面向不平衡数据集的一种精化Borderline-SMOTE方法
2017-11-09卢诚波徐根海
杨 毅,卢诚波,徐根海
(丽水学院 工学院,丽水 323000)
面向不平衡数据集的一种精化Borderline-SMOTE方法
杨 毅,卢诚波,徐根海
(丽水学院 工学院,丽水 323000)
合成少数类过采样技术(SMOTE)是一种被广泛使用的用来处理不平衡问题的过采样方法,SMOTE方法通过在少数类样本和它们的近邻间线性插值来实现过采样.Borderline-SMOTE方法在SMOTE方法的基础上进行了改进,只对少数类的边界样本进行过采样,从而改善样本的类别分布.通过进一步对边界样本加以区分,对不同的边界样本生成不同数目的合成样本,提出了面向不平衡数据集的一种精化Borderline-SMOTE方法(RB-SMOTE).仿真实验采用支持向量机作为分类器对几种过采样方法进行比较,实验中采用了10个不平衡数据集,它们的不平衡率从0.0647到0.5360.实验结果表明:RB-SMOTE方法能有效地改善不平衡数据集的类分布的不平衡性.
不平衡数据集;分类;过采样;支持向量机
不平衡数据集在现实生活中广泛存在,如信用卡欺诈检测、网络攻击识别、医学疾病诊断识别、文本分类等各个领域均存在不平衡数据集[1-2].不平衡数据集的主要特性是类分布不平衡性,少数类的样本数量远小于多数类的样本数量[3].传统的分类方法如支持向量机、决策树、贝叶斯网络、k近邻等都是基于整体分类精度最大化而设计的,这往往导致分类时多数类的分类精度较高而少数类的分类精度较低.
但在实际生活当中,少数类样本被错分的代价往往会高于多数类样本的错分代价.如医疗诊断当中,把病人(少数类)错误地诊断为正常人(多数类),将会延误病情,严重的甚至会危及病人的生命,因此提高不平衡问题中少数类样本的分类性能是一个有意义的研究课题.
目前,对于不平衡问题的解决方法主要从分类算法层面和数据层面进行研究.
分类算法层面上,比较常用的方法有代价敏感学习[4-5]、单分类器方法[6-7]和集成学习方法[8-9].代价敏感学习的思想是根据不平衡数据集的样本数量对不同的类别赋予不一样的惩罚参数,通过提高少数类样本的惩罚参数使得少数类样本尽可能地被正确分类[10-11].单类学习算法的主要思想是只对目标类的样本进行学习,通过比较新样本与目标类样本的相似度判别新样本是否属于目标类.Hippo[12]就是一种单类学习算法,它利用神经网络作为分类算法,只对少数类样本进行学习,从而识别少数类中存在的模式,并不对少数类和多数类进行区别.集成学习方法的基本思想是将若干个弱分类器组合起来,赋予弱分类器不同的权重整合成一个强分类器.集成学习方法中最有代表性的算法之一就是AdaBoost算法,它是在Bossting算法的基础上发展起的.
数据层面上,是通过某些策略来改变样本的分布,将不平衡样本转化为相对平衡分布的状态,最简单的做法就是随机采样.随机采样主要分为随机过采样和随机欠采样两种方式.随机过采样指的是通过多次有放回的从少数类样本中随机地抽取数据集,增加原始的少数类样本数量,与多数类样本构成新的相对平衡的新数据集.随机欠采样正好相反,即通过从多数类样本中随机地选择部分样本,与少数类样本合成新的数据集.
随机过采样方法虽然简单方便,但该方法不能给予样本新的信息,反而可能会导致过拟合.Chawla等提出了“合成少数类过采样技术”(Synthetic Minority Oversampling Technique,SMOTE)[13],该方法通过内插的方式合成新生的少数类样本,能更好地改善不平衡数据集的分布.文献[14]在SMOTE方法的基础上提出了Borderline-SMOTE方法,该方法把少数类样本分为安全样本、边界样本和噪声样本3类,并对边界样本进行近邻插值,该方法考虑到了少数类内部的分布不均的现象,但对边界样本之间的差异未做考虑.
本文在Borderline-SMOTE方法的基础上对边界样本做了进一步的精细化,提出了面向不平衡数据集的一种精化Borderline-SMOTE方法(Refined Borderline-SMOTE,RB-SMOTE).根据边界样本的具体分布,对其设置不同的过采样倍率,再通过近邻插值增加少数类样本的数量,进一步改善数据集的不平衡分布.
1 相关工作
1.1SMOTE方法
假设原始训练样本为T,其少数类为P,多数类为N,且P={p1,p2,…,pi,…,pp num},N={n1,n2,…,ni,…,nn mum},其中pnum,nmum分别表示少数类样本个数和多数类样本个数.SMOTE方法可描述如下.
步1 计算少数类样本中的每个样本点pi与少数类样本P的欧氏距离,获得该样本点的k近邻.
步2 根据采样倍率U,在k近邻中选择合适的个数s,pi与s个近邻进行线性插值.
步3 合成新的少数类样本syntheticj=pi+rj×dj(j=1,2,…,s),其中:dj表示pi与其s个近邻的距离;rj是介于0与1之间的随机数.
步4 新合成的少数类样本与原始训练样本T合并,构成新的训练样本T′.
该方法合成新生样本的规则赋予了少数类样本更多的新信息,避免了随机过采样的盲目性学习.
1.2Borderline-SMOTE方法
Borderline-SMOTE是在SMOTE基础上发展起来的一种过采样方法,具体步骤描述如下.
步1 计算少数类样本中的每个样本点pi与所有训练样本的欧氏距离,获得该样本点的m近邻.

步4 合成的少数类样本与原始训练样本T合并,构成新的训练样本T′.
与SMOTE方法相比,Borderline-SMOTE方法只针对边界样本进行近邻线性插值,使得合成后的少数类样本分布更为合理.
2 RB-SMOTE方法的具体步骤
不平衡数据的分类学习过程中,其边界类的点更容易被错误地分类,因此很多分类算法在训练过程中都尝试对其边界的样本点进行重点学习[14].本文在Borderline-SMOTE的基础上对少数类中的边界样本加以区分,选取合适的采样倍率,精细化分配新生成的样本数量,该方法称之为精化Borderline-SMOTE方法(RB-SMOTE),根据过采样倍率的取法不同,我们分别提出RB-SMOTE1和RB-SMOTE2两种方法.
下面给出RB-SMOTE1的具体步骤.
步1 计算少数类样本与训练样本的近邻.
计算少数类样本P的样本点pi(i=1,2,…,pnum)在原始训练样本T中的m近邻,设在m近邻中有m′个属于多数类样本,显然0≤m′≤m.
步2 对少数类样本进行划分:
若m′=m,表示pi的所有m近邻都属于多数类样本,此时pi被认为是噪声;
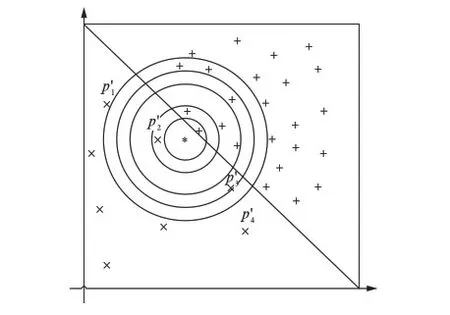
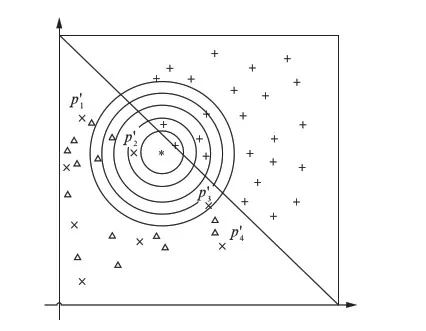
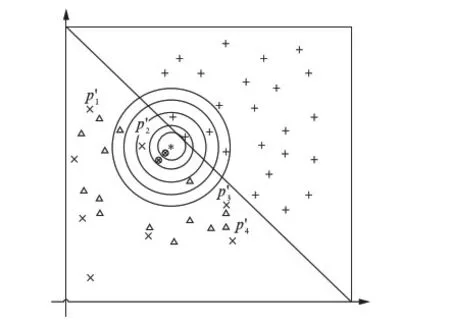
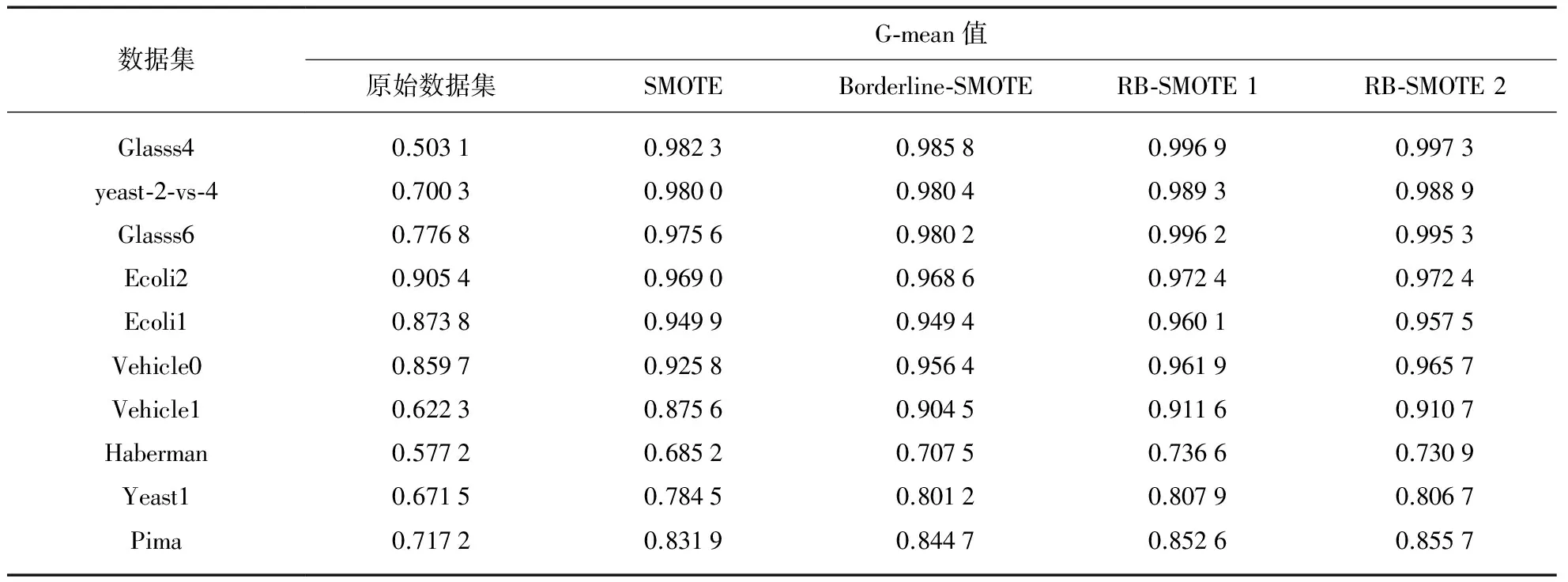
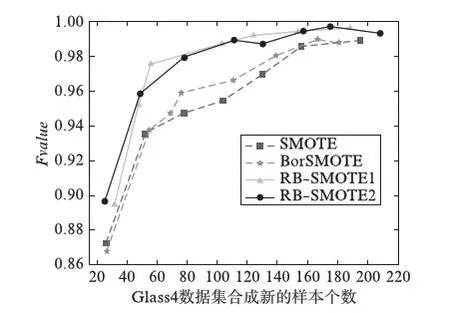
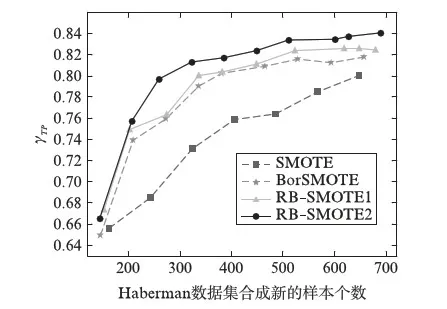
若m/t≤m′ 若0≤m′ 步3 设置采样倍率Ui(i=1,2,…,pnum). 步4 边界样本与少数类样本插值合成新生的少数类样本. 步5 合成的少数类样本与原始训练样本T合并,构成新的训练样本T′. RB-SMOTE2在第3步设置采样倍率时与RB-SMOTE1有所不同.RB-SMOTE2的第3步具体描述如下: RB-SMOTE1与RB-SMOTE2的基本思想是一致的,都是对少数类样本中的边界样本加以区别,“按需分配”设置不同的采样倍率,使得接近于多数类样本的少数类边界样本的采样倍率更高,合成的少数类样本分布更为合理,从而提高分类器的分类效果. 图1为未经处理的原始数据集的分布,图2~图4为分别使用SMOTE、Borderline-SMOTE和RB-SMOTE等方法处理后的数据集的分布. 图1 原始数据分布Fig.1 The original distribution of data 图2 SMOTE方法合成新的样本Fig.2 New samples synthesized by SMOTE method 图3 Borderline-SMOTE方法合成新的样本Fig.3 New samples synthesized by Borderline-SMOTE method 图4 RB-SMOTE方法合成新的样本Fig.4 New samples synthesized by RB-SMOTE method 以下分别用SMOTE、Borderline-SMOTE和RB-SMOTE3个过采样算法增加少数类样本点,合成训练样本,并把图1中的少数类样本点从8个增加到24个,以达到少数类样本点与多数类样本点在数量上的平衡. 图2中“△”表示原始少数类样本与其近邻合成的少数类样本.采样倍率U=2,即与其近邻合成新生的少数类样本点有16个.此时,“*”的k近邻所包含的多数类样本点的个数仍然大于少数类样本点的个数,用k近邻方法判断其类别时,还是会错误地将“*”判断为多数类样本. 从这个例子可以看出,对少数类边界样本进行精细化处理,能进一步改善数据集的不平衡分布. 实验采用5折交叉验证法,运行20次,取平均值.使用的仿真软件为Matlab R2012a,实验的环境为:Windows10 64bit操作系统,Intel Core i7-2620M 2.70GHz,12GB内存.利用支持向量机(Support Vector Machine,SVM)作为分类器,分类过程中选取核宽为0.8的径向基核. 表1 数据集的描述Tab.1 Description of datasets 3.1测试数据集描述 实验选取了不平衡率不一的10个数据集,分别来源于UCI数据库(https:∥archive.ics.uci.edu/ml/index.html)和KEEL数据库(http:∥sci2s.ugr.es/keel/study.php?cod=24),具体描述见表1.表1中的不平衡率(Imbalance Ratio,IR)反映了数据集各类之间的不平衡程度,对于二分类集,不平衡率 (1) 数据预处理将训练集和测试集归一化到[0,1]区间. 3.2不平衡数据集分类的评价准则 在对不平衡数据集进行分类时,不能简单地采用整体精度的高低来评价分类器的好坏.这是因为在不平衡数据集中各类的样本数量相差较大,如果分类器能够完全识别多数类样本,即使对少数类样本的识别完全错误,总体的分类精度也会维持在一个较高的水准.目前常用的评价标准有查全率、查准率、G-mean值、F-value等. 表2 二分类不平衡数据的混合矩阵Tab.2 Confusion matrix of two-class datasets 表2给出了二分类不平衡数据的混合矩阵,它是评价分类性能的一种常用方法.表2中TP表示少数类被准确分类的样本个数,FN表示少数类被错误分类的样本个数,FP表示多数类被错误分类的样本个数,TN表示多数类被正确分类的样本个数. 查全率: (2) 另外, (3) 查准率: (4) G-mean值: (5) 综合查全率和查准率的F值: (6) 其中G-mean值是少数类样本和多数类样本的分类准确度的乘积,它从整体上综合分析了两类分类准确度[15],只有当rTP,rTN都比较大时,G-mean值才会比较高.Fvalue中的β≥0并且可以调节,通常是取β=1的情况,只有当查全率和查准率都比较高时,Fvalue才会高. 以下分别用SMOTE、Borderline-SMOTE、RB-SMOTE 1和RB-SMOTE 2方法把10个数据集的不平衡率提高到1,利用SVM对合成后的数据集进行分类,结果见表3. 表3 各种方法的G-mean值比较Tab.3 Comparison of G-mean values of various methods 从表3可以看出,各种方法和未做处理的方法相比,G-mean值都有很大地提高,相比之下,RB-SMOTE方法表现得更好一些.RB-SMOTE1方法和RB-SMOTE2方法没有明显区别. 以下分别对Glass4、Ecoli1、Haberman、Pima 4个数据集使用SMOTE、Borderline-SMOTE、RB-SMOTE1、RB-SMOTE2这4种过采样方法,逐步增加合成样本的个数,并利用SVM进行分类,图5~图12分别刻画了Fvalue与rTP的数据比较. 图5 4种方法在Glass4数据集上Fvalue的比较Fig.5 Comparison of Fvalue of 4 methods on Glass4 图6 4种方法在Glass4数据集上rTP的比较Fig.6 Comparison of rTP of 4 methods on Glass4 图7 4种方法在Ecoli1数据集上Fvalue的比较Fig.7 Comparison of Fvalue of 4 methods on Ecoli1 图8 4种方法在Ecoli1数据集上rTP的比较Fig.8 Comparison of rTP of 4 methods on Ecoli1 图9 4种方法在Haberman数据集上Fvalue的比较Fig.9 Comparison of Fvalue of 4 methods on Haberman 图10 4种方法在Haberman数据集上rTP的比较Fig.10 Comparison of rTP of 4 methods on Haberman 由图5~图12可以看出,对于这4种方法来说,随着少数类样本个数的增加,Fvalue与rTP均有增加的趋势,当合成样本数量刚开始增加时,Fvalue与rTP都增加的较快,但当合成样本数量增加到一定数量后Fvalue与rTP的变化就趋于平缓.比较各图的Fvalue与rTP数据,总体来说RB-SMOTE1、RB-SMOTE2两种方法取得了更好的效果. 图11 4种方法在Pima数据集上Fvalue的比较Fig.11 Comparison of Fvalue of 4 methods on Pima 图12 4种方法在Pima数据集上rTP的比较Fig.12 Comparison of rTP of 4 methods on Pima 本文在Borderline-SMOTE方法的基础上,进一步精细化边界样本的采样倍率,提出了RB-SMOTE方法,该方法使得不平衡数据的分布得到进一步改善,代价是增加了采样方法的复杂度,但这仍然是可以接受的.仿真实验的结果进一步验证了RB-SMOTE方法能够有效地提高不平衡数据集的少数类的分类性能和整体的分类性能. [1] TRIVEDI I,MONIKA,MRIDUSH M.Credit card fraud detection [J].InternationalJournalofAdvancedResearchinComputerandCommunicationEngineering,2016,5(1):39-50. [2] BAHNSEN A C,AOUADA D,STOJANOVIC A,etal.Feature engineering strategies for credit card fraud detection [J].ExpertSystemswithApplications,2016,51:134-142. [3] WEISS G M.Mining with rarity: A unifying framework [J].SIGKDDExplorations,2004,6(1):7-19. [4] HUANG Y.Cost-sensitive incremental classification under the map reduce framework for mining imbalanced massive data streams [J].JournalofDiscreteMathematicalSciences&Cryptography,2015,18(1-2):177-194. [5] HUANG Y.Dynamic cost-sensitive ensemble classification based on extreme learning machine for mining imbalanced massive data streams [J].InternationalJournalofu-ande-Service,ScienceandTechnology,2015,8(1):333-346. [6] ZHU W X,ZHONG P.A new one-class SVM based on hidden information [J].Knowledge-BasedSystems,2014,60(2): 35-43. [7] WANG T,CHEN J,ZHOU Y,etal.Online least squares one-class support vector machines-based abnormal visual event detection [J].Sensors,2013,13(12):17130-17155. [8] SCHAPIRE R E.A brief introduction to boosting [C]∥Proceedings of the Sixteenth International Joint Conference on Artificial intelligenc.San Francisco: Morgan Kaufmann Publishers Inc,1999:1401-1406. [9] FREUND Y,SCHAPIRE R.Experiments with a new Bossting algorithm [C]∥Proceedings of the Thirteenth International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publishers Inc,1996:148-156. [10] OUSSALAH M.A new classification strategy for human activity recognition using cost sensitive support vector machines for imbalanced data [J].Kybernetes,2014,43(8):1150-1164. [11] ZONG W W,HUANF G B,CHEN Y Q.Weighted extreme learning machine for imbalance learning [J].Neurocomputing,2013,101(3):229-242. [12] JAPKOWICZ N,MYERS C,GLUCK M A.A novelty detection approach to classification [C]∥Proceedings of the fourteenth Joint Conference on Artificial Intelligence.San Francisco: Morgan Kaufmann Publishers Inc,1995:518-523. [13] CHAWLA N V,BOWYER K W,HALL L O,etal.SMOTE: Synthetic minority over-sampling technique [J].JournalofMachineLearningResearch,2002,16:321-357. [14] WAN K J,ADRIAN A M,CHEN K H,etal.A hybrid classifier combining borderline-SMOTE with AIRS algorithm for estimating brain metastasis from lung cancer: A case study in China Taiwan [J].ComputerMethods&ProgramsinBiomedicine,2015,119(2):63-76. [15] YEN S J,LEE Y S.Cluster-based under-sampling approaches for imbalanced data distributions [J].ExpertSystemswithApplications,2009,36(3):5718-5727. ARefinedBorderline-SMOTEMethodforImbalancedDataSet YANGYi,LUChengbo,XUGenhai (FacultyofEngineering,LishuiUniversity,Lishui323000,China) One of the most popular over-sampling approaches to deal with the class imbalance problem is SMOTE(Synthetic Minority Over-sampling Technique),which generated new synthetic samples along the line between the minority examples and their selected nearest neighbors.Based on SMOTE method,borderline-SMOTE only over-samples the minority samples near the borderline.In this paper,we propose a refined borderline-SMOTE(RB-SMOTE) method which generates different number of new synthetic samples according to different borderline minority samples.In experiments,SVMs are used as classifiers,the proposed RB-SMOTE method is evaluated on 10 imbalanced datasets whose imbalance ratios vary from drastic 0.0647 to 0.5360 and is shown to be very effective to improve the performance of classification of imbalance data sets. imbalanced data set; classification; over sampling; support vector machine 0427-7104(2017)05-0537-08 2016-08-23 浙江省自然科学基金(LY18F030003);国家自然科学基金(61373057) 杨 毅(1980—),女,讲师,硕士;卢诚波(1977—),男,副教授,博士,通信联系人, E-mail: lu.chengbo@aliyun.com. TP183;TP181 A

3 仿真实验



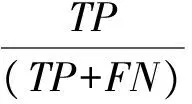

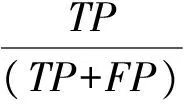
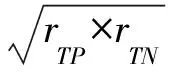







4 结 语
