标记样本隐含的标记信息,期间通过将标记信息按照样本之间的相似度进行传递[13]。样本之间的相似度越大,即边上的wij值越大,越容易传递。
同时,转移概率矩阵为Pn×n,具体i行j列的元素为:
(5)
表示样本xi将标记信息传递到样本xj的概率。定义矩阵fL,大小为l×c,fU大小为u×c,其中l表示标记样本的数目,u表示未标记样本的数目,c表示类别数目。fL,fU的第j个元素定义为:
(6)
表示只有当与样本xi类别相同的序列号对应元素为1,其余均为0。L、U分别表示标记数据集和未标记数据集。用n×c的矩阵fX表示所有数据的类别:
(7)
由于未标记样本的标记信息来源于近邻样本的传递,则可表示为:
(8)
具体步骤描述如下:
第2步 根据式(5)计算出概率转移矩阵P;

2.3 半监督流形学习框架
假设决策函数为f,半监督流形学习框架定义如下:

(9)
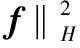
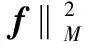
(10)
将式(10)代入式(9)中,得:
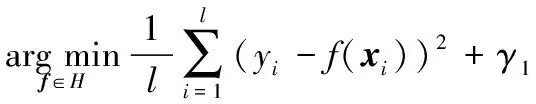

(11)

根据定理(文献[14]中已证明),式(11)的解可由如下形式表示:
(12)
将式(12)代入式(5)中,得到:
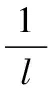
(13)
对式(13)求导并等于0,进一步得到:

(14)

3 实验及结果
3.1 数据及参数选择
首先使用Weizmann Horse数据集对算法进行验证,选取horse322(250×205)、horse288(350×276)、horse238(800×571)、horse074(627×800)图像。因为Weizmann Horse数据集本身有理想分类,所以本文对各种分类方法的效果和理想分类效果进行比较。为了验证本算法实际应用效果,本文进一步选取西北大学可视化所兵马俑数据集中G3-I-a-16俑(322×359)、84L864唐胡人俑(545×691)、569彩色骑马俑(1 023×849)、556彩色马俑(690×517)、557彩色马俑(690×517)进行实验验证。
本实验以这些数据的二维图像模型为对象,对本文提出的分类算法进行验证。对这些二维图像本身进行分类,分为背景和目标对象。每幅图像以画线方式选取已标记点,具体选取结果如表1所示。

表1 实验图像像素点选择情况
实验具体过程如下:
首先运用FCM聚类算法进行聚类,由于FCM聚类算法选取的聚类中心会对实验产生影响,所以进行10次实验,取平均结果作为最后的聚类结果。
然后在聚类结果基础上选取聚类边界(Border)的100个未标记点加入训练集,接着使用GT算法进行构建k近邻图,确定出未标记点的类别信息,加入到已标记数据集,需要确定k近邻图的近邻数N,以及参数高斯核函数的带宽σ,其中根据多次实验的经验值,将近邻数N取值为10;选取加入训练集的未标记样本的方式还可以采用随机(Random, R)、靠近聚类中心(Center, C)的方式,本文对比了这三种效果。
最后采用半监督算法对其余未标记点进行分类,得到分类结果。需要确定控制在希尔伯特空间(RKHS)函数复杂性的参数γ1,控制内在几何结构的函数复杂性参数γ2。本文采用三层网格搜索[15-16]的方式,将找到的分类正确率最高的参数格点作为最优的参数对,即在lbσ={-10∶1∶10}、lgγ1={-5∶1∶5}和lgγ2={-5∶1∶5}参数范围内的三层网格中搜索得到。参数值的设定如表2所示。

表2 三种方法的参数选择
3.2 结果及对比分析
本文采用三种评价方式对文中方法的分类效果进行评价:
1)PCR评价方式。
本文所述算法的分类效果使用图像中被正确分类的像素数与总像素数的比值进行评价,如以下公式:
PCR=正确分类像素数/图像总像素数
其中,PCR(Pixel Classification Rate)即像素分类正确率。
2)APCR评价方式。
使用每个类的像素分类正确率的均值,作为第二个衡量算法分类效果的指标[17],公式如下:
APCR=(背景分类正确率+目标对象分类正确率)/2
其中,APCR(Average Pixel Classification Rate)表示两类分类正确率的平均正确率。
3)Time评价方式。
进一步依据算法的执行时间,对算法效率进行评估。
几种分类方法的分类效果如图3、图4所示。

图3 不同方法分类结果(Weizmann Horse数据集)

图4 不同方法分类结果(兵马俑数据集)
利用Weizmann Horse数据集验证的分类效果如图3所示,通过各分类算法的分类结果与理想分类结果进行直观比较,可以看出GT(B)+SSL算法的分类效果更接近于理想分类效果。如图4所示,本文算法实际运用于兵马俑数据时,仍保持了很好的分类效果。
表3具体从PCR、APCR、Time三种评价角度对几种分类方法进行对比。由表3可知:1)传统的图转导方法没有对未标记样本进行初选操作,直接对所有的样本进行构图分类得到最终分类结果,运行时间低,但是分类效果不佳。2)GT(B)+SSL算法运行时间较GT算法而言明显加长,是因为本文算法对标记样本进行了预选取,增加了运行时间,虽然选取结束后还需要构建k近邻图以及半监督分类两个阶段,但是由于构建的是稀疏图,训练样本数大大减少,所以后两个阶段并不会对运行时间产生多大影响,但是极大地提高了分类的准确率。3)GT(B)+SSL与GT(C)+SSL、GT(R)+SSL相比,由于执行的阶段相同,所以运行时间相近,但是选取聚类边界的数据作为构图前的未标记样本集,比随机选取数据或靠近聚类中心选取数据的方式,更能找到含有隐含信息的数据,所以GT(B)+SSL分类准确率明显高于其他两种方法。4)不论从PCR指标,还是APCR指标对几种算法评估,GT(B)+SSL算法分类准确率都优于其他几种分类算法。
此外标记样本数量的多少也会对分类的准确度产生影响,分别选取horse238、horse074、556俑图像进行以下分类实验。表4分别给出不同标记样本数的实验结果对比。

表3 GT方法、GT(R)+SSL方法、GT(C)+SSL方法、GT(B)+SSL(本文方法)实验结果对比

表4 选择不同标记样本数的实验结果对比
分类结果较优的数据已在表格中加粗显示,从表4 知:随着标记像素数的增多,分类准确度也会随着提高。GT(B)+SSL算法与其他几种分类算法相比,即使在标记像素数稀少的情况下,也具有较好的分类准确度。
4 结语
通过对未标记样本进行预选,挑出携带对分类有帮助的未标记样本加入训练集,然后构建k近邻稀疏图,使得构图的数据节点大大减少,提高构图的效率。利用图转导的方式将未标记样本进行分类,得到更多可靠的标记样本数据,再使用半监督方式利用增多的标记样本和剩余未标记样本进行分类器的训练,这样得到的训练分类器分类精度更好。此外,本文算法不论对于背景单一的图像,还是背景复杂的图像,分类准确率都明显高于其他三种分类算法。目前本文算法只针对二分类问题,未来研究将二分类问题延伸到多分类问题。
References)
[1] ZHU X , GHAHRAMANI Z. Learning from labeled and unlabeled data with label propagation [EB/OL]. [2016- 12- 14]. http://pages.cs.wisc.edu/~jerryzhu/pub/CMU-CALD-02-107.pdf.
[2] ZHU X, GHAHRAMANI Z, LAFFERTY J. Semi-supervised learning using Gaussian fields and harmonic functions [C]// Proceedings of the 20th International Conference on Machine Learning. Menlo Park, CA: AAAI Press, 2003: 912-919.
[3] ZHOU D, BOUSQUET O, LAL T N, et al. Learning with local and global consistency [C]// Proceedings of the 16th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2003: 321-328.
[4] KIM K H, CHOI S. Label propagation through minimax paths for scalable semi-supervised learning [J]. Pattern Recognition Letters, 2014, 45(1): 17-25.
[5] 汪西莉,蔺洪帅.最小代价路径标签传播算法[J].计算机学报,2016,39(7):1407-1418.(WANG X L, LIN H S. Label propagation through minimum cost path [J]. Chinese Journal of Computers, 2016,39(7):1407-1418.)
[6] 晋小玲.图转导理论的研究与应用[D].北京:华北电力大学,2011:6-15.(JIN X L. Research and application of graphic conduction theory [D]. Beijing: North China Electric Power University, 2011: 6-15.)
[7] KUMAR D M, PRASHANTH K, PERURU P K, et al. A novel technique for edge detection using Gabor transform andk-means with FCM algorithms [M]// Emerging Trends in Electrical, Communications and Information Technologies, LNEE 394. Berlin: Springer, 2017: 273-280.
[8] TANHA J, SOMEREN M V, AFSARMANESH H. Semi-supervised self-training for decision tree classifiers [J]. International Journal of Machine Learning & Cybernetics, 2017, 8(1): 355-370.
[9] KIM K I, TOMPKIN J, PFISTER H, et al. Semi-supervised learning with explicit relationship regularization [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 2188-2196.
[10] 白艺娜.基于图的半监督图像分类[D].西安:陕西师范大学,2014:10-17.(BAI Y N. Semi-supervised image classification based on graph [D]. Xi’an: Shaanxi Normal University, 2014: 10-17.)
[11] 陈永健.半监督支持向量机分类方法研究[D].西安:陕西师范大学,2014:17-18.(CHEN Y J. Research on classification method of semi-supervised support vector machine [D]. Xi’an: Shaanxi Normal University, 2014: 17-18.)
[12] SONG W, LI S, KANG X, et al. Hyperspectral image classification based onKNN sparse representation [C]// Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium. Piscataway, NJ: IEEE, 2016: 2411-2414.
[13] JING L, YANG L, YU J, et al. Semi-supervised low-rank mapping learning for multi-label classification [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1483-1491.
[14] BELKIN M, NIYOGI P, SINDHWANI V. Manifold regularization: a geometric framework for learning from examples [J]. Journal of Machine Learning Research, 2004, 7(1): 2399-2434.
[15] HUANG Q, MAO J, LIU Y. An improved grid search algorithm of SVR parameters optimization [C]// Proceedings of the 2012 IEEE 14th International Conference on Communication Technology. Piscataway, NJ: IEEE, 2013: 1022-1026.
[16] PONTES F J, AMORIM G F, BALESTRASSI P P, et al. Design of experiments and focused grid search for neural network parameter optimization [J]. Neurocomputing, 2016, 186: 22-34.
[17] FU W, LI S, FANG L. Spectral-spatial hyperspectral image classification via superpixel merging and sparse representation [C]// Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium. Piscataway, NJ: IEEE, 2015: 4971-4974.
Semi-supervisedclassificationalgorithmbasedonC-meansclusteringandgraphtransduction
WANG Na, WANG Xiaofeng*, GENG Guohua, SONG Qiannan
(CollegeofInformationScienceandTechnology,NorthwestUniversity,Xi’anShaanxi710000,China)
Aiming at the problem that the traditional Graph Transduction (GT) algorithm is computationally intensive and inaccurate, a semi-supervised classification algorithm based on C-means clustering and graph transduction was proposed. Firstly, the Fuzzy C-Means (FCM) clustering algorithm was used to pre-select unlabeled samples and reduce the range of the GT algorithm. Then, thek-nearest neighbor sparse graph was constructed to reduce the false connection of the similarity matrix, thereby reducing the time of composition, and the label information of the primary unlabeled samples was obtained by means of label propagation. Finally, combined with the semi-supervised manifold hypothesis model, the extended marker data set and the remaining unlabeled data set were used to train the classifier, and then the final classification result was obtained. In the Weizmann Horse data set, the accuracy of the proposed algorithm was more than 96%, compared with the traditional method of only using GT to solve the dependence problem on the initial set of labels, the accuracy was increased by at least 10%. The proposed algorithm was applied directly to the terracotta warriors and horses, and the classification accuracy was more than 95%, which was obviously higher than that of the traditional graph transduction algorithm. The experimental results show that the semi-supervised classification algorithm based on C-means clustering and graph transduction has better classification effect in image classification, and it is of great significance for accurate classification of images.
C-means clustering; Graph Transduction (GT); semi-supervised classification; similarity matrix; sparse map
2017- 04- 01;
2017- 06- 01。
国家自然科学基金青年科学基金资助项目(61602380);国家自然科学基金面上项目(61373117, 61673319);陕西省国际合作项目(2013KW04-04)。
王娜(1993—),女,陕西榆林人,硕士研究生,主要研究方向:图像处理、模式识别; 王小凤(1979—),女,陕西渭南人,副教授,博士, CCF会员,主要研究方向:数据挖掘、三维模型检索、模式识别; 耿国华(1955—),女,山东莱西人,教授,博士,CCF会员,主要研究方向:科学计算可视化、模式识别、智能信息处理; 宋倩楠(1994—),女,山西运城人,硕士研究生,主要研究方向:图像处理、模式识别。
1001- 9081(2017)09- 2595- 05
10.11772/j.issn.1001- 9081.2017.09.2595
TP391.4
A
This work is partially supported by Youth Science Foundation of the National Natural Science Foundation of China (61602380), the General Program of the National Natural Science Foundation of China (61373117, 61673319), Shaanxi Province International Cooperation Project (2013KW04-04).
WANGNa, born in 1993, M. S. candidate. Her research interests include image processing, pattern recognition.
WANGXiaofeng, born in 1979, Ph. D., associate professor. Her research interests include data mining, 3D model retrieval, pattern recognition.
GENGGuohua, born in 1955, Ph. D., professor. Her research interests include scientific computing visualization, pattern recognition, intelligent information processing.
SONGQiannan, born in 1994, M. S. candidate. Her research interests include image processing, pattern recognition.
